1.ZooKeeper基础
1.1 为什么使用ZooKeeper?
- Nginx作为负载均衡管理大量服务器时,管理起来比较麻烦,可以通过zookeeper注册服务与发现服务协作管理。
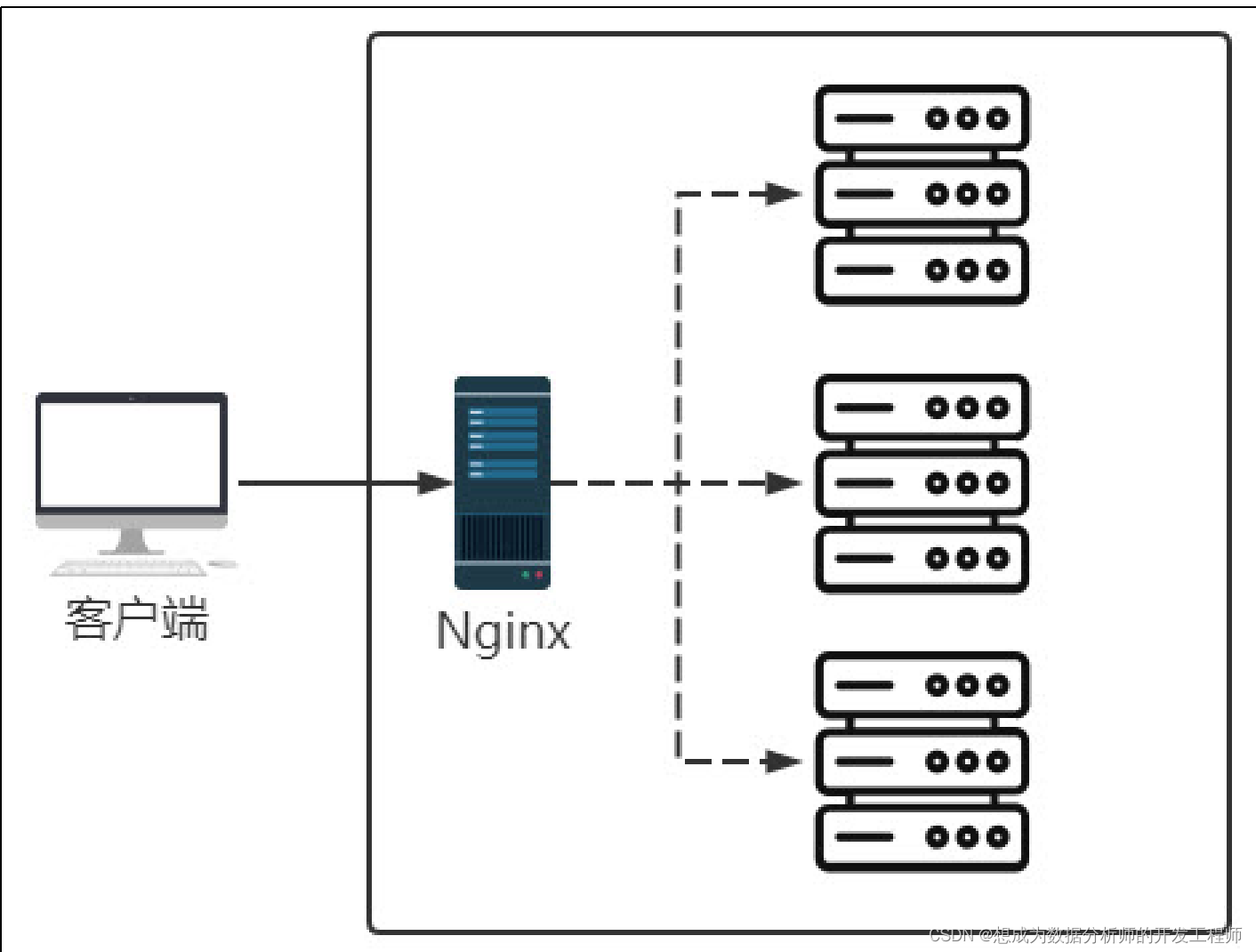
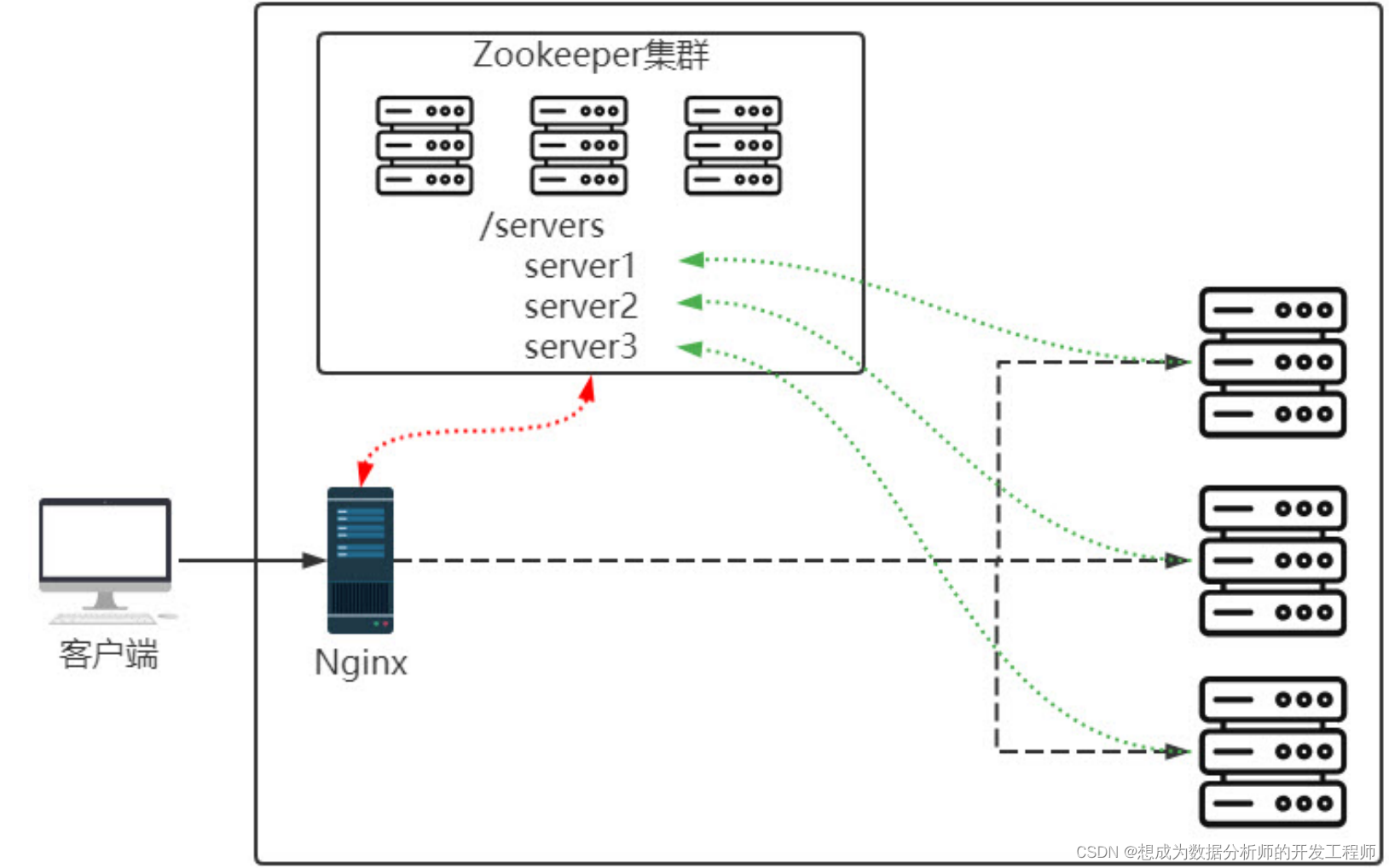
- 使用分布式部署后,多线程安全的问题,以前学的同步代码块、重构锁、读写锁等通通失效,怎么办?
- 大数据分布式集群中,集群的服务器如何管理?
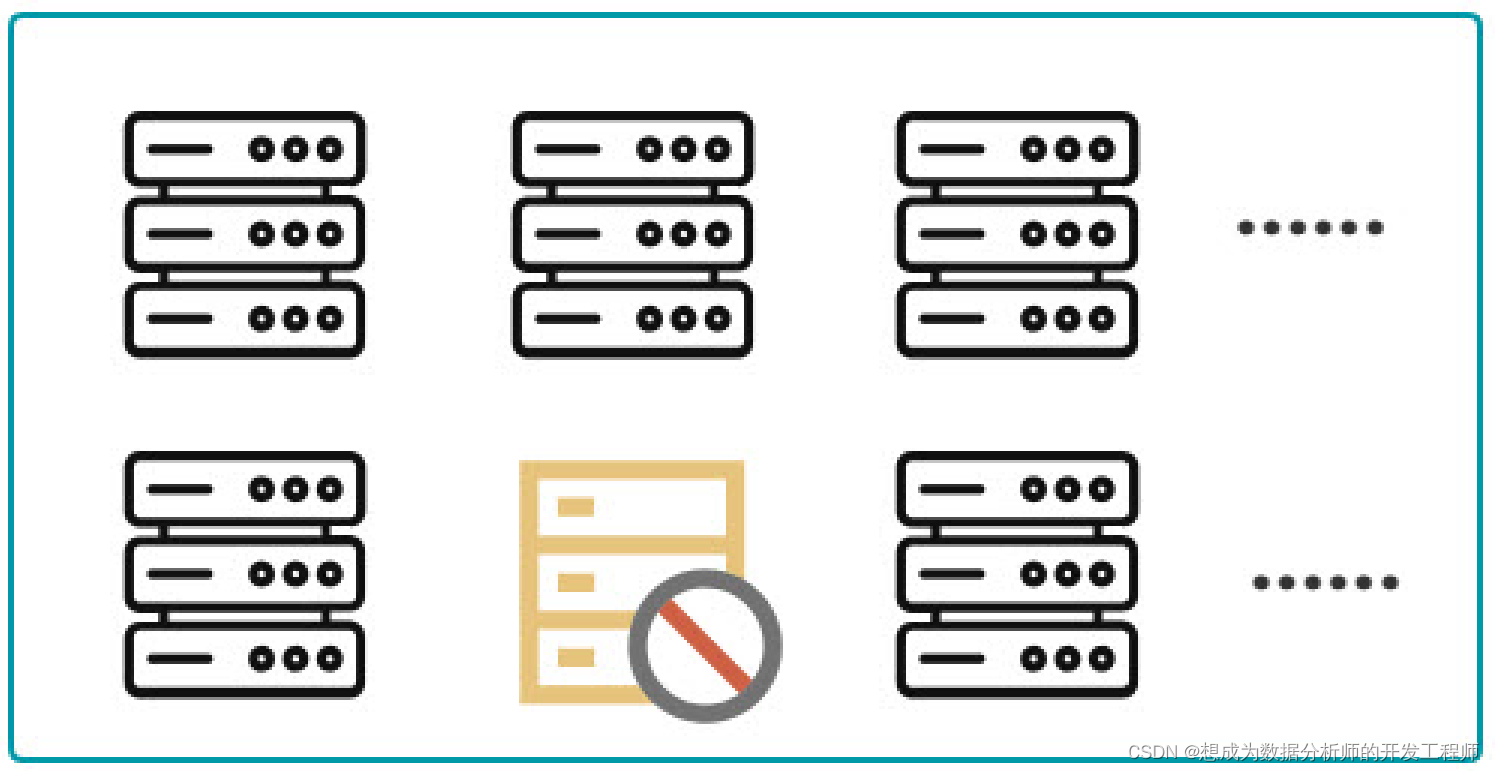
- 以前大部分应用需要开发私有的协调程序,缺乏一个通用的机制协调程序的反复编写浪费,且难以形成通用、伸缩性好的协调器
1.2 ZooKeeper概述
1.2.1 ZooKeeper简介
ZooKeeper:动物园管理员
ZooKeeper是分布式应用程序的协调服务框架,是Hadoop的重要组件。ZooKeeper是Google的Chubby一个开源的实现,是Hadoop的分布式协调服务,包含一个简单的原语集,分布式应用程序可以基于它实现。
扩展:zk是根据Google的一篇论文
《The Chubby lock service for loosely coupled distributed systems》
1.2.2 具体应用场景
- Hadoop,使用ZooKeeper的事件处理确保整个集群只有一个NameNode,存储配置信息等
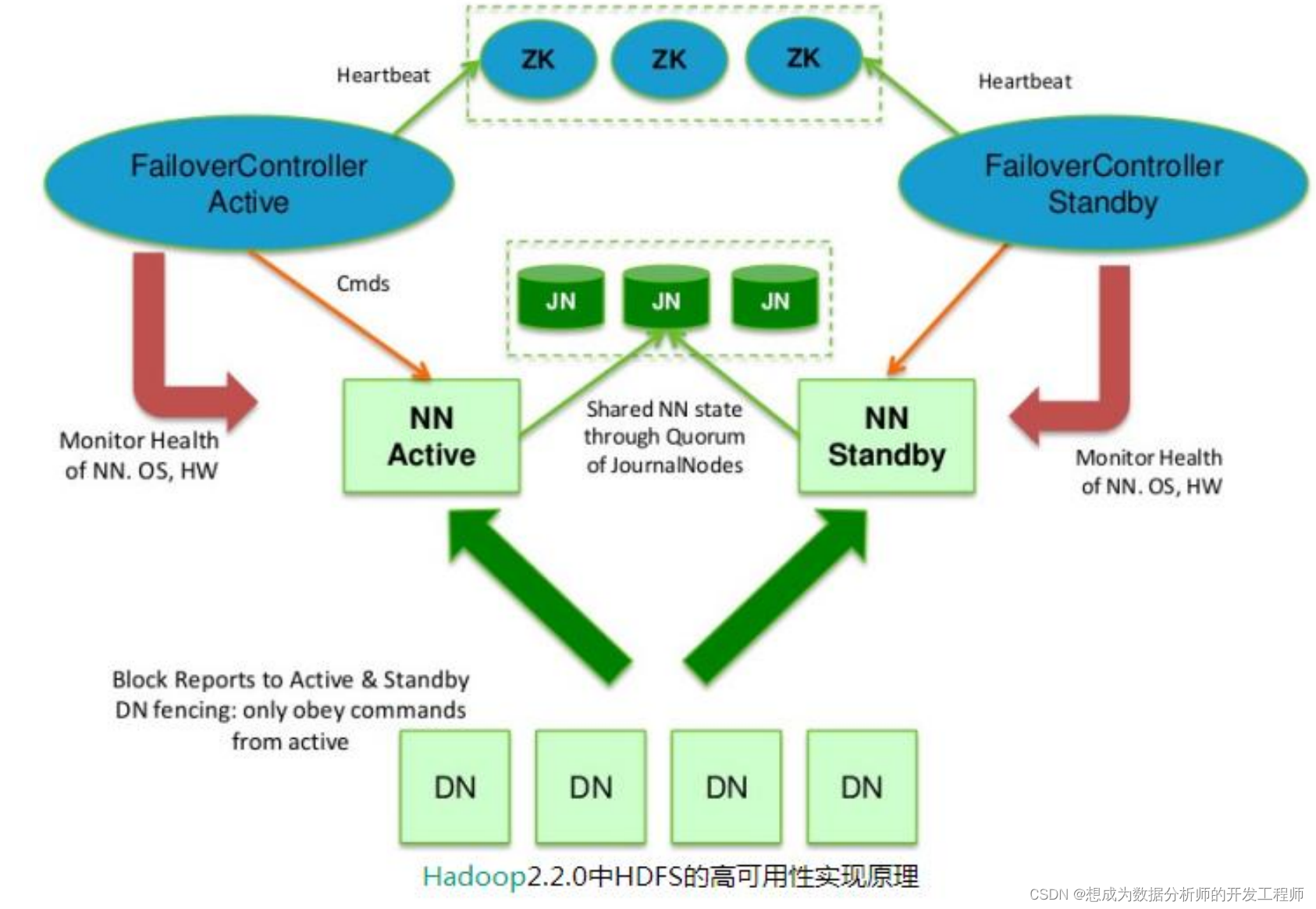
- HBase,使用ZooKeeper的事件处理确保整个集群只有一个HMaster,察觉HRegionServer联机和宕机,存储访问控制列表等.
- 分布式环境下的统一命名服务
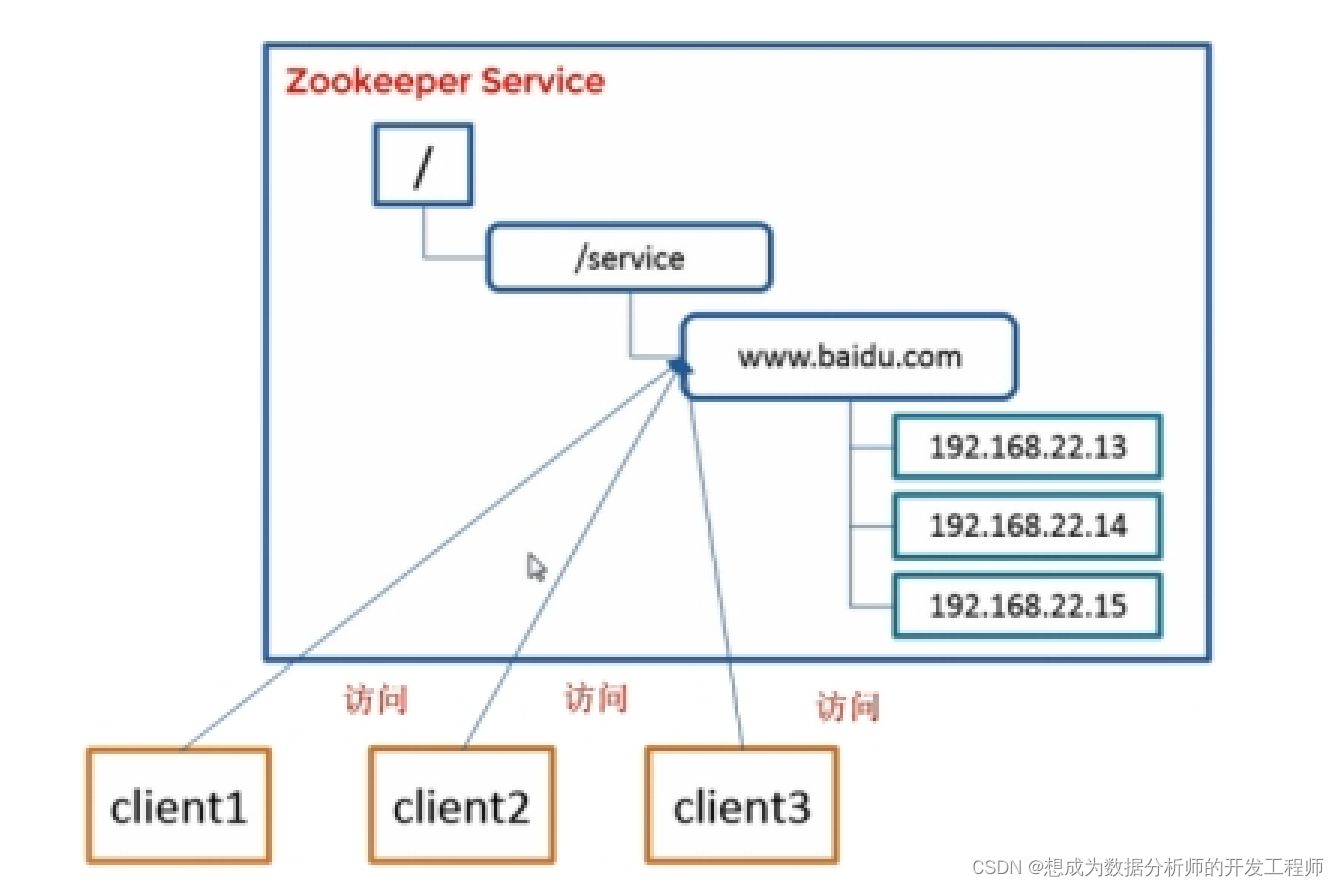
- 分布式环境下的配置管理
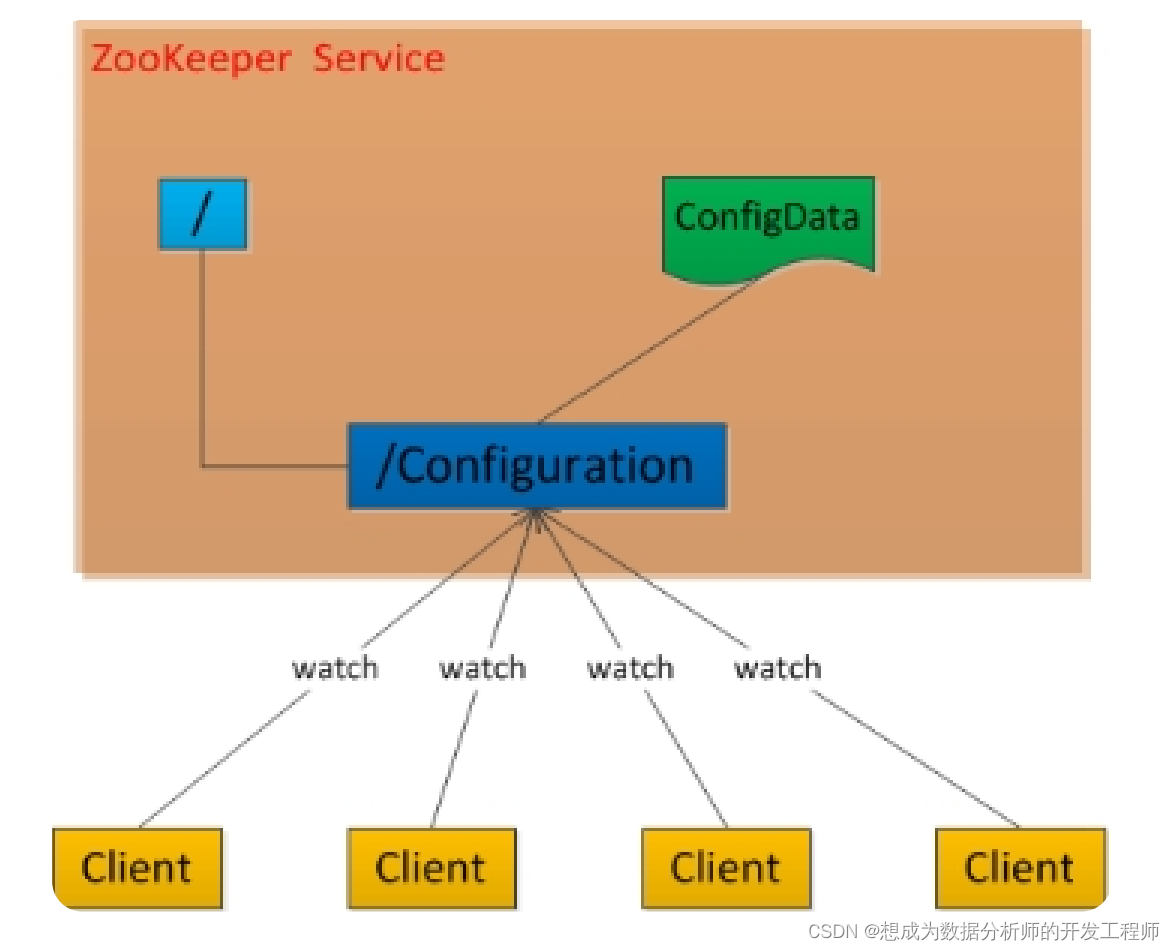
- 数据发布/订阅
- 分布式环境下的分布式锁
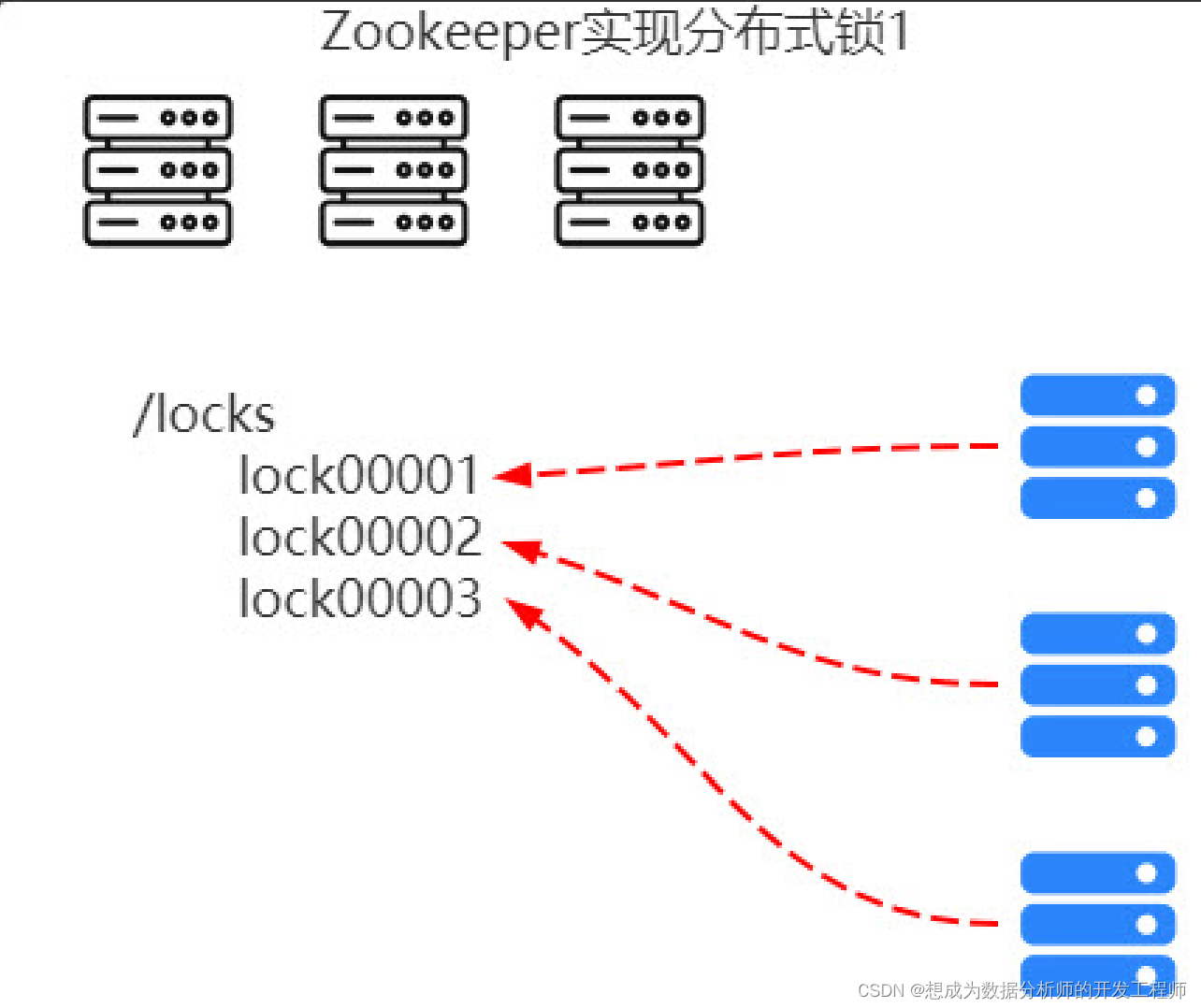
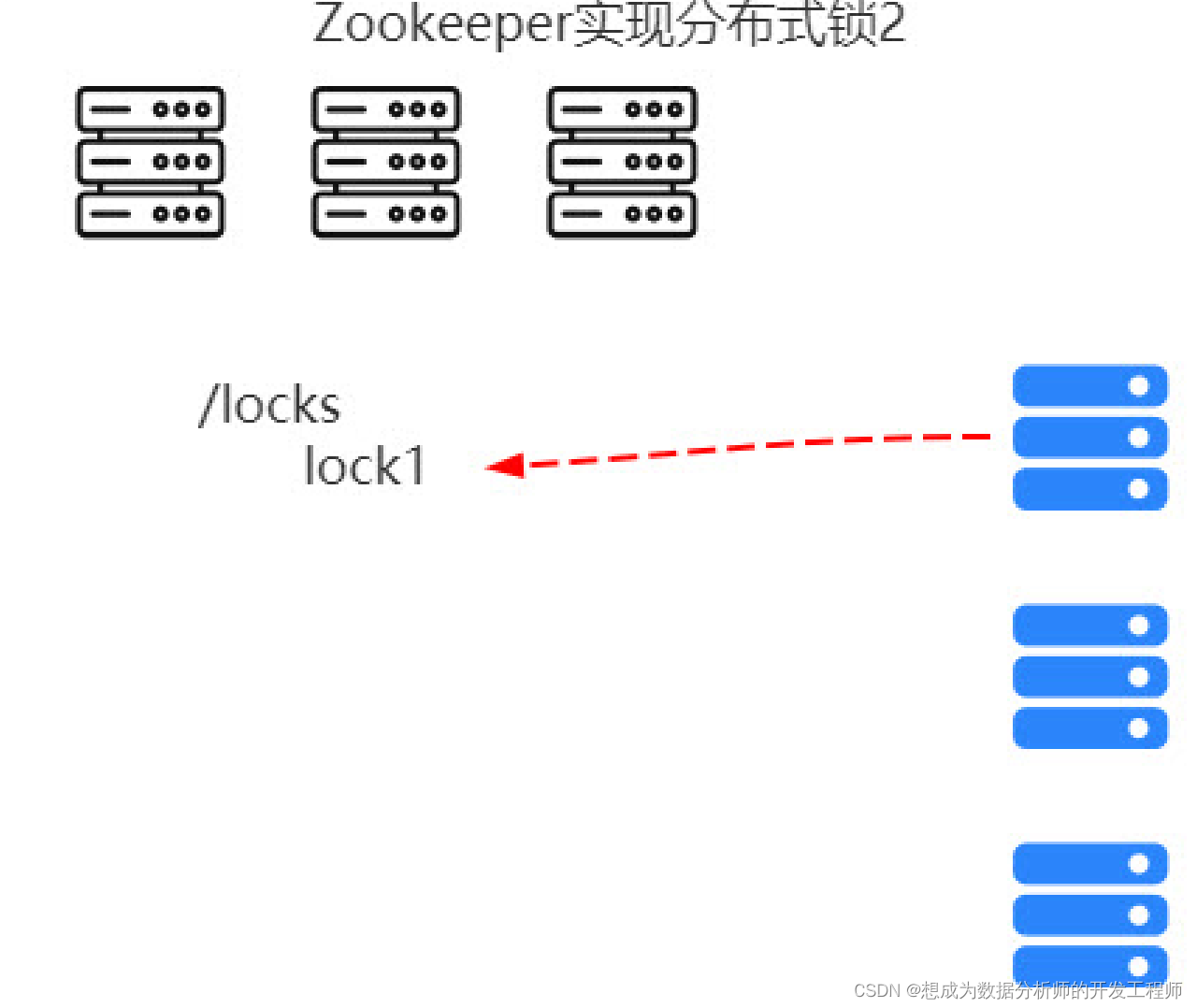
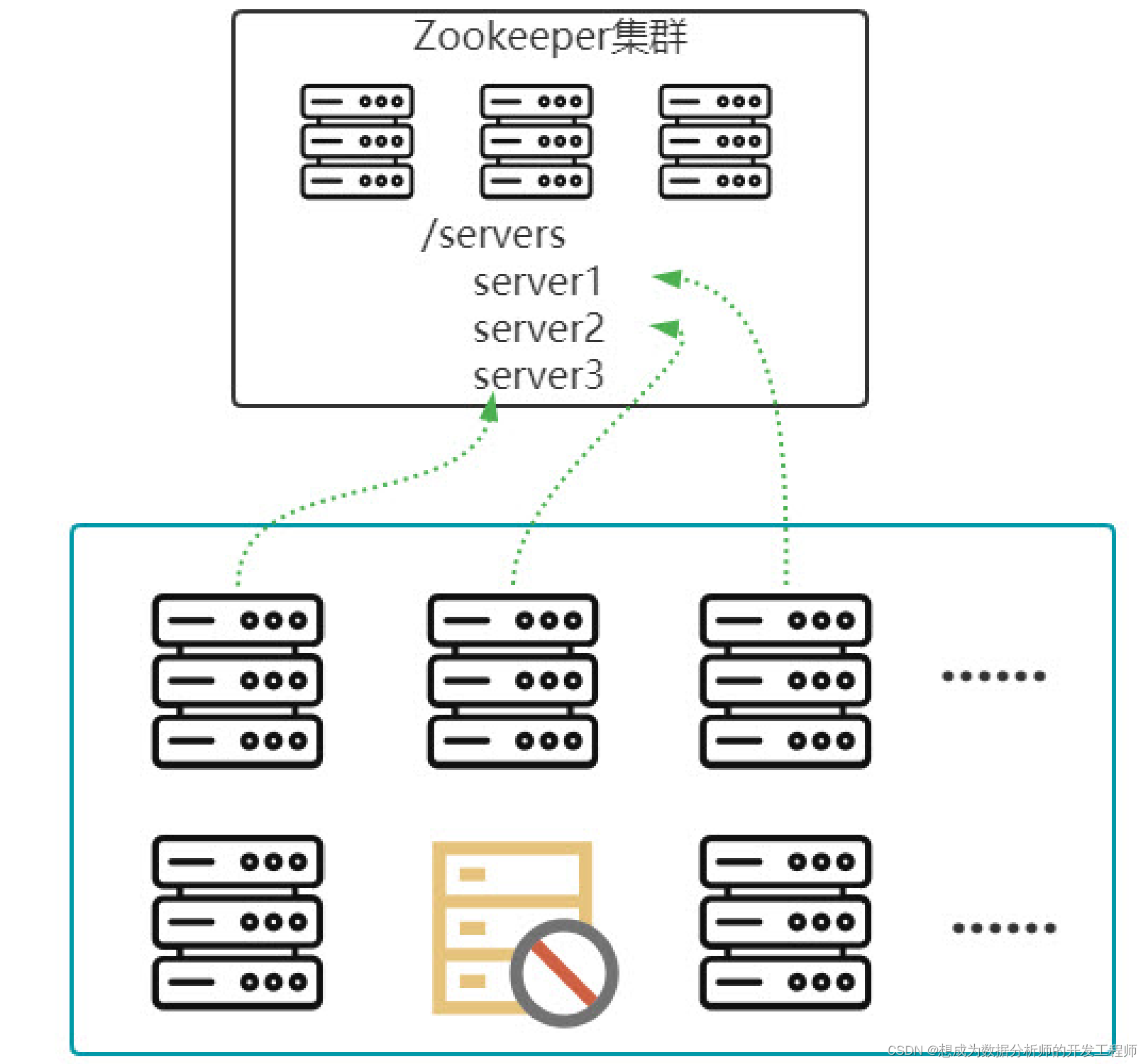
- 集群管理问题
1.3 分布式编程容易出现的问题
分布式的思想就是人多干活快,即用多台机器同时处理一个任务。分布式的编程和单机的编程 思想是不同的,随之也带来新的问题和挑战。
- 活锁。活锁定义:在程序里,由于某些条件的发生碰撞,导致重新执行,再碰撞=》再执 行,如此循环往复,就形成了活锁。活锁的危害:多个线程争用一个资源,但是没有任何一个 线程能拿到这个资源。(死锁是有一个线程拿到资源,但相互等待互不释放造成死锁),活锁 是死锁的变种。补充:活锁更深层次的危害,很耗尽Cpu资源(在做无意义的调度)

- 需要考虑集群的管理问题,需要有一套机制来检测到集群里节点的状态变化。
- 如果用一台机器做集群管理,存在单点故障问题,所以针对集群管理,也需要形成一个集群
- 管理集群里Leader的选举问题(要根据一定的算法和规则来选举),包括要考虑Leader挂掉 之后,如何从剩余的follower里选出Leader
- 分布式锁的实现,用之前学的重入锁,同步代码块是做不了的
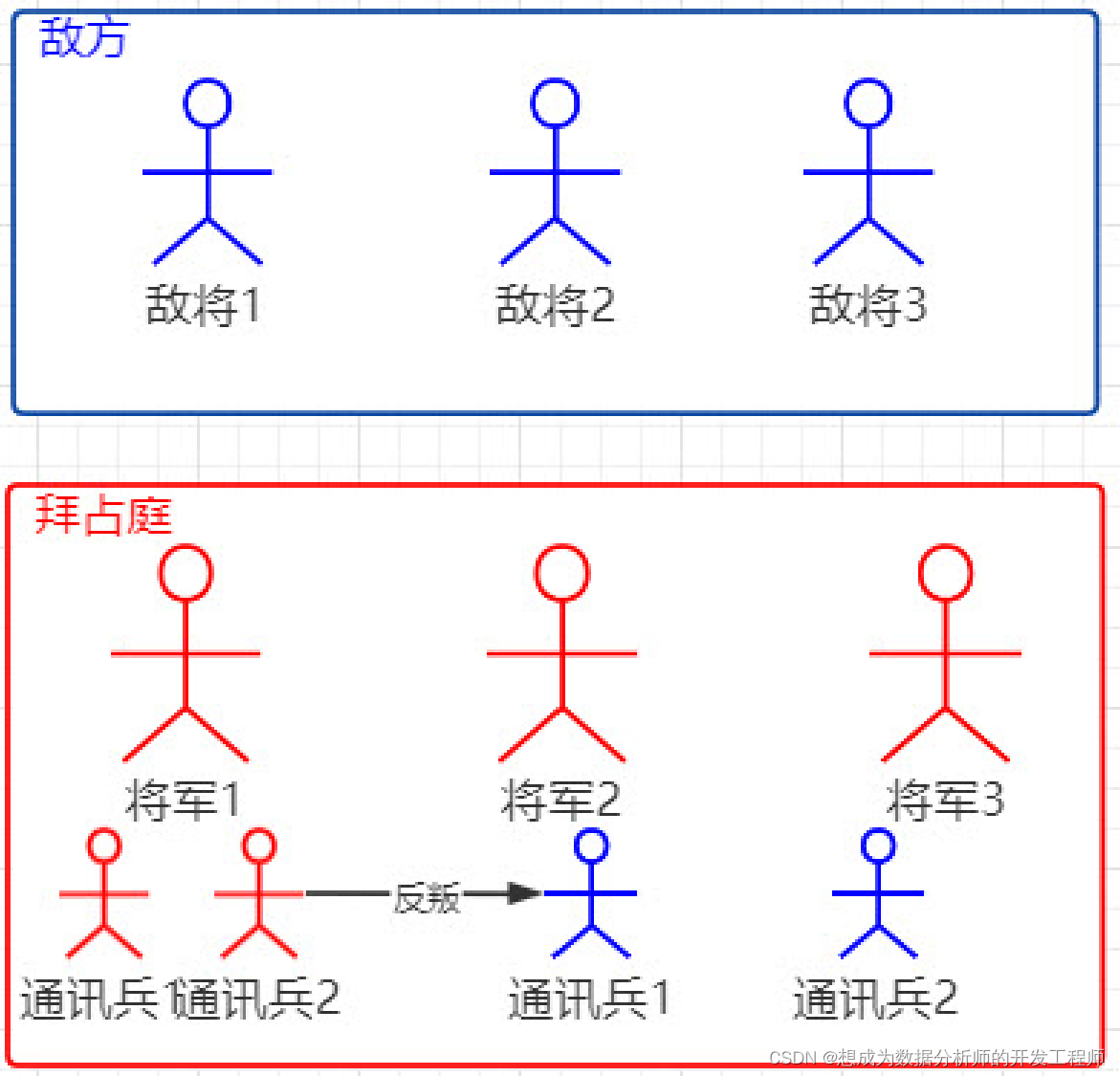
1.4 拜占庭将军问题
那么ZooKeeper最基础的东西是什么呢?不得不提Paxos,它是一个基于消息传递的一致性算法,Leslie Lamport(莱斯利·兰伯特)在1990年提出,近几年被广泛应用于分布式计算中,Google的 Chubby,Apache的ZooKeeper都是基于它的理论来实现的,Paxos还被认为是到目前为止唯一的分布式一致性算法,其它的算
法都是Paxos的改进或简化。有个问题要提一下,Paxos有一个前提:没有拜占庭将军问题。就是说Paxos只有在一个可信的计算环境中才能成立,这个环境是不会被入侵所破坏的。
1.5 Paxos的小岛的故事
Paxos描述了这样一个场景,有一个叫做Paxos的小岛(Island)上面住了一批居民,岛上面所有的事情由一些特殊的人决定,他们叫做议员(Senator)。议员的总数(Senator Count)是确定的,不能更改。岛上每次环境事务的变更都需要通过一个提议(Proposal),每个提议都有一个编号(PID),这个编号是一直增长的,不能倒退。每个提议都需要超过半数((Senator Count/2)+1)的议员同意才能生效。每个议员只会同意大于当前编号的提议,包括已生效的和未生效的。如果议员收到小于等于当前编号的提议,他会拒绝,并告知对方:你的提议已经有人提过了。这里的当前编号是每个议员在自己记事本上面记录的编号,他不断更新这个编号。整个议会不能保
证所有议员记事本上的编号总是相同的。现在议会有一个目标:保证所有的议员对于提议都能达成一致的看法。
好,现在议会开始运作,所有议员一开始记事本上面记录的编号都是0。有一个议员发了一个提议:将电费设定为1元/度。他首先看了一下记事本,嗯,当前提议编号是0,那么我的这个提议的编号就是1,于是他给所有议员发消息:1号提议,设定电费1元/度。其他议员收到消息以后查了一下记事本,哦,当前提议编号是0,这个提议可接受,于是他记录下这个提议并回复:我接受你的1号提议,同时他在记事本上记录:当前提议编号为1。发起提议的议员收到了超过半数的回复,立即给所有人发通知:1号提议生效!收到的议员会修改他的记事本,将1好提议由记录改成正式的法令,当有人问他电费为多少时,他会查看法令并告诉对方:1元/度。
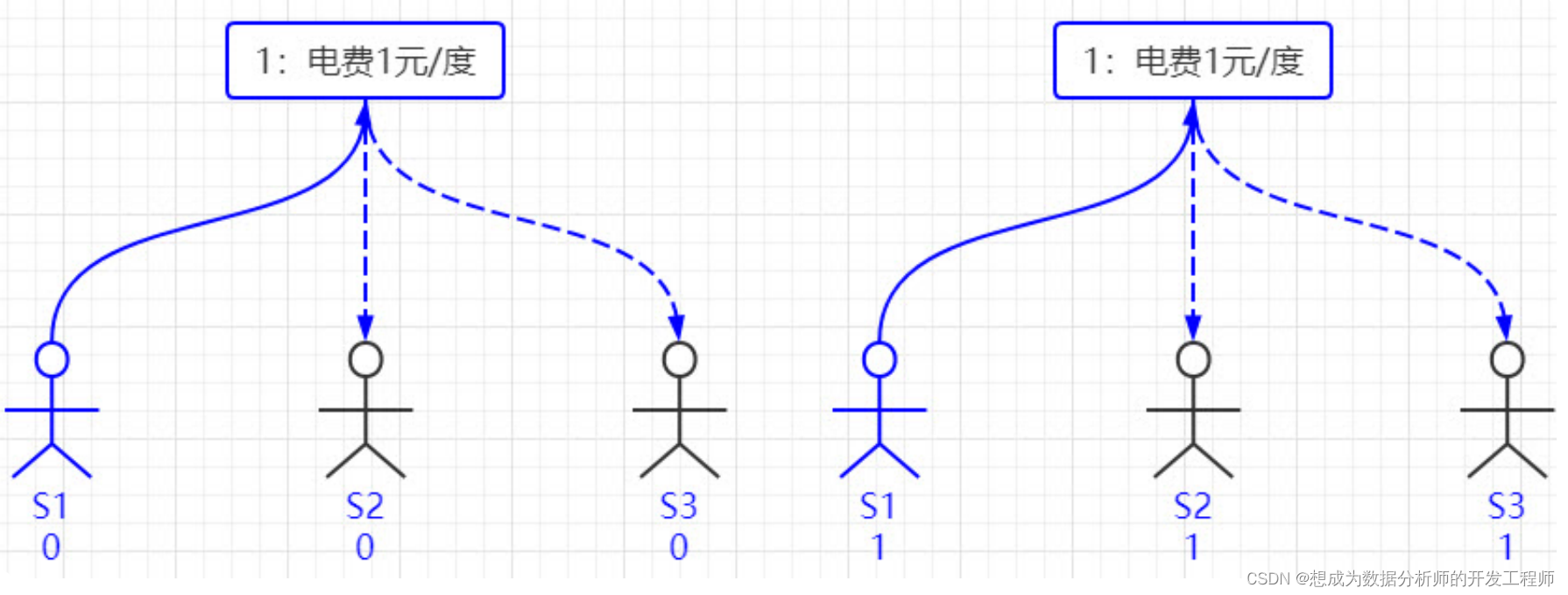
现在看冲突的解决:假设总共有三个议员S1-S3,S1和S2同时发起了一个提议:1号提议,设定电费。S1想设为1元/度, S2想设为2元/度。结果S3先收到了S1的提议,于是他做了和前面同样的操作。紧接着他又收到了S2的提议,结果他一查记事本,咦,这个提议的编号小于等于我的当前编号1,于是他拒绝了这个提议:对不起,这个提议先前提过了。于是S2的提议被拒绝,S1正式发布了提议: 1号提议生效。S2向S1或者S3打听并更新了1号法令的内容,然后他可以选择继续发起2号提议。
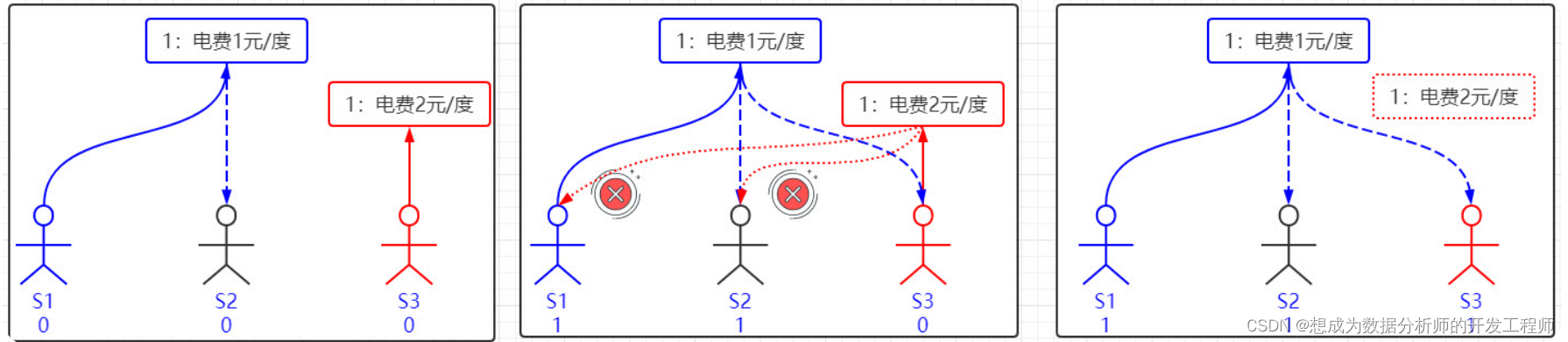
好,我觉得Paxos的精华就这么多内容。现在让我们来对号入座,看看在ZK Server里面Paxos是如何得以贯彻实施的。
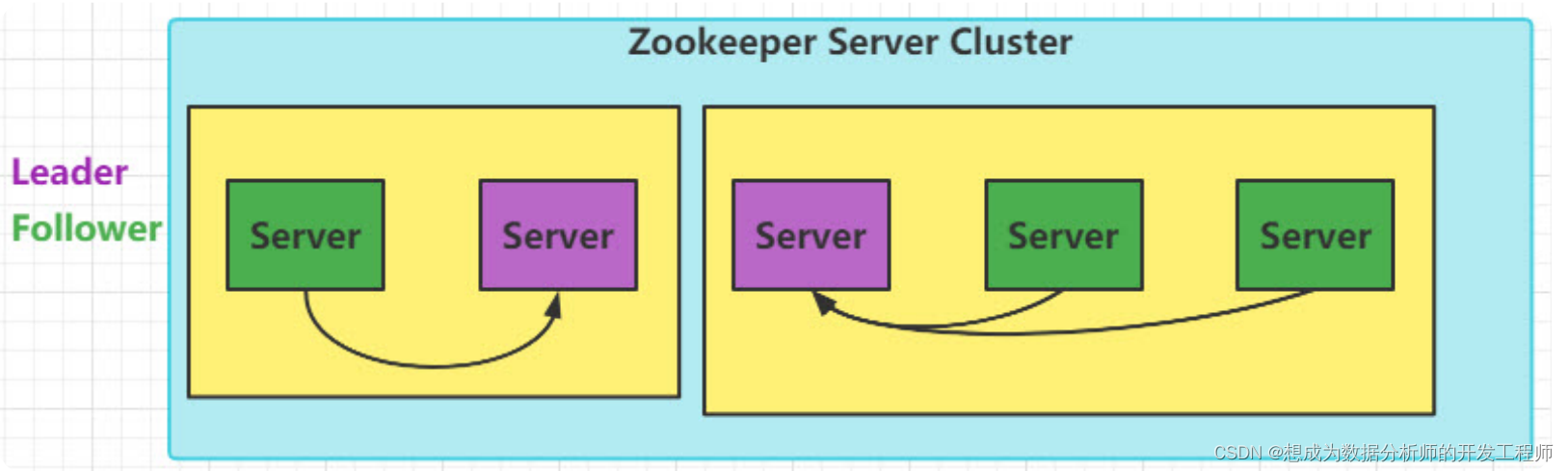
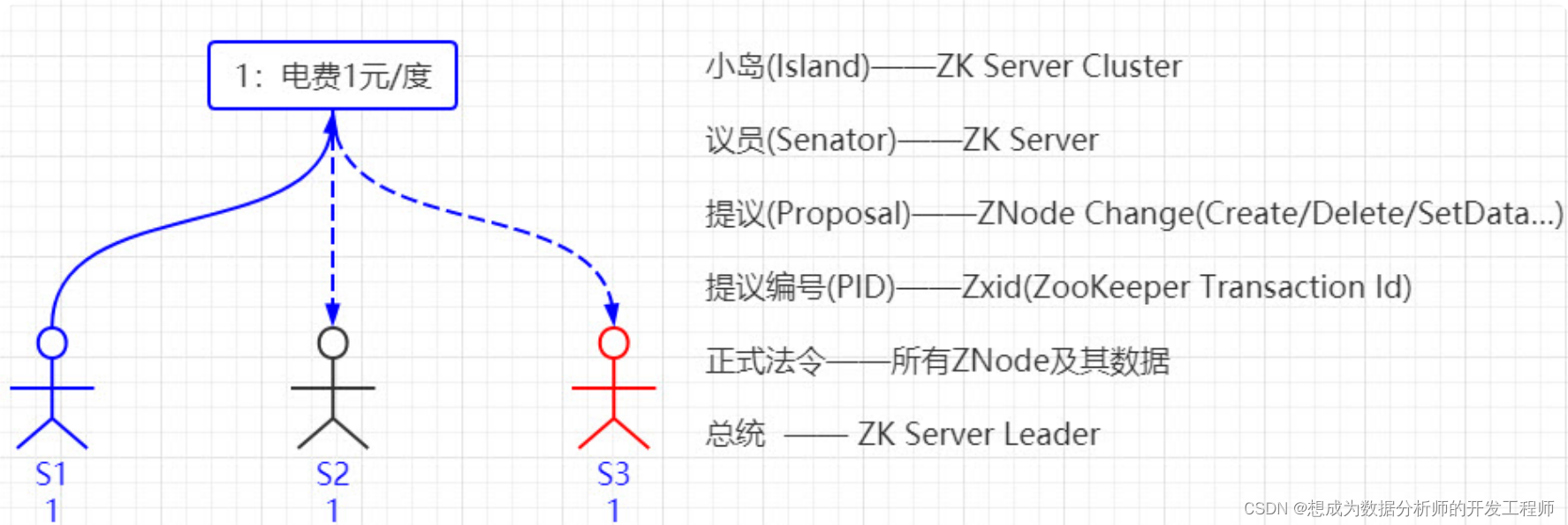
小岛(Island)——ZK Server Cluster
议员(Senator)——ZK Server
提议(Proposal)——ZNode Change(Create/Delete/SetData…)
提议编号(PID)——Zxid(ZooKeeper Transaction Id)
正式法令——所有ZNode及其数据
貌似关键的概念都能一一对应上,但是等一下,Paxos岛上的议员应该是人人平等的吧,而ZK Server好像有一个Leader的概念。没错,其实Leader的概念也应该属于Paxos范畴的。如果议员人人平等,在某种情况下由于提议的冲突而产生一个“活锁”(所谓活锁我的理解是大家都没有死,都在动,但是一直解决不了冲突问题)。Paxos的作者Lamport在他的文章”The Part-TimeParliament“中阐述了这个问题并给出了解决方案——在所有议员中设立一个总统,只有总统有权发出提议,如果议员有自己的提议,必须发给总统并由总统来提出。好,我们又多了一个角色:总统。
总统——ZK Server Leader
1.6 集群架构剖析
1.6.1 ZooKeeper之攘其外
ZooKeeper服务端有两种不同的运行模式。单机的称为**“独立模式”**(standalone mode),但是独立模式存在单点故障的问题,所以在实际开发使用较少;集群的称为“仲裁模式(quorummode)”,不存在单点故障的问题,实际开发中使用较多。

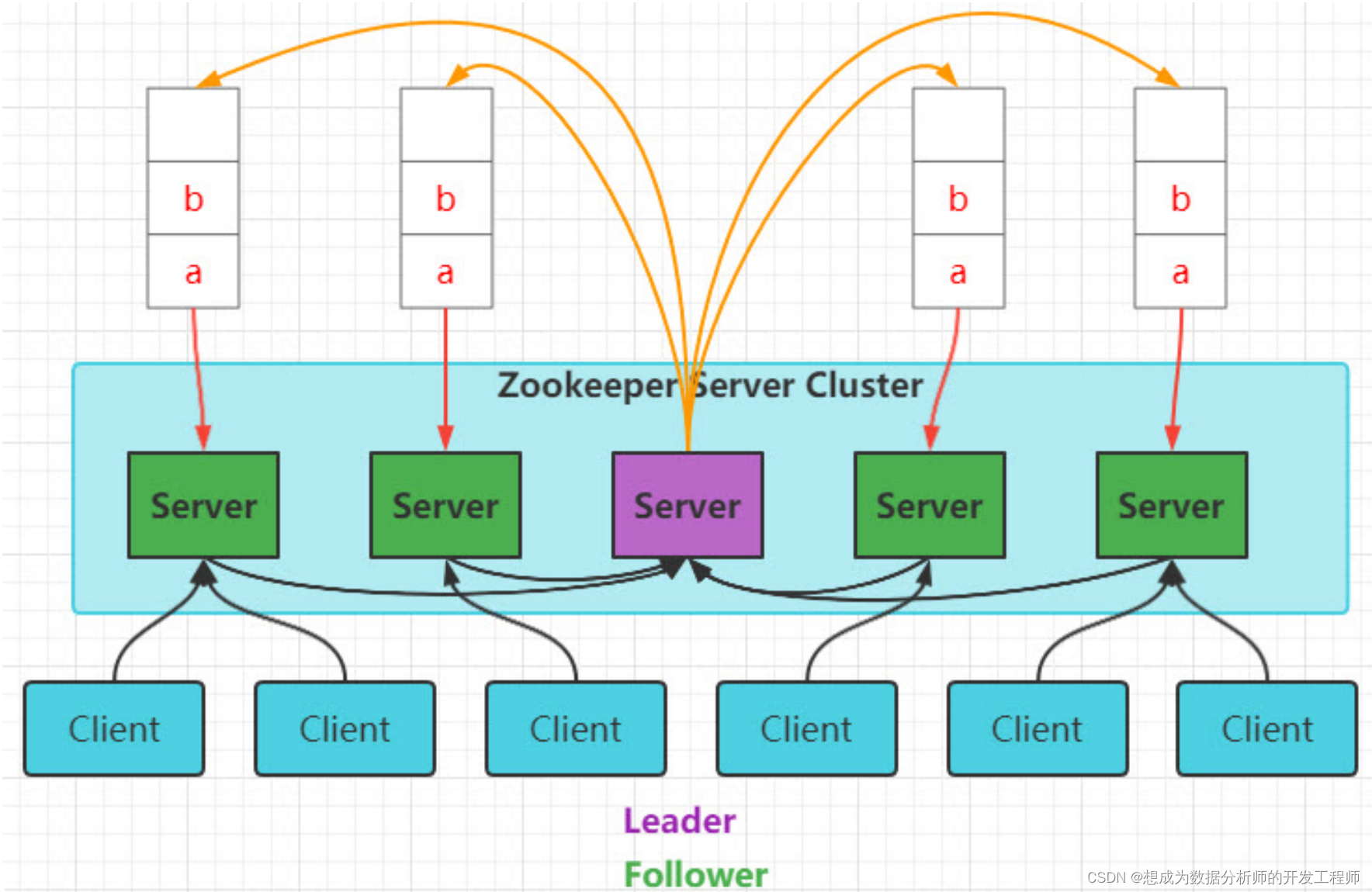
- 主从架构:Master + Slave
- 客户端读: 类比查询余额
- 客户端写:类比存钱
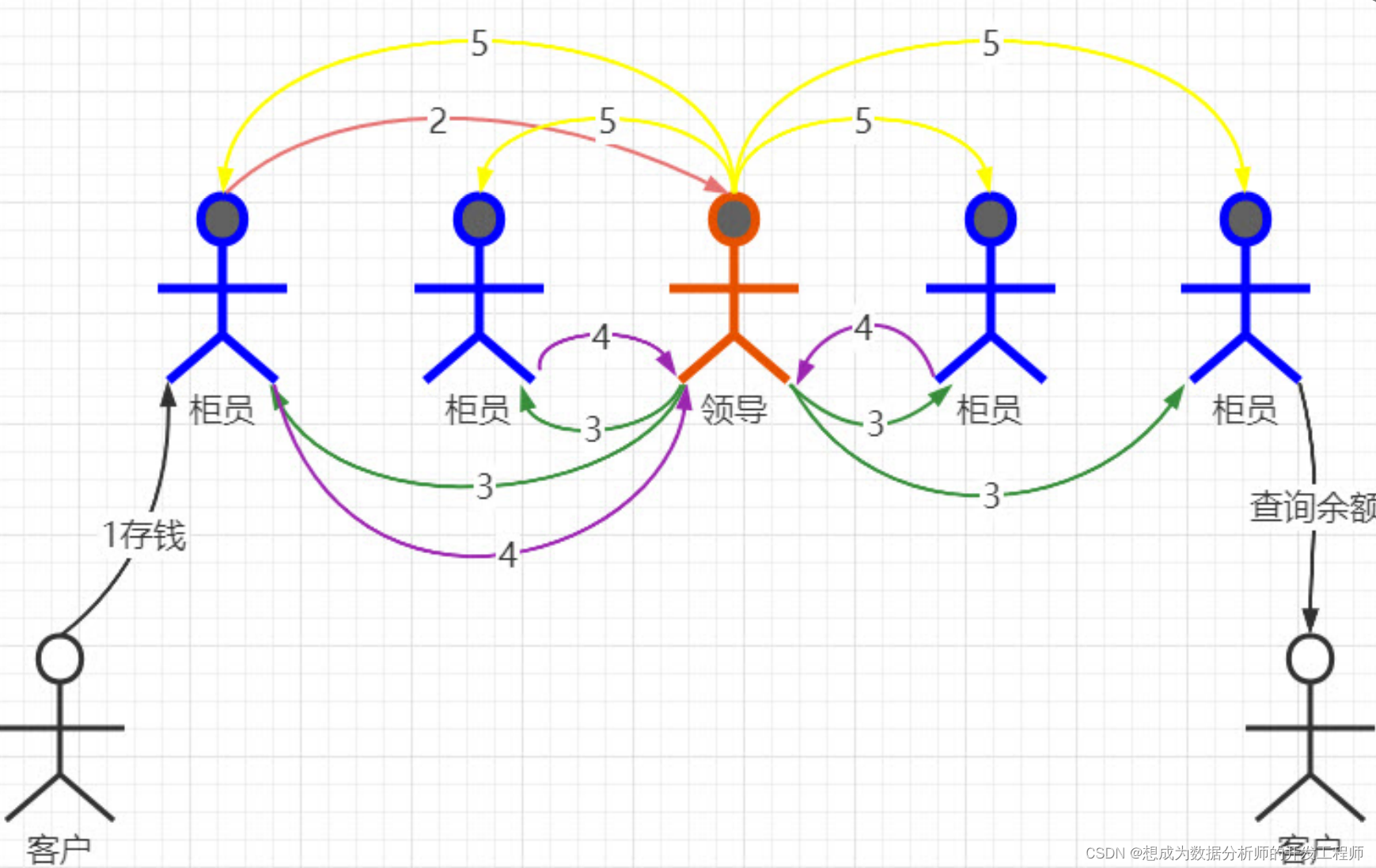
leader在通知follower执行某条命令时,如何保障每个follower都收到,并执行呢?
队列结构
CAP:Consistency一致性;Availability可用性;Partition Tolerance分区容错;三选二
1.6.2 ZooKeeper之安其内
- 思考一下这个架构有什么问题?
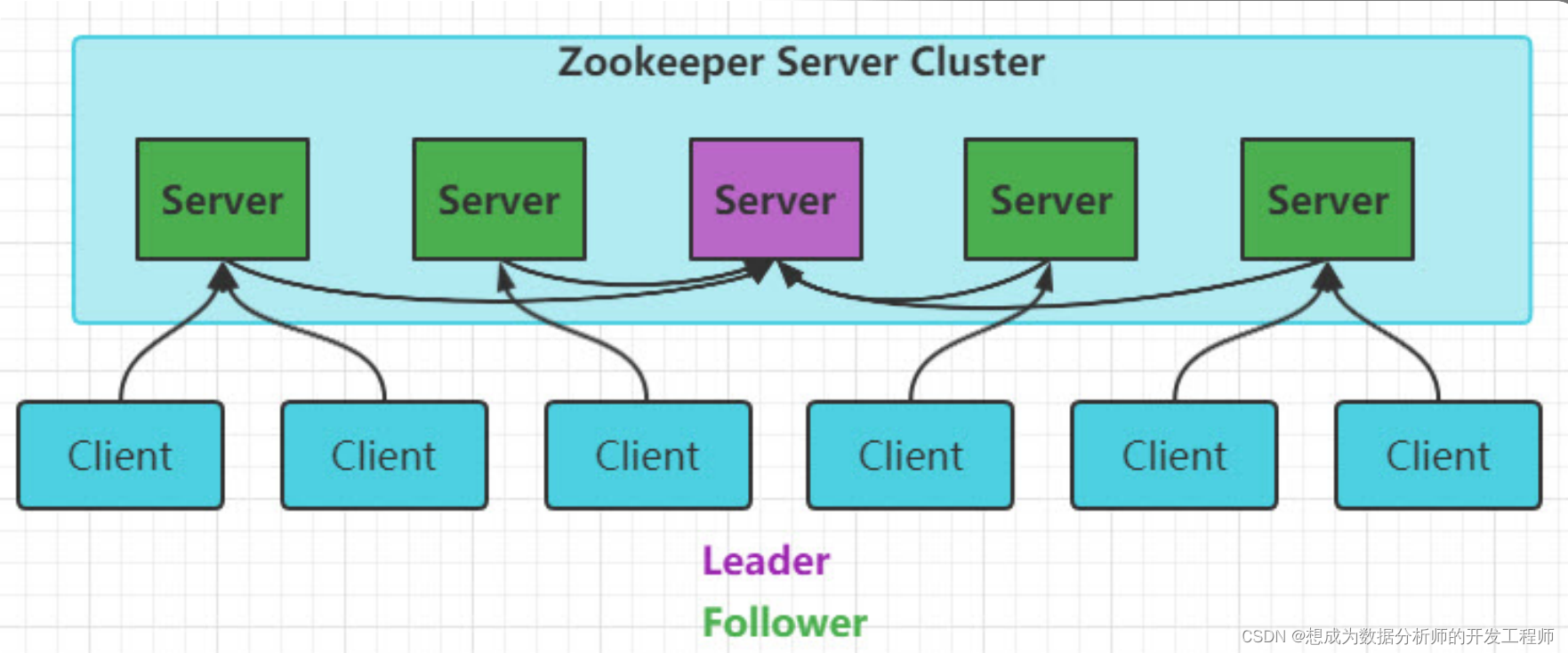
leader很重要?如果挂了怎么办?开始选举新的leader - ZooKeeper服务器四种状态:
- looking:服务器处于寻找Leader群首的状态
- leading:服务器作为群首时的状态
- following:服务器作为follower跟随者时的状态
- observing:服务器作为观察者时的状态
leader选举分两种情况 - 集群初始启动时:安装后首次启动时
- 集群运行中leader挂了时
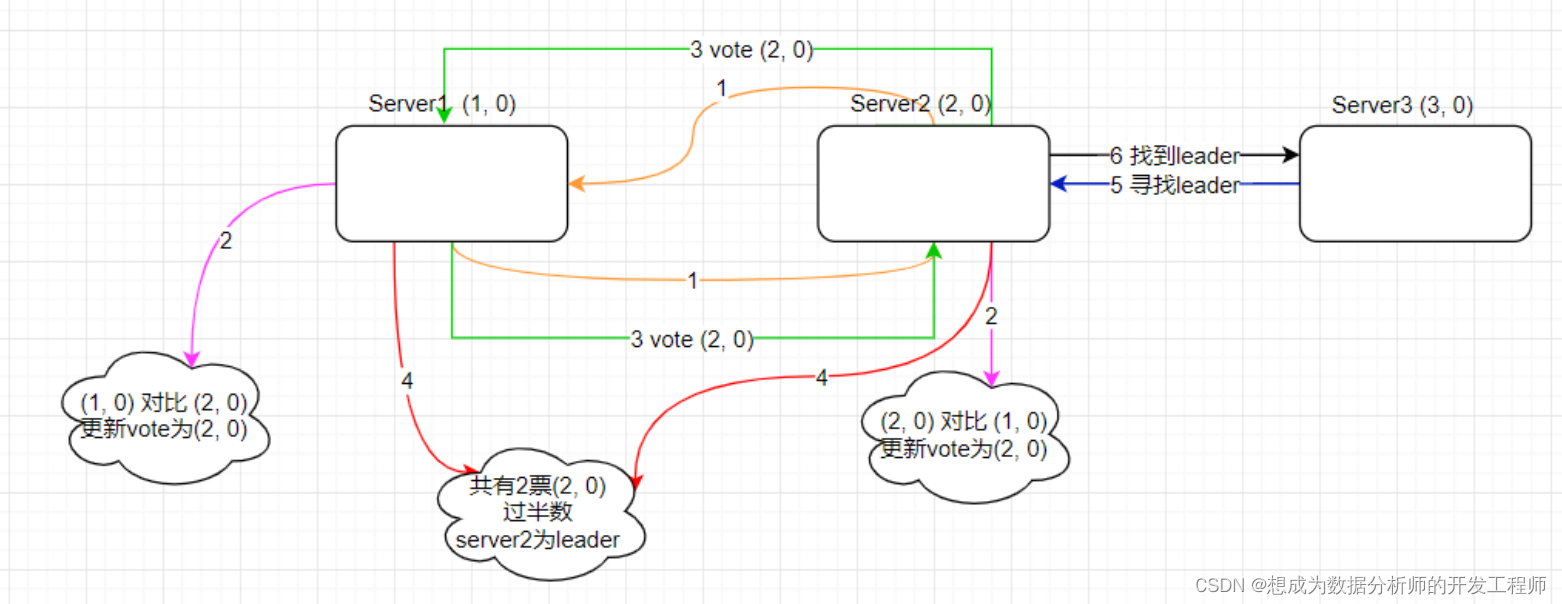
- 集群启动时的Leader选举
- 以3台机器组成的ZooKeeper集群为例
- 原则:集群中过半数Server启动后,才能选举出Leader;
- 此处quorum数是多少?
- 每个server投票信息vote信息结构为(sid, zxid);
server1~3初始投票信息分别为:
server1 -> (1, 0) server2 -> (2, 0) server3 -> (3, 0) - leader选举公式:
server1 (sid1, zxid1)
server2 (sid2, zxid2)
zxid大的server胜出;若zxid相等,再根据判断sid判断,sid大的胜出 - 流程:
- ZK1和ZK2票投给自己;ZK1的投票为(1, 0),ZK2的投票为(2, 0),并各自将投票信息分发给其他机器。
- 处理投票。每个server将收到的投票和自己的投票对比;ZK1更新自己的投票为(2, 0),并将投票重新发送给ZK2。
- 统计投票。server统计投票信息,是否有半数server投同一个服务器为leader;
- 改变服务器状态。确定Leader后,各服务器更新自己的状态,Follower变为FOLLOWING;Leader变为LEADING。
- 当ZK3启动时,发现已有Leader,不再选举,直接从LOOKING改为FOLLOWING。
- 同时ZK1、ZK2、ZK3 选举的流程:
ZK1-> (1, 0) ZK2-> (2, 0) ZK3 -> (3, 0) -> ZK3被选中为Leader,其他两台节点被选为Follower。
- 集群运行时新leader选举:
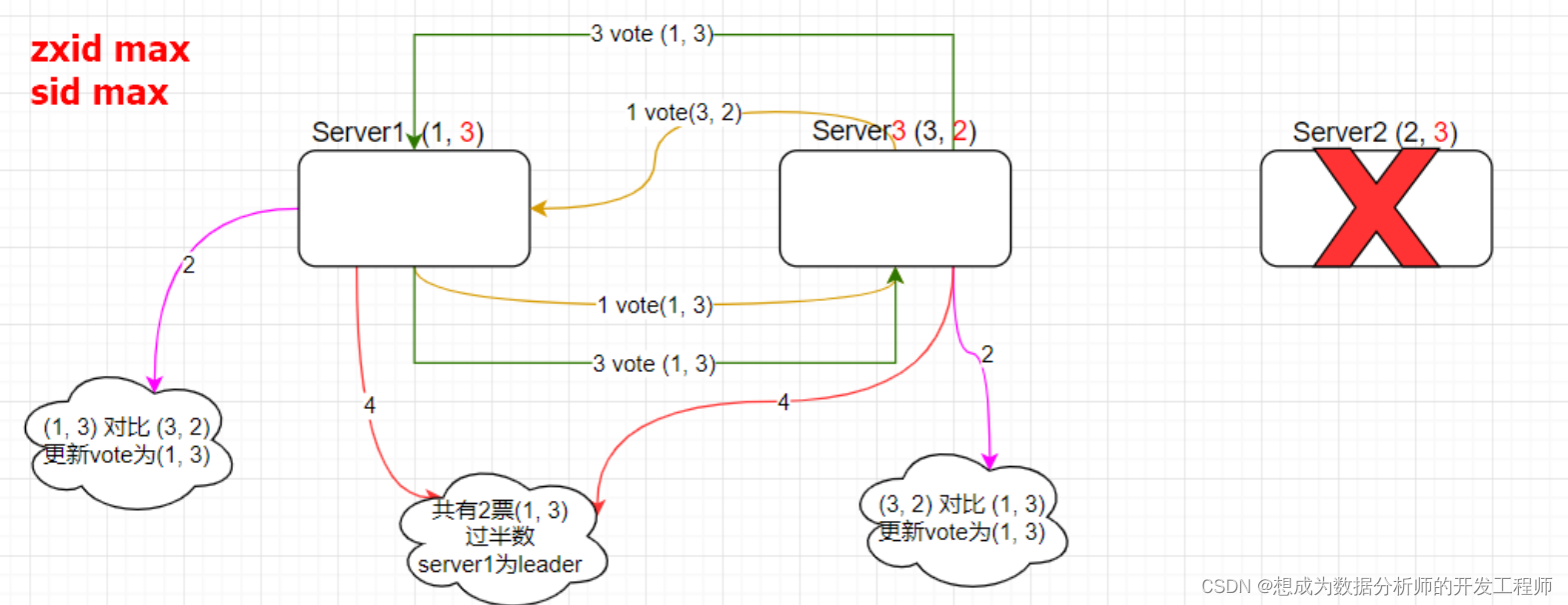
1.6.3 脑裂和服务器数量选取
-
服务器数量选取
ZK集群的服务器的数量通常为奇数台(3,5,7,9)
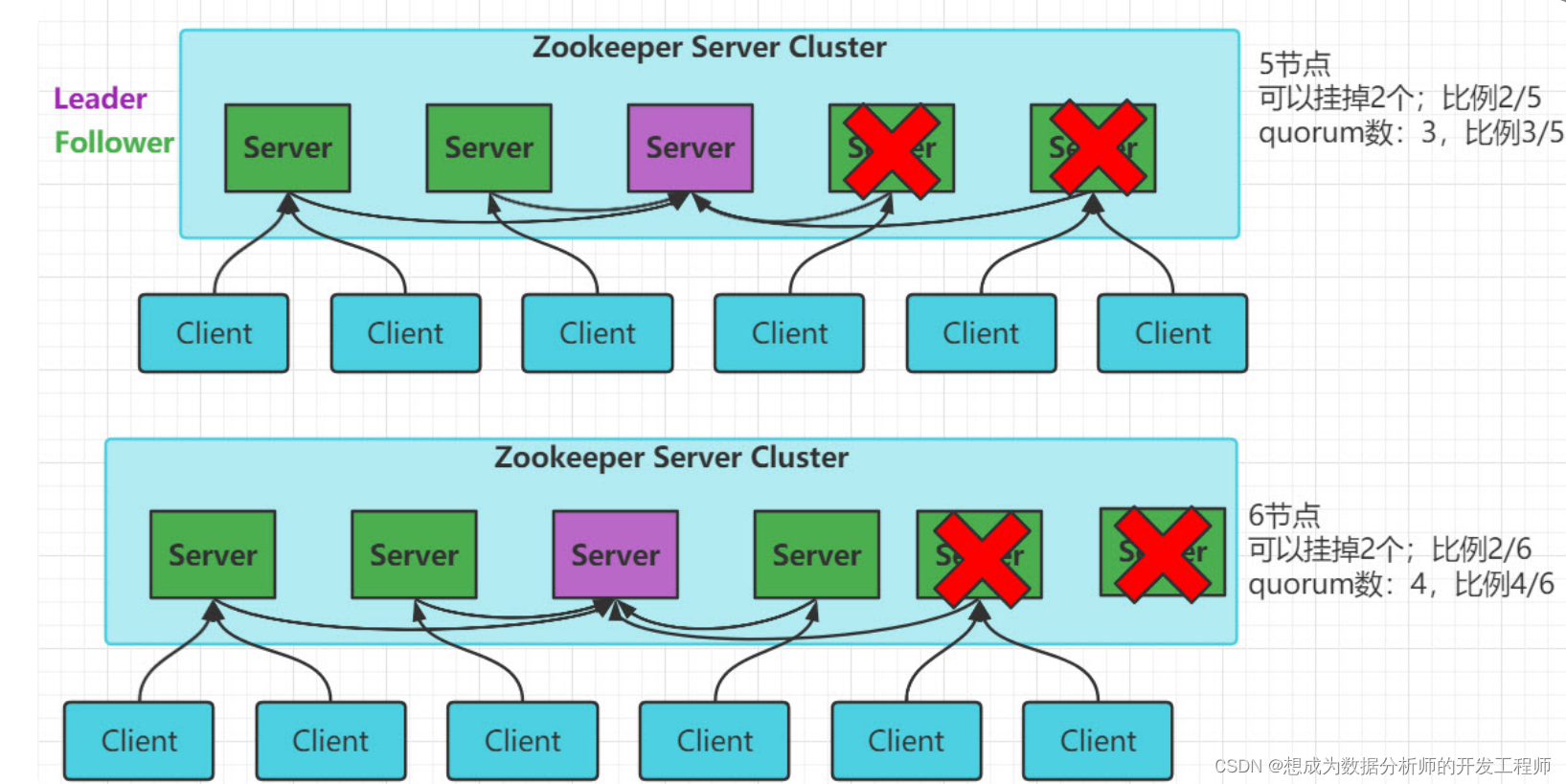
-
脑裂: