官方文档:https://grafana.com/docs/grafana/latest/
github 地址:https://github.com/grafana/grafana
1、Grafana 简介
Grafana 是一个开源的度量分析与可视化套件。经常被用作基础设施的时间序列数据和应用程序分析的可视化,它在其他领域也被广泛的使用包括工业传感器、家庭自动化、天气和过程控制等。
Grafana 支持许多不同的数据源。每个数据源都有一个特定的查询编辑器,该编辑器定制的特性和功能是公开的特定数据来源。
Grafana 的监控是基于数据库的,通过插件获取到服务器性能并存储到数据库中,然后使用Grafana 连接数据库形成可视化的图表。
官方支持以下数据源:Graphite,InfluxDB,OpenTSDB,Prometheus,Elasticsearch,CloudWatch和KairosDB。每个数据源的查询语言和能力都是不同的。你可以把来自多个数据源的数据组合到一个仪表板,但每一个面板被绑定到一个特定的数据源,它就属于一个特定的组织。
Grafana 特性
官方在线的 demo,可以体验 Grafana 最新特性 :http://play.grafana.org/
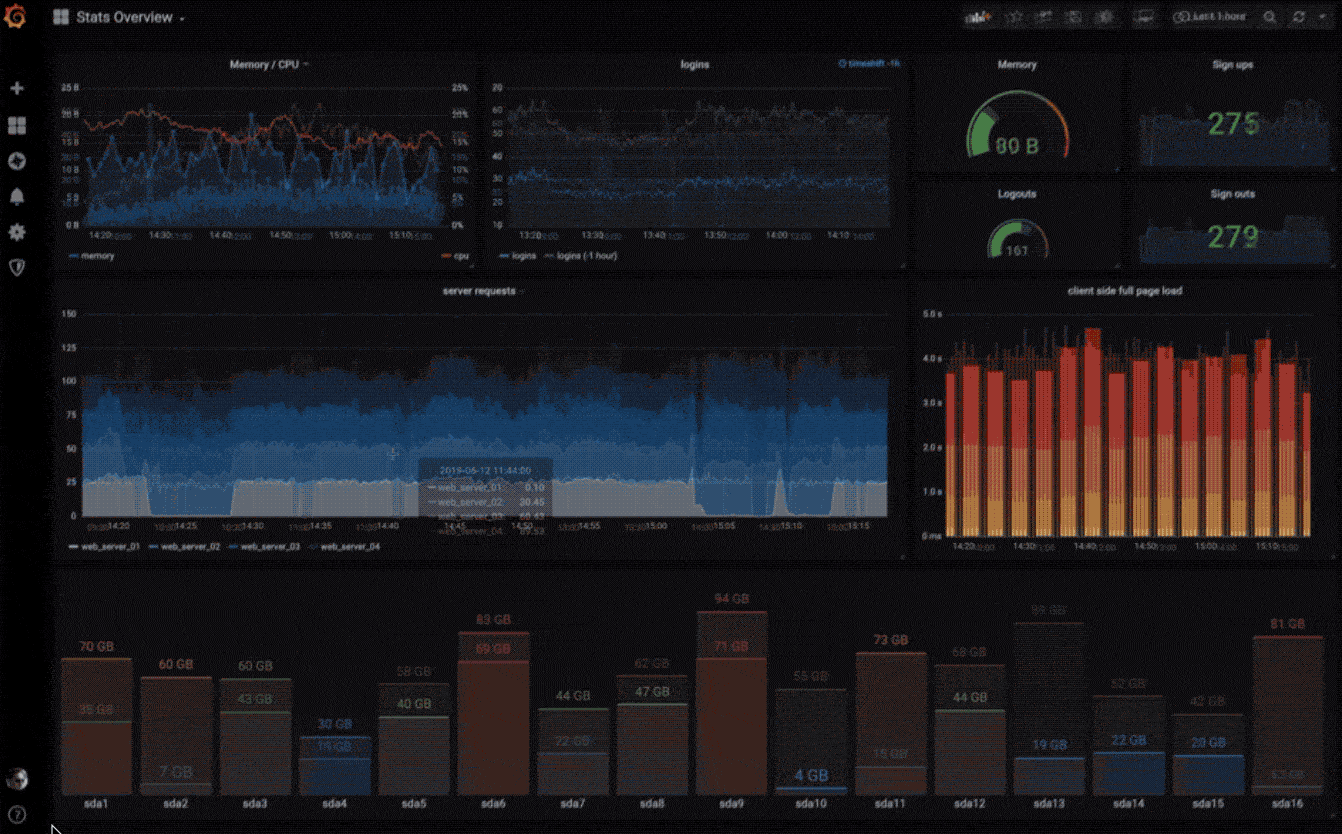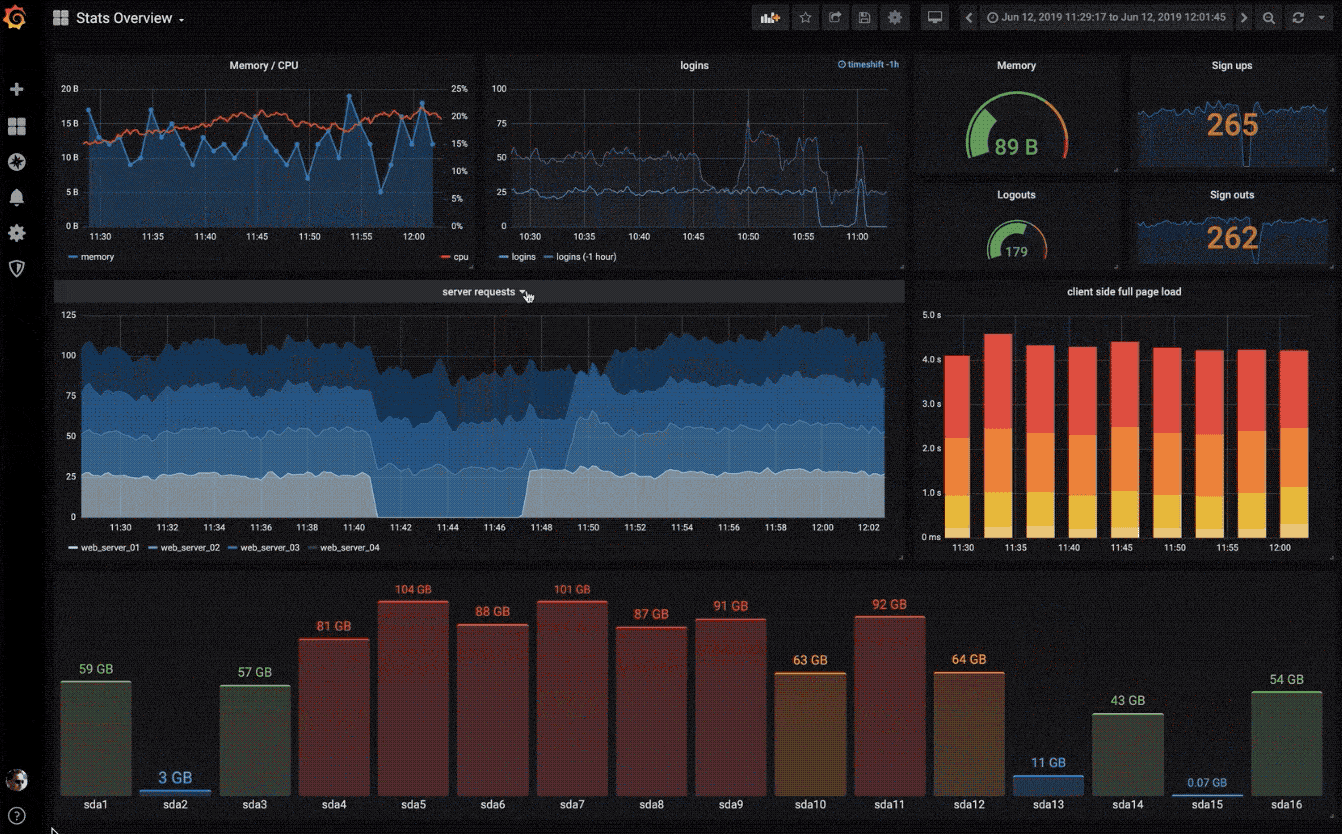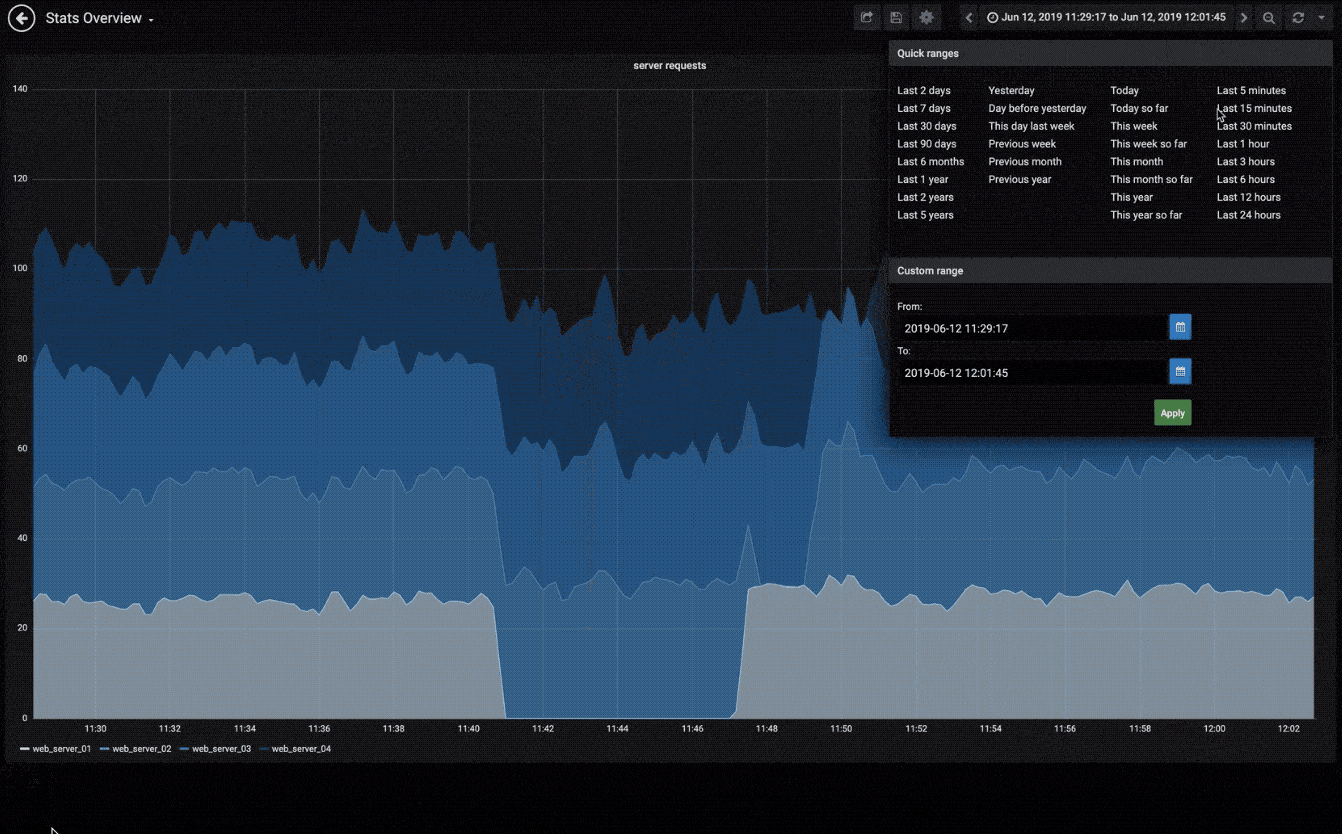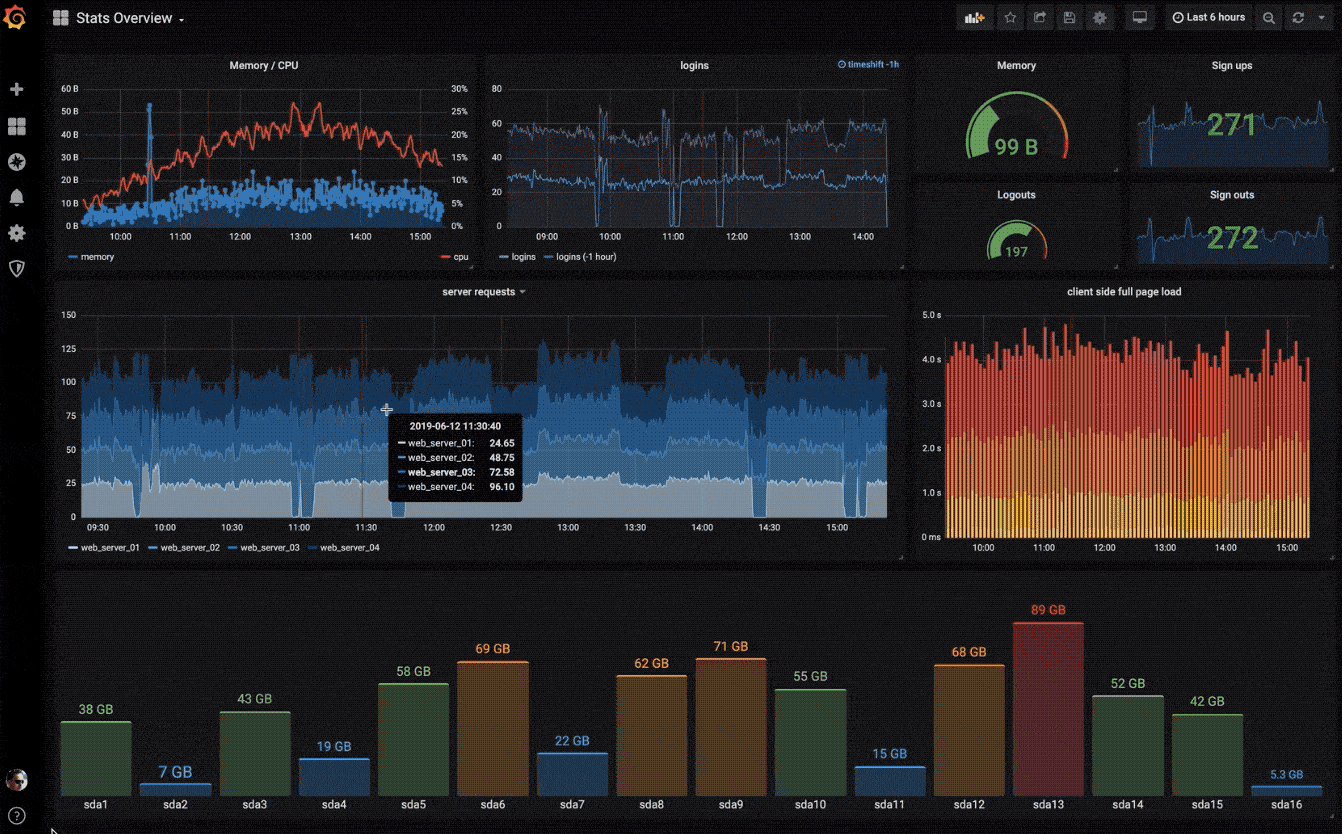
可视化
快速灵活的可视化以及多种选择,使你可以以任何方式可视化数据。官方库中具有丰富的仪表盘插件,比如热图、折线图、图表等多种展示方式。
动态仪表盘
使用模板变量创建动态且可重复使用的仪表板,这些模板变量显示在仪表板顶部。
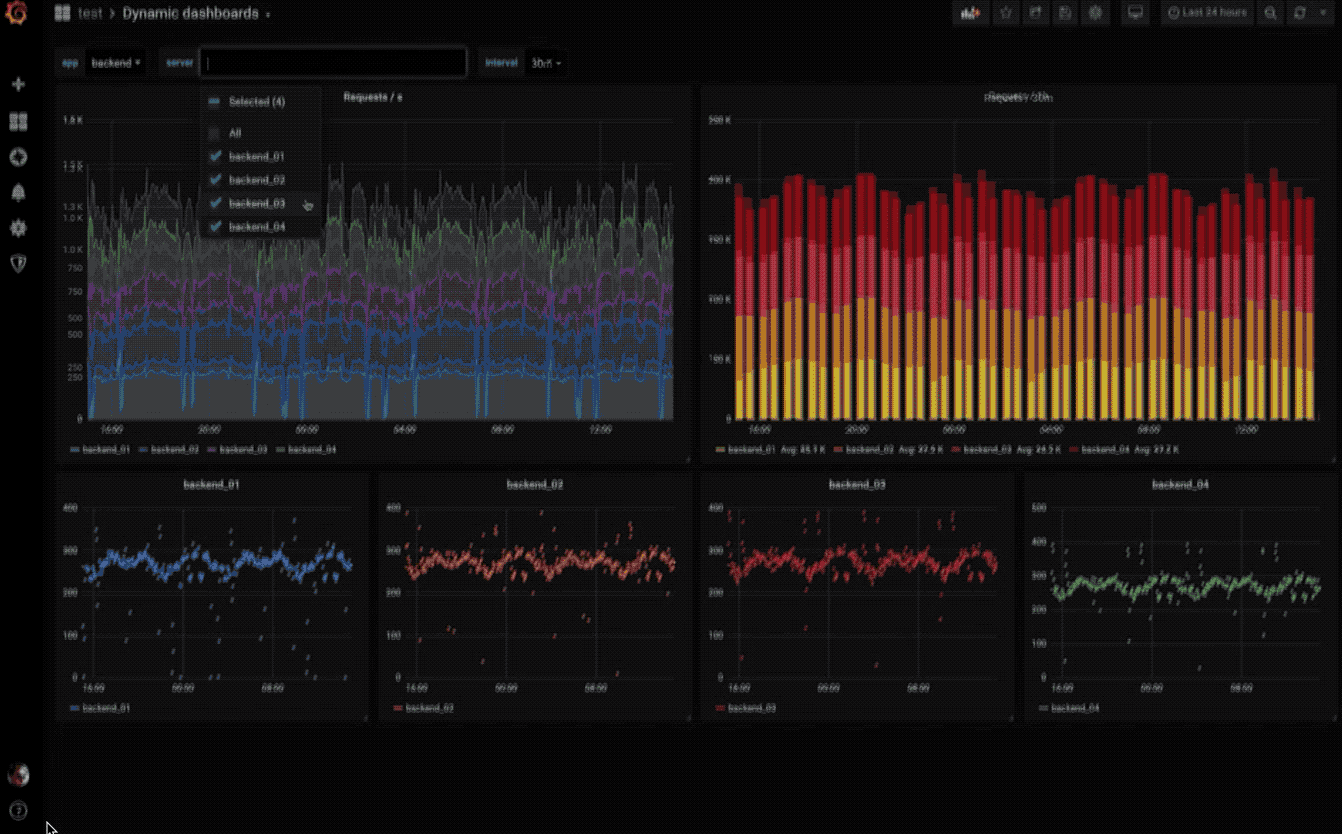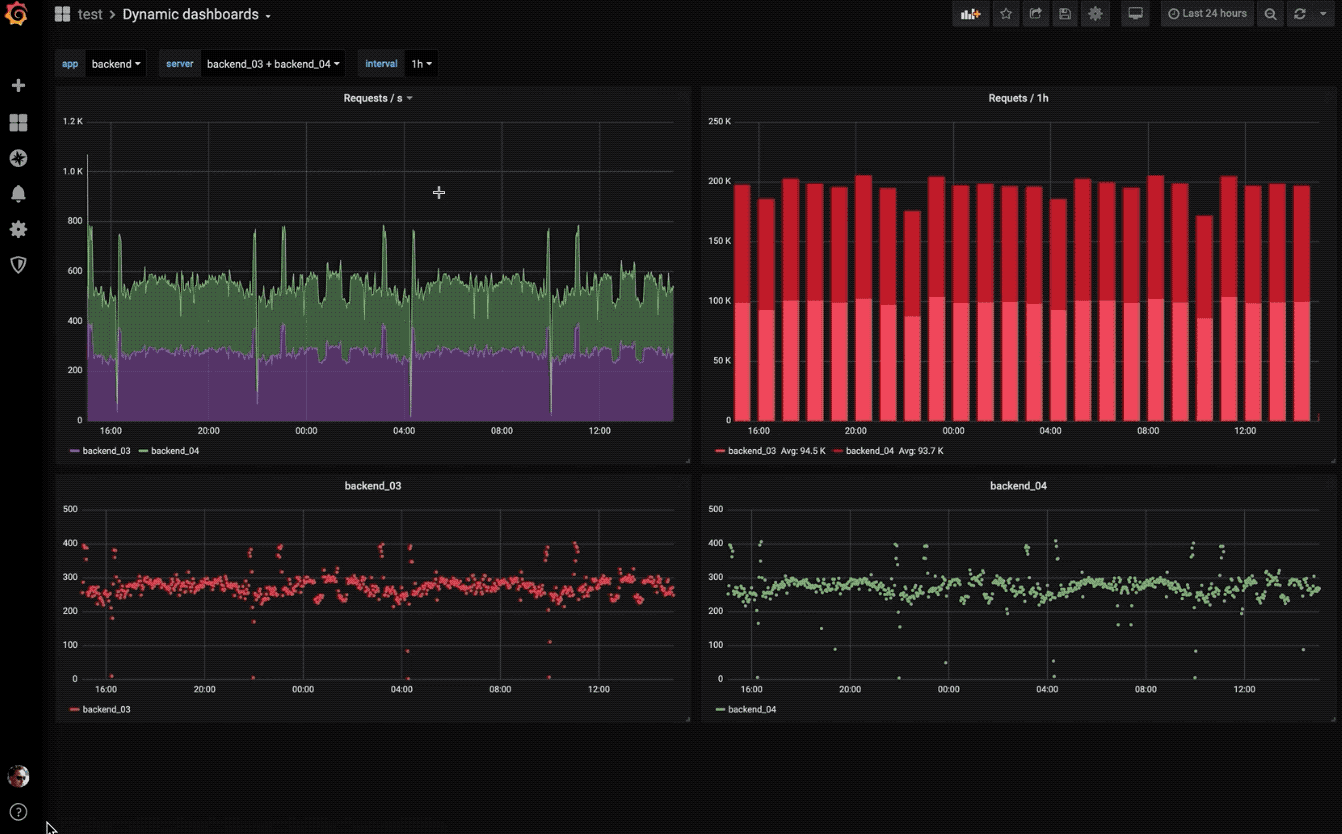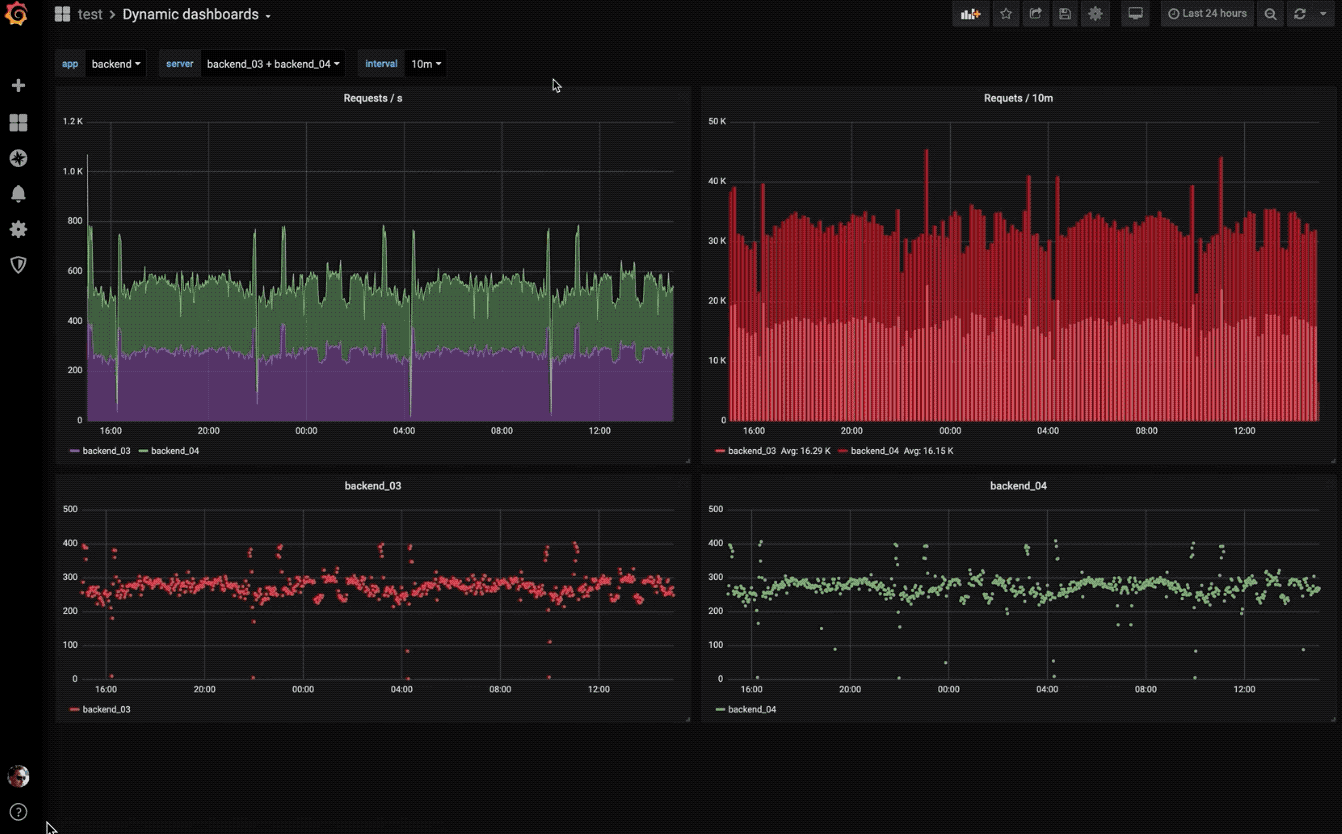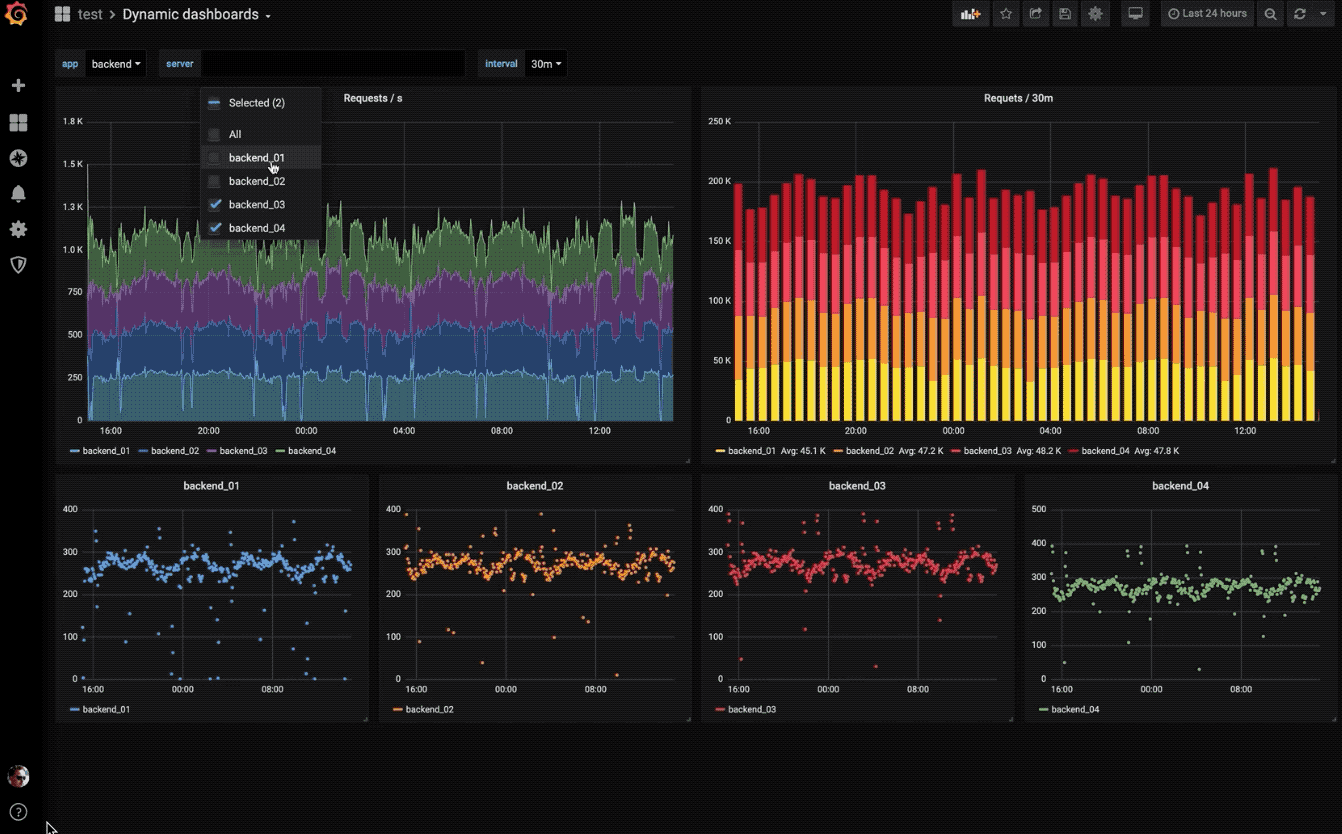
探索指标
通过临时查询和动态明细浏览数据。拆分视图并排比较不同的时间范围,查询和数据源。
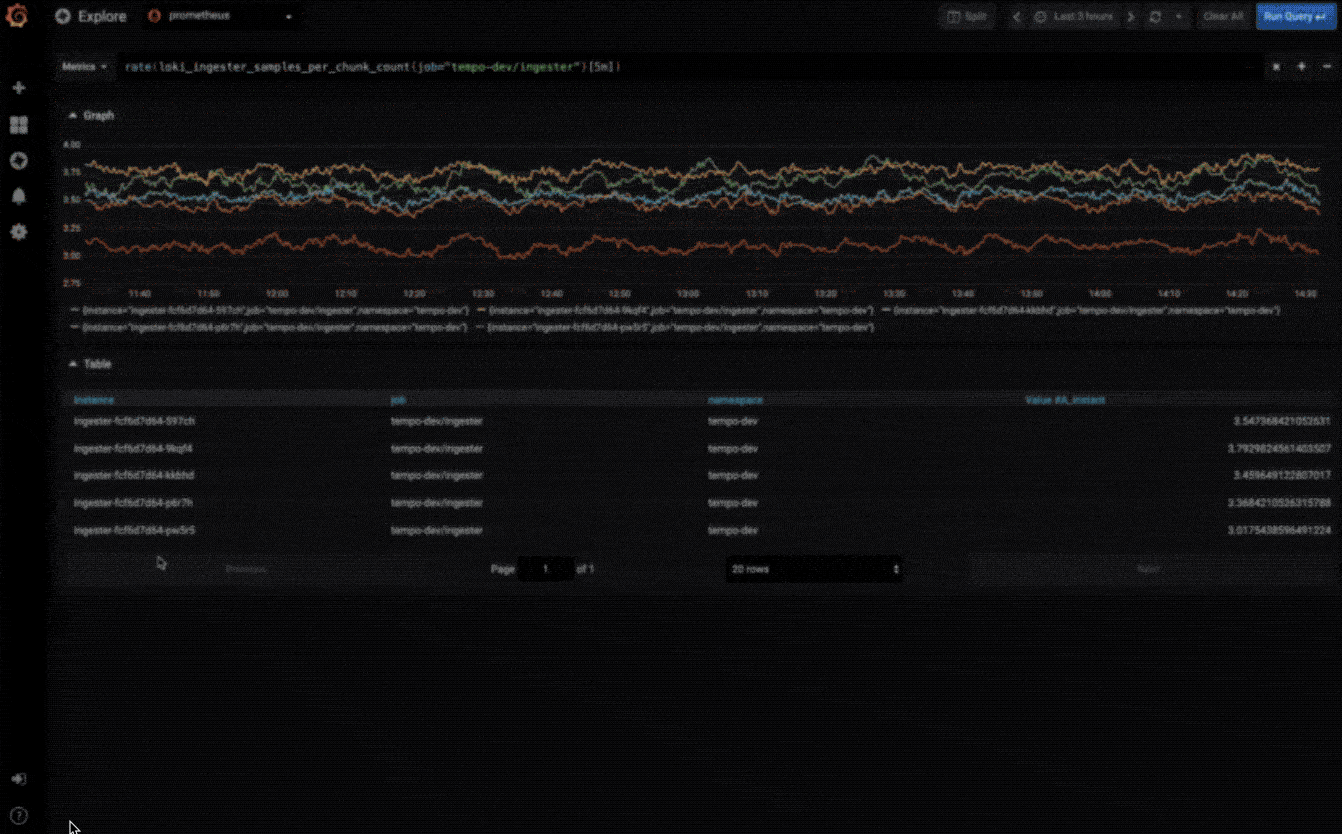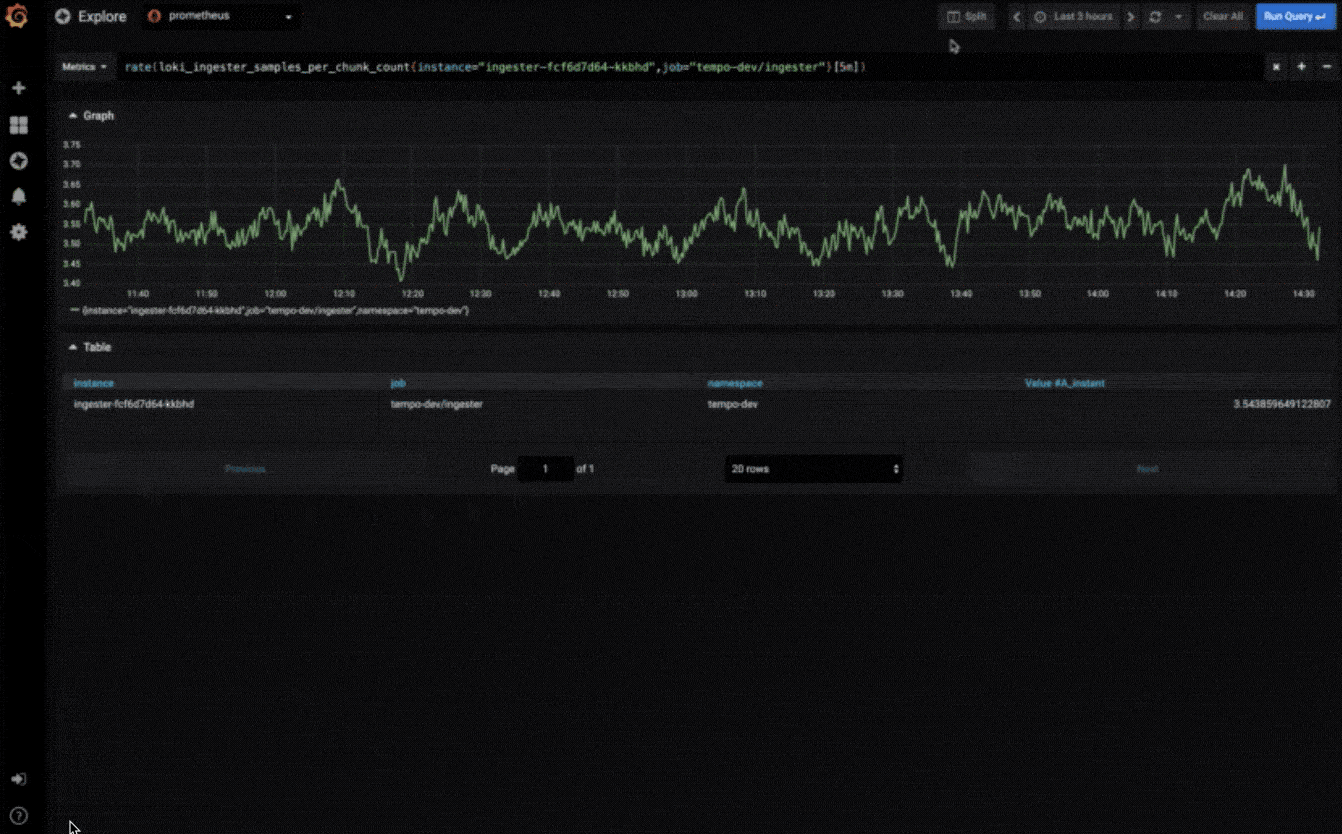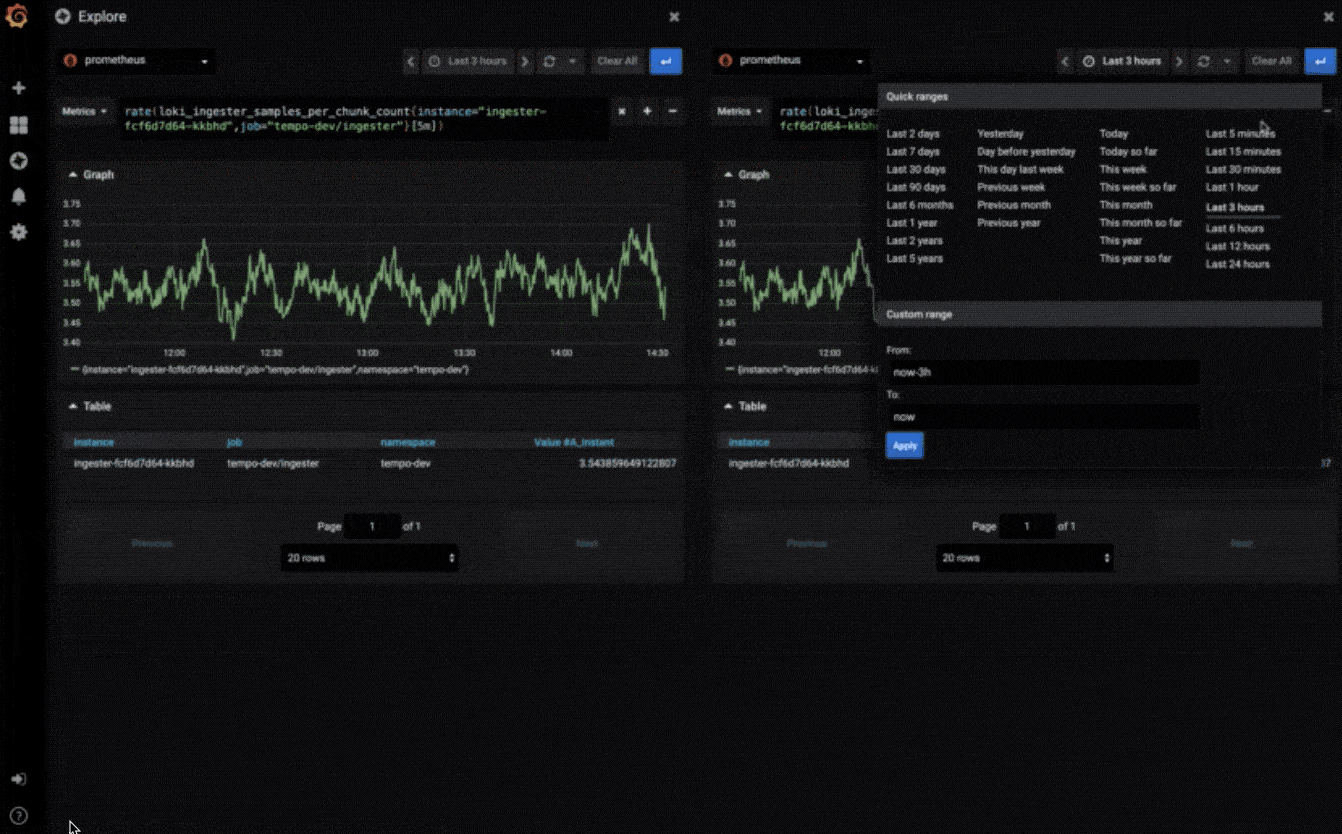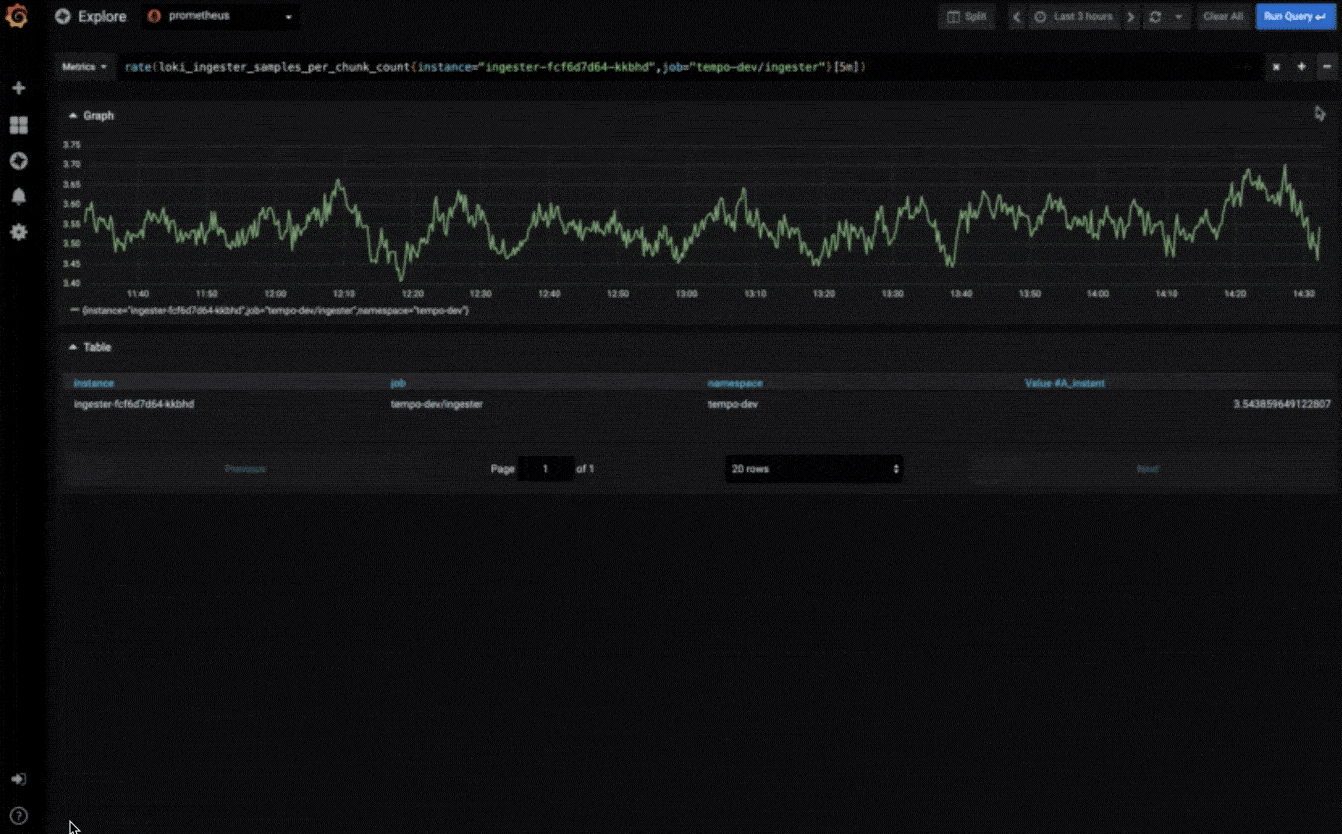
探索日志
快速搜索所有日志或实时流式传输(与 Loki 数据源配合使用效果最佳)。

警报
以可视方式定义最重要指标的警报规则。Grafana 将不断评估并向 Slack,PagerDuty,VictorOps 和 OpsGenie 等系统发送通知。
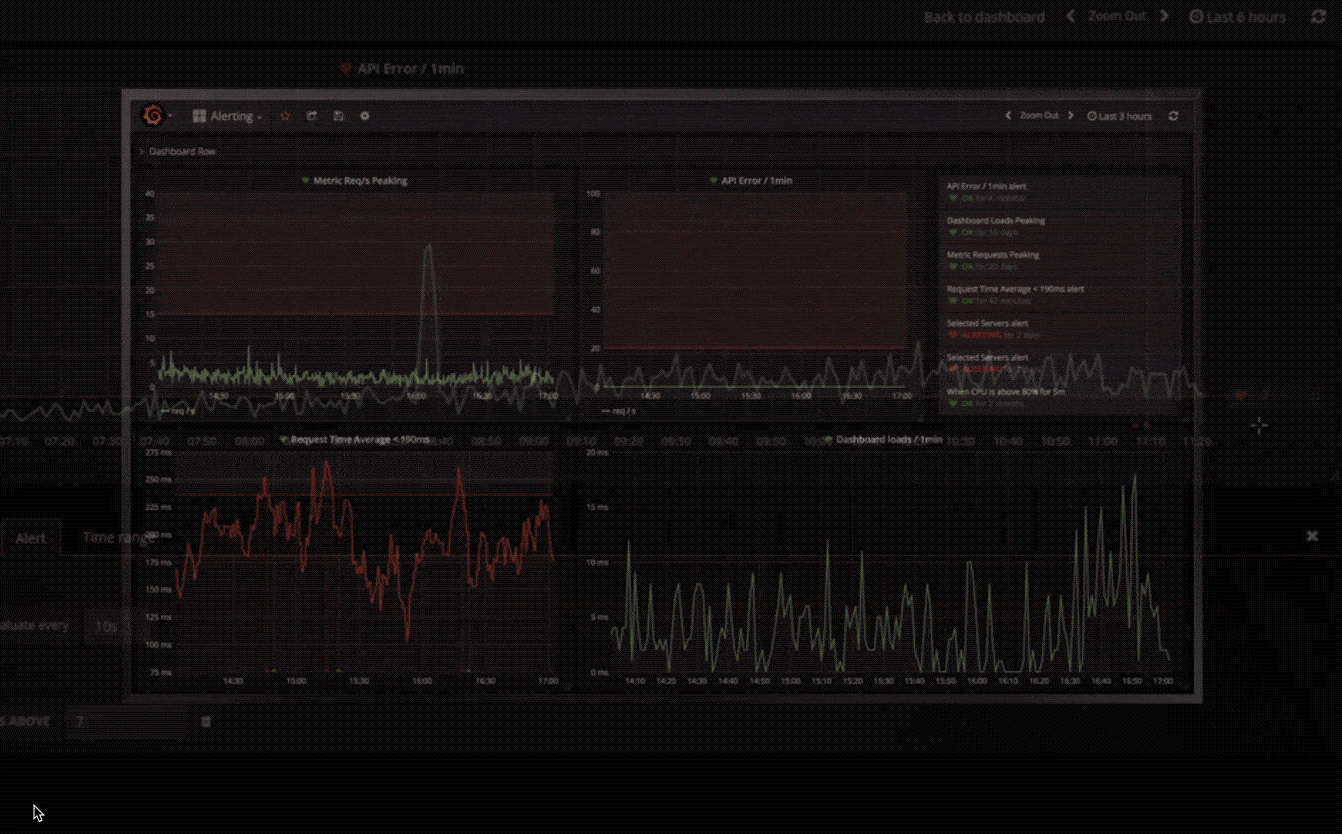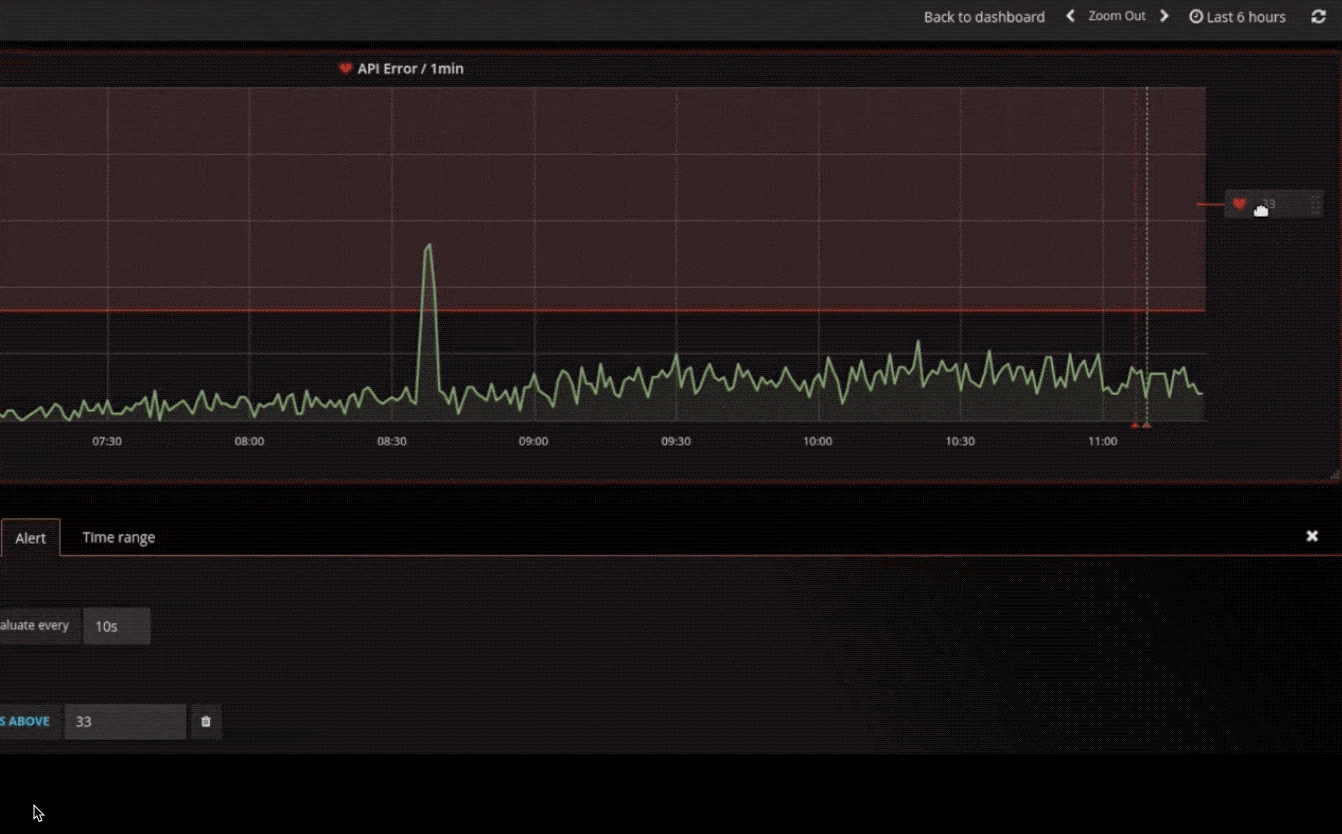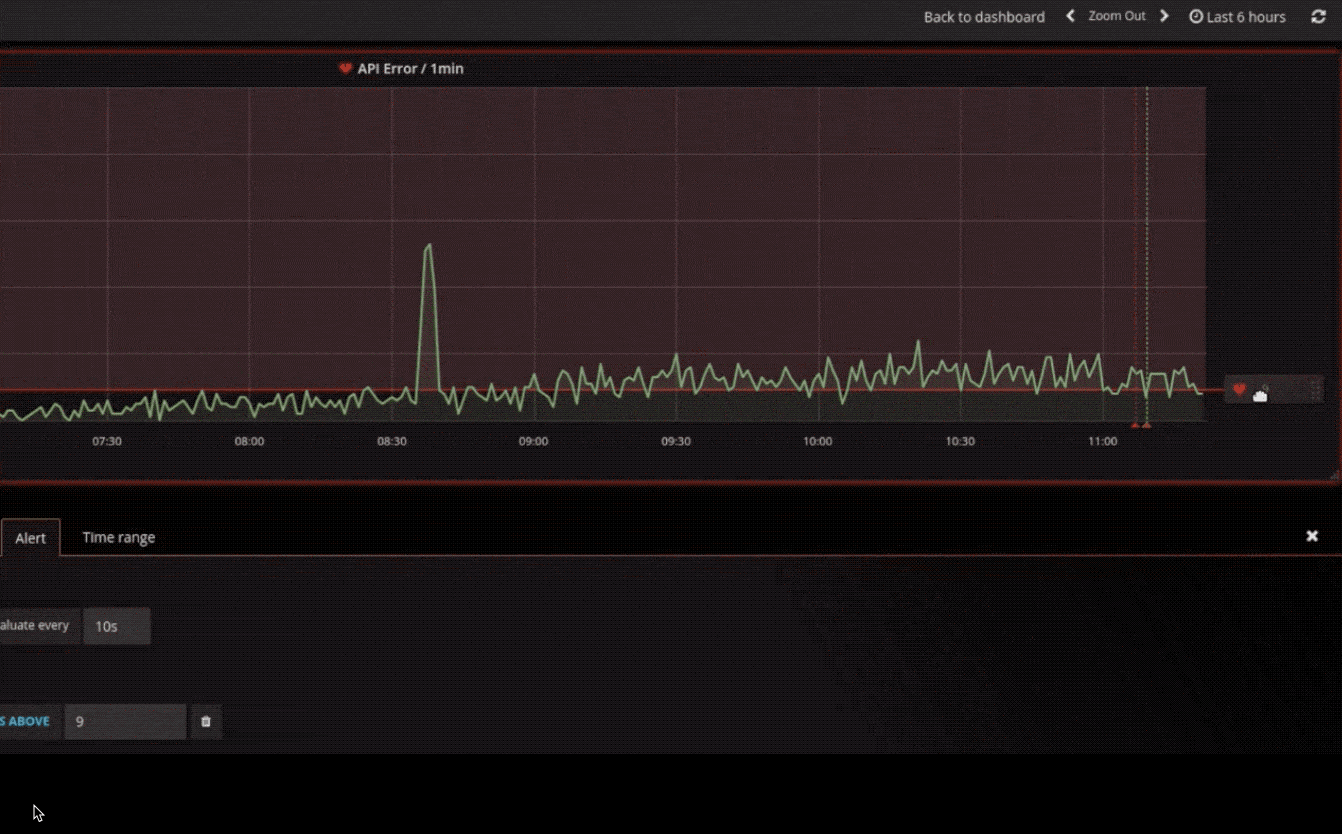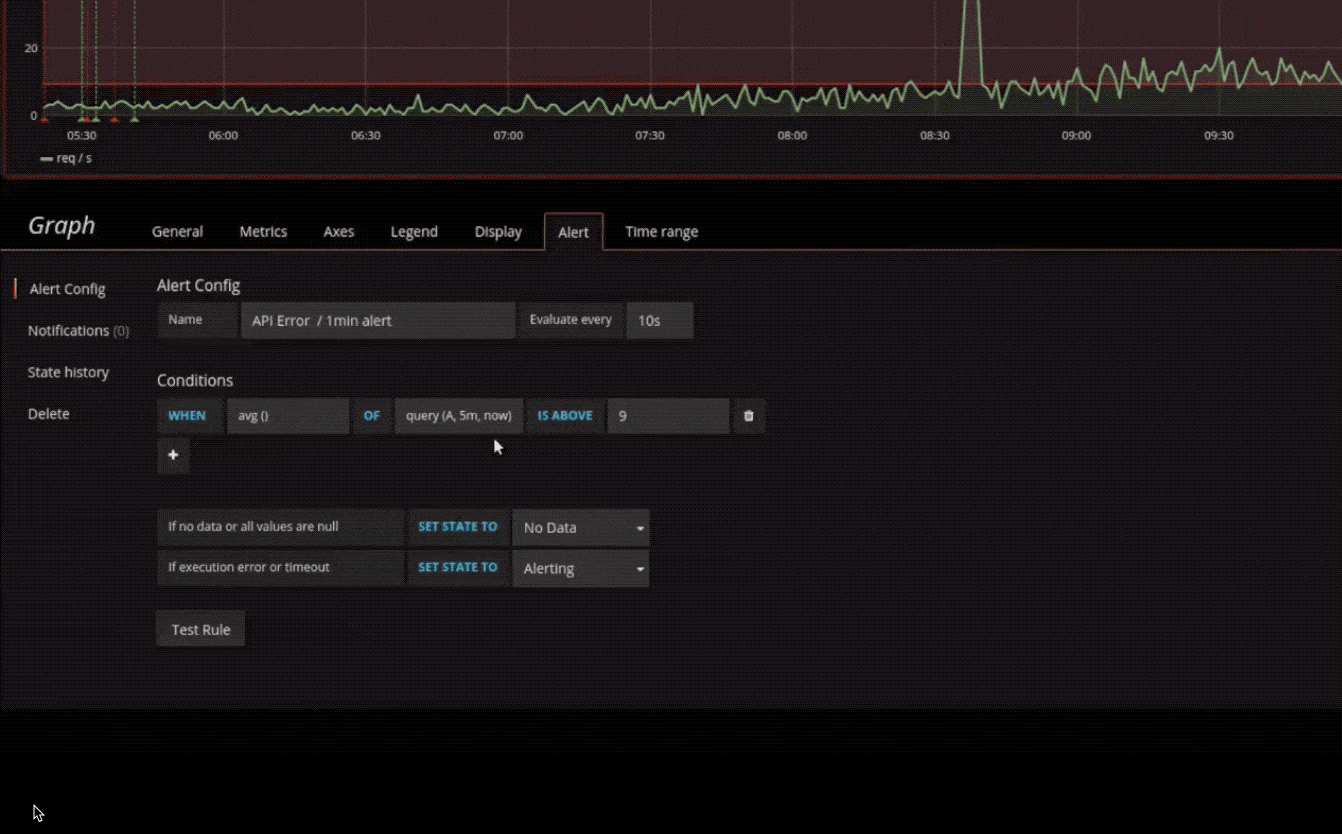
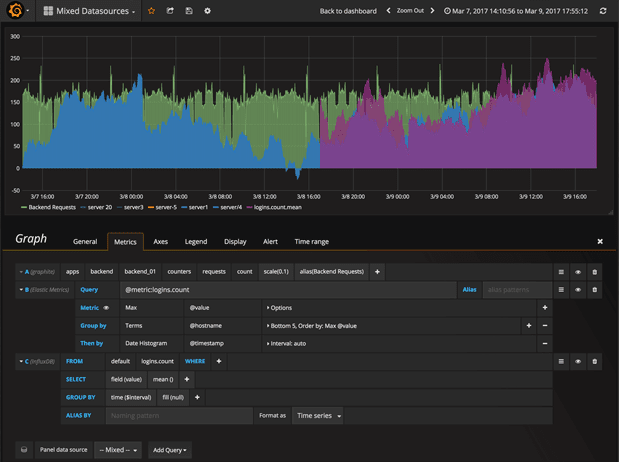
混合数据源
在同一张图中混合使用不同的数据源!你可以为每个查询指定数据源(适用于自定义数据源)。
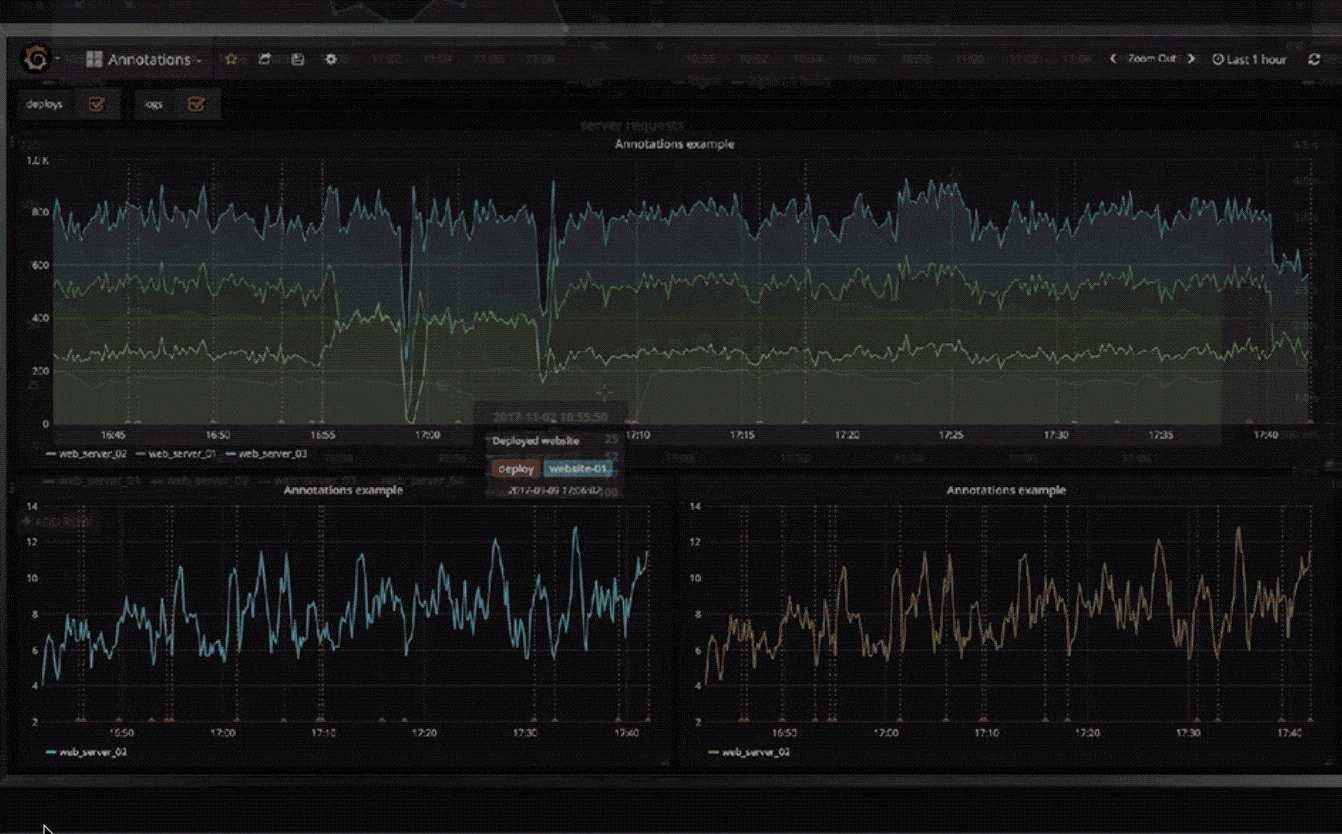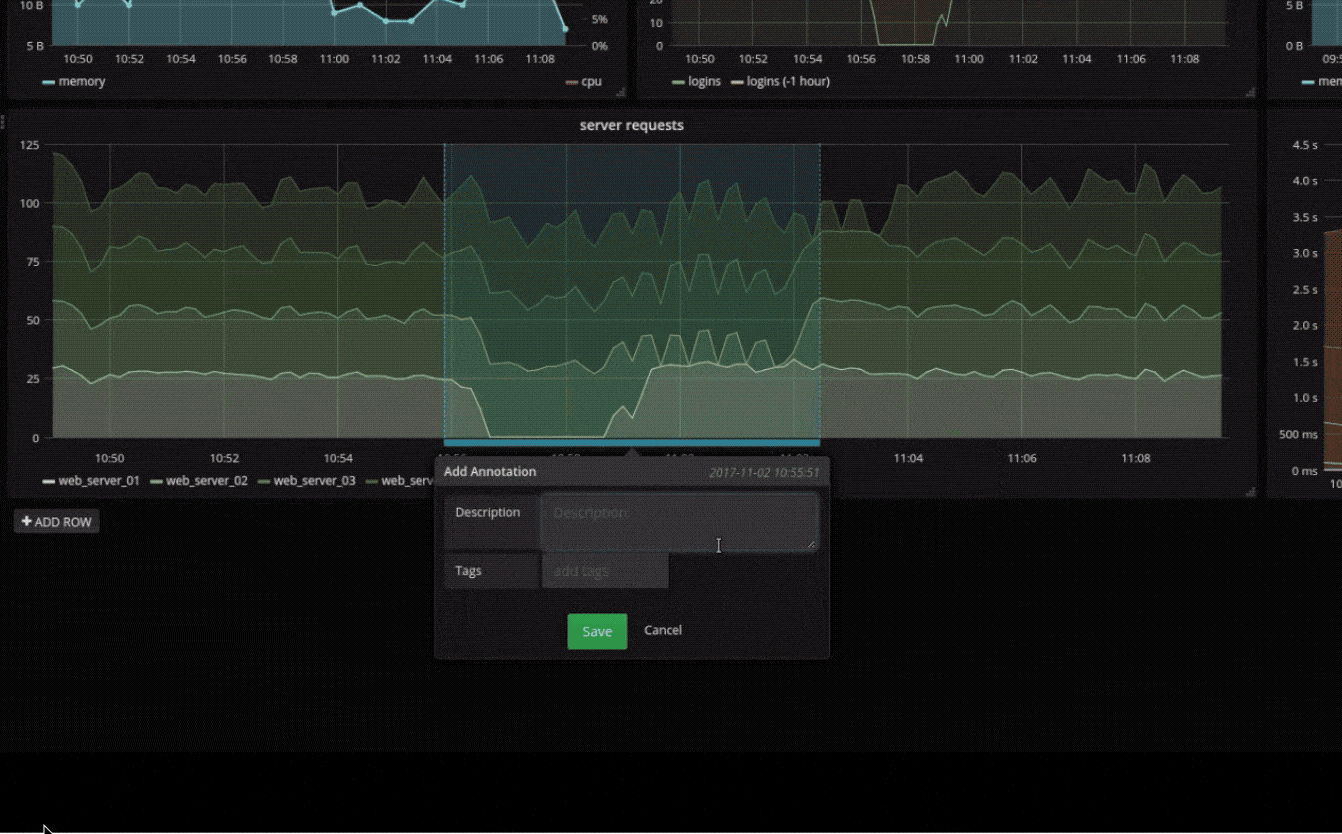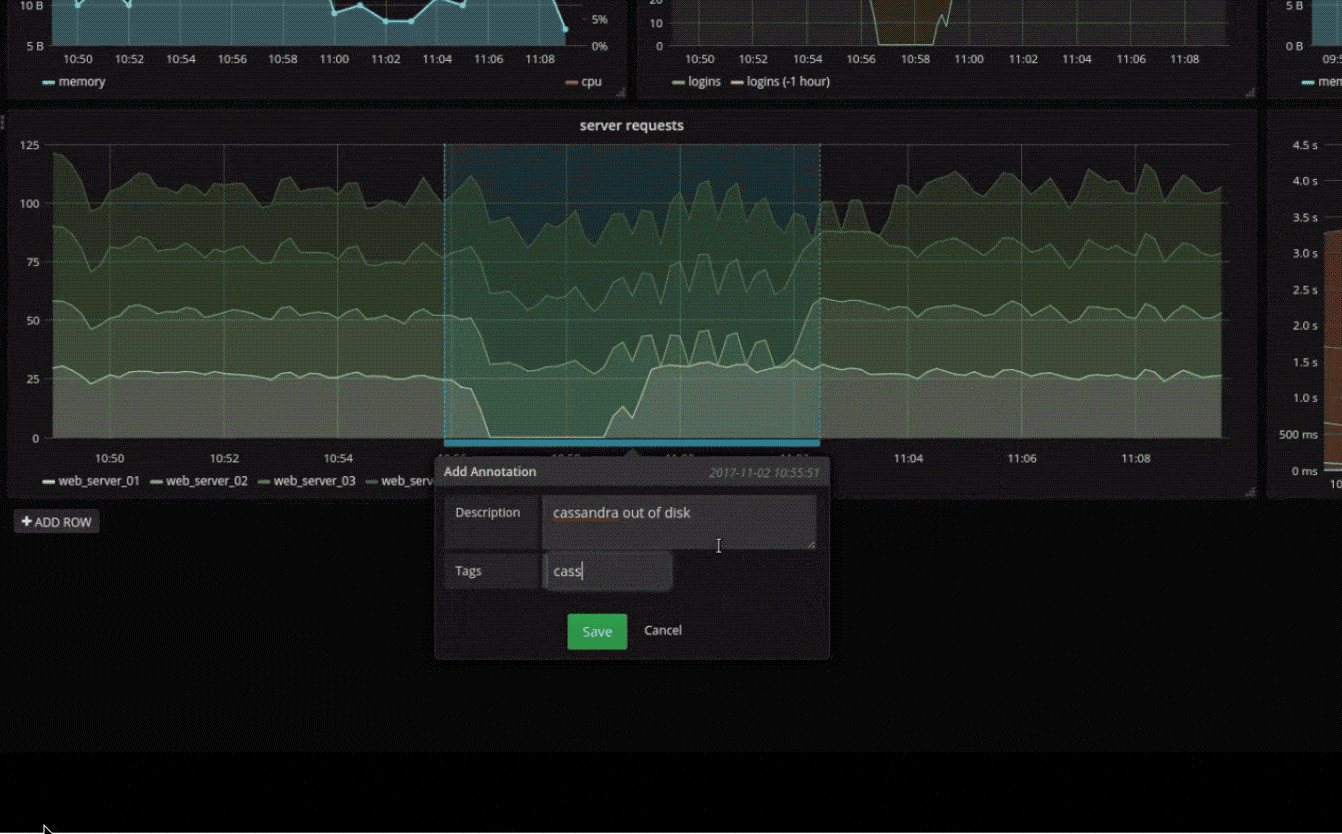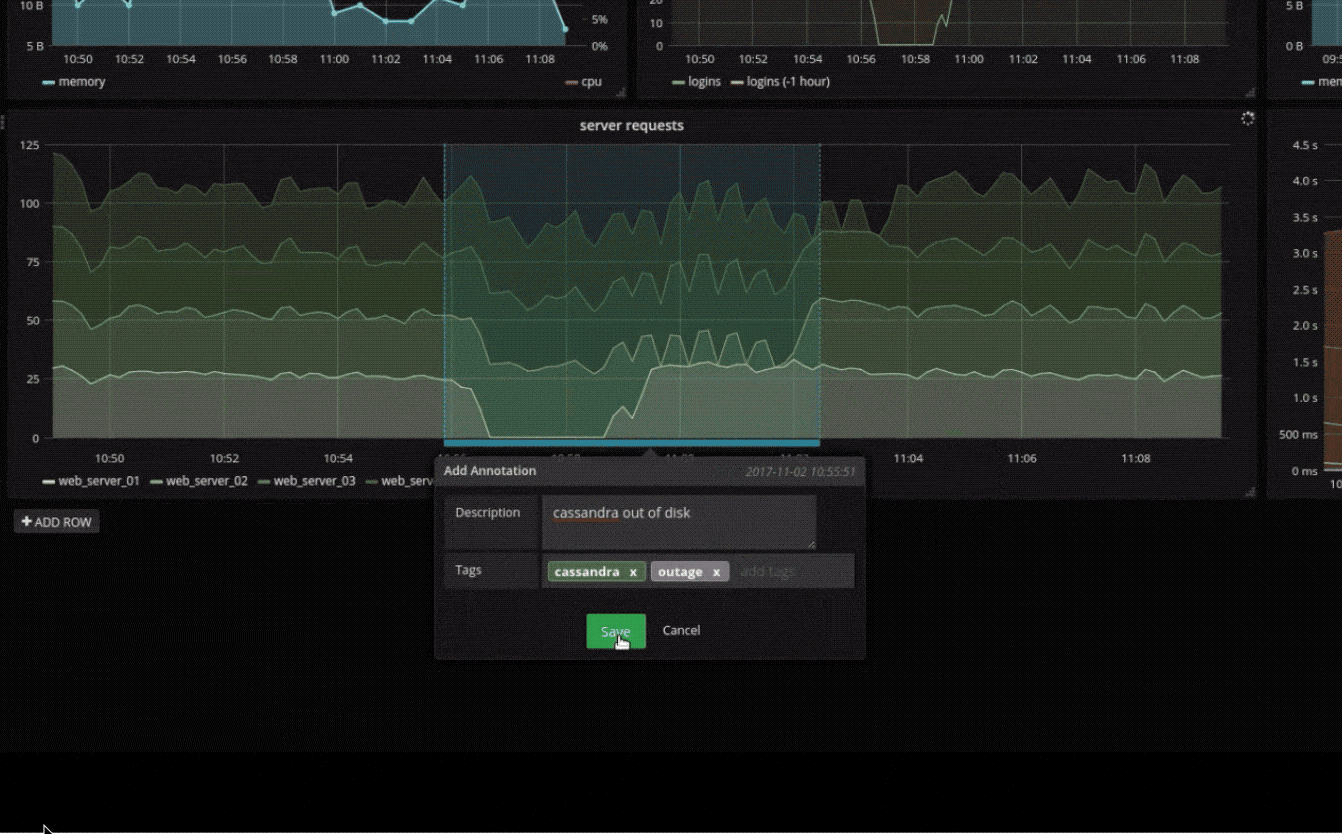
注解
使用来自不同数据源的丰富事件注释图形。将鼠标悬停在事件上会显示完整的事件元数据和标签。
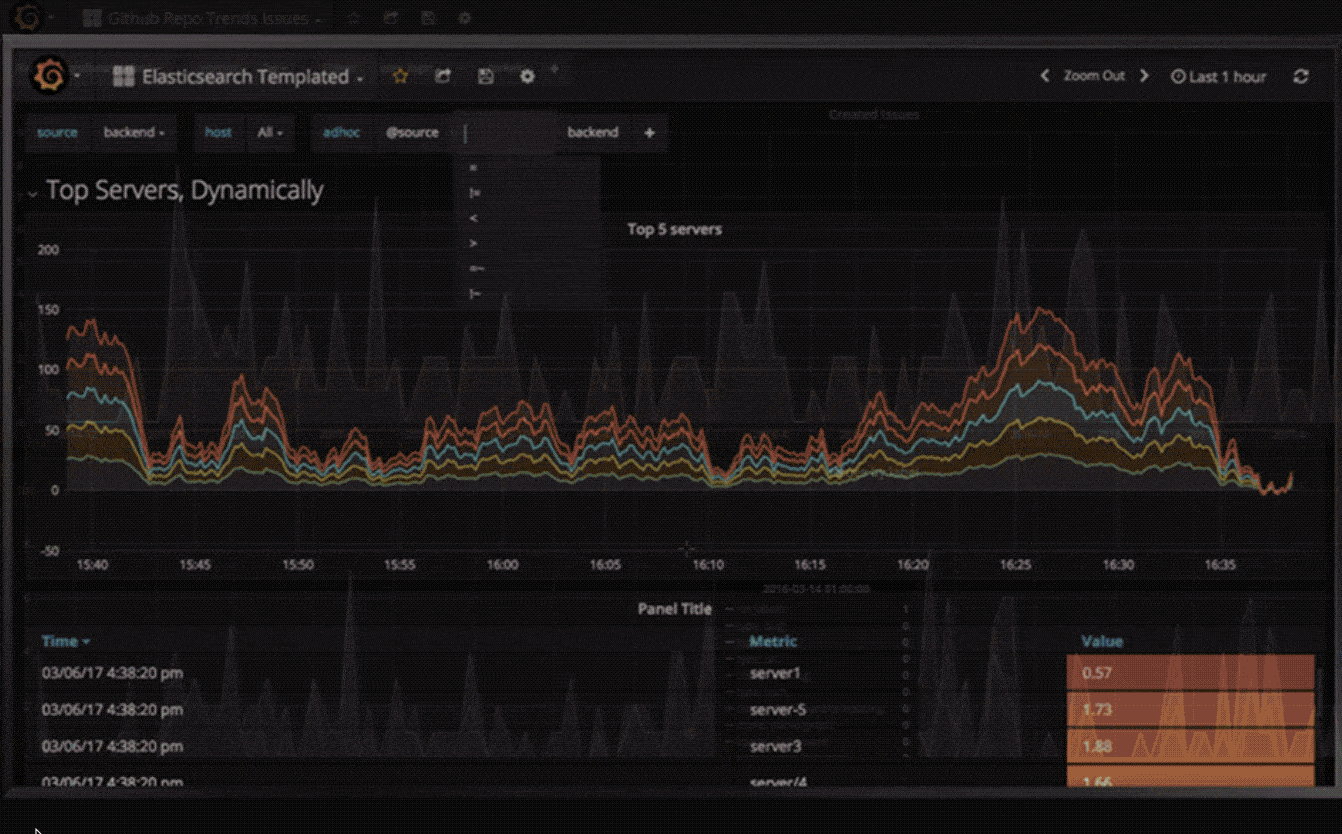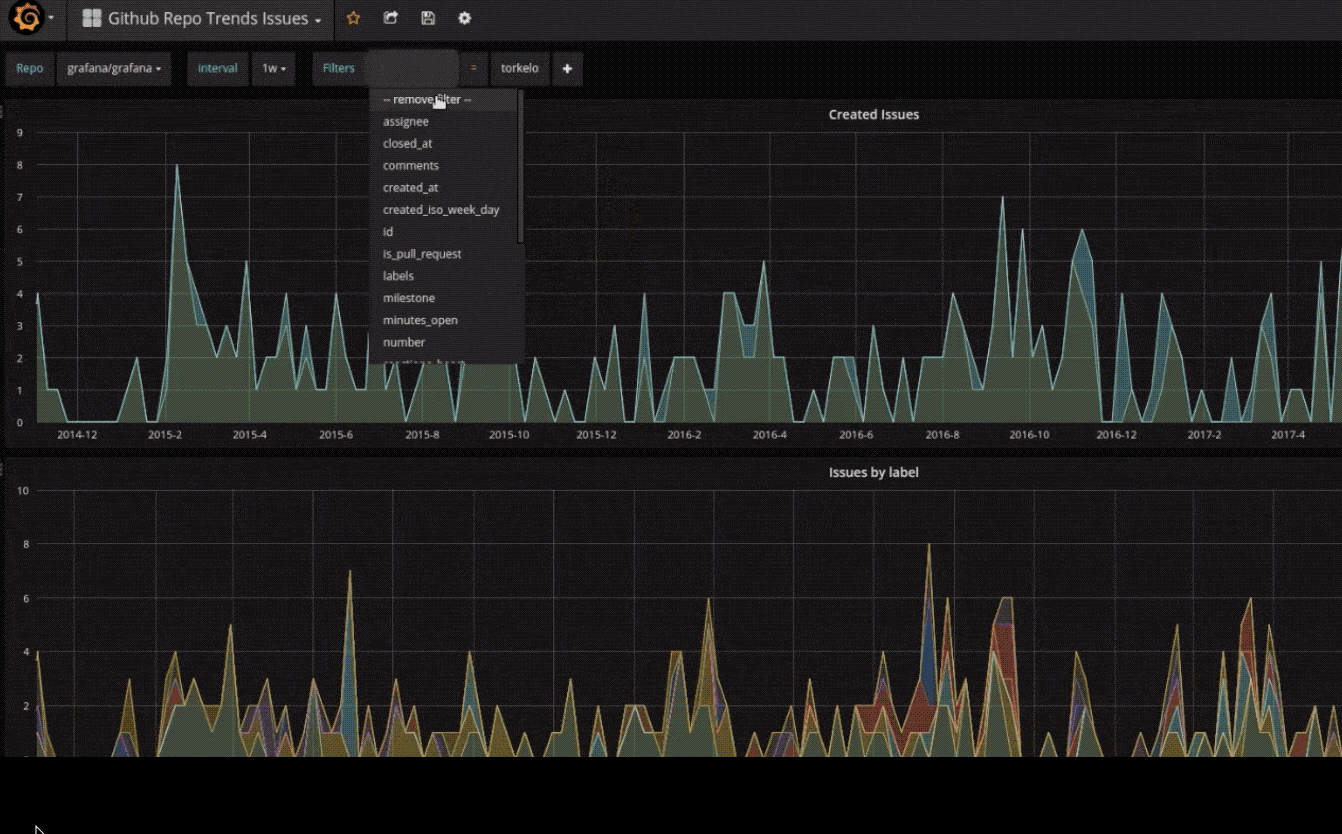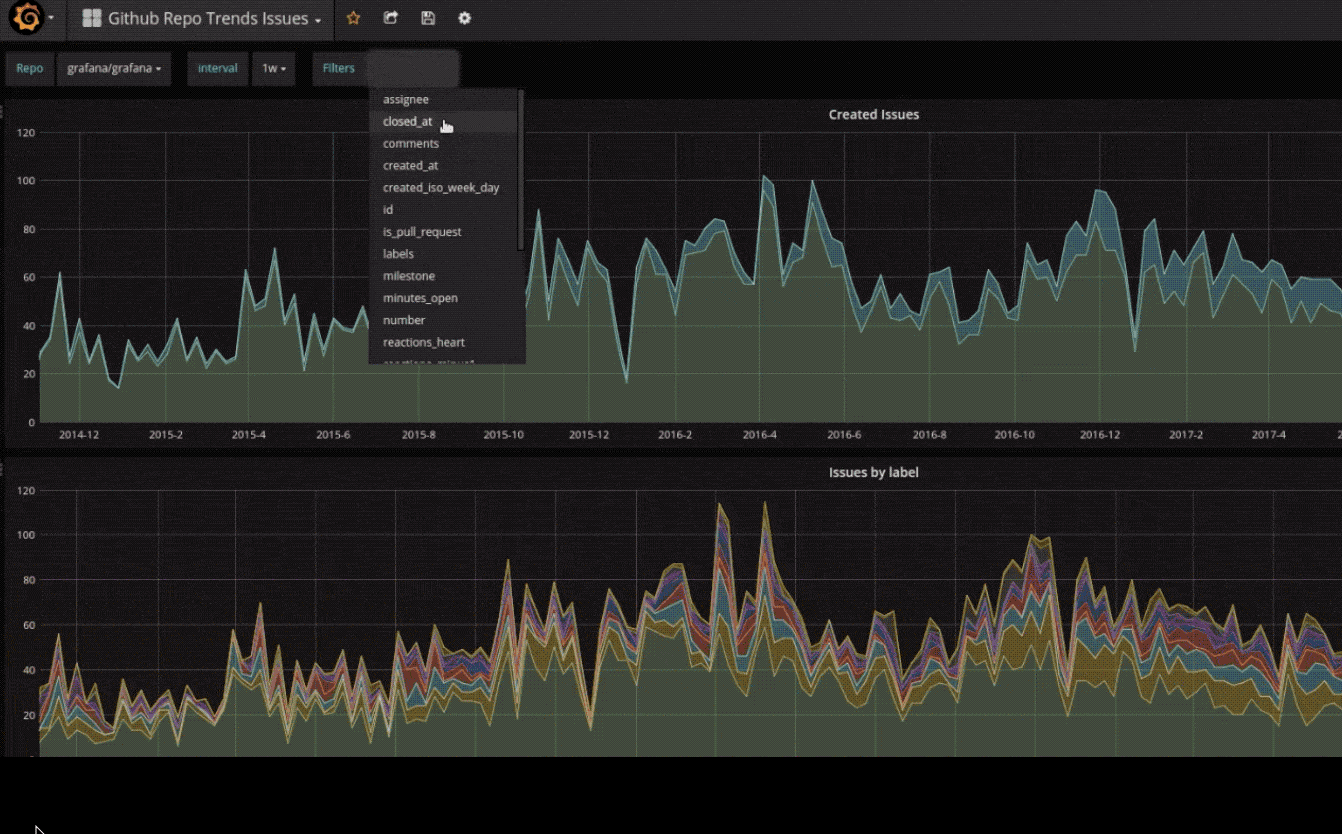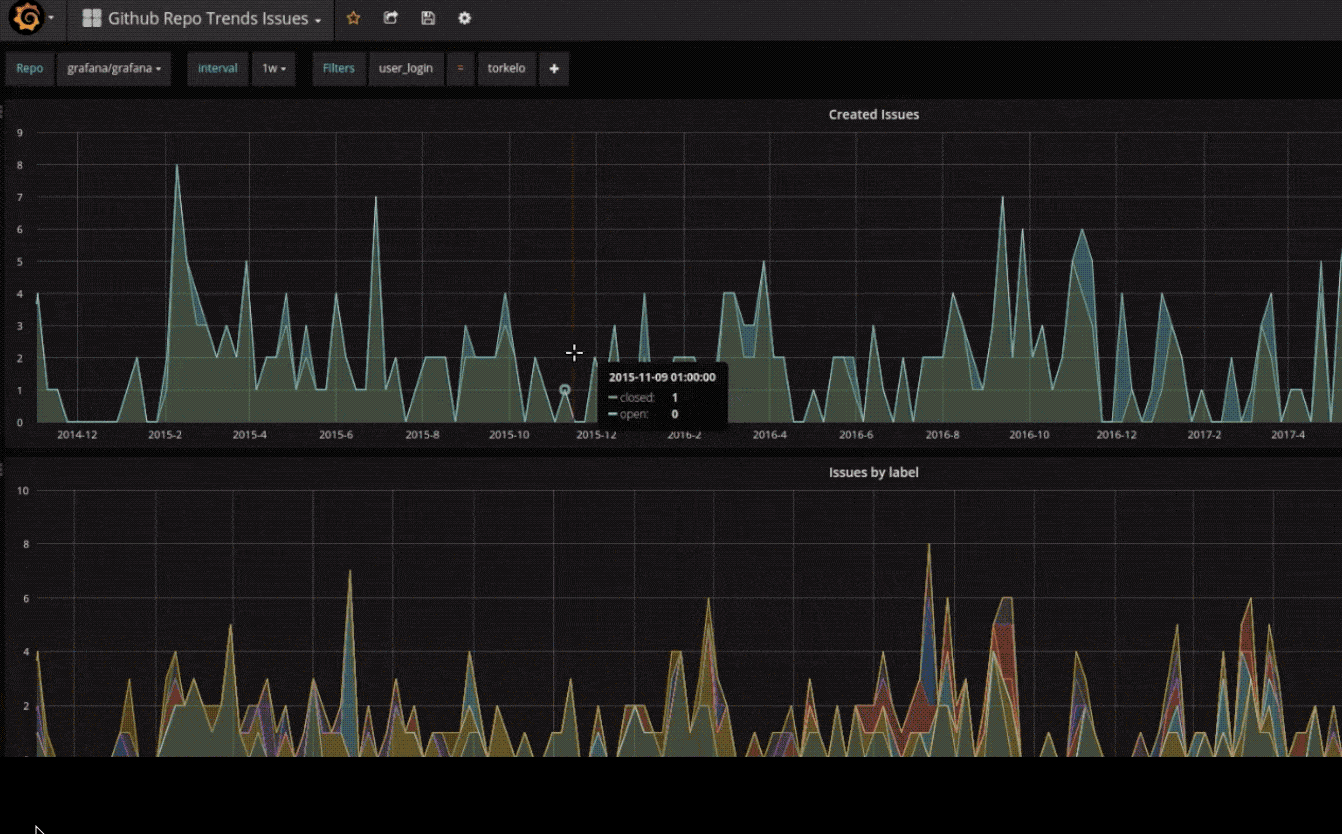
临时过滤器
临时过滤器允许您即时创建新的键/值过滤器,这些过滤器会自动应用于使用该数据源的所有查询。
在线资源
grafana 提供了一些在线资源,可以帮助使用者更方便的使用 grafana,比如在线 dashboard( https://grafana.net/dashboards ) 可以帮助快速生成一个美观的 dashboard,不用自己花心思去布局了,在线插件仓库( https://grafana.net/plugins )可以帮助连接其他数据源,如 zabbix,Open-Falcon 等,或添加其他展示图表,如饼图(Pie chat)。合理利用这些在线资源可以让 grafana 更加完善易用。
- grafana官方文档: http://docs.grafana.org/
- elasticsearch官方文档: https://www.elastic.co/guide/en/elasticsearch/reference/2.4/index.html
ELK stack 中文指南 之 Grafana:https://elkguide.elasticsearch.cn/elasticsearch/other/grafana.html
下载、安装
安装下载:https://grafana.com/grafana/download
这里以 windows 为例,下载完压缩包,直接解压,执行 grafana-server.exe
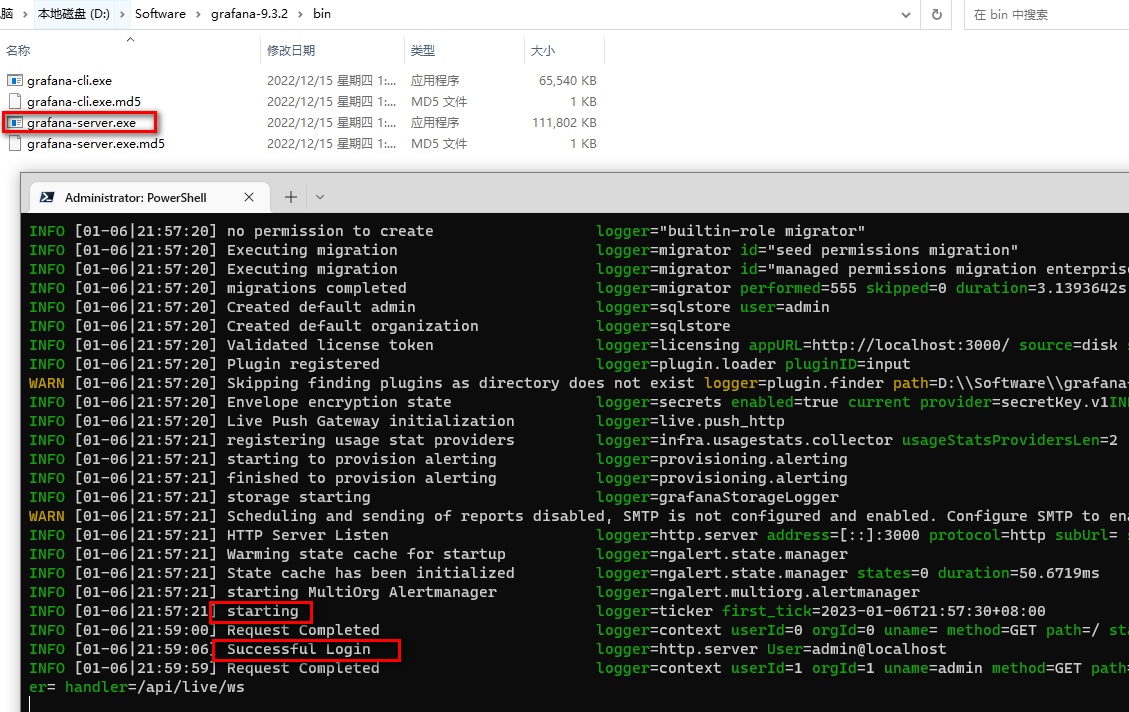
登录 grafana
- 登录 grafana 界面:http://127.0.0.1:3000
- 默认用户和密码均为:admin
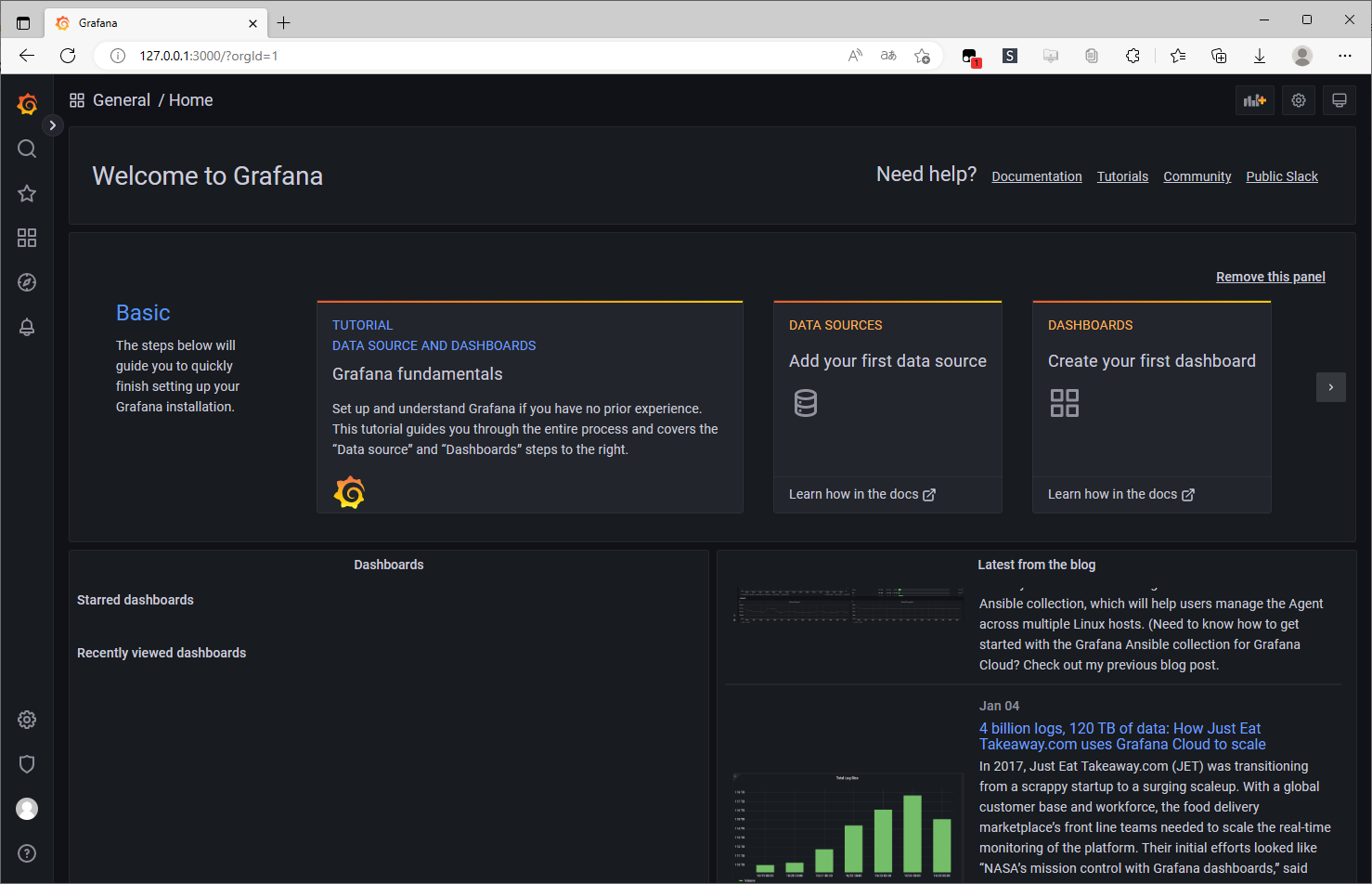
Grafana 安装 插件
这里搜索 zabbix、clock 插件并安装
插件安装完成后位置:D:\Software\grafana-9.3.2\data\plugins
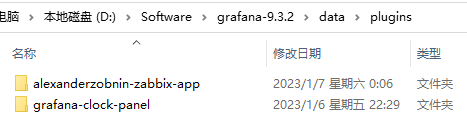
注意:安装完插件后,需要重启 grafana-server,插件才能生效。。。
clock 插件安装之后直接可以使用,无需设置。
zabbix 需要设置添加数据源:https://blog.csdn.net/weixin_62352862/article/details/128254050
2、Grafana 的 Dashboards(看板、仪表盘)
创建 Dashboards
Prometheus入门教程(三):Grafana 图表配置快速入门:https://mp.weixin.qq.com/s/sA0nYevO8yz6QLRz03qJSw
Dashboard(仪表盘)与 Panel(面板)是 Prometheus 的基本单元,所有的监控数据都会通过这两个东西来呈现。Panel 是 Prometheus 中数据呈现的最小单元。
一个 Dashboard 中可以有多个 Panel。我们看到的 Dashboard 数据,都是由一个个 Panel 构成的。Panel 的设置区域一共可以分为三部分:
- 预览区:用来预览设置的图表。
- 数据设置区:用来设置数据源、数据指标等。
- 图表设置区:用来对图表的名称等进行设置。
Dashboard 就是一个大的面板,里面包含了无数个图表(Panel)
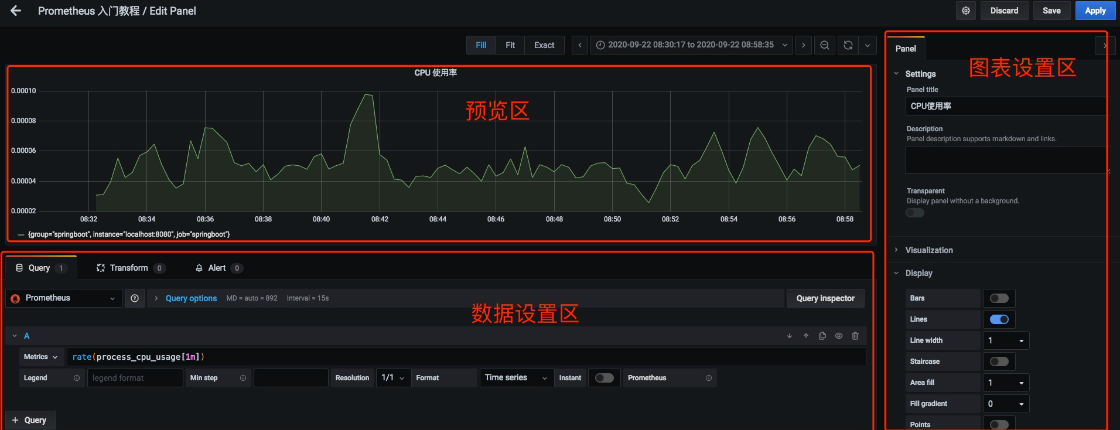
数据设置区可以分为三个设置区域,分别是:
- 查询设置区:设置查询数据的数据源、指标等。
- 转换设置区:可以对查询出来的数据进行过滤等。
- 告警设置区:可以对设置的指标设置告警规则。
手动 创建 Dashboards
可以根据自己的需求手动新建一个 Dashboard。除此之外,https://grafana.com/grafana/dashboards 上还有很多公共的 Dashboard 可以选用。
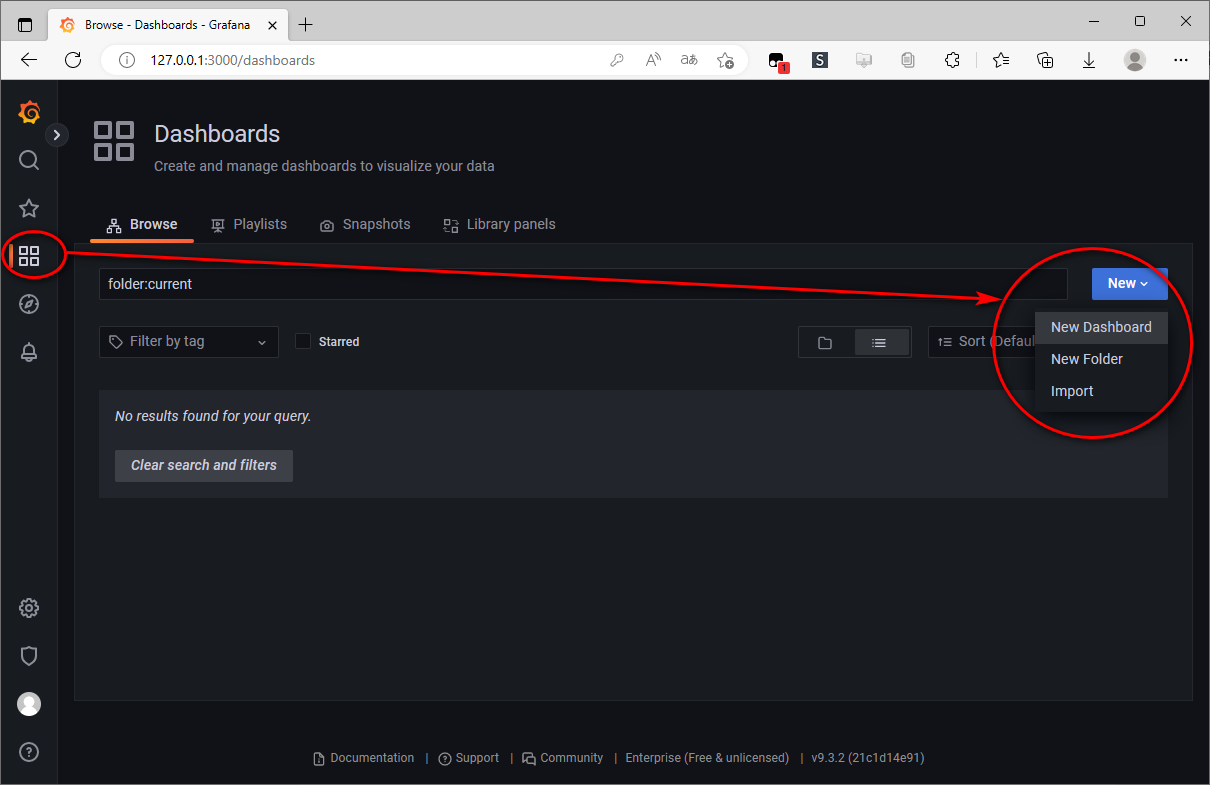
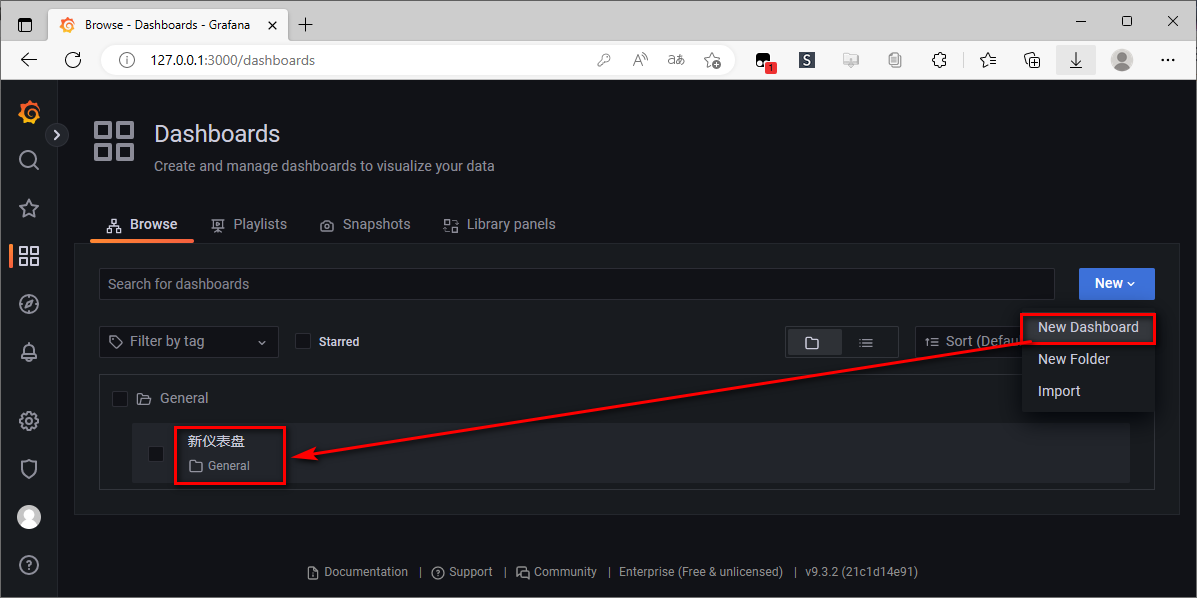
导入 公共 Dashboards
更多的模板,我们也可以去 grafana 官网下载监控面板
下载网址:https://grafana.com/grafana/dashboards?dataSource=prometheus
仪表盘 添加 面板(panel)
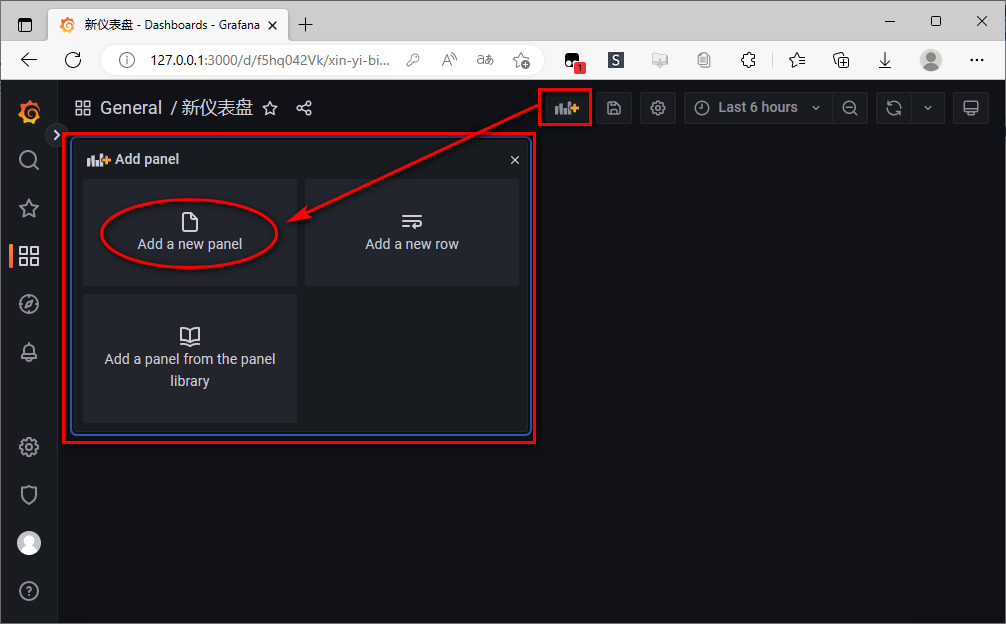
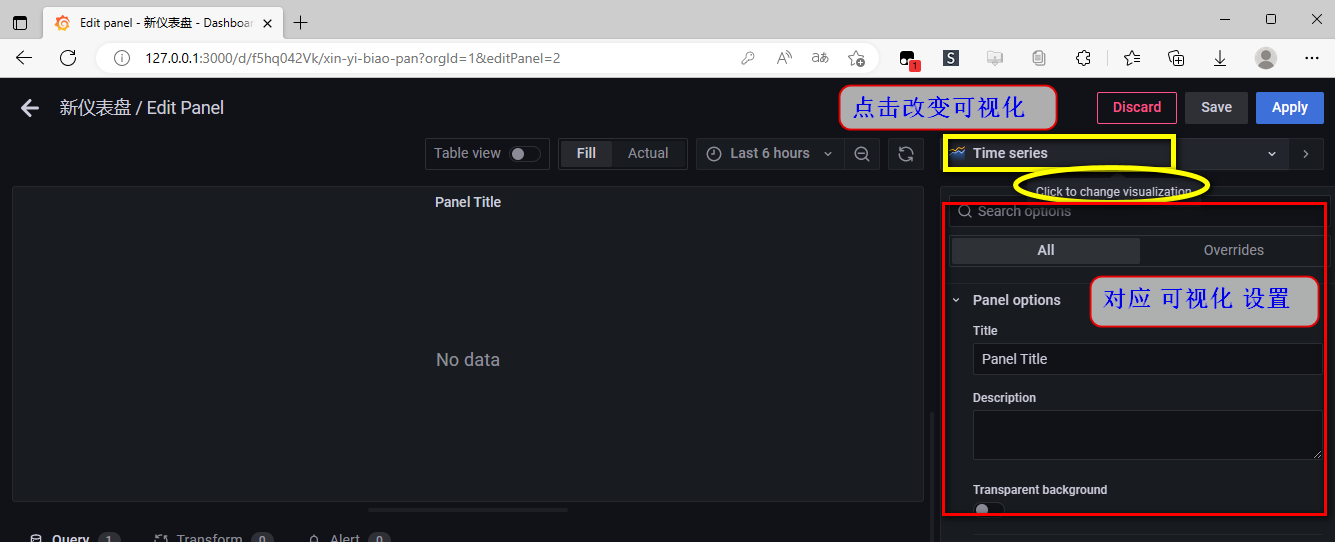
面板(panel) 的 可视化
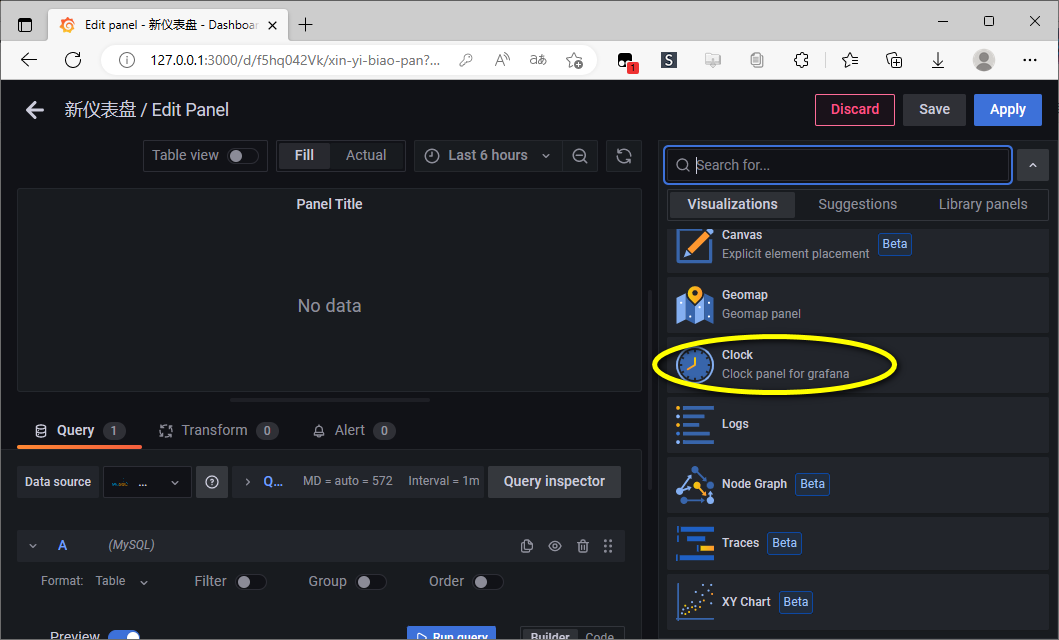
设置 面板的可视化为 clock
示例:面板可视化 --- 添加 时间 仪表板
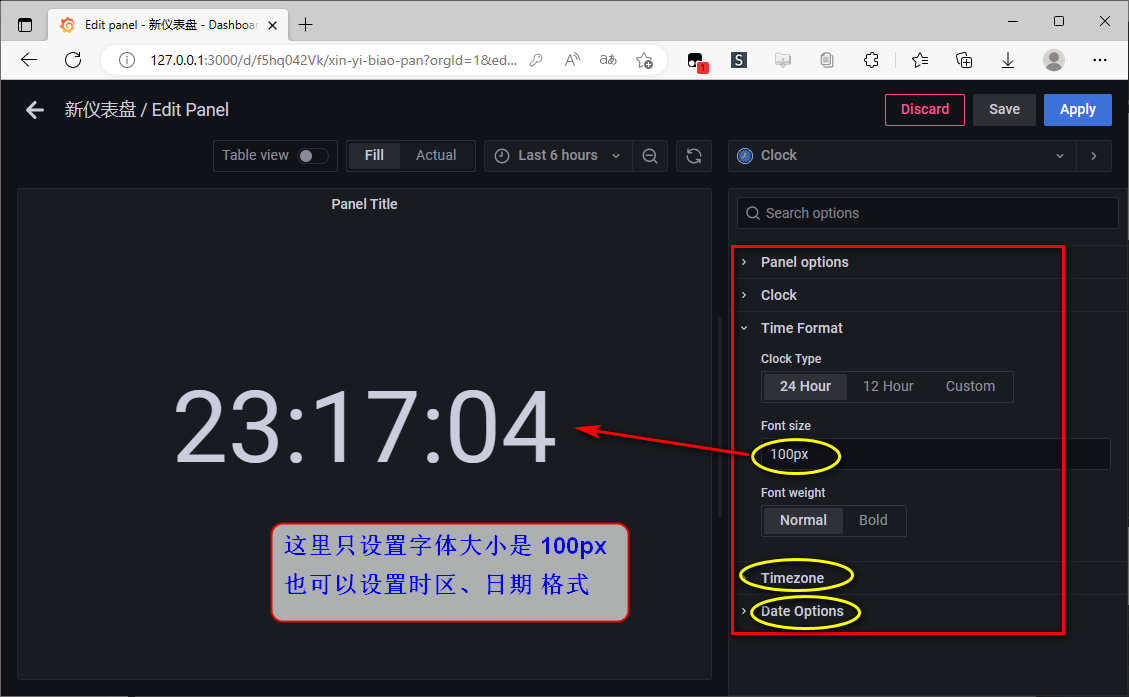
仪表盘 布局
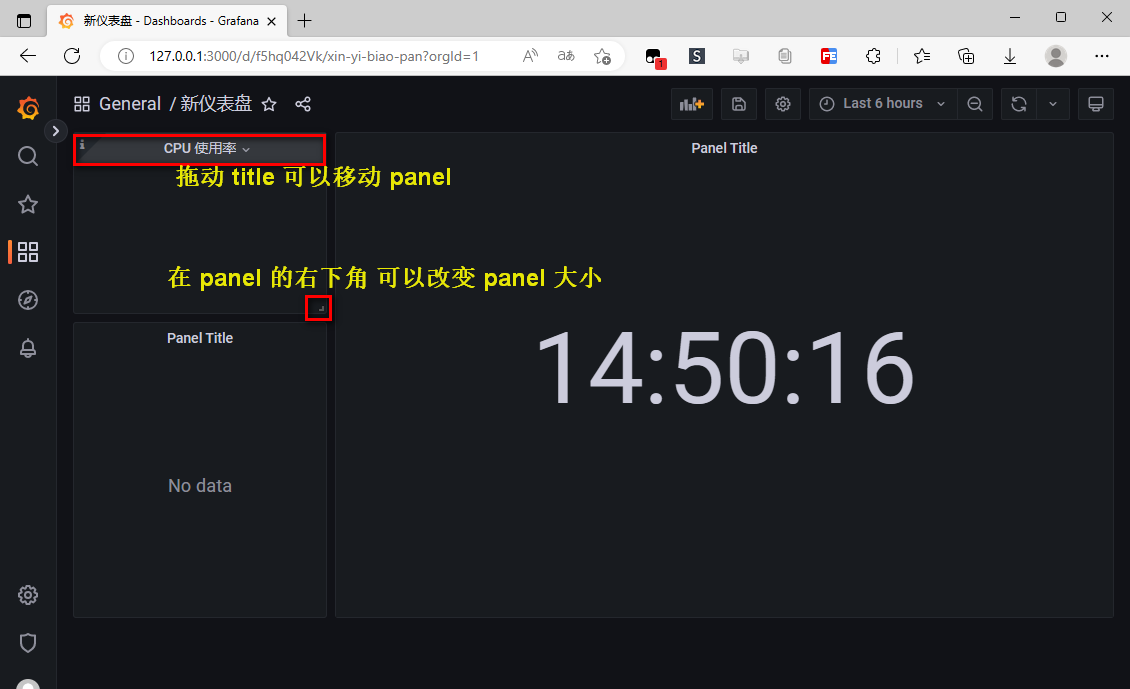
示例:面板可视化 --- 创建 CPU、内存使用率 仪表板
关键字:grafana cpu
Prometheus + Grafana 监控系统部署:https://zhuanlan.zhihu.com/p/425304902
主机基础监控(cpu,内存,磁盘,网络):https://grafana.com/grafana/dashboards/9276-1-cpu/
clock、zabbix 简单使用:https://www.zhangshengrong.com/p/v710KdGrXM/
示例:微服务监控 - Grafana 使用教程
:https://makeoptim.com/service-mesh/prometheus-grafana
3、Grafana 使用教程
:https://blog.csdn.net/bbwangj/article/details/81109615
1、登录grafana 界面
2、配置Grafana启用zabbix插件
3、配置Zabbix数据源
4、添加仪表板(仪表盘的使用)、面板
5、创建流量监控图形
6、仪表盘模板功能
7、查询格式
8、变量的使用
4、爬虫可视化动态监控
Grafana+InfluxDB+MongoDB 爬虫可视化动态监控:https://www.jianshu.com/p/9de223e05a5e
原理:爬虫将抓取的数据写入MongoDB,InfluxDB从MongoDB获取数据抓取情况,Grafana 从 InfluxDB 中获取爬虫抓取数据情况并做图形化展示。
InfluxDB 介绍
- InfluxDB 简介
-- InfluxDB 是一个当下比较流行的时序数据库;
-- InfluxDB 使用 Go 语言编写;
-- InfluxDB 无需外部依赖;
-- InfluxDB 适合构建大型分布式系统的监控系统。 - 主要特色功能:
-- 基于时间序列:支持与时间有关的相关函数(如最大,最小,求和等);
-- 可度量性:可以实时对大量数据进行计算;
-- 基于事件:它支持任意的事件数据;
安装、配置 Grafana、InfluxDB,这里省略。。。
爬虫脚本:
# -*- coding:utf-8 -*-
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import re
from selenium.common.exceptions import TimeoutException
from config import *
from lxml import etree
import pymongo
import datetime
# 设置MongoDB数据库
MONGO_URL = 'localhost'
# 设置 MongoDB 的 database 名称为 learn_selenium_doubandianying
MONGO_DB = 'learn_selenium_doubandianying'
# 设置 MongoDB 的 table 名称为 movie_info
MONGO_TABLE = 'movie_info'
client = pymongo.MongoClient(MONGO_URL)
db = client[MONGO_DB]
browser = webdriver.Chrome()
wait = WebDriverWait(browser,10)
browser.get('https://movie.douban.com/')
word = input('请输入您要搜索的内容>>> ')
def search():
try:
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'#inp-query'))
)
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR,'#db-nav-movie > div.nav-wrap > div > div.nav-search > form > fieldset > div.inp-btn > input[type="submit"]'))
)
print('输入搜索的内容【{}】'.format(word))
input.send_keys('{}'.format(word))
submit.click()
print('正在加载')
active = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'a.num.activate.thispage'))
)
print('加载第【{}】页成功'.format(active.text))
get_movies()
except TimeoutException:
print('等待超时,重新搜索...')
return search()
def next_page():
while True:
try:
next_page_submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR,'a.next'))
)
next_page_submit.click()
wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'a.num.activate.thispage'))
)
print('成功加载该页数据...')
get_movies()
print('--------------加载完成,并打印成功,开始加载下一页------------')
time.sleep(1.1)
next_page()
except TimeoutException:
print('加载超时,重新加载...')
return next_page()
except Exception:
print('加载至最后一页')
break
def get_movies():
try:
page = browser.page_source
selector = etree.HTML(page)
items = selector.xpath('//*[@id="root"]/div/div[2]/div[1]/div[1]')
for item in items:
names = item.xpath('div/div/div/div[1]/a/text()')
urls = item.xpath('div/div/div/div[1]/a/@href')
ratings = item.xpath('div/div/div/div[2]/span[2]/text()')
# 【注意】item.xpath()返回的是列表,需要使用str将其字符化
durations = re.findall(r'\d\d+',str(item.xpath('div/div/div/div[3]/text()')))
actors = item.xpath('div/div/div/div[4]/text()')
# 【注意】由于xpath返回的是列表格式,而我们需要将列表中的元素一一对应存放至字典中,这就需要使用zip()函数,将内容存放至空字典中
for name,url,rating,duration,actor in zip(names,urls,ratings,durations,actors):
movie_info = {}
movie_info['name'] = name
movie_info['url'] = url
if rating == '(尚未上映)' or '(暂无评分)':
movie_info['rating'] = None
else:
movie_info['rating'] = float(rating)
movie_info['duration'] = int(duration)
movie_info['actors'] = actor
print(movie_info)
save_to_mongo(movie_info)
except Exception as e:
print(e)
time.sleep(0.3)
return get_movies()
def save_to_mongo(result):
try:
if db[MONGO_TABLE].insert_one(result):
print('成功存储到MONGODB!')
except Exception as e:
raise e
def main():
start_time = datetime.datetime.now()
try:
search()
next_page()
except Exception as e:
raise e
finally:
browser.close()
end_time = datetime.datetime.now()
print('*'*100)
print('开始时间:',start_time)
print('结束时间:',end_time)
print('共计用时:',end_time - start_time)
total_nums = db[MONGO_TABLE].count()
print('共计获取数据:',total_nums,' 条')
print('*'*100)
if __name__ == '__main__':
main()编写监控脚本 influx_monitor.py
import ast
import time
import pymongo
import traceback
from configparser import ConfigParser
from influxdb import InfluxDBClient
from datetime import datetime
from os.path import getmtime
# 配置 influxdb
client = InfluxDBClient(host='localhost', port=8086) # influxdb默认端口为8086
# 创建 database
client.create_database('Spider')
# switch 到 database
client.switch_database('Spider')
# 设定配置文件
config_name = 'influx_settings.conf'
WATCHED_FILES = [config_name]
WATCHED_FILES_MTIMES = [(f, getmtime(f)) for f in WATCHED_FILES]
_count_dict = {}
_size_dict = {}
# 获取配置文件中的设置
def parse_config(file_name):
try:
# 创建一个配置文件对象
cf = ConfigParser()
# 打开配置文件
cf.read(file_name)
# 获取配置文件中的统计频率
interval = cf.getint('time', 'interval')
# 获取配置文件中要监控的 dbs 和 collection
dbs_and_collections = ast.literal_eval(cf.get('db', 'db_collection_dict'))
return interval, dbs_and_collections
except:
print(traceback.print_exc())
return None
# 从 MongoDB 获取数据,并写入 InfluxDB
def insert_data(dbs_and_collections):
# 连接 MongoDB 数据库
mongodb_client = pymongo.MongoClient(host='127.0.0.1',port=27017) # 直接使用默认地址端口连接 MongoDB
for db_name, collection_name in dbs_and_collections.items():
# 数据库操作,创建 collection 集合对象
db = mongodb_client[db_name]
collection = db[collection_name]
# 获取 collection 集合大小
collection_size = round(float(db.command("collstats", collection_name).get('size')) / 1024 / 1024, 2)
# 获取 collection 集合内数据条数
current_count = collection.count()
# 初始化数据条数,当程序刚执行时,条数初始量就设置为第一次执行时获取的数据
init_count = _count_dict.get(collection_name, current_count)
# 初始化数据大小,当程序刚执行时,大小初始量就设置为第一次执行时获取的数据大小
init_size = _size_dict.get(collection_name, collection_size)
# 得到数据条数增长量
increase_amount = current_count - init_count
# 得到数据大小增长量
increase_collection_size = collection_size - init_size
# 得到当前时间
current_time = datetime.utcnow().strftime('%Y-%m-%dT%H:%M:%SZ')
# 赋值
_count_dict[collection_name] = current_count
_size_dict[collection_name] = collection_size
# 构建
json_body = [
{
"measurement": "crawler",
"time": current_time,
"tags": {
"spider_name": collection_name
},
"fields": {
"count": current_count,
"increase_count": increase_amount,
"size": collection_size,
"increase_size": increase_collection_size
}
}
]
# 将获取
if client.write_points(json_body):
print('成功写入influxdb!',json_body)
def main():
# 获取配置文件中的监控频率和MongoDB数据库设置
interval, dbs_and_collexctions = parse_config(config_name)
# 如果配置有问题则报错
if (interval or dbs_and_collexctions) is None:
raise ValueError('配置有问题,请打开配置文件重新设置!')
print('设置监控频率:', interval)
print('设置要监控的MongoDB数据库和集合:', dbs_and_collexctions)
last_interval = interval
last_dbs_and_collexctions = dbs_and_collexctions
# 这里实现配置文件热更新
for f, mtime in WATCHED_FILES_MTIMES:
while True:
# 检查配置更新情况,如果文件有被修改,则重新获取配置内容
if getmtime(f) != mtime:
# 获取配置信息
interval, dbs_and_collections = parse_config(config_name)
print('提示:配置文件于 %s 更新!' % (time.strftime("%Y-%m-%d %H:%M:%S")))
# 如果配置有问题,则使用上一次的配置
if (interval or dbs_and_collexctions) is None:
interval = last_interval
dbs_and_collexctions = last_dbs_and_collexctions
else:
print('使用新配置!')
print('新配置内容:', interval, dbs_and_collexctions)
mtime = getmtime(f)
# 写入 influxdb 数据库
insert_data(dbs_and_collexctions)
# 使用 sleep 设置每次写入的时间间隔
time.sleep(interval)
if __name__ == '__main__':
main()配置文件 influx_settings.conf
配置文件主要用于热更新相关设置 。
# [需要监控的 MongoDB 数据的 数据库名 和 集合名]
[db]
db_collection_dict = {
'learn_selenium_doubandianying': 'movie_info',
}# [设置循环间隔时间]
[time]
interval = 8
运行 influxDB 监控:python3 influx_monitor.py
新建一个 terminal 窗口,使用 vi 命令修改配置文件 influx_settings.conf,修改间隔时间为8秒,并保存退出。这时运行 influxDB 的窗口,提示配置更新,说明配置热更新可用。
启动 grafana
运行爬虫文件
Grafana web 窗口设置:新建 dashboard、修改 dashboard 设置、设置监控的数据对象
5、python进行数据可视化
现在市面上可以使用 python 的可视化库多如牛毛,各有各的优点。一个经典的可视化库 matplotlib 它是基于 NumPy 的一个数据可视化工具,内置了非常多图给我们使用。下载这个库
python -m pip install matplotlib
示例:画 sin 和 cos线
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(-np.pi, np.pi, 256)
cos = np.cos(x)
sin = np.sin(x)
plt.plot(x, cos, '--', linewidth=2)
plt.plot(x, sin)
plt.show()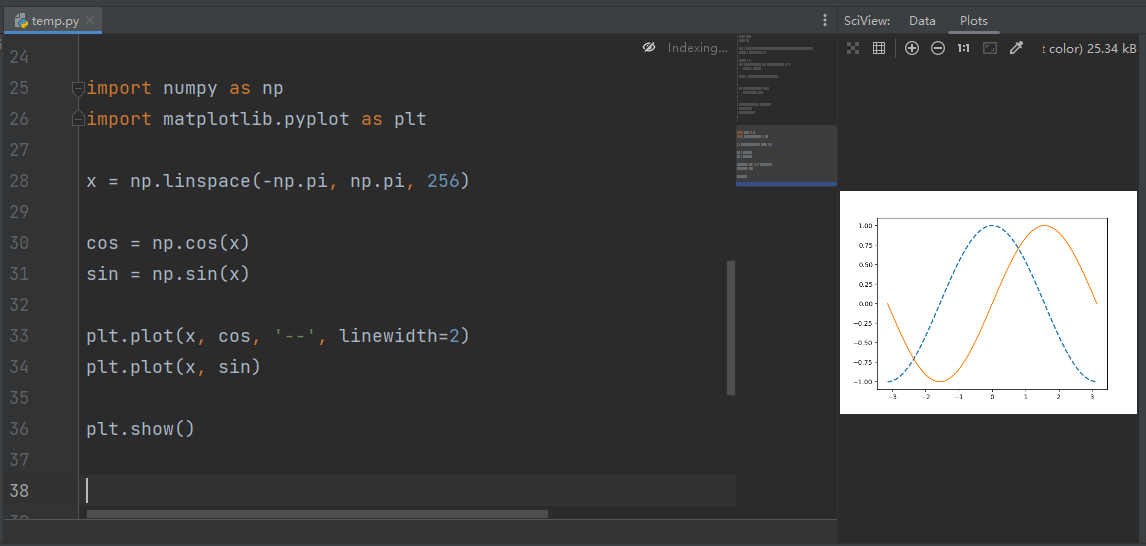
画个饼图

画直方图
更多关于 matplotlib 的文档可以到以下链接查看:https://matplotlib.org/2.0.2/contents.html
seaborn
seaborn 是基于 matplotlib 的库,所以有更加高级的接口给我们使用,相对来说更加简单使用一些
画个散点图。安装:pip install seaborn
数据源:https://github.com/mwaskom/seaborn-data
下载 seaborn-data,然后解压后,将文件拖进电脑中 seaborn-data 的空文件夹里即可。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style="darkgrid")
tips = sns.load_dataset("tips")
sns.relplot(x="total_bill", y="tip", data=tips)
plt.show()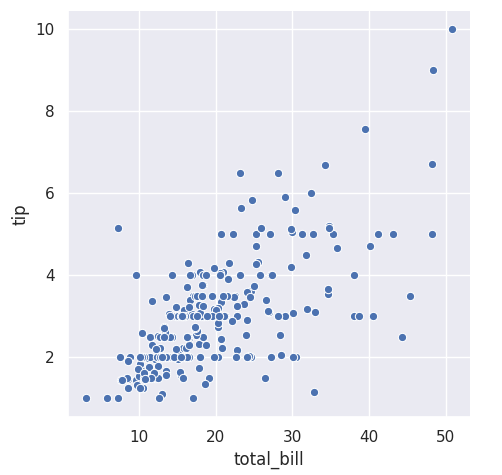
画个折线图
fmri = sns.load_dataset("fmri")
sns.relplot(x="timepoint", y="signal", hue="event", kind="line", data=fmri);
plt.show()
画个直方图
titanic = sns.load_dataset("titanic")
sns.catplot(x="sex", y="survived", hue="class", kind="bar", data=titanic);
plt.show()
更多关于 seaborn:https://seaborn.pydata.org/index.html
百度开源的数据可视化的 echarts 的库
来画个直方图
from pyecharts.charts import Bar
from pyecharts import options as opts
bar = (
Bar()
.add_xaxis(["衬衫", "毛衣", "领带", "裤子", "风衣", "高跟鞋", "袜子"])
.add_yaxis("商家A", [114, 55, 27, 101, 125, 27, 105])
.add_yaxis("商家B", [57, 134, 137, 129, 145, 60, 49])
.set_global_opts(title_opts=opts.TitleOpts(title="某商场销售情况"))
)
bar.render()画个饼图
def pie_base() -> Pie:
c = (
Pie()
.add("", [list(z) for z in zip(Faker.choose(), Faker.values())])
.set_global_opts(title_opts=opts.TitleOpts(title="Pie-基本示例"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
return c
# 需要安装 snapshot_selenium
make_snapshot(driver, pie_base().render(), "pie.png")再来画个词云图
words = [
("Sam S Club", 10000),
("Macys", 6181),
("Amy Schumer", 4386),
("Jurassic World", 4055),
("Charter Communications", 2467),
("Chick Fil A", 2244),
("Planet Fitness", 1868),
("Pitch Perfect", 1484),
("Express", 1112),
("Home", 865),
("Johnny Depp", 847),
("Lena Dunham", 582),
("Lewis Hamilton", 555),
("KXAN", 550),
("Mary Ellen Mark", 462),
("Farrah Abraham", 366),
("Rita Ora", 360),
("Serena Williams", 282),
("NCAA baseball tournament", 273),
("Point Break", 265),
]
def wordcloud_base() -> WordCloud:
c = (
WordCloud()
.add("", words, word_size_range=[20, 100])
.set_global_opts(title_opts=opts.TitleOpts(title="WordCloud-基本示例"))
)
return c
# 需要安装 snapshot_selenium
make_snapshot(driver, wordcloud_base().render(), "WordCloud.png")更多关于 pyecharts:https://pyecharts.org