自从Google发布了经典的MapReduce论文,以及Yahoo开源了Hadoop的实现,大数据这个词就成为了一个行业的热门。在不断提高的机器性能和各种层出不穷的工具框架加持下,数据分析开始从过去的采样抽查变成全量整体,原先被抽样丢弃的隐藏信息的价值也随之突现,数据拥有者可以发现新的关联信息,找到更细维度的特征,做出更精准的预测...
一说到大数据体系建设,各种高大上的概念自然就开始满天飞,数仓,数据湖,湖仓一体,流式计算名词一套套的。诚然对于一个每天产生巨量数据的大型企业来说,这些基础设施都是不可或缺的,甚至为了体系建设牺牲一定的灵活性也是可以接受的。但是对于大多数中小企业,或者是一些大型机构的分析师来说,真的需要这么一套庞大的体系吗?
对于大多数数据工作者来说,目前的工作流程是这样的。拿到原始数据,,要么导入Excel开始工作,要么申请数据导入数据仓库,然后在公司自建平台开始工作。单纯使用Excel处理的数据极限不超过100万行,再往上性能就不可接受。而且Excel对工程也不友好,各种误操作不容易发现记录,函数VB之类的屠龙之技在实际工作中还是存在较高的使用门槛。对于后一种情况则是依赖于公司流程的响应速度,在某些公司可能实际分析工作不到30分钟就能完成,但是入仓走流程就花了两天。
虽然现在Python非常火爆,相关的数据分析处理工具也层出不穷,但是对于大多数数据工作者来说,SQL是他们熟悉的语言。相比于面向过程的Python来说,SQL是描述性语言,只需要遵循规范告诉系统你想做什么,后台会自动完成任务的执行,而使用Python需要自己设计算法,告诉系统如何去执行,相比之下,SQL的学习门槛与表达能力要大大强于Python。业界一直在思考的问题,能否存在一个工具使得我们能结合Python与SQL的优点,快速的对源数据上手进行分析?
在进一步探讨这个问题之前,我们要回答多大的数据量算大数据?根据百度上的参考,toC的话千万级以上的数据,toB的话大概在10万级别。在这里我已某个经过数字化改造的线下广告行业为例,该公司拥有100万块线下数字显示屏,每周投放的数据量就是100万条数据,每条数据大小约为20K,那么总数据量就大约在20GB。对于这个级别的数据,使用标准的分布式大数据处理引擎固然没有问题,但是在硬件价格飞速下降的今天,特别是内存和磁盘,这个级别的数据量有没有可能在单机直接完成处理?
答案是可以的,这也是我们今天要谈的小数据,即单台电脑可以加载并完成处理的数据集合。今天向大家推荐一个小数据处理神器asqlcell,这个神器是jupyter lab的插件,通过"pip install asqlcell"及可快速完成安装。通过这个插件,允许你直接使用csv文件作为数据源,通过SQL完成对数据的分析处理,同时还支持Python与SQL的混合编程,充分发挥不同编程语言的长处,提高解决问题的效率。
下面我们来看一个例子,从Kaggle下载2020美国大选数据,打开jupyter lab,新建笔记本,导入asqlcell这个插件。
import asqlcell导入插件后,使用sql的语法如下:%%语法代表这个单元格的输入是sql语句。
%%sql 数据集名字
你的sql脚本
下面我们加载每个县的总统选取数据到数据集president_county_candidates,这个数据集是pandas的dataframe类型,并且可用于其它sql的输入源。
%%sql president_county_candidates
select * from 'us2020/president_county_candidate.csv'执行后结果如下,csv文件大小约1.5M,3万多条数据,30毫秒完成加载。并且返回的结果数据集支持翻页全量查看。并且对于数值类型的列,在标题栏添加了一个数值分布示意图。
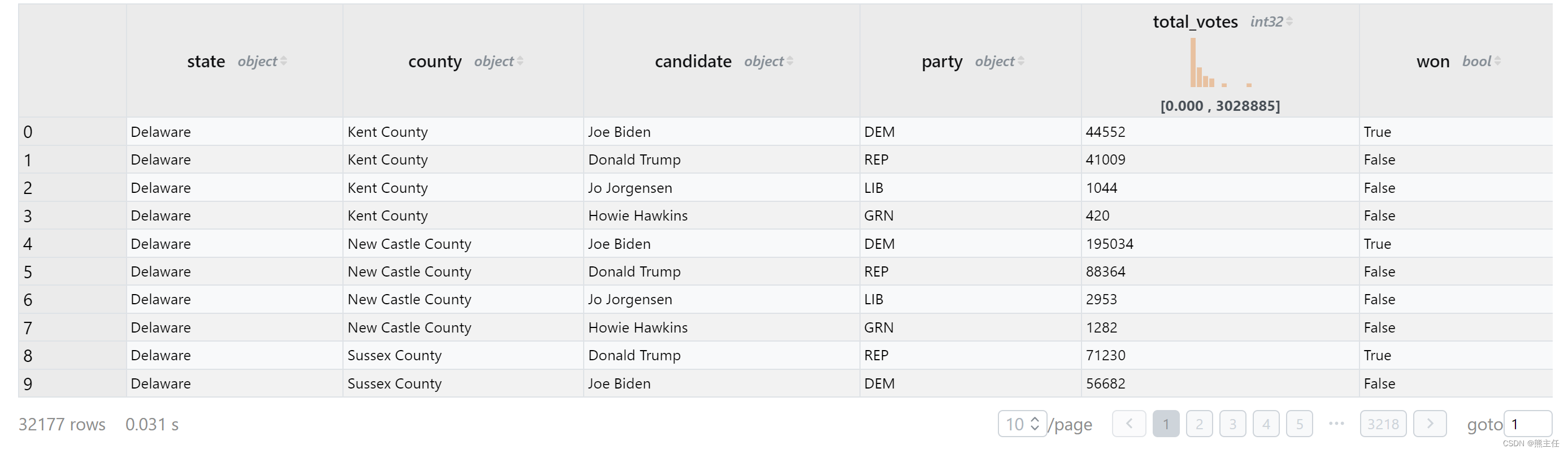
下面我们要做的是根据每个县的结果,找出每个州得票最多的候选人并统计票数。对于SQL和Python都不是特别熟悉的同学,比如我来说,可以通过走一步看一步的方式一步步得到想要的结果:
1. 将原始数据按周和候选人进行group并统计每个候选人的的票信息
%%sql state_result
select state, candidate, sum(total_votes) as total
from president_county_candidates
group by state, candidate
order by state, total desc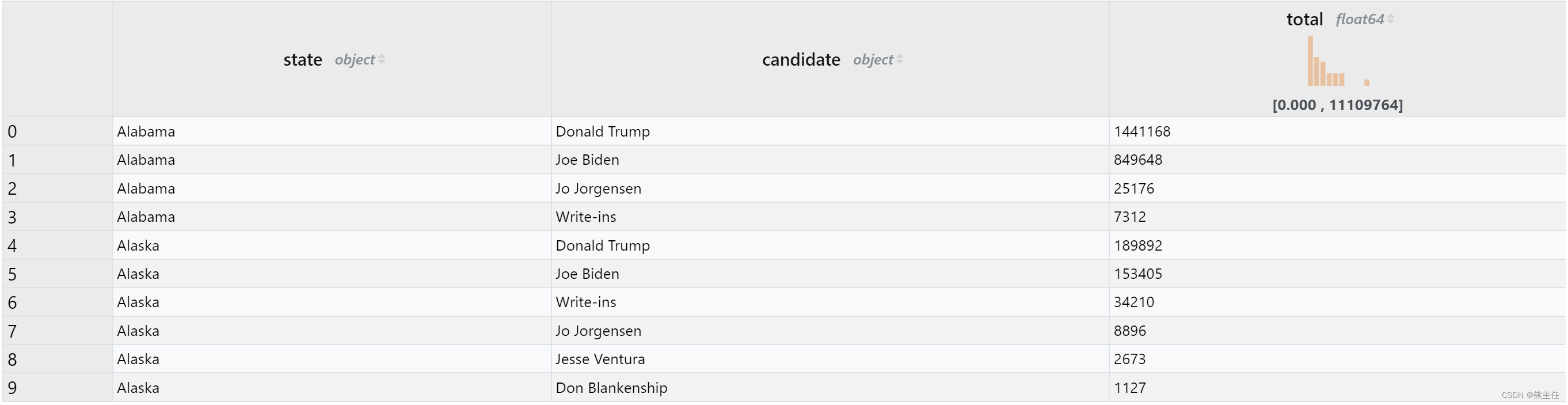
2. 根据上一步的结果,做一个子查询先统计每个周选票最多候选人的得票数量,然后select查询去匹配这个得票数量。
%%sql state_winner
select * from state_result
where (state, total) in (
select (state, max(total))
from state_result
group by state
)
order by total desc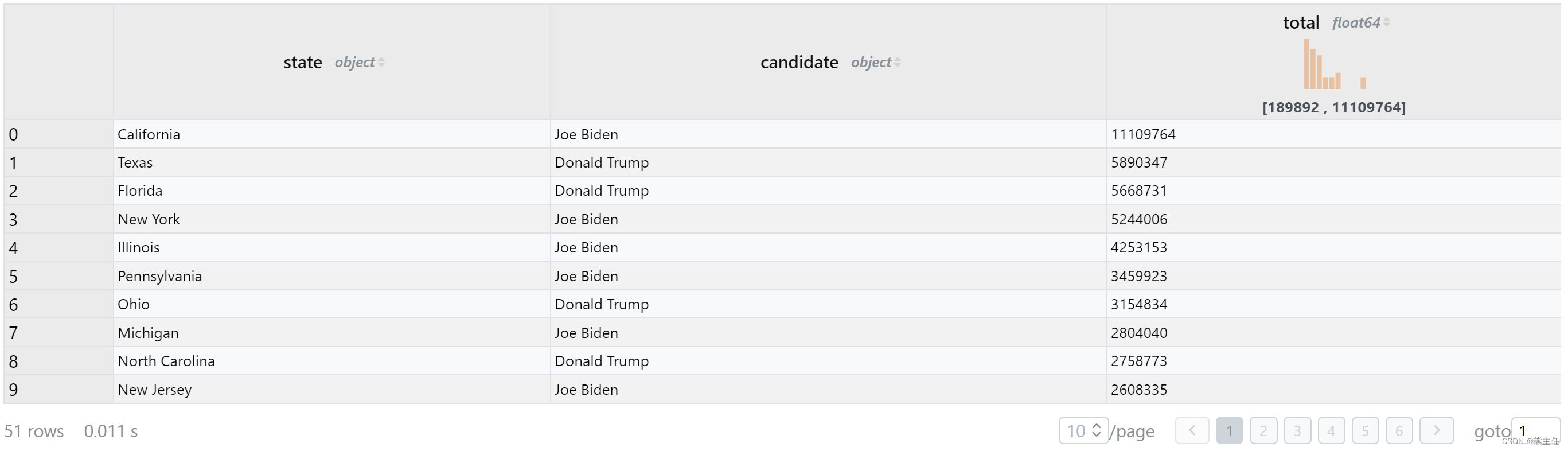
3. 我们还可以使用混合编程的模式把以上两个单元格的内容合并在一起:
state_result = %sql select state, candidate, sum(total_votes) as total from president_county_candidates group by state, candidate order by state, total desc
state_winner = %sql select * from state_result where (state, total) in (select (state, max(total)) from state_result group by state) order by total desc
state_winner相比传统数据处理模式,asqlcell有以下优点:
- 处理数据大小只受内存限制,对于一般非在线业务的中小企业,一台服务器足以装下所有数据并进行处理,数据开箱即用。
- 加载速度块,一个大小100M,有大约250万行数据的csv文件,0.7秒内完成加载。如果原始数据经过预处理为针对列压缩的parquet格式,只需0.2秒即可完成加载。
- 后台分析引擎使用基于内存的duckdb,速度快,OLAP查询SQL语法支持完善,学习门槛低。
- 支持Python混合编程,降低学习成本,同时最大限度发挥Python与SQL各自的优势。
随着硬件成本的不断降低,小数据的处理规模也会不断上升。对于一般非在线业务企业来说,如果能做到GB级别数据的开箱即用式分析,生产效率将大大提高,同时也可以降低基础设施的建设成本。
项目代码地址:GitHub - datarho/asqlcell
欢迎提出宝贵意见。!