一、学习内容
本章我们主要学习了属性文法和语法制导翻译。属性文法就是在上下文无关文法的基础上为每个文法符号(终结符或非终结符)配备若干个相关的“值”(称为属性)。属性又分为综合属性和继承属性两种,综合属性用于“自下而上”传递信息,继承属性用于“自上而下”传递信息。属性计算的过程即是语义处理的过程,对于文法的每一个产生式配备一组属性的计算规则,则称为语义规则。输入串®语法树®依赖图®语义规则计算次序®计算结果,这种由源程序的语法结构所驱动的处理办法就是语法制导翻译法。我们需要注意如果在一棵语法树中一个结点的属性b依赖于属性c,那么这个结点处计算b的属性规则必须在确定c的语义规则之后使用,那在一颗语法树中的结点的继承属性和综合属性之间的相互依赖关系就可以用称作依赖图的一个有向图来描述。属性计算方法有树遍历和一遍扫描,树遍历是语法分析构造语法树之后进行属性的计算,最常用的遍历方法是深度优先,从左到右的遍历方法,如果需要可使用多次遍历;一遍扫描的处理方法是在语法分析的同时计算属性值,而且无需构造实际的语法树。在这里要提到抽象语法树,就是从语法树中去掉对翻译不必要的信息,而获得更有效的源程序中间表示,在抽象语法树中,操作符和关键字都不作为叶结点出现,而是把它们作为内部结点,即这些叶结点的父结点。S—属性文法自下而上计算,它只含有综合属性,综合属性可以在分析符号串的同时由自上而下的分析器来构造,分析器可以保存与栈中文法符号有关的综合属性值,每当进行归约时,新的属性值就由栈中正在归约的产生式右边符号的属性值来计算,可以通过扩充分析器中的栈来存放这些综合属性值。L-属性文法的自顶向下翻译,属性的计算次序受分析方法所限定的分析树结点建立次序的限制,分析树的结点是自左向右生成,如果属性信息是自左向右流动,那么就有可能在分析的同时完成属性计算。S属性文法包含于L属性文法。最后简单介绍一下翻译模式,它是语法制导定义的一种便于翻译的书写形式。其中属性与文法符号相对应,语义规则或语义动作用花括号{}括起来,可被插入到产生式右部的任何合适的位置上。
二、知识运用
1.依赖图的构造算法
for分析树中每一个结点n
for 结点的文法符号的每一个属性a
为a在依赖图中建立一个结点;
for分析树中每一个结点n
for结点n所用产生式对应的每一个语义规则
b:=f(c1,c2,…ck)
for i :=1 to k
从ci结点到b结点构造一条有向边
2.属性计算算法(计算N的所有能够计算的综合属性)
While 还有未被计算的属性
VisitNode(S) /*S是开始符号*/
voidVisitNode(Node N);
{ if N是一个非终结符
/* 假设它的产生式为 N ®X1…Xm */
for i:=1 to m
if Xi∈VN then /*即Xi是非终结符*/
{
计算Xi的所有能够计算的继承属性;
VisitNode(Xi)
}
}
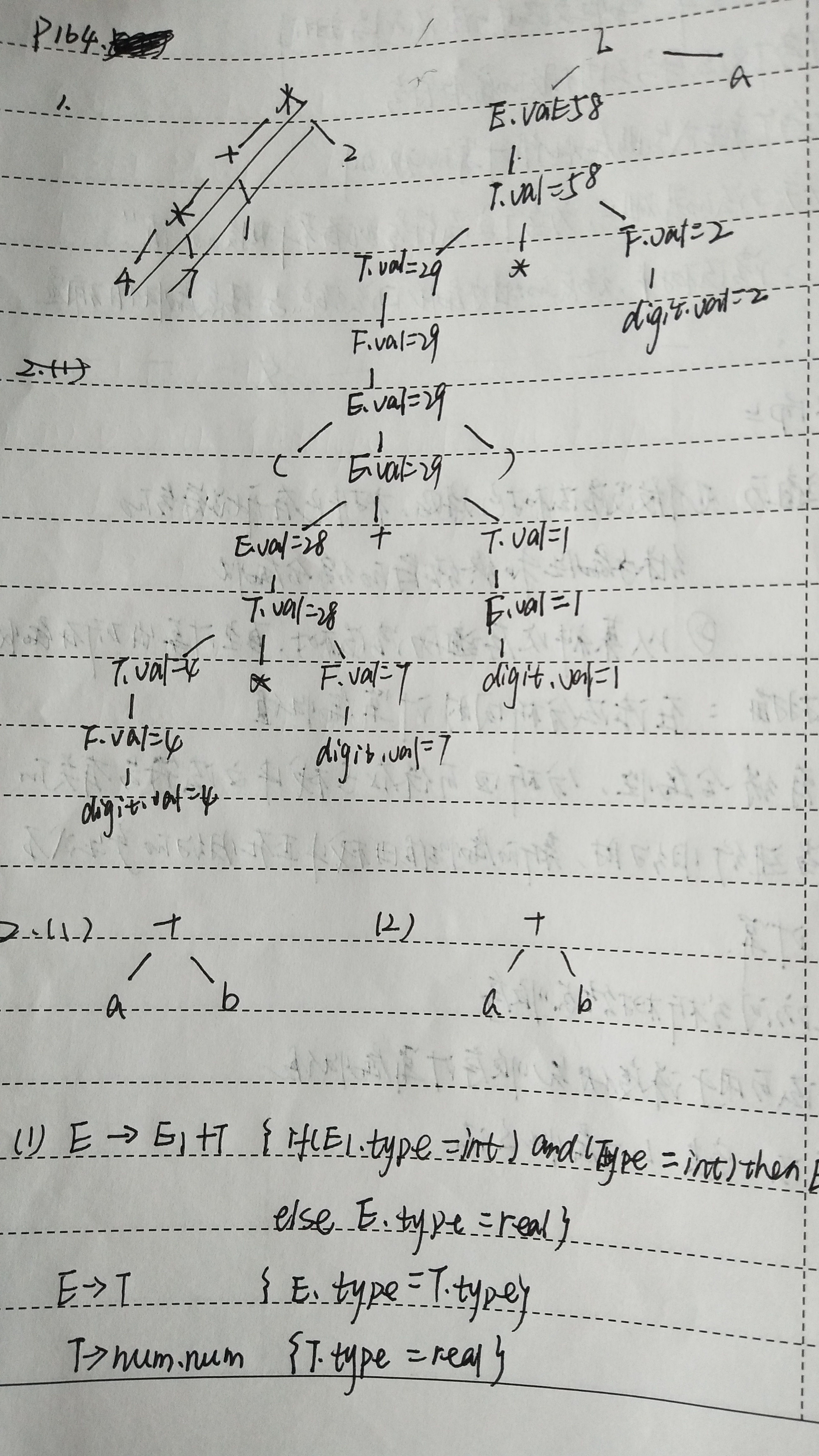
3.设计翻译模式(根据语法制导定义)
条件:语法制导定义是L-属性定义
(1)只需要综合属性的情况
为每一个语义规则建立一个包含赋值的动作,并把这个动作放在相应的产生式右边的末尾。
例如:
产生式 语义规则
T®T1*F T×val:=T1 ×val*F×val
翻译模式
T®T1*F { T×val:=T1×val*F×val}
(2)既有综合属性又有继承属性的情况
①产生式右边的符号的继承属性必须在这个符号以前的动作中计算出来。
②一个动作不能引用这个动作右边符号的综合属性。
③产生式左边非终结符号的综合属性只有在它所引用的所有属性都计算出来以后才能计算。计算这种属性的动作通常可放在产生式右端的未尾。

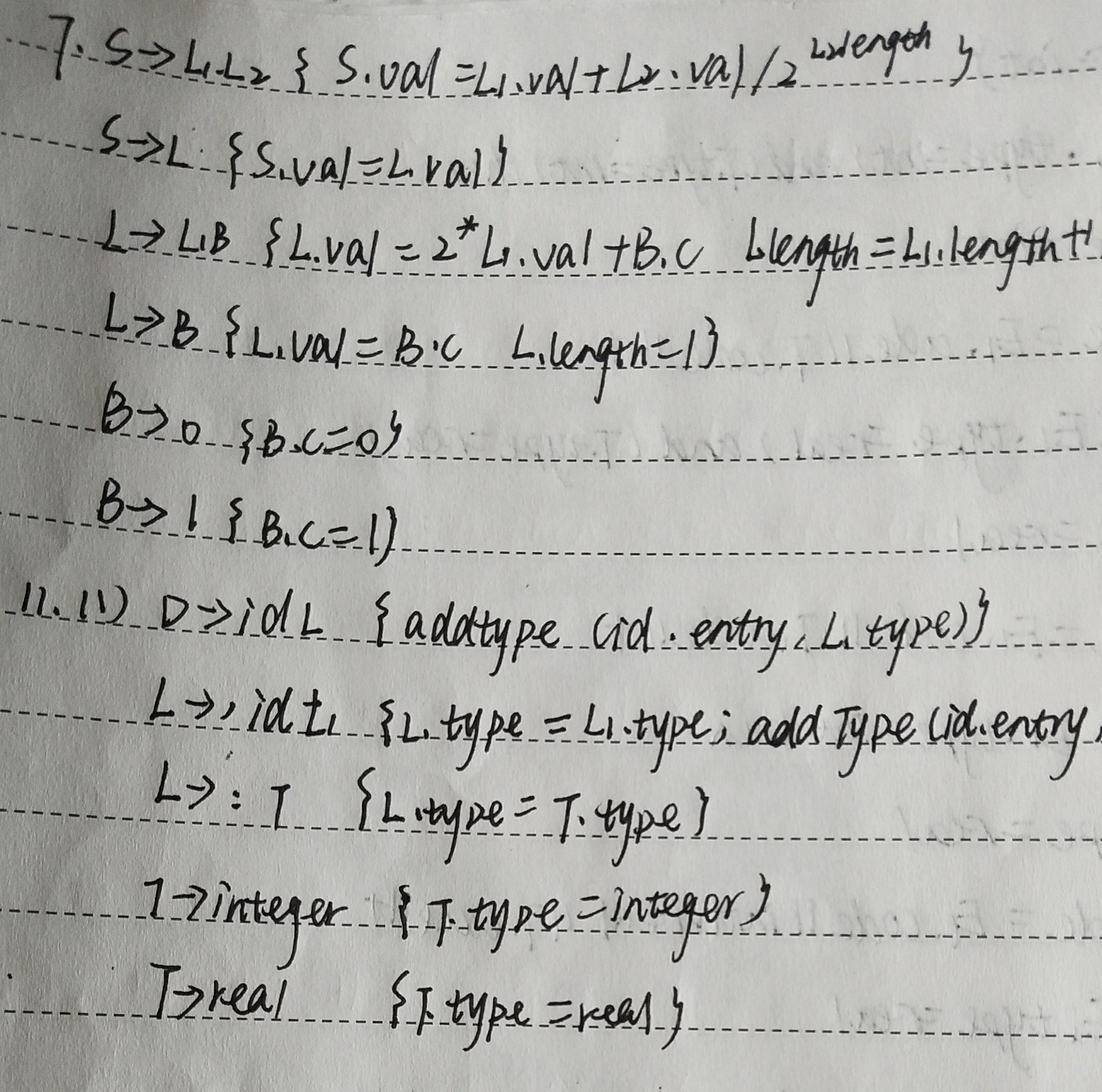
三、我的感受
第六章我们学的并没有太过深入,因为较前几章相比难度更大、更不易理解。重点学习了语法制导翻译的基本思想,语法制导定义,翻译模式,自顶向下翻译,自底向上翻译。其中属性的意义,对综合属性、继承属性和固有属性的理解,属性计算,怎么通过属性来表达翻译难度较大,掌握的并不好。做了下习题有不少做不出来的,写的也不够规范具体,与真正理解掌握差距较大,将在课后进行复习补救。