5.函数
创建类似oracle数据库的虚拟表dual,便于测试:
hive>create table dual(id string);
OK
Time taken: 0.219 seconds
hive> insert into dual values(" ");
hive> select * from dual;
5.1 内置函数
- 查看系统中自带的函数:
hive> show functions;
......
shiftrightunsigned
sign
sin
size
......
Time taken: 0.065 seconds, Fetched: 289
row(s)
- 显示自带函数的描述:
hive> desc function size;
OK
size(a) - Returns the size of a
Time taken: 0.081 seconds, Fetched: 1
row(s)
hive> desc function nvl;
OK
nvl(value,default_value) - Returns default
value if value is null else returns value
Time taken: 0.031 seconds, Fetched: 1
row(s)
- 查看函数详细信息,如何使用:
hive> desc function extended size;
OK
size(a) - Returns the size of a
Function
class:org.apache.hadoop.hive.ql.udf.generi
c.GenericUDFSize
Function type:BUILTIN
Time taken: 0.039 seconds, Fetched: 3
row(s)
hive> desc function extended nvl;
OK
nvl(value,default_value) - Returns default
value if value is null else returns value
Example:
> SELECT nvl(null,'bla') FROM src LIMIT
1;
bla
Function
class:org.apache.hadoop.hive.ql.udf.generi
c.GenericUDFNvl
Function type:BUILTIN
Time taken: 0.035 seconds, Fetched: 6
row(s)
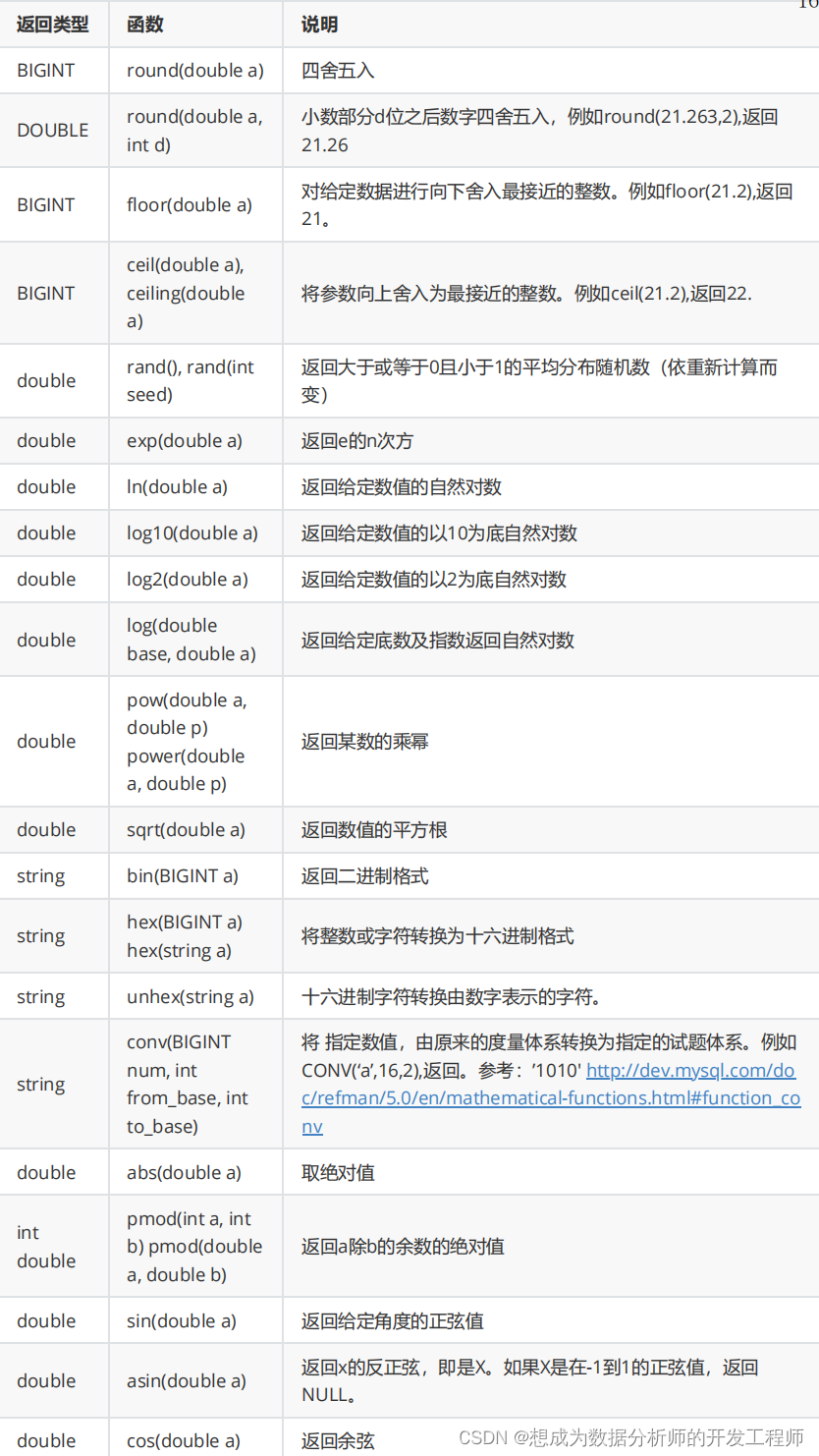
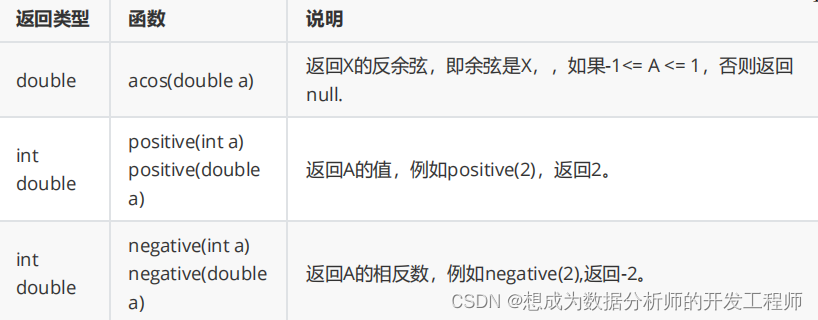
5.1.1 数学函数
5.1.2 收集函数——求元素个数

hive> select id,size(likes),size(address) from
person;
OK
1 3 2
2 3 2
3 3 2
4 3 2
5 2 2
6 3 2
7 2 2
8 2 2
9 3 2
Time taken: 0.252 seconds, Fetched: 9 row(s)
5.1.3 类型转换函数
Int->bigint自动转换,bigint->int需要强制类型

hive> select cast('123' as int) from dual;
OK
123
Time taken: 0.272 seconds, Fetched: 1 row(s)
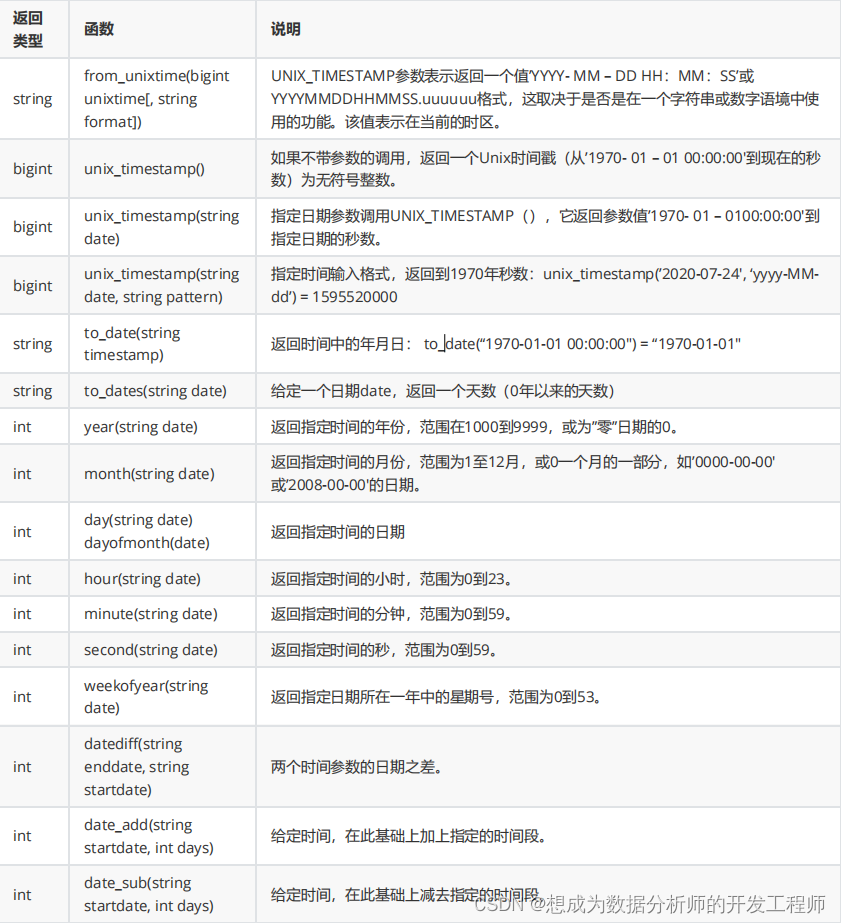
5.1.4 日期函数
hive> select unix_timestamp() from dual;
unix_timestamp(void) is deprecated. Use
current_timestamp instead.
unix_timestamp(void) is deprecated. Use
current_timestamp instead.
OK
1637213052
Time taken: 0.269 seconds, Fetched: 1 row(s)
hive> select current_timestamp() from dual;
OK
2021-11-18 13:24:43.195
Time taken: 0.262 seconds, Fetched: 1 row(s)
hive> select unix_timestamp('2021-11-18
13:24:43') from dual;
OK
1637241883
Time taken: 0.308 seconds, Fetched: 1 row(s)
hive> select from_unixtime(1637241883) from
dual;
OK
2021-11-18 13:24:43
Time taken: 0.289 seconds, Fetched: 1 row(s)
hive> select from_unixtime(1637241883,'yyyy-MMdd HH:mm:ss') from dual;
OK
2021-11-18 13:24:43
Time taken: 0.255 seconds, Fetched: 1 row(s)
hive> select from_unixtime(1637241883,'yyyy-MMdd') from dual;
OK
2021-11-18
Time taken: 0.227 seconds, Fetched: 1 row(s)
hive> select datediff('2021-11-18','2021-11-
17') from dual;
OK
1
Time taken: 0.297 seconds, Fetched: 1 row(s)
hive> select datediff('2021-11-18','2021-11-
19') from dual;
OK
-1
Time taken: 0.252 seconds, Fetched: 1 row(s)
hive> select datediff('2021-11-18','2021-11-
20') from dual;
OK
-2
Time taken: 0.279 seconds, Fetched: 1 row(s)
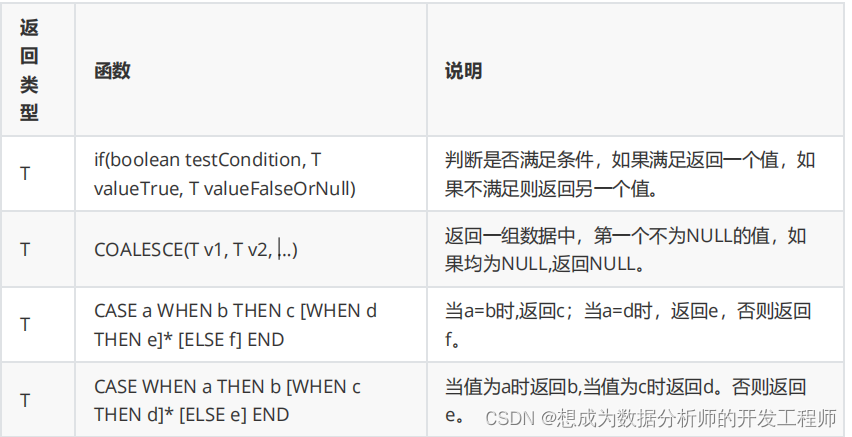
5.1.5 条件函数
hive> select if(True,1,2) from dual;
OK
1
Time taken: 0.35 seconds, Fetched: 1 row(s)
hive> select if(false,1,2) from dual;
OK
2
Time taken: 0.251 seconds, Fetched: 1 row(s)
hive> select if(False,1,2) from dual;
OK
2
Time taken: 0.244 seconds, Fetched: 1 row(s)
hive> select if(true,1,2) from dual;
OK
1
Time taken: 0.257 seconds, Fetched: 1 row(s)
hive> select coalesce("a","b","C") from dual;
OK
a
Time taken: 0.256 seconds, Fetched: 1 row(s)
hive> select coalesce(NULL,"b","C") from dual;
OK
b
Time taken: 0.265 seconds, Fetched: 1 row(s)
hive> select coalesce(NULL,null,"C") from dual;
OK
C
Time taken: 0.26 seconds, Fetched: 1 row(s)
case when案例:
select name,
case when birthday<'1970' then '50up'
when birthday<'1980' then '40-50'
when birthday<'1985' then '35-40'
when birthday<'1990' then '30-35'
when birthday<'1994' then '26-30'
when birthday<'2000' then '20-25'
else 'other' end
from hiveTable
5.1.6 字符串函数
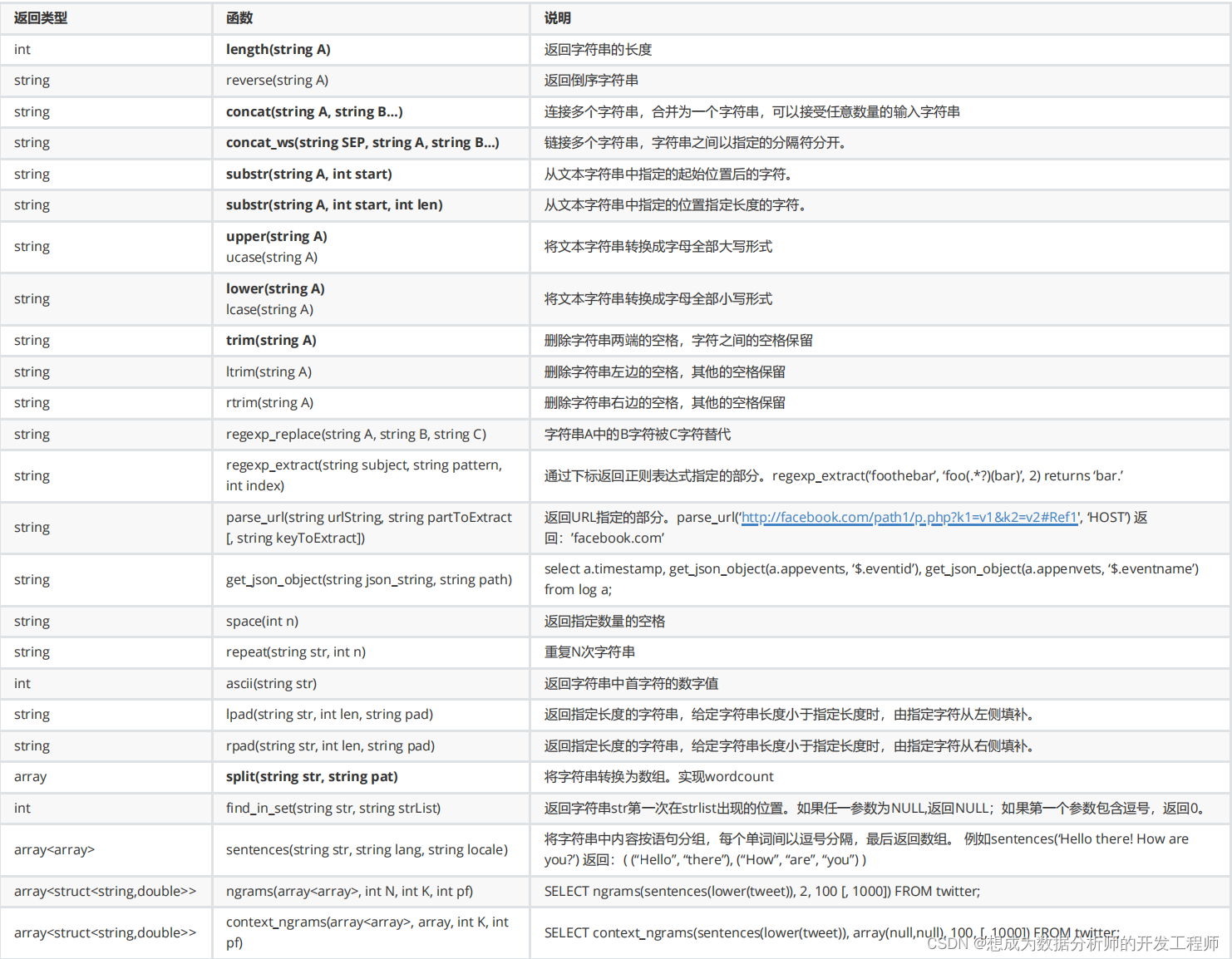
hive> select length("hello") from dual;
OK
5
Time taken: 0.327 seconds, Fetched: 1 row(s)
hive> select reverse("abc") from dual;
OK
cba
Time taken: 0.253 seconds, Fetched: 1 row(s)
hive> select concat(id,name) from person;
OK
1小明1
2小明2
3小明3
4小明4
5小明5
6小明6
7小明7
8小明8
9小明9
Time taken: 0.27 seconds, Fetched: 9 row(s)
hive> select concat(id,
"-"
,name) from person;
OK
1-小明1
2-小明2
3-小明3
4-小明4
5-小明5
6-小明6
7-小明7
8-小明8
9-小明9
Time taken: 0.273 seconds, Fetched: 9 row(s)
hive> select concat_ws("-"
,id,name) from
person;
FAILED: SemanticException [Error 10016]: Line
1:21 Argument type mismatch 'id': Argument 2 of
function CONCAT_WS must be "string or
array<string>", but "int" was found.
hive> select concat_ws(":",name,likes) from
person;
OK
小明1:lol:book:movie
小明2:lol:book:movie
小明3:lol:book:movie
小明4:lol:book:movie
小明5:lol:movie
小明6:lol:book:movie
小明7:lol:book
小明8:lol:book
小明9:lol:book:movie
Time taken: 0.261 seconds, Fetched: 9 row(s)
hive> select concat_ws("--"
,name,likes) from
person;
OK
小明1--lol--book--movie
小明2--lol--book--movie
小明3--lol--book--movie
小明4--lol--book--movie
小明5--lol--movie
小明6--lol--book--movie
小明7--lol--book
小明8--lol--book
小明9--lol--book--movie
Time taken: 0.233 seconds, Fetched: 9 row(s)
hive> select substr("[email protected]",5) from
dual;
OK
n@126.com
Time taken: 0.335 seconds, Fetched: 1 row(s)
hive> select substr("[email protected]",5,3) from
dual;
OK
n@1
Time taken: 0.237 seconds, Fetched: 1 row(s)
hive> select upper('abc') from dual;
OK
ABC
Time taken: 0.267 seconds, Fetched: 1 row(s)
hive> select upper('hello Peter') from dual;
OK
HELLO PETER
Time taken: 0.239 seconds, Fetched: 1 row(s)
hive> select ucase('hello Peter') from dual;
OK
HELLO PETER
Time taken: 0.251 seconds, Fetched: 1 row(s)
hive> select lower("HELLO PETER") from dual;
OK
hello peter
Time taken: 0.238 seconds, Fetched: 1 row(s)
hive> select lcase("HELLO PETER") from dual;
OK
hello peter
Time taken: 0.235 seconds, Fetched: 1 row(s)
hive> select trim(" gtjin ") from dual;
OK
gtjin
Time taken: 0.25 seconds, Fetched: 1 row(s)
hive> select lpad("gtjin",10,
"*") from dual;
OK
*****gtjin
Time taken: 0.282 seconds, Fetched: 1 row(s)
hive> select rpad("gtjin",10,
"*") from dual;
OK
gtjin*****
Time taken: 0.235 seconds, Fetched: 1 row(s)
hive> select split("tom peter lucy"," ") from
dual;
OK
["tom","peter","lucy"]
Time taken: 0.25 seconds, Fetched: 1 row(s)
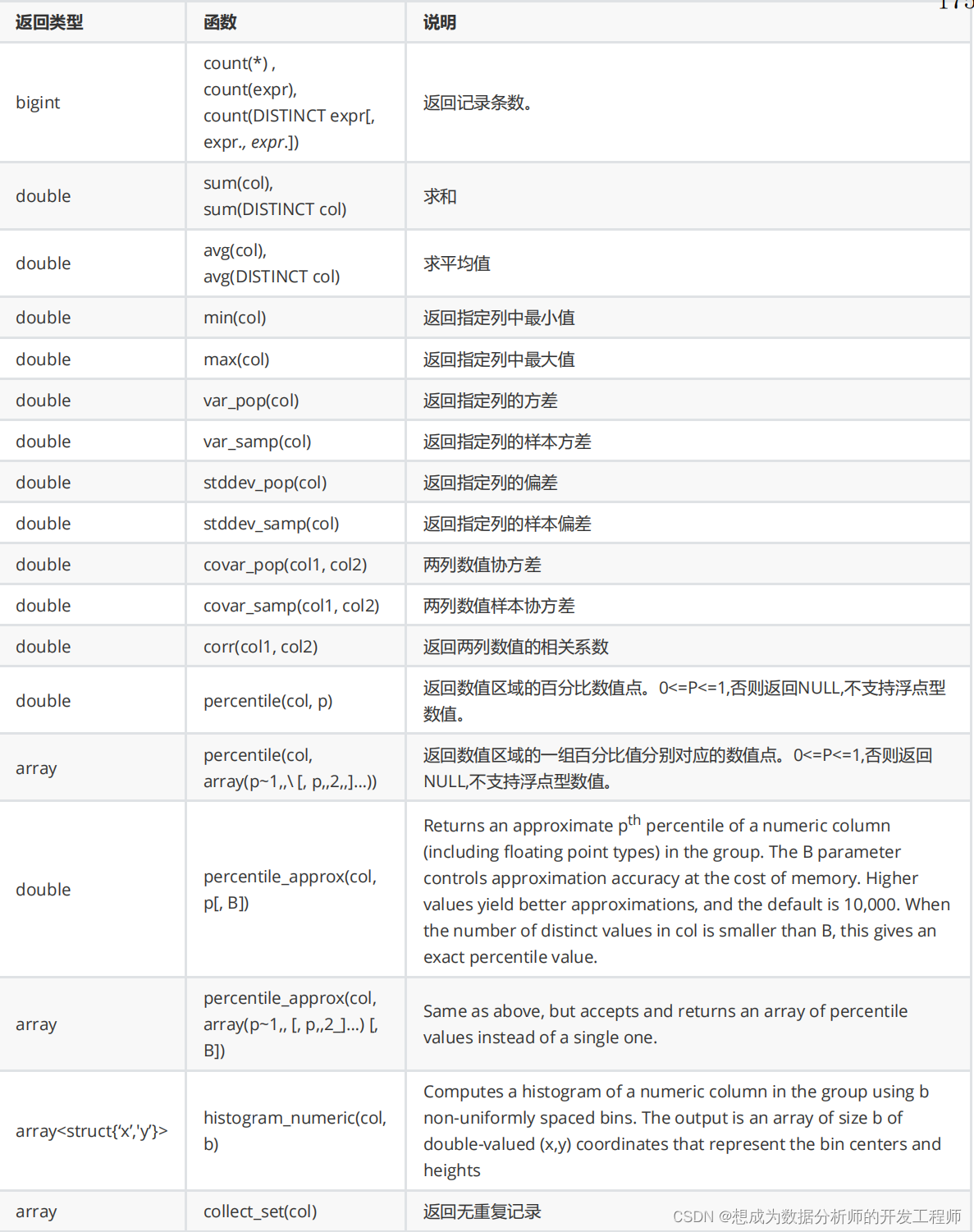
5.1.7 内置的聚合函数(UDAF)
多进一出:进来多个值,聚合后变成一个值。
5.1.8 内置表生成函数(UDTF)
一进多出:进来一个值,经过处理变成多个值出去。

hive> select explode(split("tom peter lucy","
")) from dual;
OK
tom
peter
lucy
Time taken: 0.248 seconds, Fetched: 3 row(s)
hive> select explode(likes) from person;
OK
lol
book
movie
lol
book
......
5.2 复杂函数
5.2.1 复杂类型函数
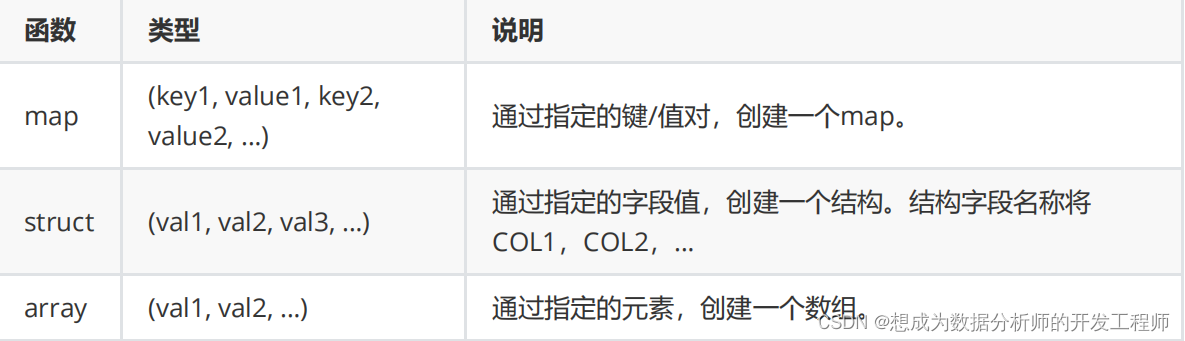
5.2.2 对复杂类型函数操作

hive> select id,name,likes[0],likes[1] from
person;
OK
1 小明1 lol book
2 小明2 lol book
3 小明3 lol book
4 小明4 lol book
5 小明5 lol movie
6 小明6 lol book
7 小明7 lol book
8 小明8 lol book
9 小明9 lol book
Time taken: 0.34 seconds, Fetched: 9 row(s)
hive> select id,name,address['beijing'] from
person;
OK
1 小明1 xisanqi
2 小明2 xisanqi
3 小明3 xisanqi
4 小明4 xisanqi
5 小明5 xisanqi
6 小明6 xisanqi
7 小明7 xisanqi
8 小明8 xisanqi
9 小明9 xisanqi
Time taken: 0.259 seconds, Fetched: 9 row(s)
5.3 自定义函数
5.3.1 自定义函数的开发步骤
https://cwiki.apache.org/confluence/display/Hive/HivePlugins
自定义函数包括三种UDF、UDAF、UDTF
- UDF(User-Defined-Function) 一进一出
- UDAF(User- Defined Aggregation Funcation) 聚集函数,多进一出。Count/max/min
- UDTF(User-Defined Table-Generating Functions) 一进多出,如lateral view explore()
使用方式 :在HIVE会话中add 自定义函数的jar文件,然后创建function继而使用函数
开发步骤:
- 创建maven项目,添加hive依赖
- 创建类继承XXX类,并实现相关方法
package com.example.hive.udf;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
public final class Lower extends UDF {
public Text evaluate(final Text s) {
if (s == null) {
return null; }
return new
Text(s.toString().toLowerCase());
}
}
- 将项目打成jar,上传到Linux服务器(node4)[并从服务器上传到hdfs文件系统的某目录下]
- 将jar包添加hive的classpath上(未上传到hdfs文件系统中的版本)
hive>add jar /xxx/xx.jar
- 使用命令创建函数
create function [db_name.]function_name as
class_name
[using jar|file|archive 'file_uri' [,
jar|file|archive 'file_uri'] ];
实例:
jar未上传到hdfs文件系统中的版本,需要4步:
create temporary function my_lower as
'com.example.hive.udf.Lower';
jar上传到hdfs文件系统中的版本,不需要4步:
create temporary function my_lower as
'com.example.hive.udf.Lower' using
/hdfspath/xxx.jar;
- 在select语句中使用
select my_lower(ename) from emp;
5.4 hive实现wordcount

- 数据准备
[root@node1 ~]# scp wc.txt node4:/root/data
wc.txt
[root@node4 data]# cat wc.txt
hello tom
andy joy
hello rose
hello joy
mark andy
hello tom
andy rose
hello joy
- 创建原始数据表
create table words(line string);
- 将数据文件wc.txt load到words表中:
hive> load data local inpath '/root/data/wc.txt' into table words;
Loading data to table default.words
OK
Time taken: 0.434 seconds
hive> select * from words;
OK
hello tom
andy joy
hello rose
hello joy
mark andy
hello tom
andy rose
hello joy
Time taken: 0.223 seconds, Fetched: 8 row(s)
- 编写sql语句,先将每行内容按照空格拆分
hive> select split(line,' ') from words;
OK
["hello","tom"]
["andy","joy"]
["hello","rose"]
["hello","joy"]
["mark","andy"]
["hello","tom"]
["andy","rose"]
["hello","joy"]
- 将数组的元素再次进行拆解
hive> select explode(split(line,' ')) from words;
OK
hello
tom
andy
joy
hello
rose
hello
joy
mark
andy
hello
tom
andy
rose
hello
joy
Time taken: 0.202 seconds, Fetched: 16 row(s)
- 按照单词进行分组,并统计数量
select word,count(word)
from (select explode(split(line,' ')) word
from words) tmp
group by word;
Total MapReduce CPU Time Spent: 7 seconds 510 msec
OK
andy 3
hello 5
joy 3
mark 1
rose 2
tom 2
- 创建结果表:
create table wc_count(word string,count int);
- 将统计出来的结果添加结果表中
from (select explode(split(line,' ')) word
from words) tmp
insert into wc_count
select word,count(word)
group by word;
- 结果查看
hive> select * from wc_count;
OK
andy 3
hello 5
joy 3
mark 1
rose 2
tom 2
Time taken: 0.974 seconds, Fetched: 6 row(s)
5.5 struct的使用
创建student表
create table student(
id int,
info struct<name:string,age:int>
)
row format delimited
fields terminated by ','
collection items terminated by ':';
向这个student表中插入数据
[root@node4 data]# vim stu.txt
1,tuhao:25
2,diaosi:26
3,baifumei:18
将数据加载到表中:
hive> load data local inpath
'/root/data/stu.txt' into table student;
Loading data to table default.student
OK
Time taken: 0.592 seconds
hive> select * from student;
OK
1 {
"name":"tuhao","age":25}
2 {
"name":"diaosi","age":26}
3 {
"name":"baifumei","age":18}
可以通过 struct.属性名来获取属性
hive> select id,info.name,info.age from
student;
OK
1 tuhao 25
2 diaosi 26
3 baifumei 18
Time taken: 0.311 seconds, Fetched: 3 row(s)