跨集群的数据复制是一个复杂且耗时的过程。 公司必须使用外部工具或编写自定义脚本将数据从一个集群移动到另一个集群。 Elasticsearch 以其跨集群复制功能来救援。
跨集群复制 (CCR) 是 Elasticsearch 中的一项内置功能,允许近乎实时地将数据从一个集群复制到另一个集群。 它是一个强大的工具,使用户能够跨多个集群分发数据,提高数据弹性并实现跨地理区域的数据分析。
让我们深入了解跨集群复制的世界并探索一些用例。
用例 1:灾难恢复
灾难随时可能发生,制定灾难恢复计划至关重要。 跨集群复制可以通过将数据从主集群复制到不同地理位置的辅助集群来帮助灾难恢复。 这确保了如果主集群出现故障,辅助集群可以接管,并且业务运营可以继续而不会中断。

用例 2:负载平衡
拥有海量数据的大公司可能会发现单个集群无法处理负载。 跨集群复制允许通过跨多个集群分布数据来实现负载平衡,从而提高性能和可扩展性。 用户可以从任意集群查询数据,结果将实时合并并返回。
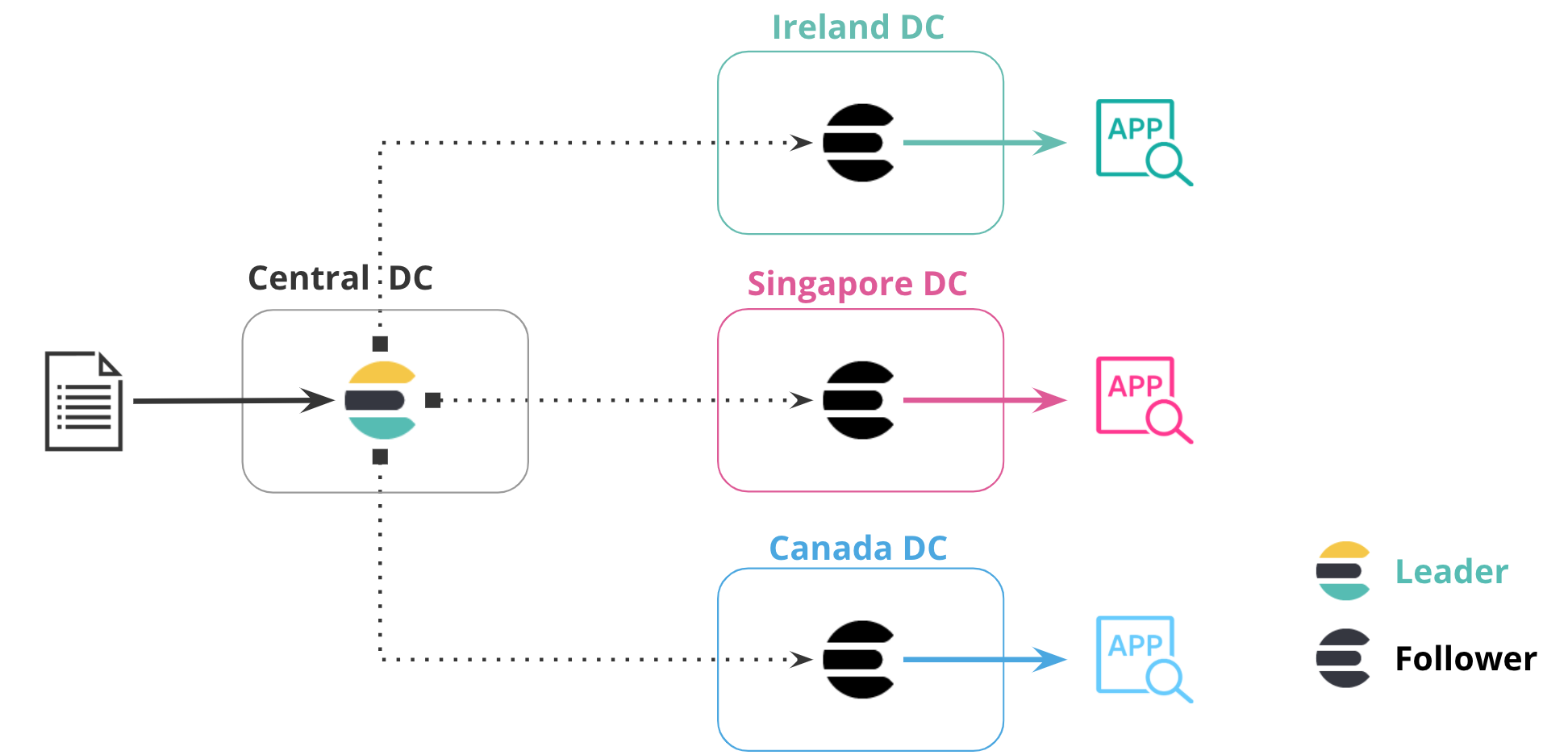
用例 3:分析
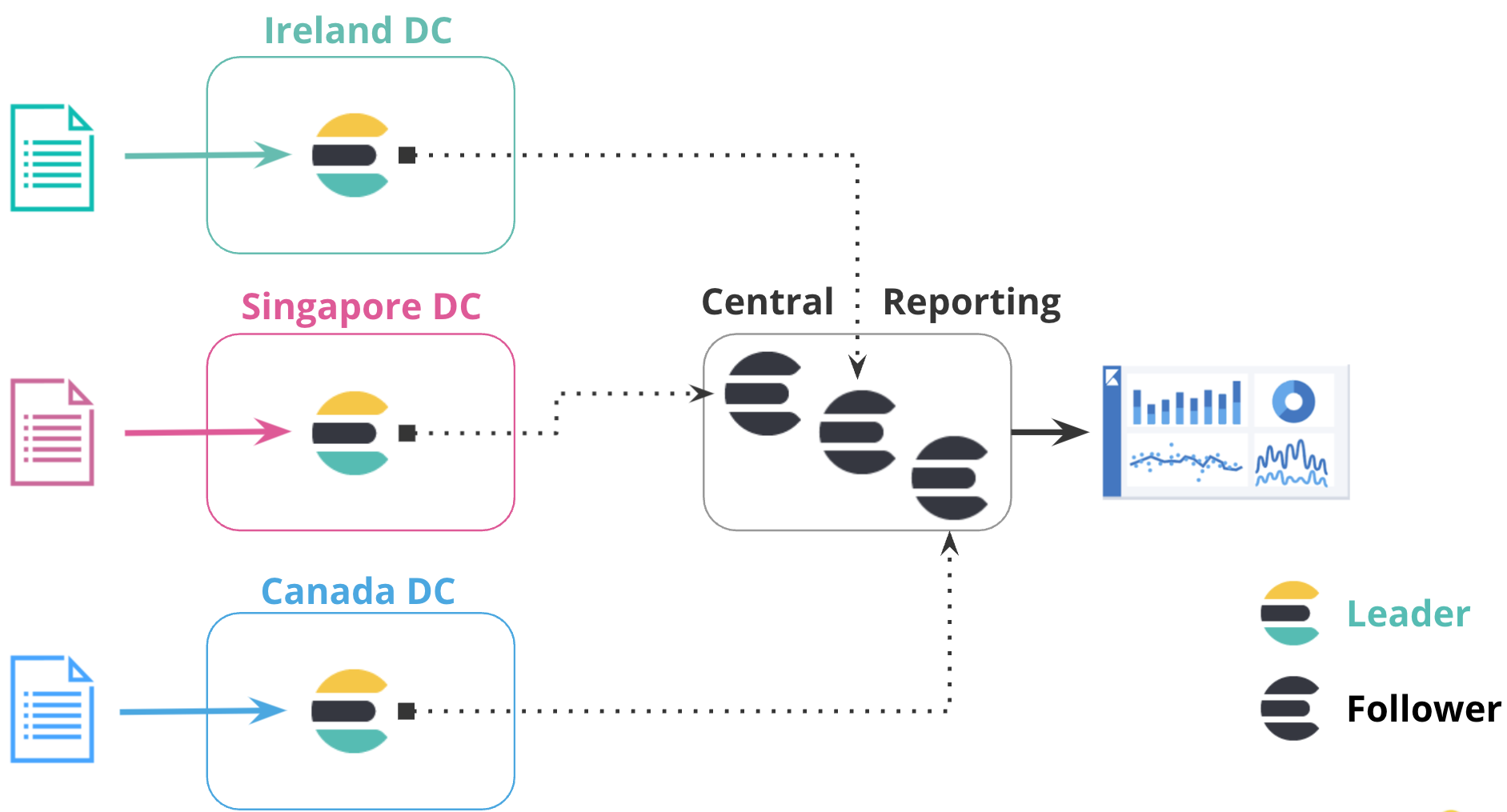
跨地理区域的数据分析可能具有挑战性,尤其是当数据存储在单独的集群中时。 通过跨集群复制,用户可以将数据从多个集群复制到中央集群,从而更轻松地跨所有数据源执行分析。 这使公司能够根据完整的数据视图做出明智的决策。

实操
要设置跨集群复制,你需要在辅助集群中定义跟随者索引。 这是一个例子:
PUT /_ccr/auto_follow/my_index
{
"remote_cluster": "primary_cluster",
"leader_index_patterns": ["my_index*"],
"follow_index_pattern": "{
{leader_index}}_follower",
"max_outstanding_read_requests": 1024,
"max_outstanding_write_requests": 512,
"max_read_request_operation_count": 256,
"max_write_request_operation_count": 256,
"max_write_buffer_count": 512,
"max_write_buffer_size": "512mb",
"max_retry_delay": "10s",
"read_poll_timeout": "1m",
"max_poll_interval": "5m"
}这将创建一个自动跟随索引,该索引跟随主集群中与 my_index* 模式匹配的任何索引。
要检查复制的状态,你可以使用 _ccr/stats API。 这是一个例子:
GET /_ccr/stats这将返回一个 JSON 对象,其中包含有关复制状态的信息。
让我们更深入地了解跨集群复制的一些关键概念和配置。
需要理解的一个重要概念是领导者索引(leader index)和跟随者(follower)索引之间的区别。 领导者索引是正在复制的主集群上的索引,而跟随者索引是正在接收复制数据的辅助集群上的索引。
定义跟随者索引时,你可以指定控制复制过程行为的各种设置。 例如,你可以设置未完成的读取和写入请求的数量、写入缓冲区的最大大小以及最大重试延迟的限制。 这些设置对于控制跨网络的数据流并确保复制不会压垮任一集群非常重要。
另一个重要的考虑因素是复制过程的安全性。 跨集群复制可以配置为使用 SSL/TLS 加密来实现集群之间的安全通信。 此外,你可以使用 Elasticsearch 的内置安全功能来控制对复制 API 的访问并加密静态敏感数据。你可以参考文章 “Elasticsearch:如何在不更新证书的情况下为集群之间建立互信”。
让我们仔细看看前面提到的用例之一:灾难恢复。 在此场景中,你可能有一个主集群位于一个数据中心,而一个辅助集群位于另一个数据中心。 要设置复制,你需要在辅助集群上定义一个跟随者索引,指定远程集群和领导者索引模式:
PUT /_ccr/auto_follow/my_index
{
"remote_cluster": "primary_cluster",
"leader_index_patterns": ["my_index*"],
"follow_index_pattern": "{
{leader_index}}_follower"
}设置复制后,对主集群上的领导者索引所做的任何更改都将自动复制到辅助集群上的跟随者索引。 如果发生影响主集群的灾难,您可以切换到辅助集群并使用复制的数据继续操作。
跨集群复制的另一个用例是数据整合。 在某些情况下,你可能有多个具有相似数据的集群,但分布在不同的区域或业务部门。 通过在这些集群之间设置复制,你可以将数据整合到单个中央集群中,以便于分析和报告。
要开始使用跨集群复制,您需要安装 Elasticsearch 6.4 或更高版本。 然后,你可以按照 Elasticsearch 文档中的步骤配置集群之间的复制。
跨集群复制是 Elasticsearch 中的一项强大功能,可实现跨集群的数据复制,以实现灾难恢复、负载平衡和分析。 通过定义跟随者索引和配置复制设置,你可以控制数据流并确保复制过程的安全性。 因此,如果您希望提高 Elasticsearch 部署的弹性和可扩展性,请尝试跨集群复制!