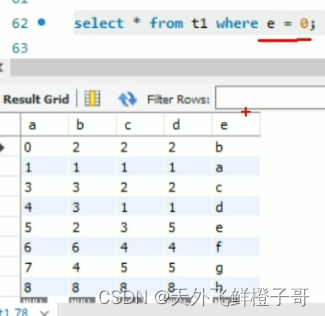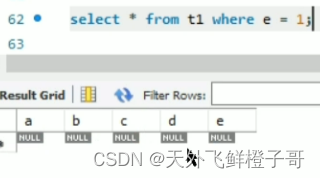

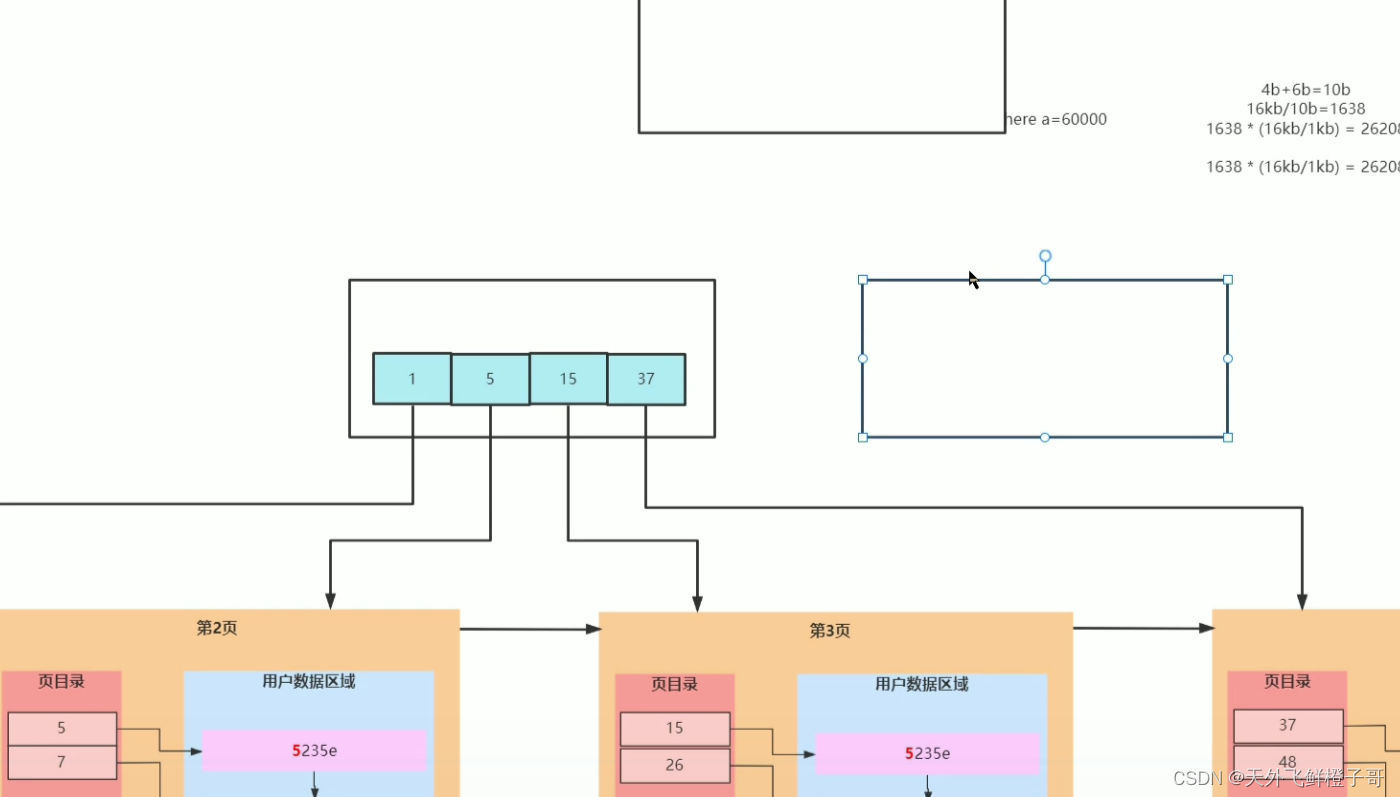
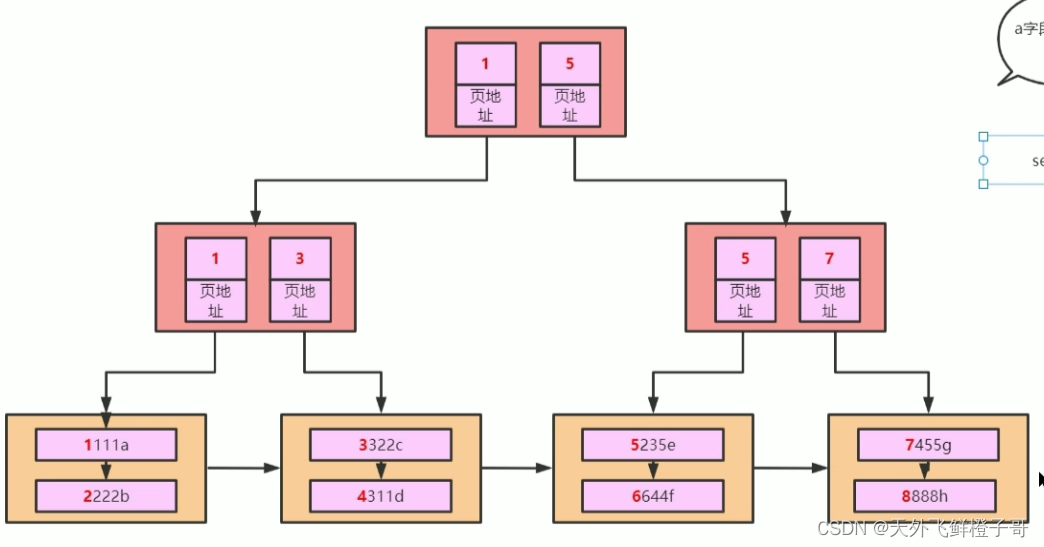
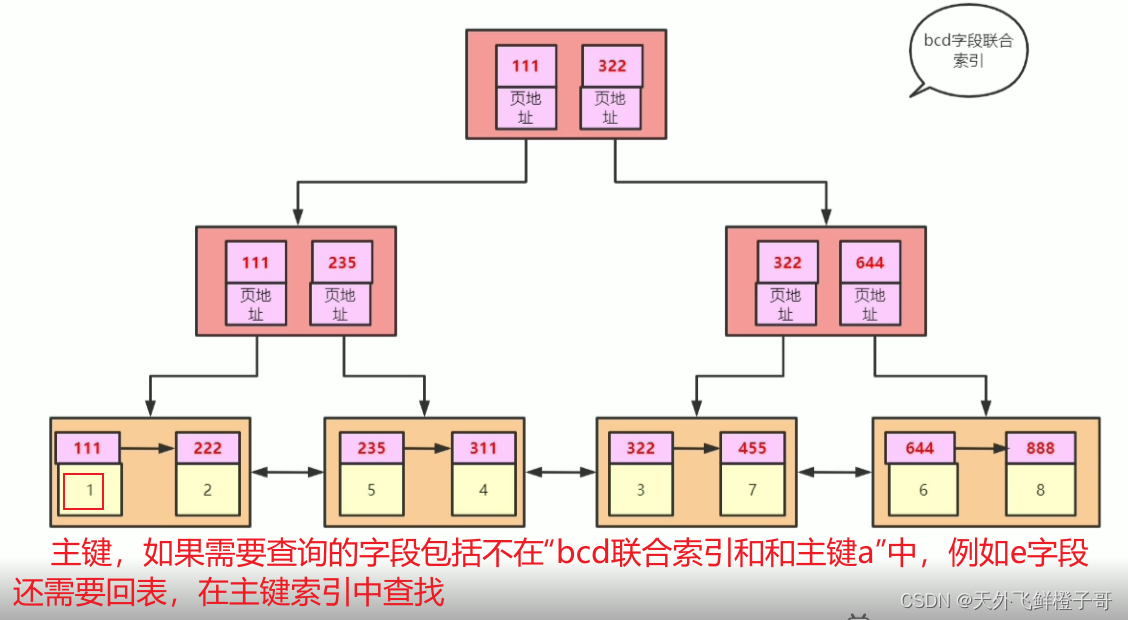
索引失效一般是不满足最左匹配原则
联合索引中c有序仅在b确定的情况下,d有序仅在c确定的情况下。
范围查找导致索引失效
select * from t1 where b>1
这里因为查找所有字段(*),且b>1的条件覆盖到表中大部分数据。如果走bcd索引的话,那么需要回表很多次,效率不如全表扫描(mysql底层会做判断),导致索引失效。
覆盖索引
select b from t1 where b>1;
select b,c,d from t1 where b>1;
select b,c,d,a from t1 where b>1;
因为bcd联合索引中存在abcd字段,走索引查询,不会回表。这就叫覆盖索引(不需要取e字段,需要查询的字段在索引中已经存在,不需要回表,就叫覆盖索引)。
select b from t1;
索引查找,因为同样只需要b字段,联合索引bcd一页容纳abcd字段的数量,比一页容纳abcde字段的数量多,效率更高,所以会走索引。
order by为什么导致索引失效
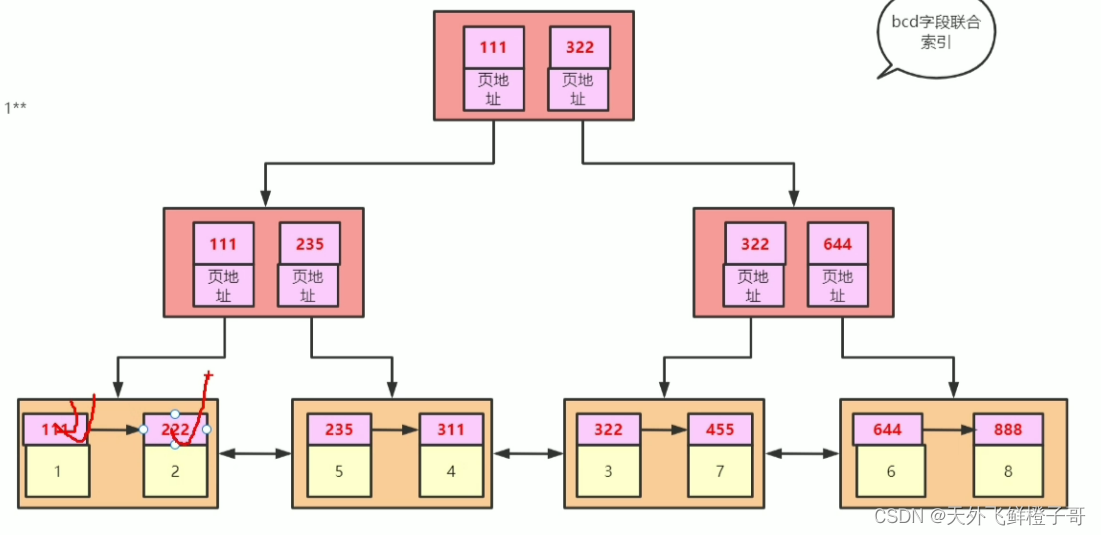
select * from t1 order by b,c,d;
如果走bcd索引,那么需要的时间是遍历bcd索引叶子节点的时间+所有节点回表的时间。
如果走全表扫描,那么是遍历主键索引全部叶子节点的时间+数据在内存中排序的时间。
而数据在内存中排序的时间远小于所有节点回表的时间,所以会走全表扫描。
对字段进行操作导致索引失效
a是int类型,e是varchar类型
select * from a = 1;//走索引
select * from e = '1';//走索引
select * from a = '1';//走索引
select * from e = 1;//不走索引
因为mysql的字符会自动转换从数字,'11’会转换成11,但是像‘a’,‘Q’,‘11w’等均转换为0,所以select * from a = '1’相当于select * from a = 1,而select * from e = 1,会把所有数据的e字段转换成数字,然后比较是否是1。