场景
HashSet
HashSet 基于 HashMap 来实现的,是一个不允许有重复元素的集合。HashSet 允许有 null 值。
HashSet 是无序的,即不会记录插入的顺序。 HashSet 不是线程安全的, 如果多个线程尝试同时修改 HashSet,
则最终结果是不确定的。
在Java语言中,Set数据结构可以用于对象排重,常见的Set类有HashSet、LinkedHashSet等。
比如:
代码中使用HashSet数据结构,为了避免城市数据重复,对读取的城市数据进行强制排重。
这里的数据源从csv文件中读取。

注:
博客:
霸道流氓气质的博客_CSDN博客-C#,架构之路,SpringBoot领域博主
读取csv文件内容的方式有很多种,这里使用apache的commons-csv的方式。
首先项目中引入依赖
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-csv</artifactId>
<version>1.7</version>
</dependency>然后新建读取文件和解析数据的工具类,这里是读取城市数据,所以是
CityHelper
import org.apache.commons.csv.CSVFormat;
import org.apache.commons.csv.CSVParser;
import org.apache.commons.csv.CSVRecord;
import java.io.*;
import java.util.*;
public class CityHelper {
public static Collection<City> readCities(String fileName){
try (
FileInputStream stream = new FileInputStream(fileName);
InputStreamReader reader = new InputStreamReader(stream,"GBK");
CSVParser parser = new CSVParser(reader, CSVFormat.DEFAULT.withHeader())
)
{
Set<City> citySet = new HashSet<>(1024);
Iterator<CSVRecord> iterator = parser.iterator();
while (iterator.hasNext()){
citySet.add(parseCity(iterator.next()));
}
return citySet;
} catch (Exception e) {
e.printStackTrace();
}
return Collections.emptySet();
}
/**
* 解析城市
* @param record
* @return
*/
private static City parseCity(CSVRecord record){
City city = new City();
city.setCode(record.get(0));
city.setName(record.get(1));
return city;
}
}然后新建City实体类
public class City{
private String code;
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getCode() {
return code;
}
public void setCode(String code) {
this.code = code;
}
}下面进行业务测试
Collection<City> cities = CityHelper.readCities("D:\\test.csv");
System.out.println(cities);查看输出结果
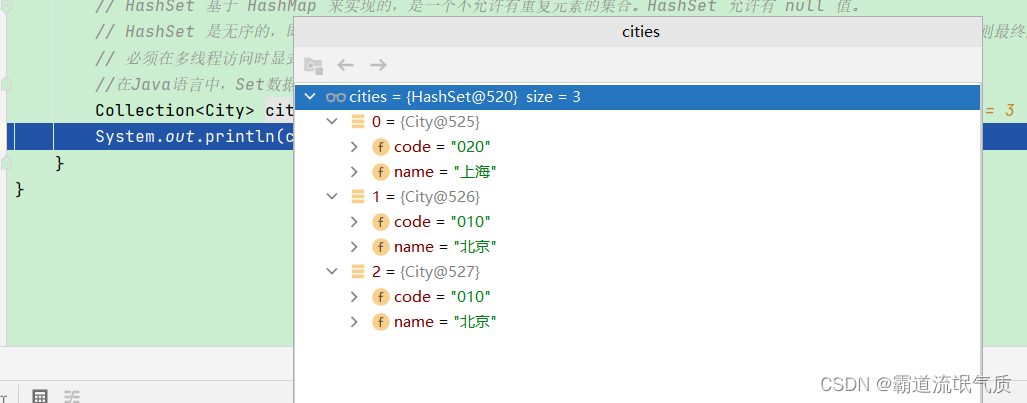
竟然没有实现去重效果。
这里注意踩坑:
原因分析:
当向集合Set中增加对象时,首先集合计算要增加对象的hashCode,根据该值来得到一个位置用来存放当前对象。
如在该位置没有一个对象存在的话,那么集合Set认为该对象在集合中不存在,直接增加进去。
如果在该位置有一个对象存在的话,接着将准备增加到集合中的对象与该位置上的对象进行equals方法比较:
如果该equals方法返回false,那么集合认为集合中不存在该对象,就把该对象放在这个对象之后;
如果equals方法返回true,那么就认为集合中已经存在该对象了,就不会再将该对象增加到集合中了。
所以,在哈希表中判断两个元素是否重复要使用到hashCode方法和equals方法。
hashCode方法决定数据在表中的存储位置,而equals方法判断表中是否存在相同的数据。
分析上面的问题,由于没有重写City类的hashCode方法和equals方法,就会采用Object类的hashCode方法和equals方法。
Object类的hashCode方法是一个本地方法,返回的是对象地址;Object类的equals方法只比较对象是否相等。
所以,对于两条完全一样的北京数据,由于在解析时初始化了不同的City对象,导致hashCode方法和equals方法值都不一样,
必然被Set认为是不同的对象,所以没有进行排重。
解决Java中使用HashSet进行排重时不生效问题
解决:重写City类的hashCode方法和equals方法
这里我们再新建一个City2实体类并修改如下
import java.util.Objects;
/**
* 城市类
*/
public class City2 {
private String code;
private String name;
/**
* 判断相等
* @param obj
* @return
*/
@Override
public boolean equals(Object obj) {
if(obj == this){
return true;
}
if(Objects.isNull(obj)){
return false;
}
if(obj.getClass() != this.getClass()){
return false;
}
return Objects.equals(this.code,((City2)obj).getCode());
}
/**
* 哈希编码
* @return
*/
@Override
public int hashCode() {
return Objects.hashCode(this.code);
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getCode() {
return code;
}
public void setCode(String code) {
this.code = code;
}
}这里重写的equals方法中指定了自己需要的逻辑,根据code字段判断,如果相等则认为相同。
然后再重新调用并查看结果
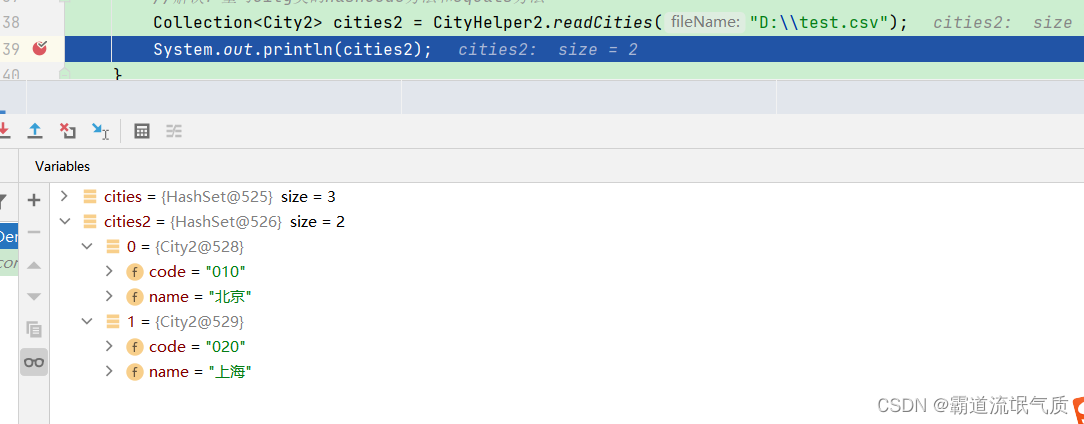
总结:
1、当确定解析的城市数据唯一时,就没有必要进行排重操作,可以直接使用List来存储。
2、确定解析的城市数据不唯一时,需要按照城市名称进行排重操作,可以直接使用Map进行存储。
为什么不建议实现City类的hashCode方法,再采用HashSet来实现排重呢?
首先,不希望把业务逻辑放在模型DO类中;其次,把排重字段放在代码中,便于代码的阅读、理解和维护。
3、不重写hashCode方法和equals方法的自定义类不应该在Set中使用。