前言:
参考内容来自up:RCNN_哔哩哔哩_bilibili
up的代码和ppt:https://github.com/WZMIAOMIAO/deep-learning-for-image-processing
论文:
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
R-CNN详解
原文名称:Rich feature hierarchies for accurate object detection and semantic segmentation
R-CNN可以说是利用深度学习进行目标检测的开山之作。作者Ross Girshick多次 在PASCAL VOC的目标检测竞赛中折桂,曾在2010年带领团队获得终身成就奖。这篇RCNN是在2014年提出的,在此之前主流的都是传统的目标检测算法,基本都是认定定义特征的方法进行检测,传统的目标检测的准确率在30%左右,而RCNN的准确率直接跳到50%多。
RCNN算法流程可分为4个步骤 :
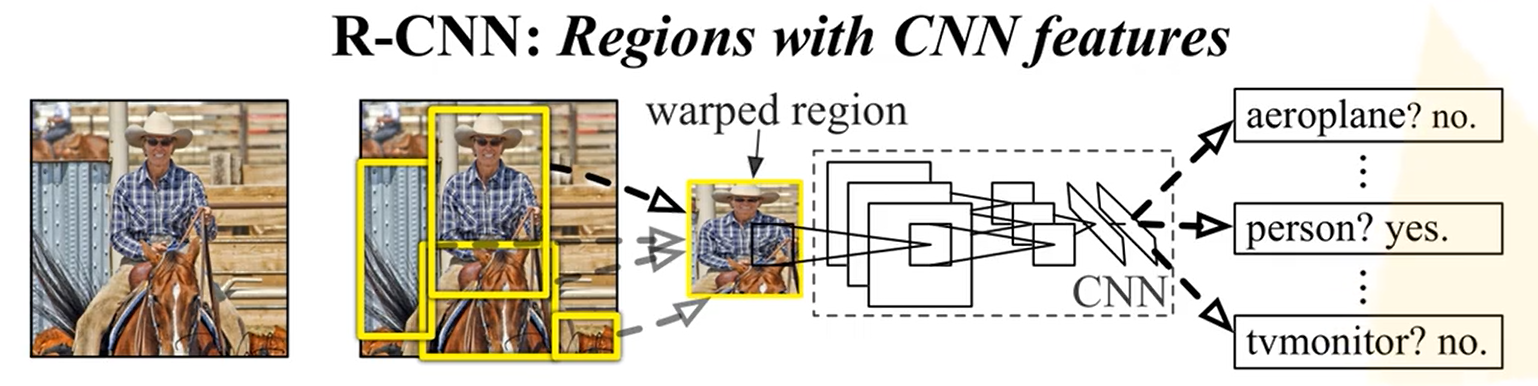
一张图像生成1K~2K个候选区域(使用Selective Search方法)
利用Selective Search算法通过图像分割的方法得到一些原始区域,然后使用一些合并策略将这些区域合并, 得到一个层次化的区域结构,而这些 结构就包含着可能需要的物体。
对每个候选区域,使用深度网络提取特征
将2000候选区域缩放到227x227pixel,这是因为AlexNet输入是固定的,接着 将候选区域输入事先训练好的AlexNet CNN网络 获取4096维的特征得到2000×4096维矩阵,每一行对应一个候选区域的特征向量。
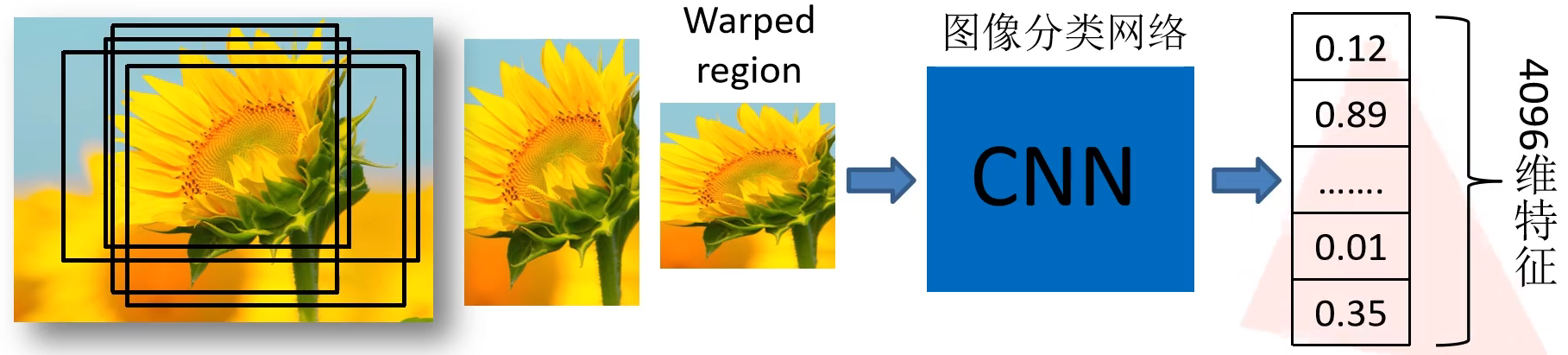
特征送入每一类的SVM 分类器(二分类),判别是否属于该类
将2000×4096维特征与20个SVM组成的权值矩阵4096×20相乘, 获得2000×20维矩阵表示每个建议框是某个目标类别的得分。分别 对上述2000×20维矩阵中每一列即每一类进行非极大值抑制剔除重 叠建议框,得到该列即该类中得分最高的一些建议框。

非极大值抑制:两个目标框的交并比,寻找得分最高的目标,直到所有的建议框遍历完
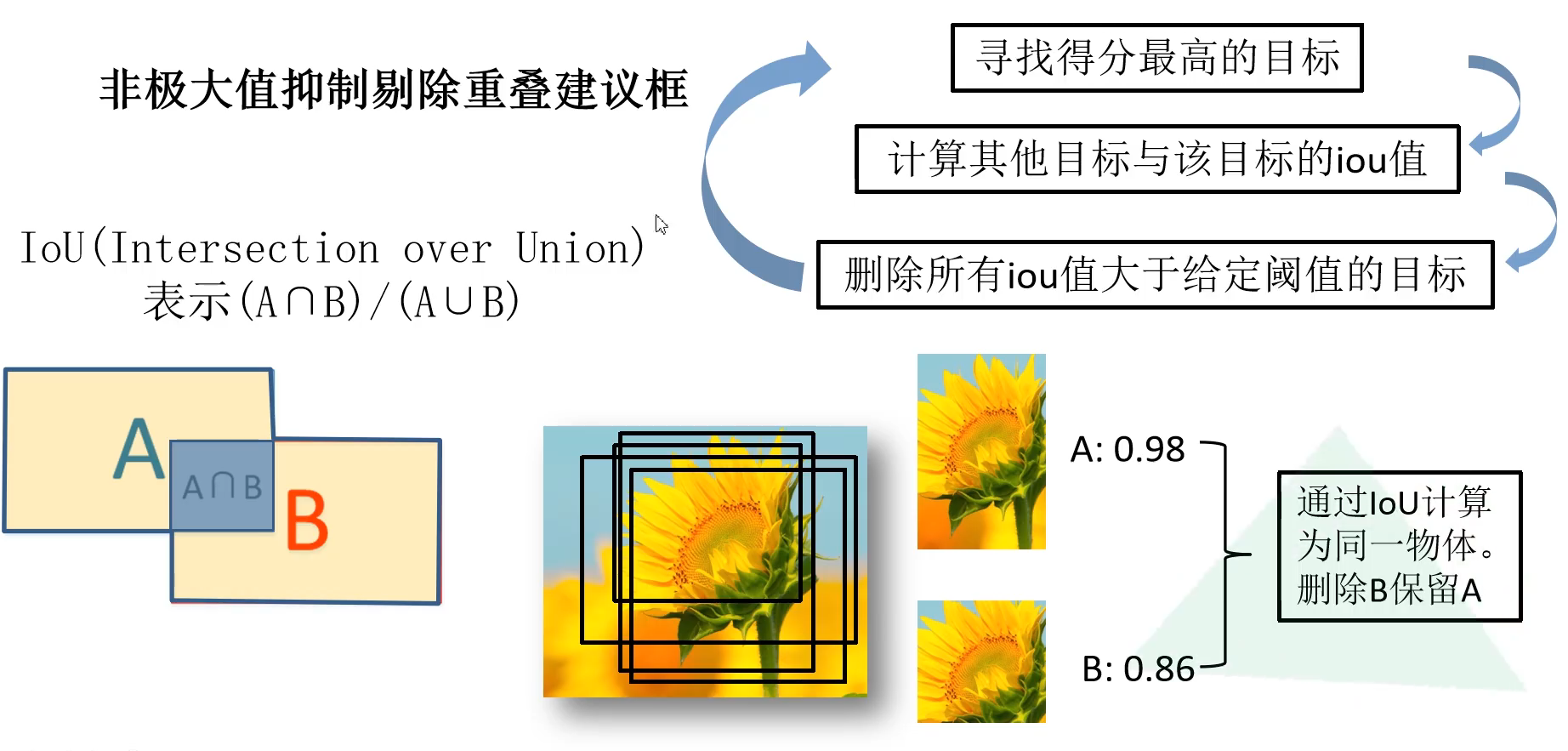
上图中向日葵的IoU都大于给定的阈值,说明都包含目标,所以保留IoU大的A,最终得到一个最完美的建议框
使用回归器精细修正候选框位置
依旧针对CNN输出的特征向量进行预测:即对每一个边界框所得到的4096维的特征向量来进行预测
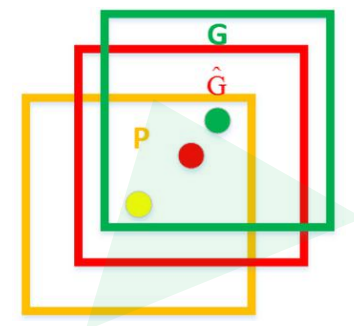
对NMS处理后剩余的建议框进一步筛选。接着分别 用20个回归器对上述20个类别中剩余的建议框进行回归操作,最终得到每个类别的修正后的得分最高的 bounding box。 如图,黄色框口P表示建议框Region Proposal:通过SS算法得到的目标建议框
绿色窗口G表示实际框Ground Truth:目标准确的边界框
红色窗口 表示Region Proposal进行回归后的预测窗口,可以用 最小二乘法解决的线性回归问题。(通过回归分类器可以得到4个参数,分别为目标建议框的中心点的x,y的偏移量和高度,宽度缩放因子),通过这4个参数对建议框进行调整就得红色的边界框
R-CNN的结构

在之后的Fast R-CNN和Faster R-CNN中会一步一步的融合,最后形成端对端的完整网络
R-CNN存在的问题 :
测试速度慢: 测试一张图片约53s(CPU)。用Selective Search算法 提取候选框用时约2秒,一张图像内候选框之间存在大 量重叠,提取特征操作冗余。
训练速度慢: 过程及其繁琐
训练所需空间大: 对于SVM和bbox回归训练,需要从每个图像中的每个目标候选框 提取特征,并写入磁盘。对于非常深的网络,如VGG16,从VOC07 训练集上的5k图像上提取的特征需要数百GB的存储空间。
Fast R-CNN详解
Fast R-CNN 主要是在R-CNN和SPPNet的基础上进行改进的,有着以下几个优点:
与R-CNN、SPPNet相比,有着更高的准确率。
通过使用多任务损失,将模型训练由多阶段转变为单阶段训练。
训练时可以一次更新网络的所有层,不再需要分步更新参数。
不再需要硬盘来存储CNN提取的特征数据
Fast R-CNN是作者Ross Girshick继R-CNN后的又一力作。同样使用VGG16作为网络 的backbone,与R-CNN相比训练时间快9倍,测试推理时间快213倍,准确率从 62%提升至66%(再Pascal VOC数据集上)。
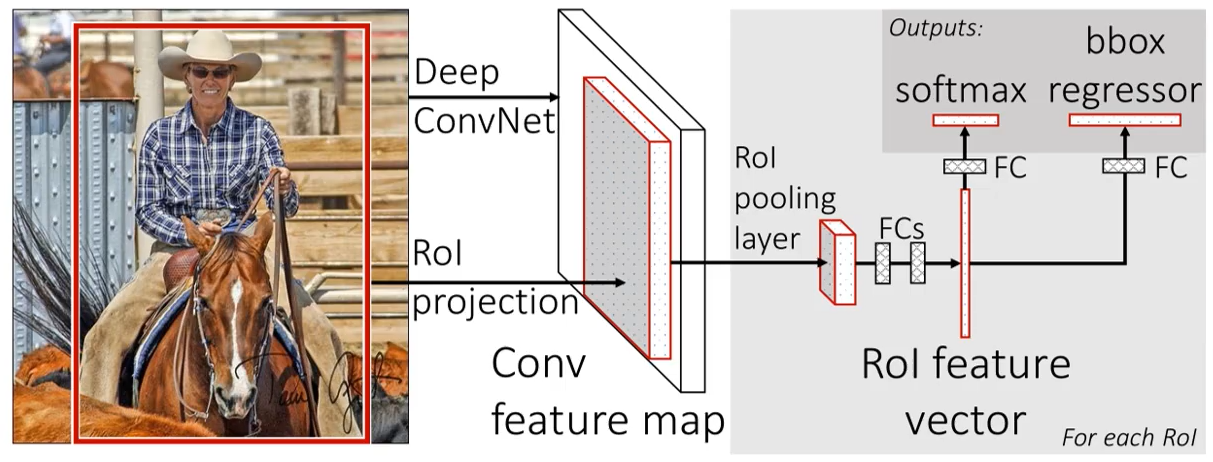
Fast R-CNN算法流程可分为3个步骤
一张图像生成1K~2K个候选区域(使用Selective Search方法)
将图像输入网络得到相应的特征图,将SS算法生成的候选框投影到特征图上获得相应的特征矩阵
(在训练过程中只是随机选取一部分进行训练)--------与之前不同
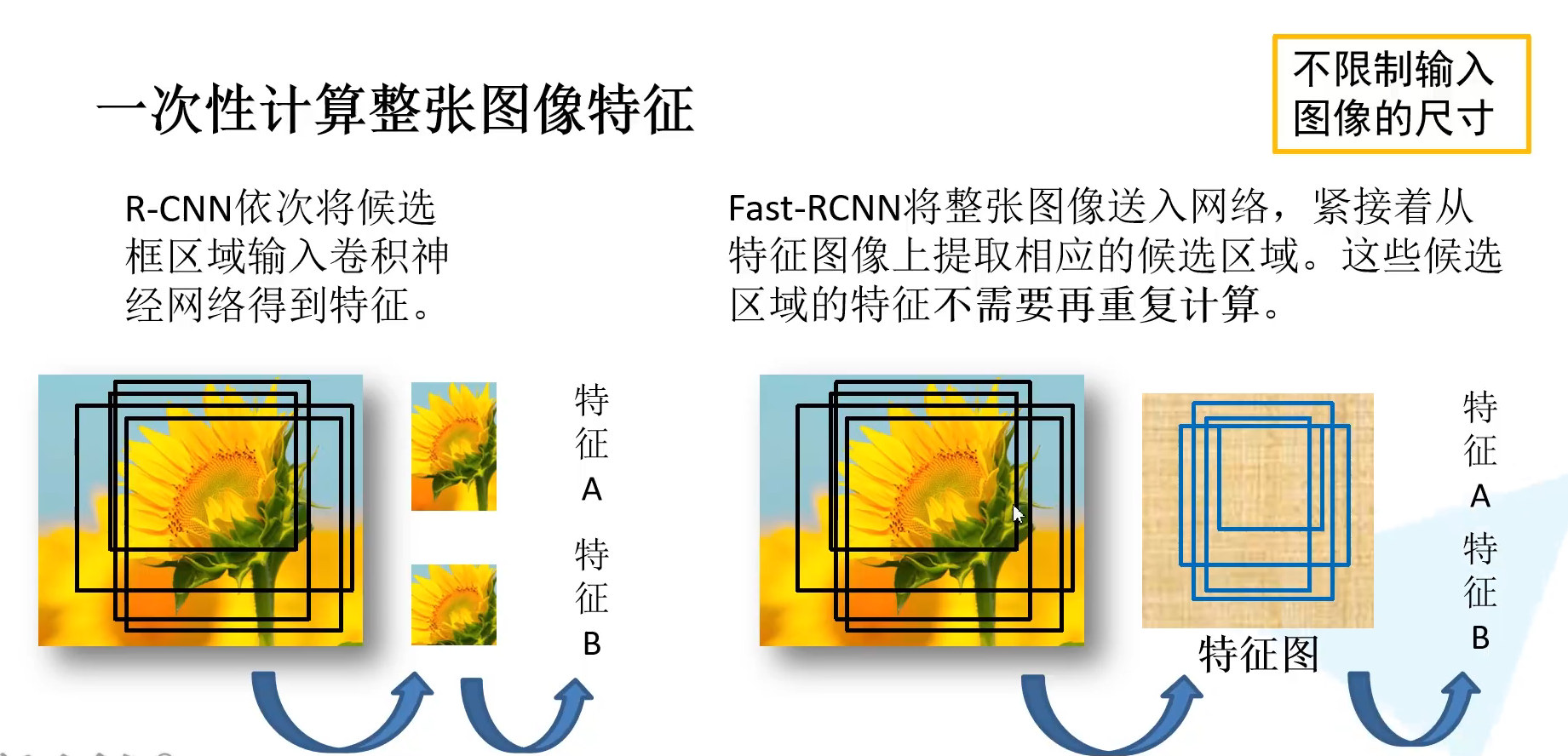
左边R-CNN:对每一个候选区域进行缩放,输入到网络中得到对应的特征,2k个候选框就需要2k次正向传播,存在大量冗余。
右边Fast-R-CNN:整张图输入网络就得到了特征图,参考的是SPPNet,在通过每个候选区域原图和特征图的映射关系,就能在特征图中直接获取到特征矩阵,这些候选区域的特征就不需要重复计算了,能大幅提升计算过程。
为什么要分正负样本?:因为如果全为正样本的话,网络就会有很大的概率认为检测的就是目标,所以就要区分正负样本
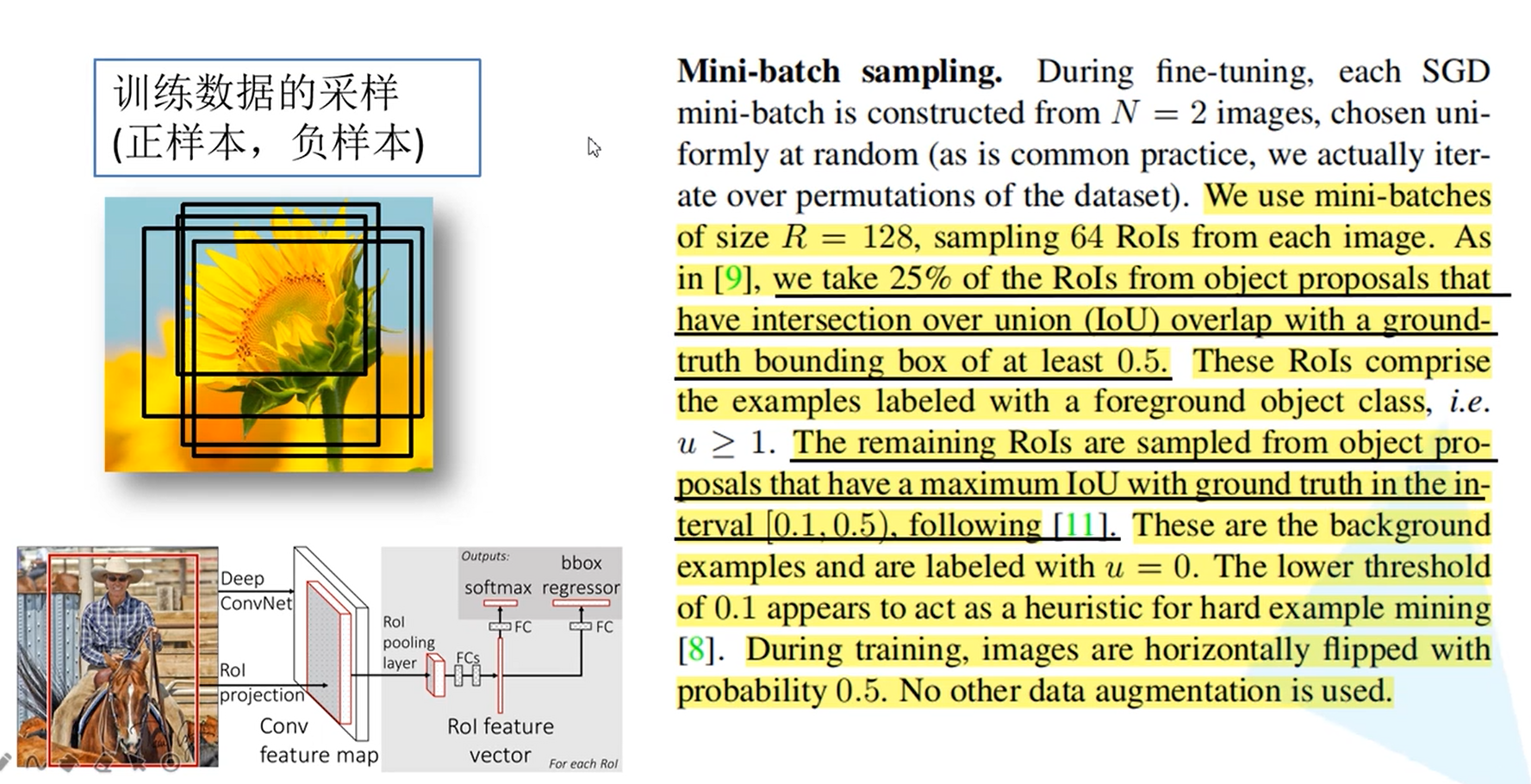
如上图:原文中从2000个候选框中取64个候选区,其中一部分是正样本(IoU大于0.5),使用是随机选取一部分;一部分是负样本(IoU在0.1到0.5之间的)
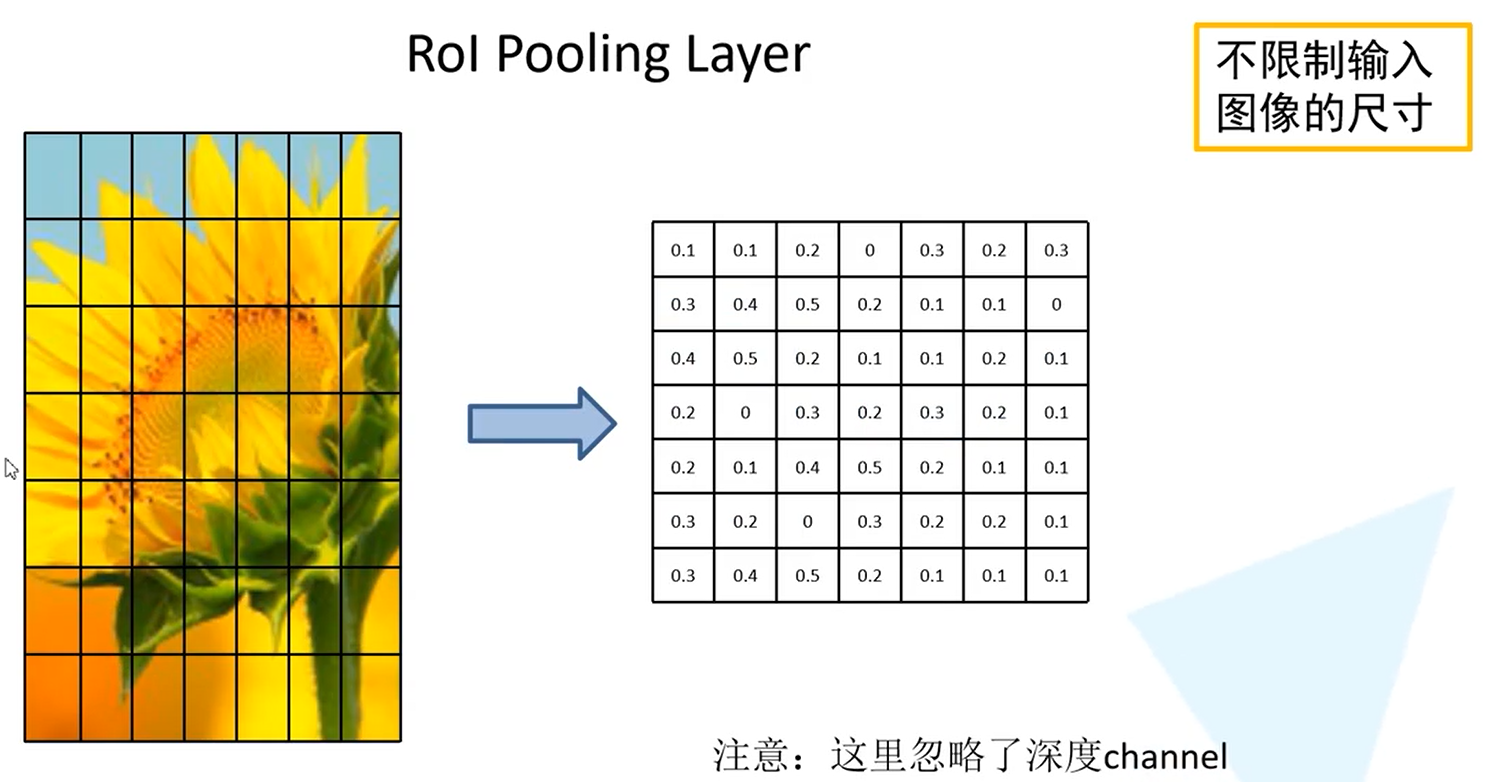
将每个特征矩阵通过ROI pooling层缩放到7x7大小的特征图,接着将特征图展平通过一系列全连接层得到预测结果-----------与之前不同
示例:将得到的特征举证划分为7*7,49等分,然后对每一个区域进行最大池化下采样,得到一个7*7的特征矩阵,无论候选区域的特征矩阵是什么样的,都缩放到7*7大小,就可以不限制输入图像的尺寸
重点:
分类器:下图蓝色框中的部位,这个概率是经过softmax处理后的,所以满足概率分布,即和为1,需要N+1个概率,所以图中的FC全连接层就需要N+1个节点。

边界框回归器:下中蓝色的部分,也是一个全连接层,每个类别都有4个参数,一共有(N+1)*4
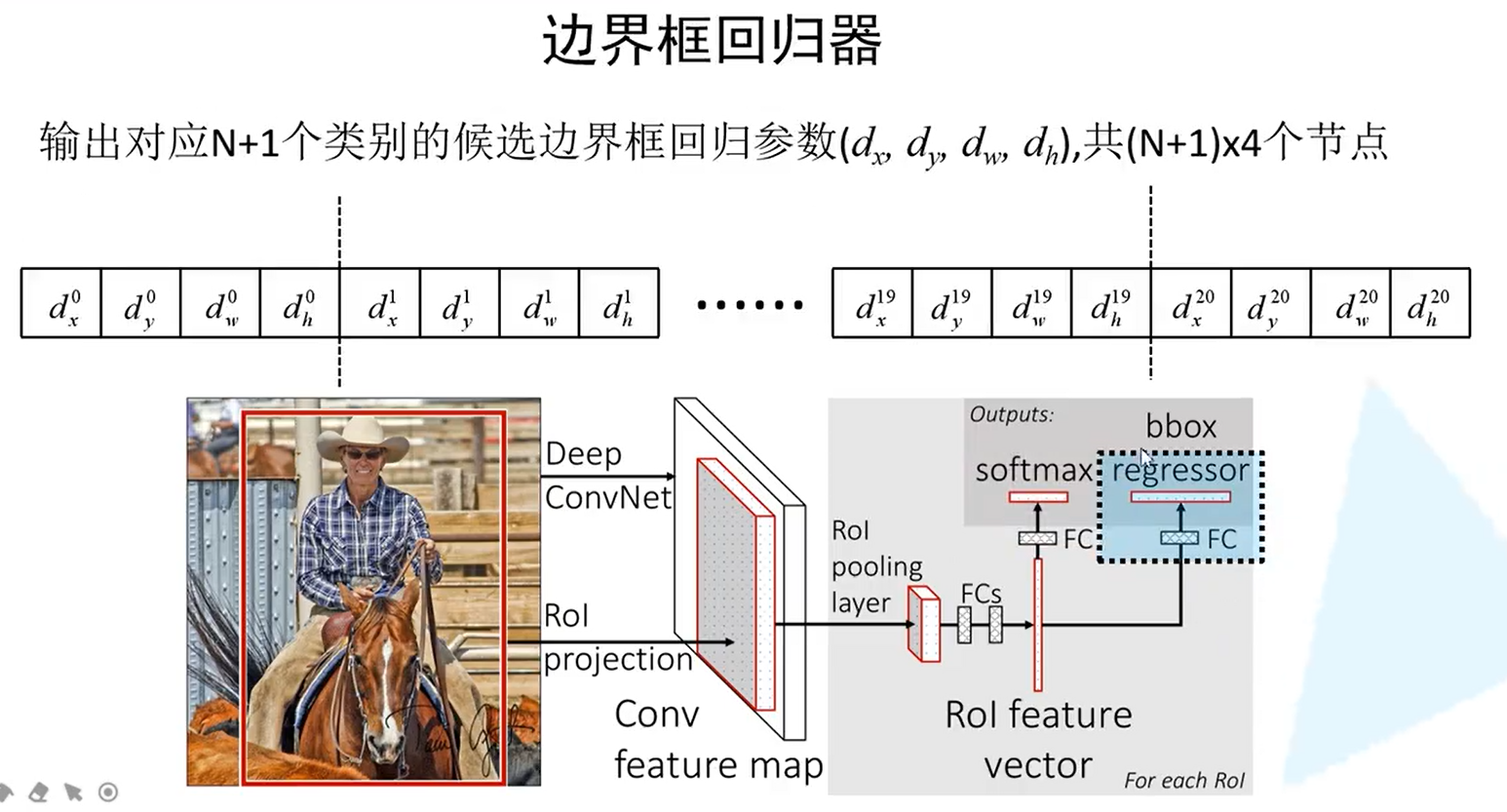
如何利用回归参数得到最终的边界框?
dx和dy是用来调整中心坐标的
exp是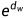 的意思,所以dw和dh分别对应宽度和高度回归参数,就可以将边界框从黄色调整到红色的位置
的意思,所以dw和dh分别对应宽度和高度回归参数,就可以将边界框从黄色调整到红色的位置

损失计算:总损失=分类损失+边界框回归损失

分类损失如何计算:

边界框回归损失:

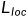 由四部分组成,为4组smooth函数数据相加的值
由四部分组成,为4组smooth函数数据相加的值
[u>=1]艾弗森括号:u>=1 [ ] = 1 对应正样本时才有回归损失
u<1 [ ] = 0 负样本,对应当前区域为背景时为0
Fast R-CNN的结构

Faster R-CNN详解
Faster R-CNN是作者Ross Girshick继Fast R-CNN后的又一力作。同样使用VGG16作 为网络的backbone,推理速度在GPU上达到5fps(包括候选区域的生成),准确率 也有进一步的提升。在2015年的ILSVRC以及COCO竞赛中获得多个项目的第一名。
Faster RCNN可以看作 RPN+Fast RCNN,其中RPN使用CNN来生成候选区域,并且RPN网络可以认为是一个使用了注意力机制的候选区域选择器,具体的网络结构如下图所示:
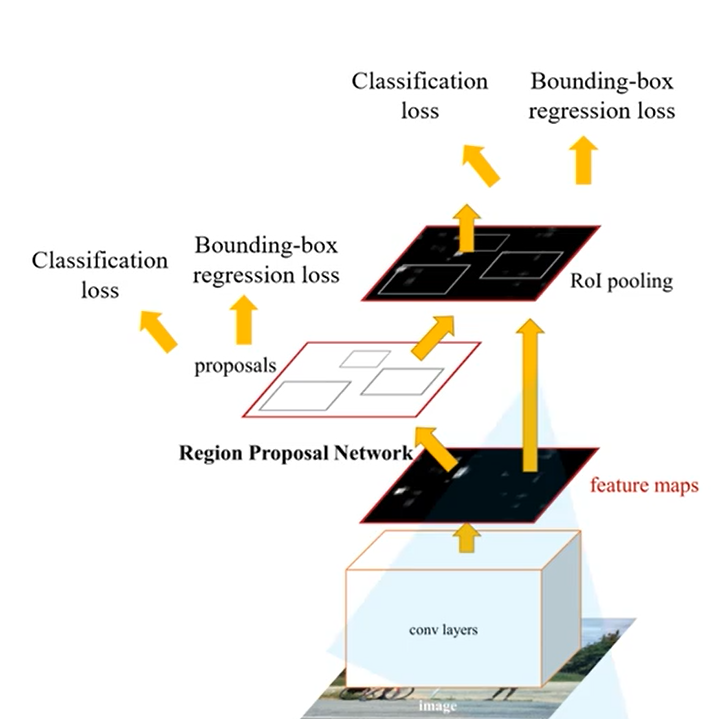
这里主要介绍RPN,其他部分和之前的Fast-R-CNN时一样的

Faster R-CNN算法流程可分为3个步骤
将图像输入网络得到相应的特征图
使用RPN结构生成候选框,将RPN生成的候选框投影到 特征图上获得相应的特征矩阵
将每个特征矩阵通过ROI pooling层缩放到7x7大小的特征图, 接着将特征图展平通过一系列全连接层得到预测结果
RPN详解
下图为原文中RPN 的结构
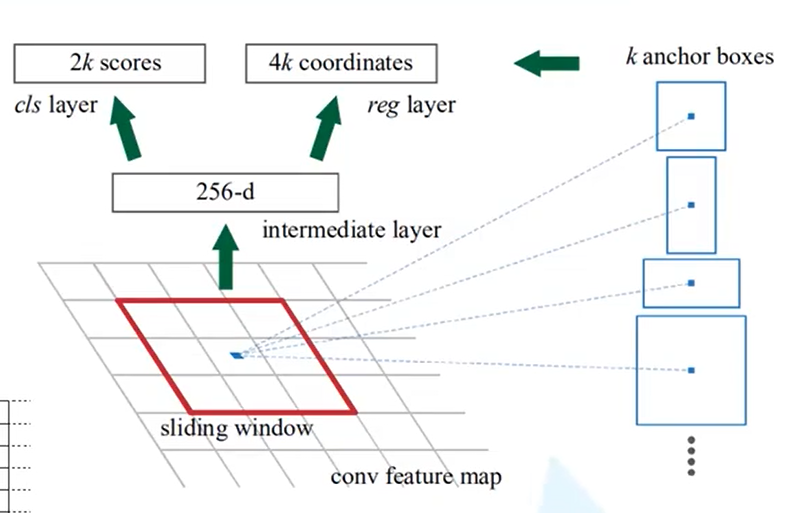
feature map 即通过卷积层的特征图,在特征图上使用一个滑动窗口,每滑动到一个位置就生成一个一维的向量,在这个向量的基础上通过两个全连接层分别输出它的目标概率和边界框回归参数
2kscores是针对k个anchor boxes的,2k就是针对每一个anchor生成的两个概率,一个是它为背景的概率,一个是它为前景的概率
针对每个anchor又会生成4个边界框回归参数,即4k
256-d:在使用ZF网络是,因为它的特征图的深度即channer是256,如果使用VGG-16的话此处应该为512,所以上图中一维向量的个数是根据使用的backbone的输出特征矩阵的深度来确定的
什么是anchor?
对于特征图上的每一个3*3的滑动窗口,首先计算它的中心点在原图上所对应的位置:
首先找到原图上的这个点
找x坐标:原图的宽度/特征图的宽度 取整得到一个步距,如下图右侧,中心点在第三个位置,则用步距*3就得到在原图上对应的x坐标,y坐标同理
在以这个点为中心计算出k个anchor boxes,这个的anchor boxes都是给定的大小和长宽比,下图中画出了3个

例:
如下图连线位置为计算的中心坐标,以这个点为中心生成一系列anchor,这个anchor中可能包含需要检测的目标,也可能没有

下面说明2kscores个4k个coordinates是怎么影响anchor的
假设下图cls为生成的2kscores,reg为4k个回归参数

如下图所示:
上面的一个箭头:第一对scores判断当前区域为背景和前景的概率,这里不分类,不管是人还是车,都会检测出来
第二个箭头:第一组coordinate,
 和
和 是中心点的偏移量,
是中心点的偏移量,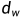 和
和 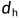 是对anchor宽度和高度的一个调整,通过边界框回归参数要尽可能的框选出目标
是对anchor宽度和高度的一个调整,通过边界框回归参数要尽可能的框选出目标
为什么有不同大小,不同尺寸的anchor:因为目标的大小不同

原文中给出的尺度和比例
128,256,512尺度分别对应有3个anchor,共3*3=9个
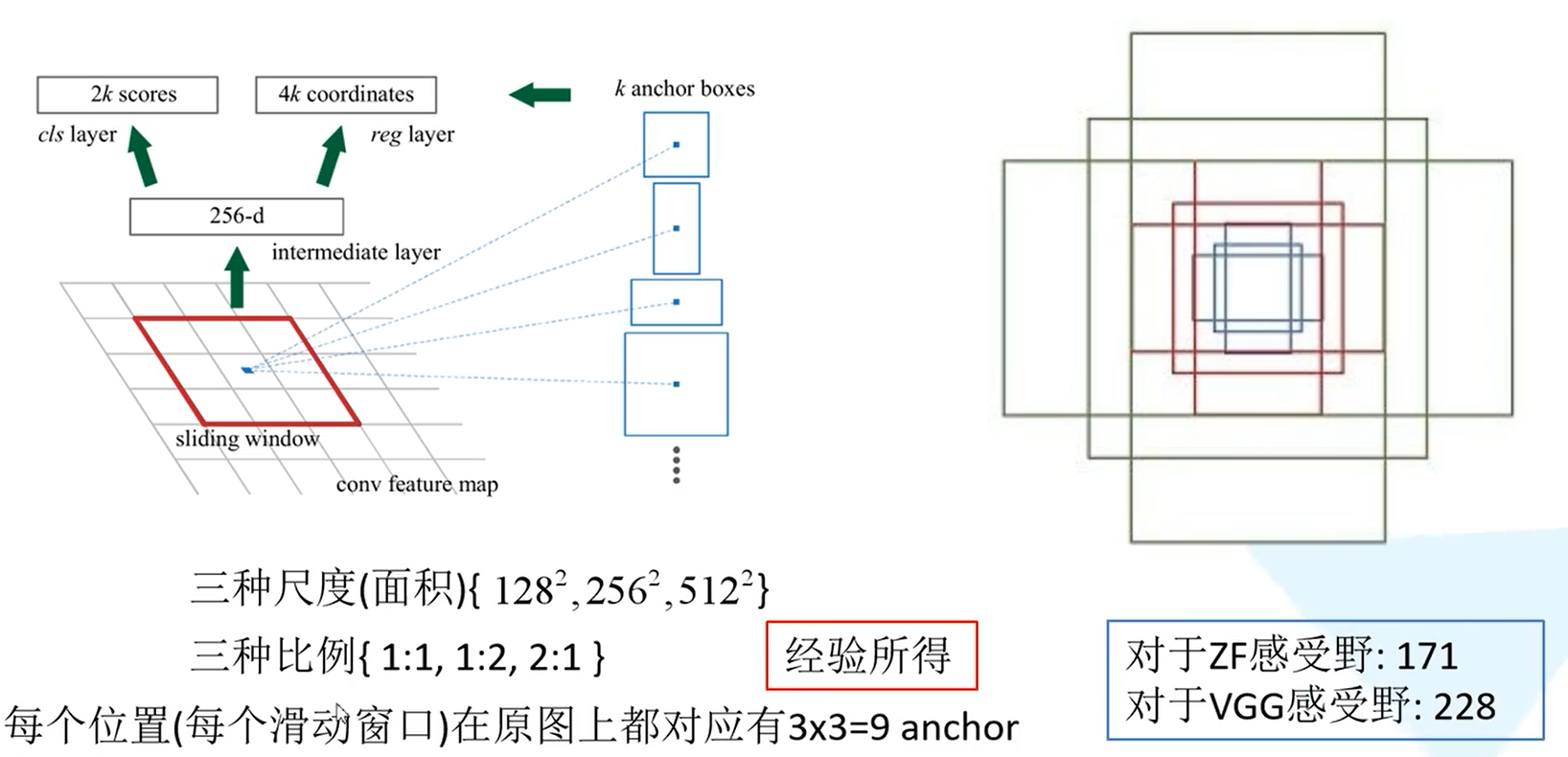
3*3滑动窗口在原图上感受野的问题:
比如使用VGG网络,它在原图上的感受野是228*228的,但为什么还能预测比它大的目标的边界框?
作者的解释:通过一个小的感受野去预测一个比它大的目标的边界框是有可能的,因为通过经验,可以由目标的一部分判断出目标的类别和区域

计算ZF网络的感受野:
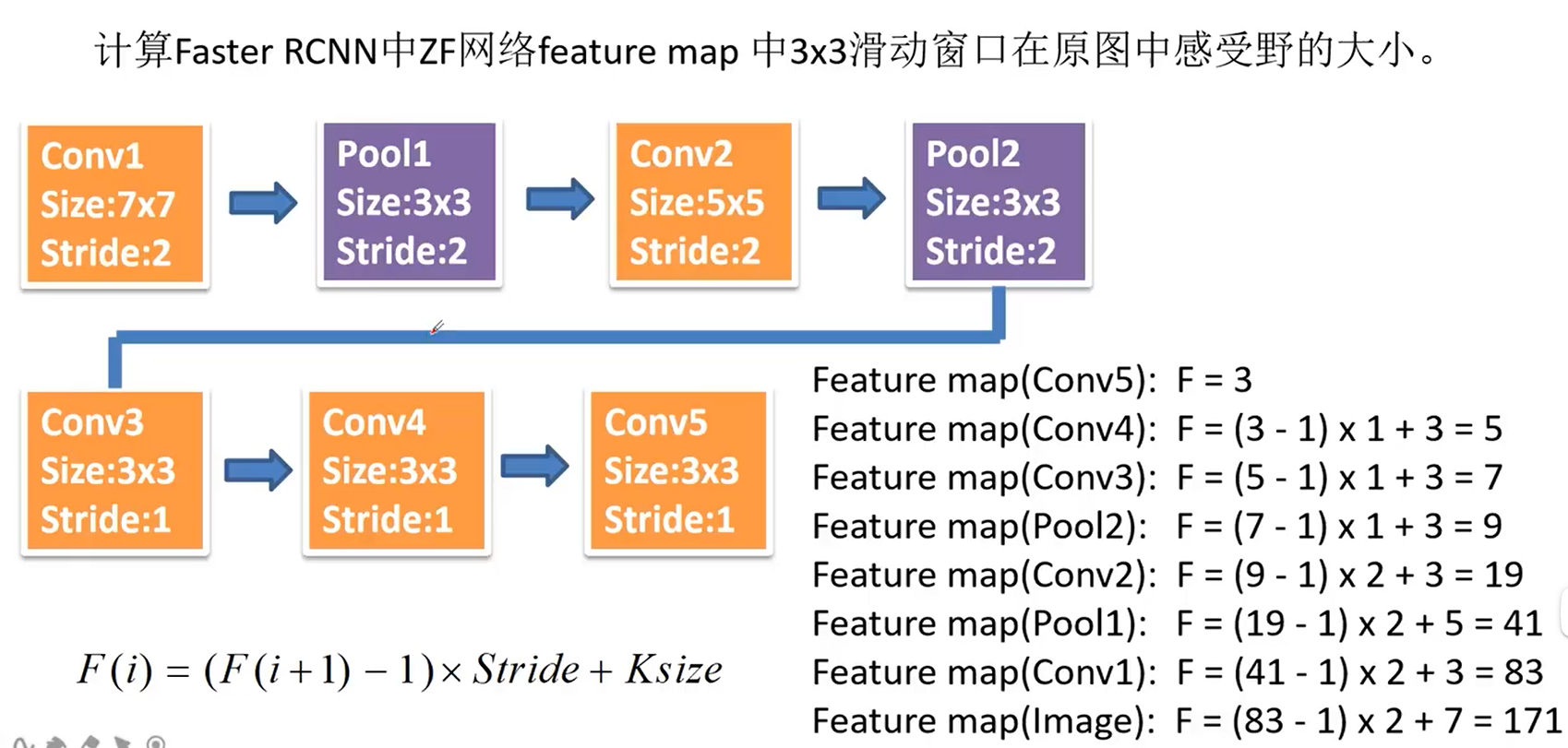
对于一张1000*600的图像,通过特征提取后为60*40的大小,60*40*9大概20k个anchor
anchor和候选框不是一个东西!!!要通过RPN生成的边界框回归参数将anchor调整到需要的候选框
再经过非极大值抑制算法得到2k个候选框就和SS算法得到的差不多了

RPN网络是如何实现的:

滑动窗口使用3*3的卷积处理,采用步距和padding都为1,这样滑动窗口就能将每一个点都覆盖到,通过3*3卷积就得到了高度宽度和feature map一样的特征矩阵,深度也和feature map一样的
在得到的特征矩阵上并联两个1*1的卷积层来实现类别的预测和边界框回归参数的预测,
左边的类别:可以采用卷积核大小为1*1,卷积核个数为2k的卷积层处理,
右边的参数:可以采用卷积核大小为1*1,卷积核个数为4k的卷积层处理.
选择的anchor数:原文中给出
选取256个anchor,一个是正样本,一半是负样本,如果正样本的个数不足128,就用负样本来填充

选择正样本:如下图
ii:IoU大于0.7就作为正样本
i:是ii的补充,anchor和ground-truth真实标注IoU最大的也作为正样本
负样本:anchor和ground-truth真实标注IoU小于0.3
其他的anchor舍弃

RPN损失计算:包含两部分
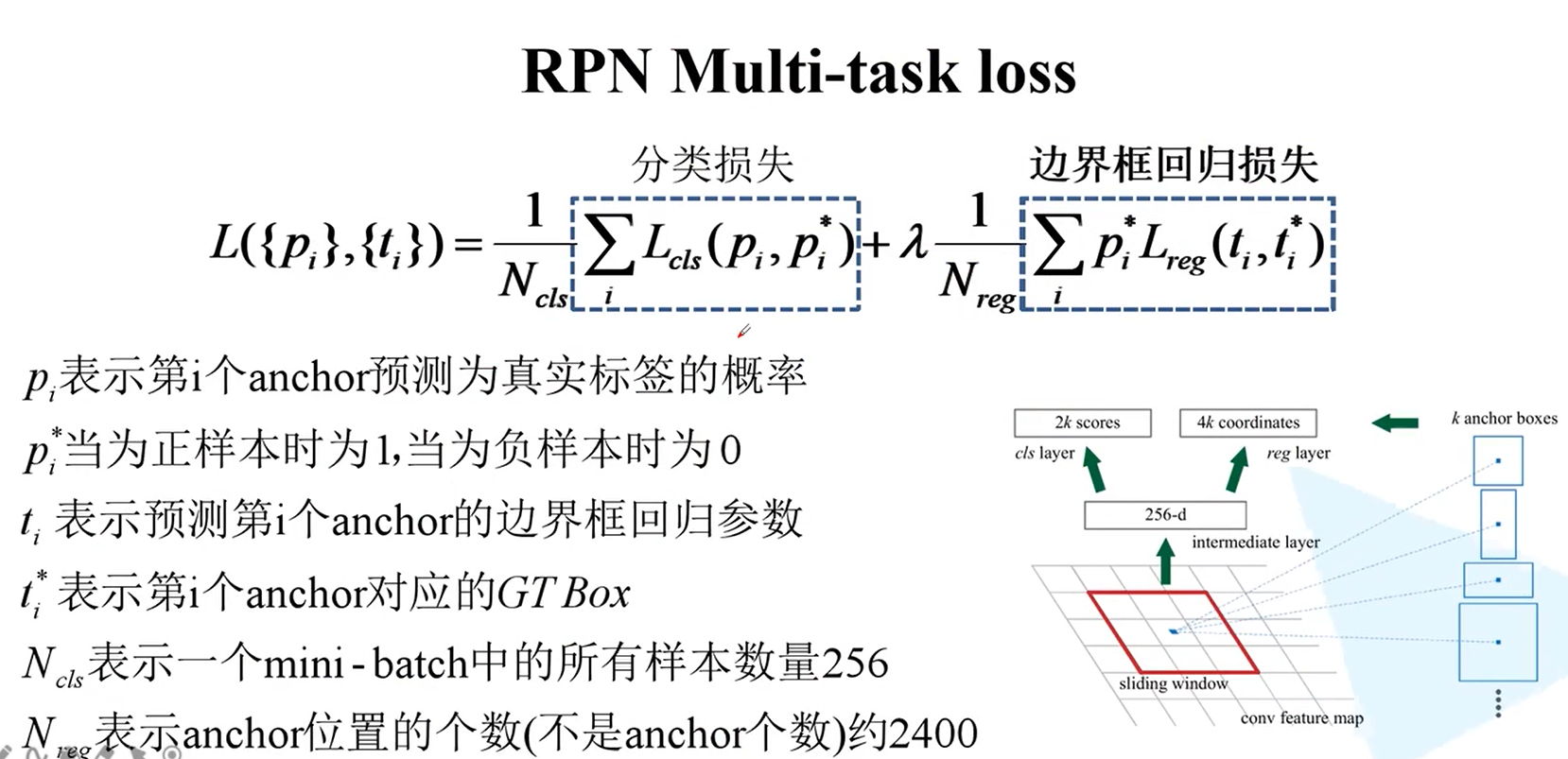
公式化简:将后面的替换为前面的

分类损失:原文使用多类别的交叉熵损失计算方法

二值交叉熵损失计算方法:使用k个参数,pytorch官方使用的是二值交叉熵损失

边界框回归损失:

Fast-R-CNN损失的计算:

Fasert-R-CNN是如何进行训练的:直接使用联合训练方法,将两部分损失加在一起直接进行反向传播

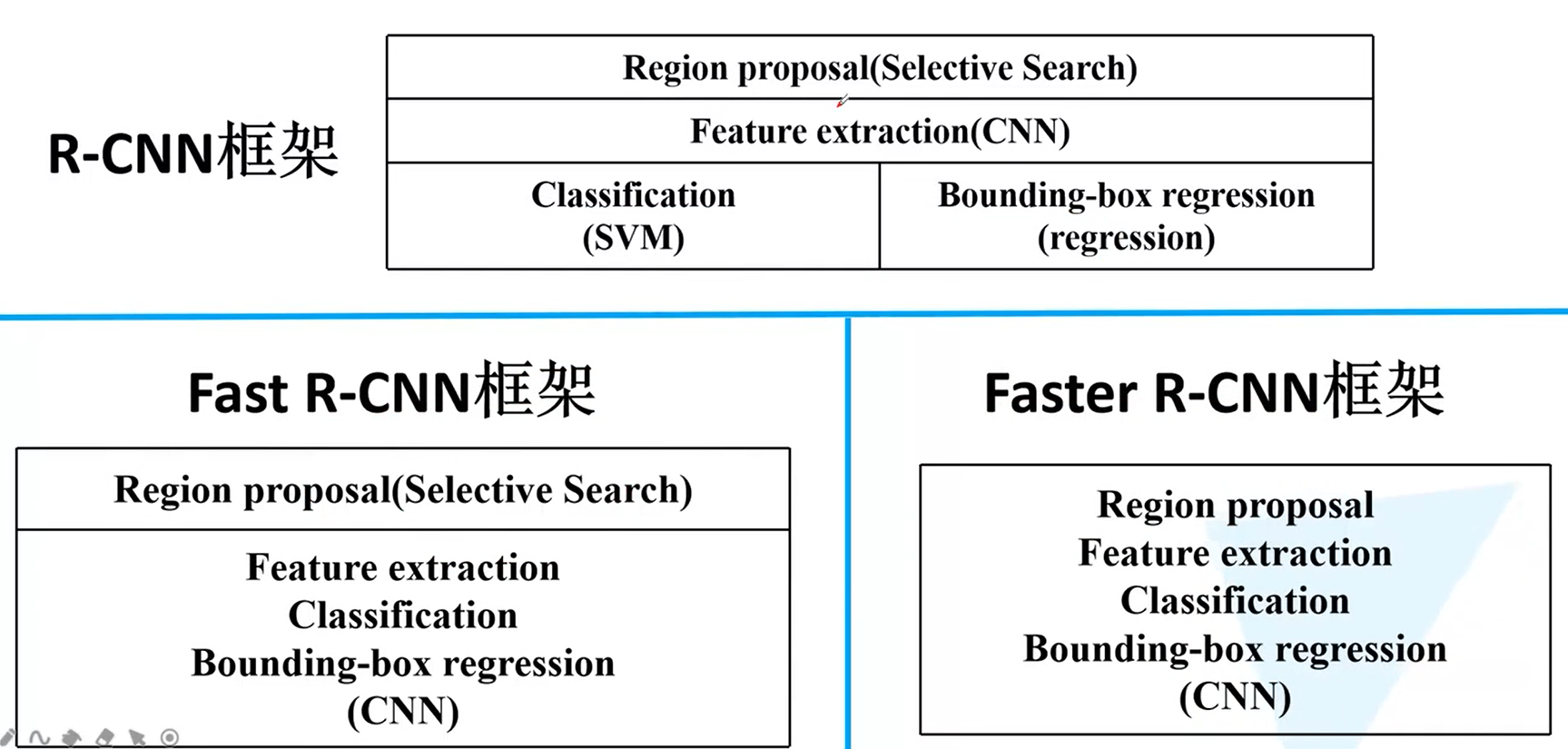
Faster R-CNN的结构:是一个整体,实现了端对端的过程

对比:框架越来越简单,效果也越来越好
代码
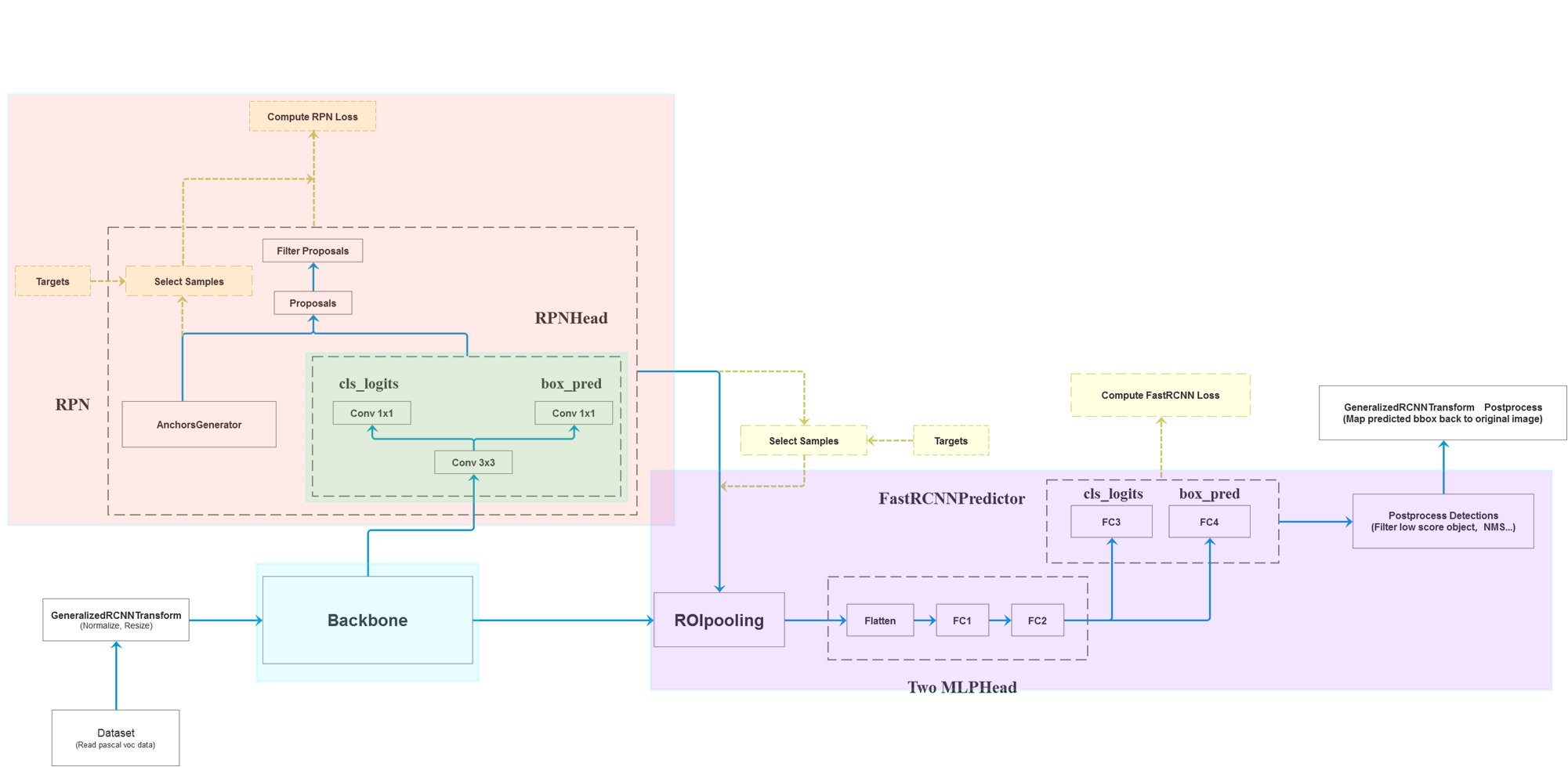
faster_rcnn_framework
import warnings
from collections import OrderedDict
from typing import Tuple, List, Dict, Optional, Union
import torch
from torch import nn, Tensor
import torch.nn.functional as F
from torchvision.ops import MultiScaleRoIAlign
from .roi_head import RoIHeads
from .transform import GeneralizedRCNNTransform
from .rpn_function import AnchorsGenerator, RPNHead, RegionProposalNetwork
class FasterRCNNBase(nn.Module):
"""
Main class for Generalized R-CNN.
Arguments:
backbone (nn.Module):
rpn (nn.Module):
roi_heads (nn.Module): takes the features + the proposals from the RPN and computes
detections / masks from it.
transform (nn.Module): performs the data transformation from the inputs to feed into
the model
"""
#区域建议生成网络
def __init__(self, backbone, rpn, roi_heads, transform): #初始化
super(FasterRCNNBase, self).__init__()
self.transform = transform
self.backbone = backbone
self.rpn = rpn
self.roi_heads = roi_heads
# used only on torchscript mode
self._has_warned = False
@torch.jit.unused
def eager_outputs(self, losses, detections):
# type: (Dict[str, Tensor], List[Dict[str, Tensor]]) -> Union[Dict[str, Tensor], List[Dict[str, Tensor]]]
if self.training:
return losses
return detections
def forward(self, images, targets=None):
# type: (List[Tensor], Optional[List[Dict[str, Tensor]]]) -> Tuple[Dict[str, Tensor], List[Dict[str, Tensor]]]
#输入的是一个list,其中的每一个图片是tensor,这里输入的图片大小都是不一样的,后面会进行预处理,将这些图片放入同样大小的tensor中打包成一个batch
#targets是字典类型,包含每个图片的标注信息
"""
Arguments:
images (list[Tensor]): images to be processed
targets (list[Dict[Tensor]]): ground-truth boxes present in the image (optional)
Returns:
result (list[BoxList] or dict[Tensor]): the output from the model.
During training, it returns a dict[Tensor] which contains the losses.
During testing, it returns list[BoxList] contains additional fields
like `scores`, `labels` and `mask` (for Mask R-CNN models).
"""
#对传入的数据进行检查
if self.training and targets is None: #判断是否为训练模式
raise ValueError("In training mode, targets should be passed")
if self.training:
assert targets is not None
for target in targets: # 进一步判断传入的target的boxes参数是否符合规定
boxes = target["boxes"]
if isinstance(boxes, torch.Tensor): #检查boxes是否是tensor格式
if len(boxes.shape) != 2 or boxes.shape[-1] != 4:
raise ValueError("Expected target boxes to be a tensor"
"of shape [N, 4], got {:}.".format(
boxes.shape))
#[N, 4] N对应图像中有多少个目标,对应多少个边界框,左上角的xy坐标,右下角的xy坐标
else:
raise ValueError("Expected target boxes to be of type "
"Tensor, got {:}.".format(type(boxes)))
original_image_sizes = torch.jit.annotate(List[Tuple[int, int]], [])
#一个空列表,存储每张图像的原始尺寸 对变量进行声明,声明它是list类型
for img in images:
val = img.shape[-2:] #【channel,height,width】取后两个元素
assert len(val) == 2 # 防止输入的是个一维向量
original_image_sizes.append((val[0], val[1])) #记录原始图像的size,最后得到的输出会映射会原图像中
# original_image_sizes = [img.shape[-2:] for img in images]
images, targets = self.transform(images, targets) # 对图像进行预处理, 存放到一个batch中,因为原图的每张大小都不一样
# print(images.tensors.shape)
features = self.backbone(images.tensors) # 将图像输入backbone得到特征图
if isinstance(features, torch.Tensor): # 若只在一层特征层上预测,将feature放入有序字典中,并编号为‘0’
features = OrderedDict([('0', features)]) # 若在多层特征层上预测,传入的就是一个有序字典,resnet中会用到
# 将特征层以及标注target信息传入rpn中
# 区域建议框proposals: List[Tensor], Tensor_shape: [num_proposals, 4],
# 每个proposals是绝对坐标,且为(x1, y1, x2, y2)格式
proposals, proposal_losses = self.rpn(images, features, targets)
# 将rpn生成的数据以及标注target信息传入fast rcnn后半部分
detections, detector_losses = self.roi_heads(features, proposals, images.image_sizes, targets)
# 对网络的预测结果进行后处理(主要将bboxes还原到原图像尺度上)
#得到最终检测的一系列目标和fasterrcnn的损失
detections = self.transform.postprocess(detections, images.image_sizes, original_image_sizes)
losses = {}
losses.update(detector_losses)
losses.update(proposal_losses)
if torch.jit.is_scripting():
if not self._has_warned:
warnings.warn("RCNN always returns a (Losses, Detections) tuple in scripting")
self._has_warned = True
return losses, detections
else:
return self.eager_outputs(losses, detections)
# if self.training:
# return losses
#
# return detections
class TwoMLPHead(nn.Module):
"""
Standard heads for FPN-based models
Arguments:
in_channels (int): number of input channels
representation_size (int): size of the intermediate representation
"""
def __init__(self, in_channels, representation_size):
super(TwoMLPHead, self).__init__()
self.fc6 = nn.Linear(in_channels, representation_size)
self.fc7 = nn.Linear(representation_size, representation_size)
def forward(self, x):
x = x.flatten(start_dim=1)
x = F.relu(self.fc6(x))
x = F.relu(self.fc7(x))
return x
class FastRCNNPredictor(nn.Module):
"""
Standard classification + bounding box regression layers
for Fast R-CNN.
Arguments:
in_channels (int): number of input channels
num_classes (int): number of output classes (including background)
"""
def __init__(self, in_channels, num_classes):
super(FastRCNNPredictor, self).__init__()
self.cls_score = nn.Linear(in_channels, num_classes)
self.bbox_pred = nn.Linear(in_channels, num_classes * 4)
def forward(self, x):
if x.dim() == 4:
assert list(x.shape[2:]) == [1, 1]
x = x.flatten(start_dim=1)
scores = self.cls_score(x)
bbox_deltas = self.bbox_pred(x)
return scores, bbox_deltas
class FasterRCNN(FasterRCNNBase):
def __init__(self, backbone, num_classes=None, #加背景的
# transform parameter
min_size=800, max_size=1333, # 预处理resize时限制的最小尺寸与最大尺寸
image_mean=None, image_std=None, # 预处理normalize时使用的均值和方差
# RPN parameters
rpn_anchor_generator=None, rpn_head=None, #anchor生成器
rpn_pre_nms_top_n_train=2000, rpn_pre_nms_top_n_test=1000, # rpn中在nms处理前保留的proposal数(根据score)
rpn_post_nms_top_n_train=2000, rpn_post_nms_top_n_test=1000, # rpn中在nms处理后保留的proposal数
rpn_nms_thresh=0.7, # rpn中进行nms处理时使用的iou阈值
rpn_fg_iou_thresh=0.7, rpn_bg_iou_thresh=0.3, # rpn计算损失时,采集正负样本设置的阈值
rpn_batch_size_per_image=256, rpn_positive_fraction=0.5, # rpn计算损失时采样的样本数,以及正样本占总样本的比例
rpn_score_thresh=0.0,
# Box parameters
box_roi_pool=None, box_head=None, box_predictor=None,
# 移除低目标概率 fast rcnn中进行nms处理的阈值 对预测结果根据score排序取前100个目标
box_score_thresh=0.05, box_nms_thresh=0.5, box_detections_per_img=100,
box_fg_iou_thresh=0.5, box_bg_iou_thresh=0.5, # fast rcnn计算误差时,采集正负样本设置的阈值
box_batch_size_per_image=512, box_positive_fraction=0.25, # fast rcnn计算误差时采样的样本数,以及正样本占所有样本的比例
bbox_reg_weights=None):
if not hasattr(backbone, "out_channels"):
raise ValueError(
"backbone should contain an attribute out_channels"
"specifying the number of output channels (assumed to be the"
"same for all the levels"
)
assert isinstance(rpn_anchor_generator, (AnchorsGenerator, type(None)))
assert isinstance(box_roi_pool, (MultiScaleRoIAlign, type(None)))
if num_classes is not None:
if box_predictor is not None:
raise ValueError("num_classes should be None when box_predictor "
"is specified")
else:
if box_predictor is None:
raise ValueError("num_classes should not be None when box_predictor "
"is not specified")
# 预测特征层的channels
out_channels = backbone.out_channels
# 若anchor生成器为空,则自动生成针对resnet50_fpn的anchor生成器
if rpn_anchor_generator is None:
anchor_sizes = ((32,), (64,), (128,), (256,), (512,)) #每一个都是元组,5个预测特征层,对于尺寸最大的,即清晰度最高的特征层,就预测最小的目标,对于特征图已经缩到很小的尺寸的,就预测大目标
aspect_ratios = ((0.5, 1.0, 2.0),) * len(anchor_sizes) #anchor_sizes=5
rpn_anchor_generator = AnchorsGenerator(
anchor_sizes, aspect_ratios
)
# 生成RPN通过滑动窗口预测网络部分
if rpn_head is None:
rpn_head = RPNHead(
out_channels, rpn_anchor_generator.num_anchors_per_location()[0]
)
# 默认rpn_pre_nms_top_n_train = 2000, rpn_pre_nms_top_n_test = 1000,
# 默认rpn_post_nms_top_n_train = 2000, rpn_post_nms_top_n_test = 1000,
rpn_pre_nms_top_n = dict(training=rpn_pre_nms_top_n_train, testing=rpn_pre_nms_top_n_test)
rpn_post_nms_top_n = dict(training=rpn_post_nms_top_n_train, testing=rpn_post_nms_top_n_test)
# 定义整个RPN框架
rpn = RegionProposalNetwork(
rpn_anchor_generator, rpn_head,
rpn_fg_iou_thresh, rpn_bg_iou_thresh,
rpn_batch_size_per_image, rpn_positive_fraction,
rpn_pre_nms_top_n, rpn_post_nms_top_n, rpn_nms_thresh,
score_thresh=rpn_score_thresh)
# Multi-scale RoIAlign pooling
if box_roi_pool is None:
box_roi_pool = MultiScaleRoIAlign(
featmap_names=['0', '1', '2', '3'], # 在哪些特征层进行roi pooling
output_size=[7, 7],
sampling_ratio=2)
# fast RCNN中roi pooling后的展平处理两个全连接层部分
if box_head is None:
resolution = box_roi_pool.output_size[0] # 默认等于7
representation_size = 1024
box_head = TwoMLPHead(
out_channels * resolution ** 2,
representation_size
)
# 在box_head的输出上预测部分
if box_predictor is None:
representation_size = 1024
box_predictor = FastRCNNPredictor(
representation_size,
num_classes)
# 将roi pooling, box_head以及box_predictor结合在一起
roi_heads = RoIHeads(
# box
box_roi_pool, box_head, box_predictor,
box_fg_iou_thresh, box_bg_iou_thresh, # 0.5 0.5
box_batch_size_per_image, box_positive_fraction, # 512 0.25
bbox_reg_weights,
box_score_thresh, box_nms_thresh, box_detections_per_img) # 0.05 0.5 100
if image_mean is None:
image_mean = [0.485, 0.456, 0.406]
if image_std is None:
image_std = [0.229, 0.224, 0.225]
# 对数据进行标准化,缩放,打包成batch等处理部分
transform = GeneralizedRCNNTransform(min_size, max_size, image_mean, image_std)
super(FasterRCNN, self).__init__(backbone, rpn, roi_heads, transform)