论文原文:https://arxiv.org/pdf/2106.06963.pdf
参考:https://blog.csdn.net/qq_45645521/article/details/123493075
先验知识:这些柿子红了,肯定已经熟了
后验知识:我刚刚吃了柿子,已经熟透了
Abstract
Posterior-and-Prior Knowledge Exploring-and-Distilling approach (PPKED)
-
first examine the abnormal regions 检查异常部位
-
assign the disease topic tags 分配疾病主题标签
-
include modules:
- Posterior Knowledge Explorer (PoKE) 后验知识探索器
- explores the posterior knowledge 探索后验知识
- provides **explicit abnormal visual regions ** 提供显式异常视觉区域
- alleviate visual data bias 缓解视觉数据偏差
- 使用疾病的词袋探索后验知识,捕捉罕见、多样和重要的异常区域
- Prior Knowledge Explorer (PrKE) 先验知识探索器
- explores the prior knowledge from the prior medical knowledge graph (prior medical knowledge PrMK G P r G_{Pr} GPr) and prior radiology reports (prior working experience PrWE W P r W_{Pr} WPr) 从既往医学知识图(医学知识)和既往放射学报告(工作经验)中探索既往知识
- alleviate textual data bias 缓解文本数据偏差
- 从以前的工作经验和以前的医学知识中探索以前的知识
- Multi-domain Knowledge Distiller (MKD) 多领域知识提取器
- generate the final reports
- 将提取的知识提取出来生成报告
- adaptive distilling attention (ADA)
- make the model adaptively learn to distill correlate knowledge
- Posterior Knowledge Explorer (PoKE) 后验知识探索器
Introduction
directly applying image captioning approaches to radiology images has problems:
- visual data deviation - unbalanced visual distribution
- textual data deviation - too much normal discriptions
Related Works
Image Captioning
encoder-decoder framework - translates the image to a single descriptive sentence 单一描述性句子
radiology report generation - aims to generate a long paragraph - consists of multiple structural sentences
- each one focusing on a specific medical observation for a specific region in the radiology image 每一个都聚焦于放射图像中特定区域的特定医学观察
Image Paragraph Generation
- in a natural image paragraph: each sentence has equal importance
- in radiology report: generating abnormalities should be emphasized more than other normalities 需要更重视异常信息
Radiology Report Generation
explore and distill the posterior and prior knowledge for accurate radiology report generation 探索和提取后验和先验知识,以便准确地生成放射学报告
- for the network structure: explore the posterior knowledge of input radiology image by proposing to explicitly extract the abnormal regions 通过提出明确地提取异常区域来探索输入放射学图像的后验知识
- leverage the retrieved reports and medical knowledge graph to model the prior working experience and prior medical knowledge 利用检索到的报告和医学知识图对以前的工作经验和以前的医学知识建模
- retrieve a large amount of similar reports
- treat the retrieved reports as latent guidance 将检索到的报告作为潜在的指引
(use fixed templates to introduce inevitable errors)
Posterior-and-Prior Knowledge Exploring-and-Distilling (PPKED)
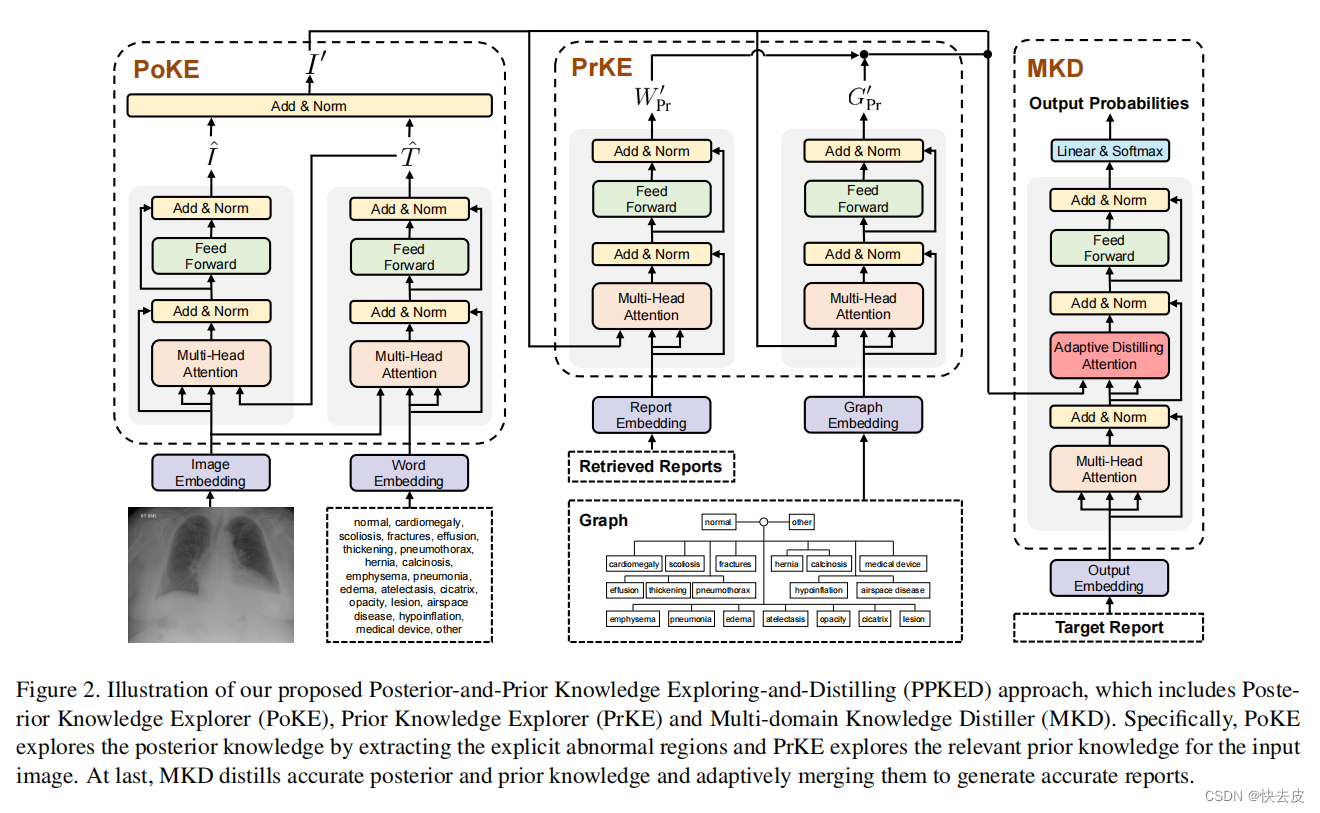
PoKE后验知识资源管理器 + PrKE先验知识资源管理器 + MKD多域知识蒸馏器
- PoKE: explores the posterior knowledge by extracting the explicit abnormal regions 通过提取显式异常区域来探索后验知识
- PrKE: explores the relevant prior knowledge for the input image 通过提取显式异常区域来探索后验知识
- MKD: distills accurate posterior and prior knowledge and adaptively merging them to generate accurate reports 提取准确的后验和先验知识,并自适应地合并它们以生成准确的报告
Backgrounds
Problem Formulation
PoKE : { I , T } → I ′ ; PrKE : { I ′ , W Pr } ; { I ′ , G Pr } → G Pr ′ MKD : { I ′ , W Pr ′ , G Pr ′ } → R \text{PoKE}:\{I,T\}\to I'; \\ \text{PrKE}:\{I',W_{\text{Pr}}\};\ \{I',G_{\text{Pr}}\}\to G'_{\text{Pr}} \\ \text{MKD}:\{I',W'_{\text{Pr}},G'_{\text{Pr}}\}\to R PoKE:{ I,T}→I′;PrKE:{ I′,WPr}; { I′,GPr}→GPr′MKD:{ I′,WPr′,GPr′}→R
Information Sources
-
I I I: adopt the ResNet-152 to extract 2048 7$\times 7 i m a g e f e a t u r e m a p s w h i c h a r e f u r t h e r p r o j e c t e d i n t o 5127 7 image feature maps which are further projected into 512 7 7imagefeaturemapswhicharefurtherprojectedinto5127\times$7 feature maps, resulting I = { i 1 , i 2 , . . . , i N 1 } ∈ R N 1 × d ( N 1 = 49 , d = 512 ) I=\{i_1,i_2,...,i_{N_1}\}\in \mathbb{R}^{N_1 \times d}(N_1=49,d=512) I={ i1,i2,...,iN1}∈RN1×d(N1=49,d=512)
-
T T T: topic bag (common abnormality topics or findings)
- T = { t 1 , t 2 , . . . , t N T ∈ R N T × d } T=\{t_1,t_2,...,t_{N_T}\in \mathbb{R}^{N_T \times d}\} T={ t1,t2,...,tNT∈RNT×d}
- t i ∈ R d t_i\in\mathbb{R}^d ti∈Rd: the word embedding of the i t h i^{th} ith topic 主题的词嵌入
-
W Pr W_{\text{Pr}} WPr: the reports of the top- N K N_K NK retrieved images are returned and encoded as the W Pr = { R 1 , R 2 , . . . , R N K } ∈ R N K × d W_{\text{Pr}}=\{R_1,R_2,...,R_{N_K}\}\in\mathbb{R}^{N_K\times d} WPr={ R1,R2,...,RNK}∈RNK×d
- use a BERT encoder followed by a max-pooling layer over all output vectors 在所有的输出向量上使用一个BERT编码器后跟一个max-pooling层 as the report embedding module R i ∈ R d R_i\in\mathbb{R}^d Ri∈Rd of the i t h i^{th} ith retrieved report
- 先验工作经验:从ResNet-152的最后一个平均池化层提取image embedding,这个image embedding是针对所有图像的; 然后对于给定一张图片。在语料库中找与输入图像余弦相似度最高的100张图片,将这样检索到的100张图片的报告用BERT和一个最大池化连接层进行编码,以此得到工作经验
-
G Pr G_{\text{Pr}} GPr:
- build a universal graph G Uni = ( V , E ) G_{\text{Uni}}=(V,E) GUni=(V,E): models the domain-specific prior knowledge structure 为特定领域的先验知识结构建模
- compose a graph that covers the most common abnormalities or findings 组成一个图表,涵盖最常见的异常或发现
- connect nodes with bidirectional edges 用双向边连接节点
- nodes V V V: N T N_T NT common topics in T T T
- acquire a set of nodes V ′ = { v 1 ′ , v 2 ′ , . . . , v N T } ∈ R R T × d V'=\{v_1',v_2',...,v_{N_T}\}\in \mathbb{R}^{R_T\times d} V′={
v1′,v2′,...,vNT}∈RRT×d encoded by a graph embedding module 由图形嵌入模块编码
- based on the graph convolution operation 基于图的卷积运算
- 先验医学知识:构建一张医学图。词袋中的主题被设置为节点,根据它们相关的器官和身体部分进行分组;对于分在一起的主题用边连接起来,用图卷积神经网络提取先验医学知识
Basic Module
Multi-Head Attention (MHA)
The MHA consists of n parallel heads and each head is defined as a scaled dot-product attention:
Att i ( X , Y ) = softmax ( X W i Q ( Y W i K ) T d n ) Y W i V MHA ( X , Y ) = [ Att 1 ( X , Y ) ; . . . ; Att n ( X , Y ) ] W O \text{Att}_i(X,Y)=\text{softmax}(\frac{X\text{W}_i^\text{Q}(Y\text{W}_i^\text{K})^T}{\sqrt{d_n}})Y\text{W}_i^\text{V} \\ \text{MHA}(X,Y)=[\text{Att}_1(X,Y);...;\text{Att}_n(X,Y)]\text{W}^{\text{O}} Atti(X,Y)=softmax(dnXWiQ(YWiK)T)YWiVMHA(X,Y)=[Att1(X,Y);...;Attn(X,Y)]WO
-
X ∈ R l x × d X\in\mathbb{R}^{l_x \times d} X∈Rlx×d: the Query matrix
-
Y ∈ R l y × d Y\in\mathbb{R}^{l_y \times d} Y∈Rly×d: the Key/Value matrix
-
W i Q , W i K , W i V ∈ R d × d n \text{W}_i^\text{Q},\text{W}_i^\text{K},\text{W}_i^\text{V}\in\mathbb{R}^{d\times d_n} WiQ,WiK,WiV∈Rd×dn, W i O ∈ R d × d \text{W}_i^\text{O}\in \mathbb{R}^{d\times d} WiO∈Rd×d: learnable parameters
-
d n = d / n d_n=d/n dn=d/n
-
[ ⋅ , ⋅ ] [·,·] [⋅,⋅]: concatenation operation 序连运算
序连运算:https://blog.csdn.net/Frank_LJiang/article/details/104333272
-
Feed-Forward Network (FFN)
FNN ( x ) = max ( 0 , x W f + b f ) W ff + b ff \text{FNN}(x)=\text{max}(0,x\text{W}_\text{f}+\text{b}_\text{f})\text{W}_\text{ff}+\text{b}_\text{ff} FNN(x)=max(0,xWf+bf)Wff+bff
- max ( 0 , ∗ ) \text{max}(0,*) max(0,∗): ReLU activation function
- W f ∈ R d × 4 d \text{W}_\text{f} \in \mathbb{R}^{d\times4d} Wf∈Rd×4d & W ff ∈ R 4 d × d \text{W}_\text{ff} \in \mathbb{R}^{4d\times d} Wff∈R4d×d : learnable matrices for linear transformation 线性变换的可学习矩阵
- b f \text{b}_\text{f} bf & b ff \text{b}_\text{ff} bff: bias terms 偏置项
Motivation
- MHA computes the association weights between different features 计算不同特征之间的关联权值
- allows probabilistic many-to-may relations 概率多对多关系
apply MHA to correlate the posterior and prior knowledge for the input radiology image, as well as distilling useful knowledge to generate accurate reports 应用MHA将输入的放射图像的后验和先验知识关联起来,并提取有用的知识以生成准确的报告
Posterior Knowledge Explorer (PoKE)
extract the posterior knowledge from the input image (abnormal regions) 从输入图像中提取后验知识
T ^ = FFN ( MHA ( I , T ) ) ; I ^ = FFN ( MHA ( T ^ , I ) ) ; \hat{T}=\text{FFN}(\text{MHA}(I,T)); \\ \hat{I}=\text{FFN}(\text{MHA}(\hat{T},I)); T^=FFN(MHA(I,T));I^=FFN(MHA(T^,I));
the image features I ∈ R N 1 × d I\in\mathbb{R}^{N_1\times d} I∈RN1×d are first used to find the most relevant topics and filter out the irrelevant topics, resulting in T ^ ∈ R N 1 × d \hat{T}\in\mathbb{R}^{N_1\times d} T^∈RN1×d. Then the attended topics T ^ \hat{T} T^ are further used to mine topic related image features I ^ ∈ R N 1 × d \hat{I}\in\mathbb{R}^{N_1\times d} I^∈RN1×d 用于挖掘与主题相关的图像特征
利用词袋中包含的异常主题找到图像中的异常区域
align the attended abnormal regions with the relevant topics 异常区域与相关的主题相一致
- need to filter out the irrelevant topics
将参与的异常区域和相关主题进行对齐
since I ^ \hat{I} I^ and T ^ \hat{T} T^ are aligned, we directly add them up to acquire the posterior knowledge of the input image:
I ′ = LayerNorm ( I ^ + T ^ ) I'=\text{LayerNorm}(\hat{I}+\hat{T}) I′=LayerNorm(I^+T^)
- LayerNorm \text{LayerNorm} LayerNorm: Layer Normalization 层归一化
- I ′ I' I′: first impression of radiologists after check the abnormal regions
Prior Knowledge Explorer (PrKE)
PrKE consists of a Prior Working Experience component and a Prior Medical Knowledge component
- both obtain prior knowledge from existing radiology report corpus and represent them as W Pr W_{\text{Pr}} WPr & G Pr G_{\text{Pr}} GPr
- W Pr ′ W'_{\text{Pr}} WPr′ & G Pr ′ G'_{\text{Pr}} GPr′: prior knowledge relating to the abnormal regions of the input image 分别代表先前工作经验和先前医学知识
- I ′ ∈ R N I × d I'\in\mathbb{R}^{N_\text{I} \times d} I′∈RNI×d: Query
- W Pr ∈ R N K × d W_{\text{Pr}} \in\mathbb{R}^{N_\text{K} \times d} WPr∈RNK×d: Key
- G Pr ∈ R N T × d G_{\text{Pr}} \in\mathbb{R}^{N_\text{T} \times d} GPr∈RNT×d: Value
W Pr ′ = FNN ( MHA ( I ′ , W Pr ) ) G Pr ′ = FNN ( MHA ( I ′ , G Pr ) ) W'_{\text{Pr}}=\text{FNN}(\text{MHA}(I',W_{\text{Pr}})) \\ G'_{\text{Pr}}=\text{FNN}(\text{MHA}(I',G_{\text{Pr}})) WPr′=FNN(MHA(I′,WPr))GPr′=FNN(MHA(I′,GPr))
- W Pr ′ ∈ R N I × d W'_{\text{Pr}} \in\mathbb{R}^{N_\text{I} \times d} WPr′∈RNI×d & G Pr ′ ∈ R N I × d G'_{\text{Pr}} \in\mathbb{R}^{N_\text{I} \times d} GPr′∈RNI×d: a set of attended prior knowledge related to the abnormalities of the input image 一组与输入图像异常相关的相关先验知识
- have potential to alleviate the textual data bias
通过这两个部分来处理PoKE中的后验知识,就可以获得输入图像异常区域的先验知识
Multi-domain Knowledge Distiller (MKD)
performs as a decoder 作为解码器生成最终的放射学报告
take the embedding of current input word x t = w t + e t x_t=w_t+e_t xt=wt+et as input:
- w t w_t wt: word embedding 词嵌入
- e t e_t et: fixed position embedding 位置嵌入
h t = MHA ( x t , x 1 : t ) h_t = \text{MHA}(x_t,x_{1:t}) ht=MHA(xt,x1:t)
Then employ the proposed Adaptive Distilling Attention (ADA) to distill the useful and correlated knowledge: 然后使用提出的自适应蒸馏注意(ADA)来提取有用的和相关的知识:
h t ′ = ADA ( h t , I ′ , G Pr ′ , W Pr ′ ) h_t'=\text{ADA}(h_t,I',G'_{\text{Pr}},W'_{\text{Pr}}) ht′=ADA(ht,I′,GPr′,WPr′)
Finally, the h t ′ h_t' ht′ is passed to a FFN and a linear layer to predict the next word: 被传递给一个FFN和一个线性层来预测下一个单词
y t ∼ p t = softmax ( FNN ( h t ′ ) W p + b p ) y_t\sim p_t=\text{softmax}(\text{FNN}(h'_t)\text{W}_p+\text{b}_p) yt∼pt=softmax(FNN(ht′)Wp+bp)
- W p \text{W}_p Wp & b p \text{b}_p bp: learnable parameters
train the PPKED by minimizing the cross-entropy loss:
L CE ( θ ) = − ∑ i = 1 N R log ( p θ ( y i ∗ ∣ y 1 : i − 1 ∗ ) ) L_{\text{CE}}(\theta)=-\sum_{i=1}^{N_R}\text{log}(p_\theta(y_i^*|y_{1:i-1}^*)) LCE(θ)=−i=1∑NRlog(pθ(yi∗∣y1:i−1∗))
- R ∗ = { y 1 ∗ , y 2 ∗ , . . . , y N R ∗ } R^*=\{y_1^*,y_2^*,...,y_{N_R}^*\} R∗={ y1∗,y2∗,...,yNR∗}: ground truth report
Adaptive Distilling Attention (ADA)
make the model adaptively learn to distill correlate knowledge: 使模型自适应学习提取相关知识
ADA ( h t , I ′ , G Pr ′ , W Pr ′ ) = MHA ( h t , I ′ + λ 1 ⊙ G Pr ′ + λ 2 ⊙ W Pr ′ ) λ 1 , λ 2 = σ ( h t W h ⊕ ( I ′ W I + G Pr ′ W G + W Pr ′ W W ) ) \text{ADA}(h_t,I',G'_{\text{Pr}},W'_{\text{Pr}})=\text{MHA}(h_t,I'+\lambda_1\odot G'_{\text{Pr}}+\lambda_2\odot W'_{\text{Pr}}) \\ \lambda_1,\lambda_2 = \sigma(h_t\text{W}_h\oplus(I'\text{W}_I+G'_{\text{Pr}}\text{W}_G+W'_{\text{Pr}}\text{W}_W)) ADA(ht,I′,GPr′,WPr′)=MHA(ht,I′+λ1⊙GPr′+λ2⊙WPr′)λ1,λ2=σ(htWh⊕(I′WI+GPr′WG+WPr′WW))
- W h , W I , W G , W W ∈ R d × 2 \text{W}_h,\text{W}_I,\text{W}_G,\text{W}_W\in\mathbb{R}^{d\times 2} Wh,WI,WG,WW∈Rd×2: learnable parameters
- ⊙ \odot ⊙: element-wise multiplication 哈达玛积
- σ \sigma σ: sigmoid function
- ⊕ \oplus ⊕: matrix-vector addition
- λ 1 , λ 2 ∈ [ 0 , 1 ] \lambda_1,\lambda_2\in [0,1] λ1,λ2∈[0,1]: weight the expected importance of G Pr ′ G'_{\text{Pr}} GPr′ & W Pr ′ W'_{\text{Pr}} WPr′ for each target word
Experiments
datasets: IU-Xray and MIMIC-CXR
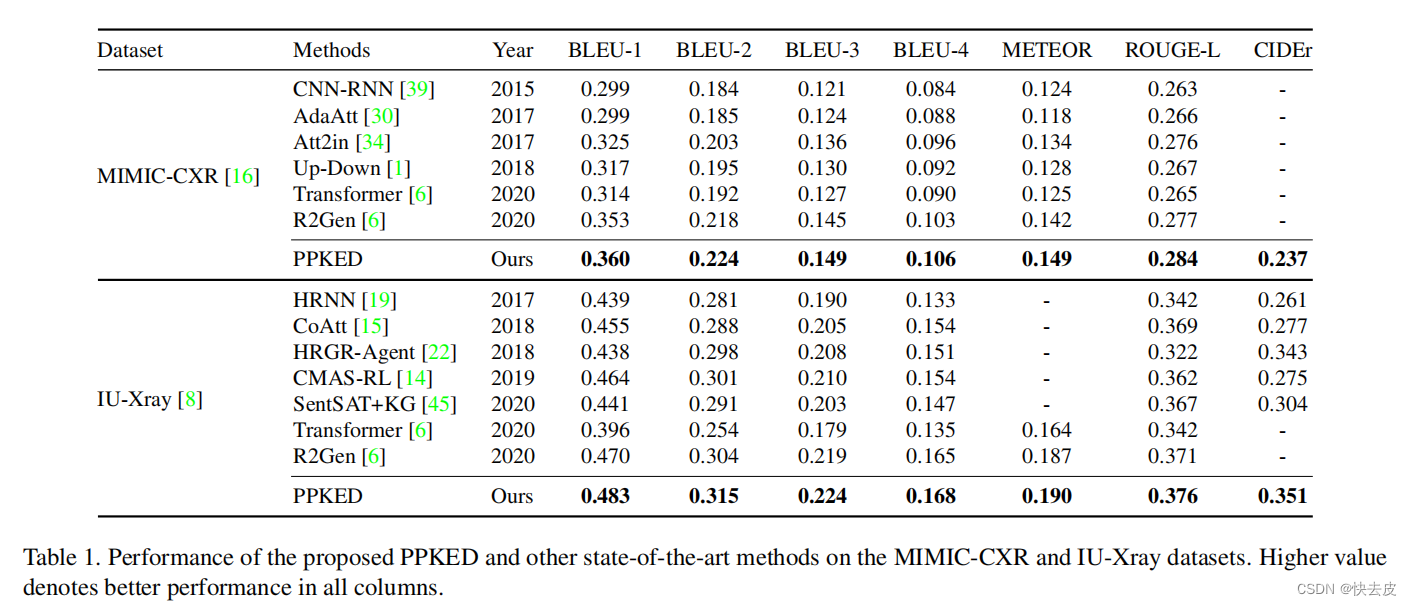
Quantitative Analysis
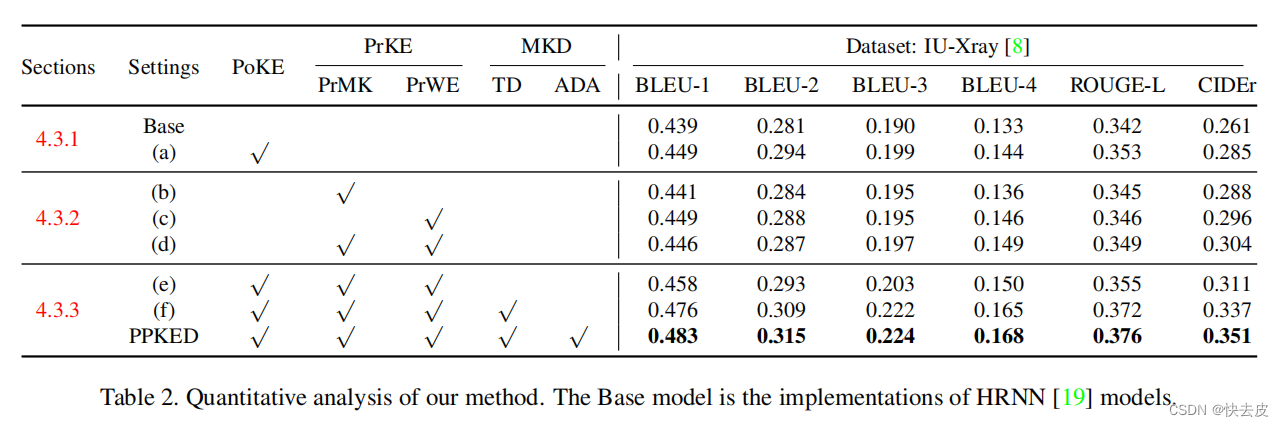
Posterior Knowledge Explorer
PoKE can better recognize abnormalities
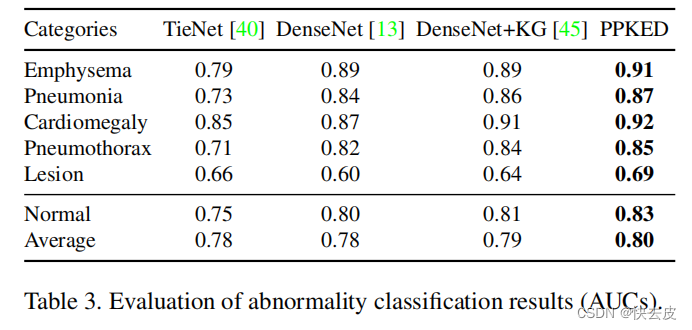
Prior Knowledge Explorer
- PrMK: can help the model learn enriched medical knowledge of the most common abnormalities or findings 能帮助模型学习最常见的异常或发现的丰富的医学知识
- PrWE: verifies the effectiveness of introducing existing similar reports 验证了引入现有类似报告的有效性

Multi-domain Knowledge Distiller
based on the Transformer Decoder equipped with the proposed Adaptive Distilling Attention
Qualitative Analysis
prove that their arguments and verify the effectiveness of our proposed approach in alleviating the data bias problem by exploring and distilling posterior and prior knowledge 证明了我们的论点,并验证了我们提出的方法通过探索和提取后验和先验知识来缓解数据偏差问题的有效性
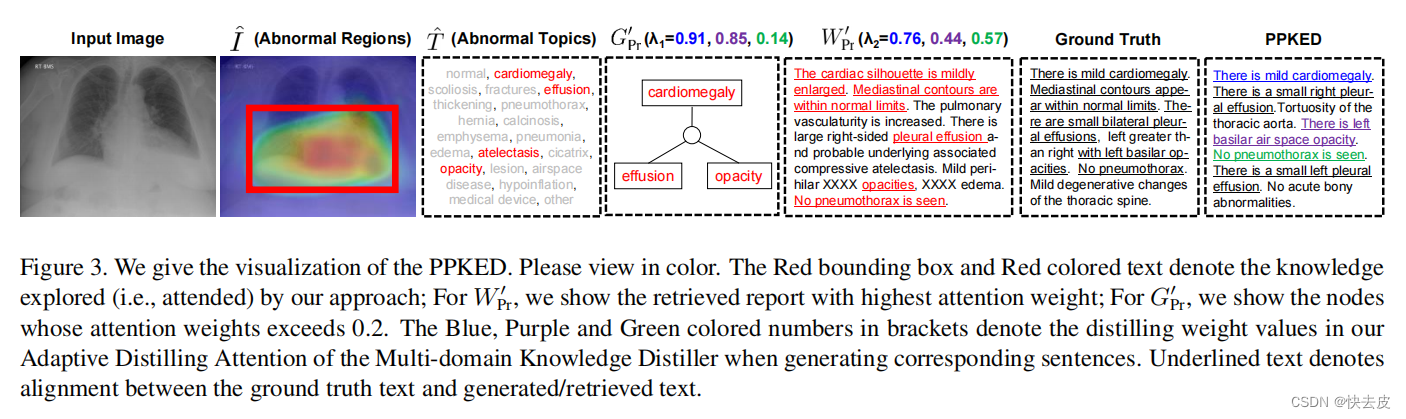
Conclusion
- generate meaning and robust radiology reports supported with accurate abnormal descriptions and regions
- outperforms previous state-of-the-art models on the 2 public datasets