-
泛化性能的首要因素是样本:训练的数据量越小越容易过拟合,模型泛化性不好首先应该考虑的是训练样本的数量和质量
-
提高泛化的本质是引入更多随机性:正则化,dropout,数据增强这些其实都相当于增加噪声,为loss函数搜索最优解时加入更多随机性,从而尽可能避免陷入局部最优(sharp minima),逼近一个相对全局更优的解(flat minima)
-
无脑选择Adam类优化器不一定更好:Adam类优化器通常收敛速度很快,但是相比SGD更不容易收敛到一个flat minima的解,所以Adam训练得到的训练 loss可能会更低,但测试performance常常更差,也就是泛化性能更差。一般CV领域带动量的SGD更多,NLP领域Adam类优化器更多
-
不需要一上来就考虑泛化的问题:搭建模型的初期先要保证模型的复杂度能够充分拟合数据(先避免欠拟合并且保证模型能正确训练),代价函数能够快速的下降,在训练集上达到一个非常高的准确率,再考虑泛化的问题。
- check模型能正确训练的trick: 对一条或几条数据进行过拟合,绘制学习曲线观察loss能迅速下降并收敛到一个很低的值
- 此时说明模型能正常梯度下降且在训练集上收敛精度很高,但是模型严重过拟合,这时再调整超参以及各种策略提升泛化性能
-
L1/L2正则化
- 正则化就是在原来 Loss Function 的基础上,加了一些正则化项,常用的是L1和L2范数
- L1 正则化,直接在原来的损失函数基础上加上权重参数的绝对值
- L2 正则化,直接在原来的损失函数基础上加上权重参数的平方和
- 一般L2范数比L1范数更受欢迎,深度学习里应用更平滑和稳定
-
dropout
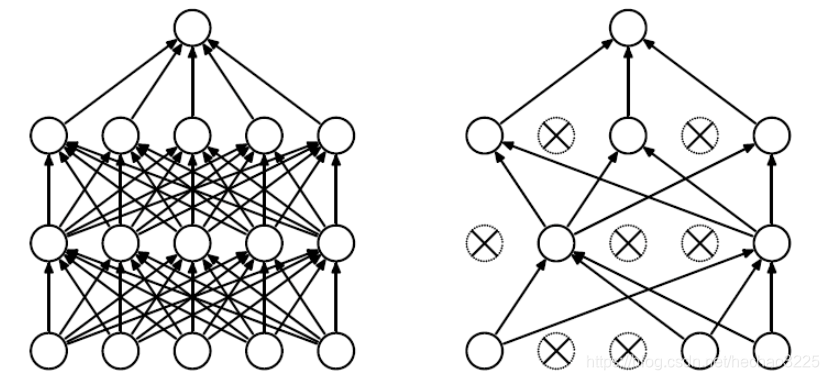
- 是指在深度学习网络的训练过程中,按照一定的概率将一部分神经网络单元暂时从网络中丢弃,相当于从原始的网络中找到一个更瘦的网络
- 早停法(Early Stop)
- 需要和交叉验证(如k-fold cross validate)结合使用,在过拟合前就停止训练
- 具体步骤
- 将原始的训练数据集划分成训练集和验证集
- 只在训练集上进行训练,并每个一个周期计算模型在验证集上的误差,例如,每15次epoch(mini batch训练中的一个周期)
- 当模型在验证集上的误差比上一次训练结果差的时候停止训练
- 使用上一次迭代结果中的参数作为模型的最终参数