欢迎大家关注公众号【哈希大数据】
【小白学爬虫连载(5)】--Beautiful Soup库详解
【小白学爬虫连载(10)】--如何用Python实现模拟登陆网站
前面已经分享过用Requests库、Selenium库结合正则表达式、BeautifulSoup库爬取一些租房信息、招聘信息、淘宝商品信息,接下来准备给大家分享一个更为强大的爬虫框架——scrapy,接下来主要介绍scrapy的安装过程。
Windows环境
1.首先确保电脑上已安装Python
如果没有安装过Python,请参考教程:http://blog.csdn.net/qq_29883591/article/details/52664478(谢谢陌上行走的分享)
如果已安装Python,可按以下步骤检验Python可执行程序路径是否已加入到PATH环境变量中。
利用win+R快捷键打开运行窗口,输入cmd打开命令行,在命令行中输入python --version,如果出现Python版本信息如下图

则说明Python可执行程序已加入PATH环境变量中,如果没有出现则需要python.exe所在文件及scripts文件路径加入到PATH环境变量。例如将C:\Python2.7\;C:\Python2.7\Scripts\;加入到环境变量PATH,可打开命令行,并且运行以下命令来修改 PATH:
c:\python27\python.exe c:\python27\tools\scripts\win_add2path.py
关闭并重新打开命令行窗口,使之生效。
2.安装pip
pip是用来安装其他必要包的工具,一般安装完Python,pip已经安装好了,咱们可以在命令行里输入:pip --version,检查是否安装完成,及安装版本。如果出现下图信息

说明pip已安装,否则首先下载 get-pip.py,下载好之后,选中该文件所在路径,执行下面的命令:python get-pip.py,执行命令后便会安装好pip。
3.安装scrapy
上面两步铺垫工作已经做好啦,接下来上演重头戏,安装scrapy,在命令行输入:pip install scrapy ,接下来的安装过程会比较长,因为scrapy需要大量其他Python库。如果一切顺利,最终大家将看到下面的信息
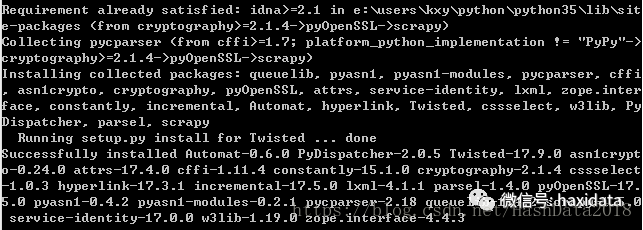
如果安装过程遇到什么问题欢迎在下面留言。
Linux环境
linux环境安装scrapy相对简单,因为其已经预装了Python环境,不过一般为Python2.7版本,如果想安装Python3,请参考:https://www.cnblogs.com/Guido-admirers/p/6259410.html(感谢橡皮头的分享)
然后直接在命令行中输入sudo pip install scrapy即可。
小结
本次分享简单介绍Pythony重要的爬虫框架scrapy库Windows环境和Linux环境的安装过程,如果大家在安装过程中遇到什么问题欢迎在下面留言,下次分享将为大家介绍如何快速上手scrapy。