Fast-RCNN
背景
根据之前对RCNN的学习,我们了解到RCNN是先将输入图片通过selective search来获得2k个预选框,然后将预选框的图片resize成227×227的尺寸(因为AlexNet卷积神经网络对输入图片的尺寸要求是227*227)。由于卷积神经网络的全连接层对于输入的特征图尺寸有固定的要求(因为全连接层的权值个数是一定的),所以候选区域的图像必须经过resize之后才能送入卷积神经网络模型进行特征提取,但是无论采用剪切还是变形的方式,都无法完整的保留原始图像的信息。因此何凯明等人提出了空间金字塔池化层(Spatial Pyramid Pooling Layer)来解决传统卷积神经网络对输入图像的尺寸的限制。
SPPnet
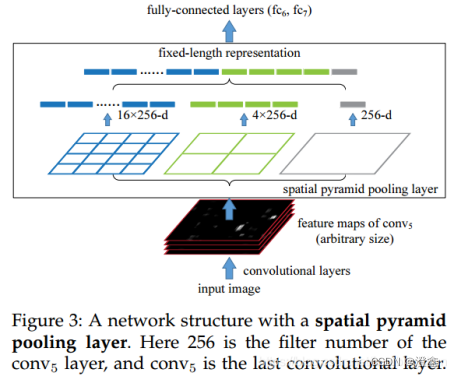
上图即为凯明大佬文章中提出的SPP-Net结构,该结构是针对当时的主流卷积神经网络所提出的,因此文章中提到的方法也许与我们现在以及将来魔改出来的SPP方式有些许不同,但是思想都是差不多的。文中提出的SPP结构是加在卷积层与全连接层之间,来代替传统的CNN的pool5普通池化层(以AlexNet为例子,是在第5层隐藏层和第6层隐藏层之间,由上图也可以发现)。SPP-Net的主要流程是,首先输入图像(input image,这里我们的输入图像尺寸不是固定的,可以输入任意尺寸的图像),经过五层卷积层的特征提取网络后获得feature maps(由于输入图像的尺寸不是固定的,因此这里获得的feature maps也不是固定的尺寸)。重点来了:
将我们获得的feature maps送入空间金字塔池化层中,通过多种尺度的池化方式(论文中展示的三种尺度的池化),经过金字塔池化层后,我们会获得固定尺寸的特征图向量,分别是4×4×256,2×2×256,1×1×256(其中256是卷积核的个数)。将不同尺度的特征向量拼成一个一维向量送入全连接层训练(即上图的FC6和FC7),能够很好的对应全连接层设置的每个权值。
由以上描述我们可以清楚SPPNet的主要作用(对于传统的AlexNet和VGG16卷积神经网络而言)是特征提取网络(backbone)与全连接层之间的桥梁,为了方便使backbone得到的特征图信息能够满足全连接层的权重参数的个数。
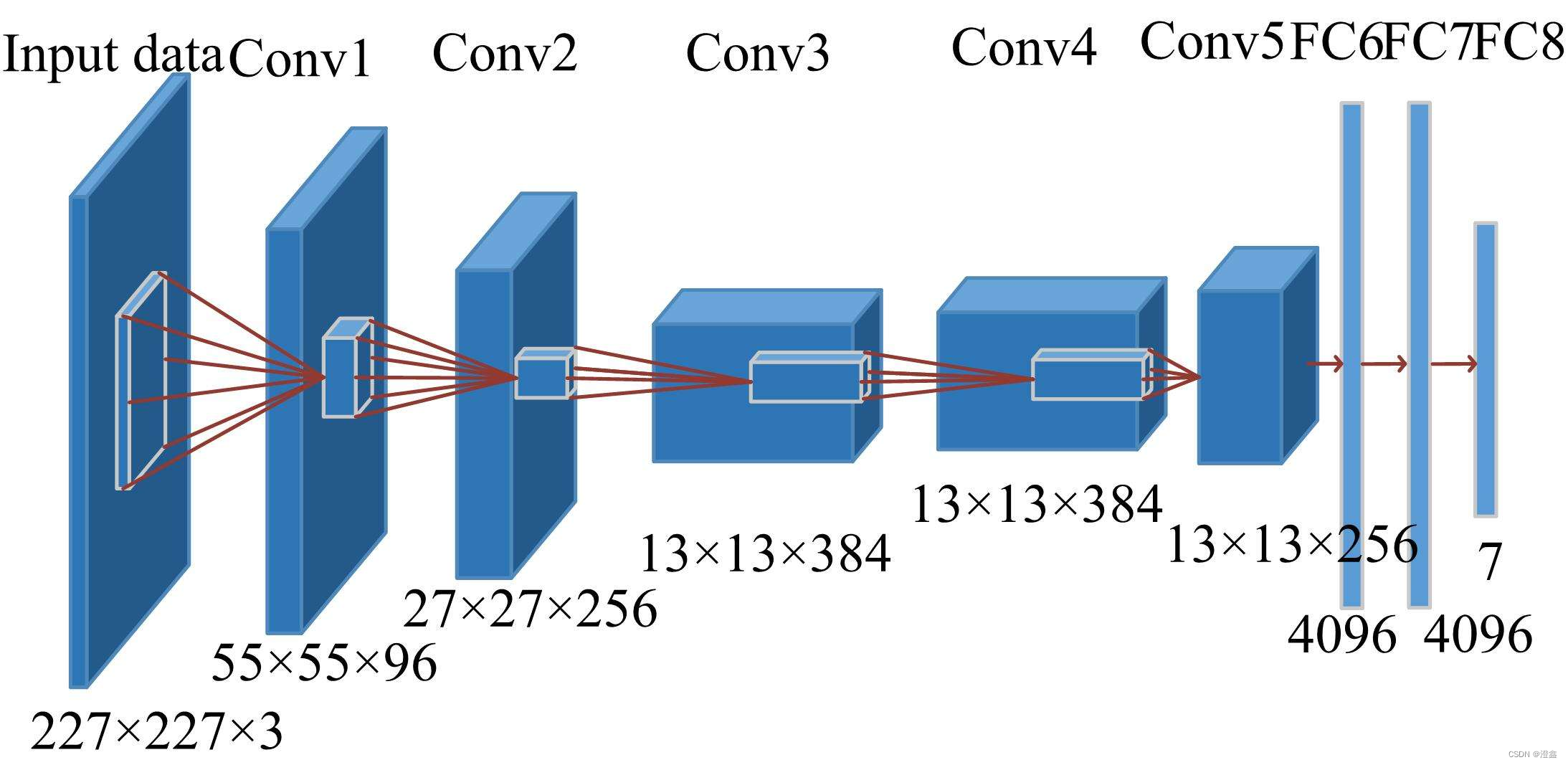
下图附上经典卷积神经网络AlexNet的网络结构图来方便大家理解我所做的笔记:
SPP-Net相对于RCNN的优势
SPP-Net的优势:
1.实现了任意尺寸的图像输入,固定了全连接层接收特征图信息的尺寸。
2.大大降低了计算时间,对于以前的RCNN来说,是将所有的候选框resize之后一个个送入CNN网络中进行特征提取,然后获得统一的参数量再送入全连接层中训练。
Fast-RCNN
RCNN的缺陷
RBG大佬在借鉴了凯明大佬的SPP-Net之后,在RCNN的基础上提出了Fast-RCNN算法。
RBG大佬在文中提出了RCNN的三个缺点:
1.训练过程是一个多阶段的管道。
简单来说,RCNN将卷积层的参数调整(log损失函数),目标的分类(SVM),回归框的计算这三个部分的损失函数分成三个阶段单独进行。
2.算法训练时的时空复杂度较高
由于RCNN是将一张图像的2k个预选框一个个送入网络中进行训练,并且这2k个预选框中含有大量的重叠部分,会造成大量的重复计算。
3.在预测阶段,预测一张图片的速度太慢。
Fast-RCNN的提出

上图就是Fast-RCNN文章中的算法流程图了。
这里我简单总结了一下Fast-RCNN在RCNN的基础上提出的一些创新:
1. 输入方式的创新
在训练时,Fast-RCNN在由ss算法计算出2k个RP区域之后,直接将原图送如backbone中进行特征提取。获取特征图之后,通过原图与特征图之间的映射关系得到对应的RP在特征图上的ROI,这里不得不提的是,Fast-RCNN中每张图片获得的RoI个数是64,每个mini-batch是两张图,因此一个mini-batch是128个RoI,然后每张图选取百分之25的RoI与groud truth进行IoU的计算,设置IoU的阈值为0.5,大于的作为正例,小于的作为反例(在预测阶段,每张输入的图都含有2000个RP区域)。这样可以减少很多重复的运算,因为在RCNN中,是先通过ss获取原图的RP,然后将每一个RPresize之后送入CNN进行特征提取的,不同的RP之间会存在很多重叠区域,会导致多余的计算,并且这样操作,一张图就要在CNN里被计算2k次(因为一张图里有2000个RP)。
2. RoI pooling
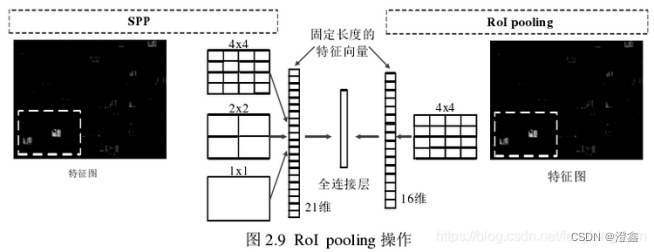
使用ROI pooling进行特征图的尺寸变化,因为输入全连接层的特征图需要尺寸统一(全连接层设置的权重参数个数是一定的)。将传统的pool5层(即AlexNet的第五层隐藏层中的池化层)的池化层换成ROI pooling层之后,将特征图统一成7×7的尺寸,然后根据将映射关系获得的roi区域送入全连接层中进行分类和回归。(这里要注意的是,Fast-RCNN使用的spp策略是简易版的,单尺度的spp,见下图,并且下图中的4×4在Fast-RCNN中应该是7×7)。将RoI pooling获得的特征图展平之后经过两个全连接层,得到RoI vector,将RoI vector分别并联送入分类和回归的全连接层中。
3.多任务的损失函数
使用了多任务的损失函数。将分类损失和regressor损失加入了分类损失中,同时包含了候选区域的分类损失和位置损失,能够训练在CNN的中的关于分类和回归框的参数。使用了softmax分类器取代SVM来进行分类,回归框的计算方式和RCNN一致。将获取的特征图通过并联的方式,一个计算分类,一个计算回归框。这样一来,Fast-RCNN就不需要像RCNN一样需要训练CNN,训练SVM,训练BBox regression了,因为Fast-RCNN将分类损失和回归损失都加入了损失函数中,见下面两张图我们就可以直观的看到Fast-RCNN在此处做出的优化:
这是RCNN的:

这是Fast-RCNN的:

(这里借鉴的是图片引用链接)
我们先接受这样的一个设定:u表示真实分类,v表示真实目标位置。Fast-RCNN的多任务损失函数表示为:
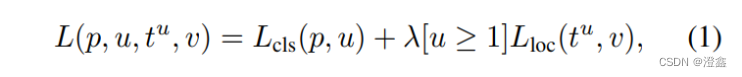
其中,第一部分的表示的是分类的损失,第二部分的是回归框的损失。
第一部分的分类损失函数表示为:
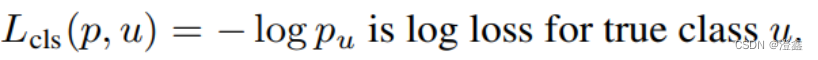
其中分类的损失用的是softmax的log loss,将目标类别分为k+1类,k为目标的类别个数,1位背景类别。
第二部分的位置损失函数表示为:
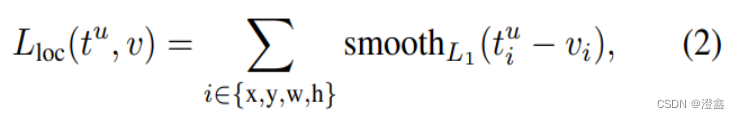
其中:
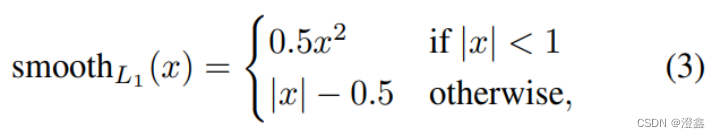
4.全连接层
使用SVD对全连接层的权值矩阵进行分解,使得处理一幅图像的速度明显提升。