目录
1.ChiUsecase数据结构用来概括一个usecase的信息
2.ChiPipelineTargetCreateDescriptor数据结构用来描述一个完整的pipeline
3.ChiPipelineCreateDescriptor数据结构描述一个pipeline的构成
4.ChiTargetPortDescriptorInfo数据结构描述一个pipeline的sink/source缓存信息
usecase裁剪是指根据pruneSettings将一个usecase描述中部分内容剪修的处理过程。
接下来会以ZSLSnapshotJpeg 这条pipeline的裁剪为例子,了解是如何裁剪的。
在开始裁剪一条pipeline前,先看下usecas描述中的几个数据结构,了解可裁剪的内容有哪些(node, target, link)。
基础介绍
1.ChiUsecase数据结构用来概括一个usecase的信息
struct ChiUsecase
{
const CHAR* pUsecaseName;
UINT streamConfigMode;
UINT numTargets;
ChiTarget** ppChiTargets;
UINT numPipelines;
ChiPipelineTargetCreateDescriptor* pPipelineTargetCreateDesc;
const PruneSettings* pTargetPruneSettings;
BOOL isOriginalDescriptor;
}一个usecase的基本信息包括:
-
usecase名字
-
streamConfigMode, 表明该usecase用于什么相机操作模式
-
chiTargets, 该usecase所拥有的target,包括sinkTarget和sourceTarget.
-
chiPipelineTargetCreateDescriptor, 该usecase所拥有的pipeline的描述
-
pruneSettings, 该usecase的裁剪配置
2.ChiPipelineTargetCreateDescriptor数据结构用来描述一个完整的pipeline
struct ChiPipelineTargetCreateDescriptor
{
const CHAR* pPipelineName;
ChiPipelineCreateDescriptor pipelineCreateDesc;
ChiTargetPortDescriptorInfo sinkTarget;
ChiTargetPortDescriptorInfo sourceTarget;
};一个Pipeline的完整描述有四个内容:
-
pipeline名,区分pipeline的不同;
-
pipeline的构建描述,描述这条pipeline是什么样的构成
-
sinkTarget下游目标,描述pipeline的输出是什么样的;
-
sourceTarget上游目标,描述pipeline的输入是什么样的。
3.ChiPipelineCreateDescriptor数据结构描述一个pipeline的构成
typedef struct ChiPipelineCreateDescriptor
{
UINT32 size;
INT32 numNode;
CHINODE* pNodes;
INT32 nulLinks;
CHINODELINK* pLinks;
UINT32 isRealTime;
UINT numBatchedFrames;
UINT maxFPSValue;
UINT32 cameraId;
CHIMETAHANDLE hPipelineMetadata;
BOOL HALOutputBufferCombined;
UINT32 logicalCameraId;
}pipeline的构成有两个基本构件:
-
CHINODE,说明这条pipeline由哪些节点租出
-
CHINODELINK, 说明够成这条pipeline的节点是如何连接的
对于realtime pipeline是sensor作为开始节点,通过isRealTime和cameraId区分。
3.1用CHINODE数据结构描述一个节点
typedef struct ChiNode
{
CHINODEPROPERTY* pNodeProperties;
UINT32 nodeId;
UINT32 nodeInstanceId;
CHINODEPORTS nodeAllPorts;
UINT32 numProperties;
PruneSettings pruneProperties;
}CHINODE;3.2用CHINODELINK数据结构描述两个端口的连接
typedef struct ChiNodeLink
{
CHILINKNODESCRIPTOR srcNode;
UINT32 numDestNodes;
CHILINKNODESCRIPTOR pDestNodes;
CHILINKBUFFERPROPERTIES bufferProperties;
CHILINKPROPERTIES linkProperties;
}CHINODELINK;4.ChiTargetPortDescriptorInfo数据结构描述一个pipeline的sink/source缓存信息
struct ChiTargetPortDescriptorInfo
{
UINT numTargets;
ChiTargetPortDescriptor* pTargetPortDesc;
}按照数据的流入/流出方向,端口缓存分为两种:流入端口的缓存称为sinkTarget,从端口流出的缓存sourceTarget。
一个端口的缓存包括两个内容:
-
numTargets缓存的个数,表明该端口缓存有几份组成
-
chiTargetPortDescriptor缓存的端口描述,说明一份缓存是和哪些端口交互、这份缓存的地址是什么
4.1用ChiTargetPortDescriptor数据结构描述一个端口的一个缓存
struct ChiTargetPortDescriptor
{
const CHAR* pTargetName;
ChiTarget* pTarget;
UINT numNodePorts;
ChiLinkNodeDescriptor* pNodePort;
}一份端口缓存包含三个内容:
-
target名字,
-
指向chiTarget的指针。
-
和这个target连接的ports信息
struct ChiTarget
{
ChiStreamType direction; //target的方向:input/output/bidirectional
BufferDimension dimension; //缓存尺寸
UINT numFormats; //该target支持的缓存格式的个数
ChiBufferFormat* pBufferFormats; //缓存格式
ChiStream* pChiStream; //指向该target使用的chiStream的指针
}ChiLinkNodeDescriptor数据结构用于描述link中关于node的用于定义两个node间连接的信息:
typedef struct ChiLinkNodeDescriptor
{
UINT32 nodeId;
UINT32 nodeInstanceId;
UINT32 nodePortId;
UINT32 portSourceTypeId;
PruneSettings pruneProperties;
}CHILINKNODESCRIPTOR;从以上数据结构的定义发现具有裁剪属性的有:
-
ChiUsecase,即usecase的描述
-
ChiLinkNodeDescriptor, target中的link描述
-
ChiNode, 节点
裁剪变量
1.裁剪变量的定义
struct PruneSettings {
UINT numSettings;
const PruneVariant* pVariants;
}2.usecase描述中的裁剪参数
在描述usecase的xml中node的裁剪参数如下,

link port的裁剪参数:

usecase裁剪的代码实现
CDKResult UsecaseSelector::PruneUsecaseDescriptor(const ChiUsecase* const pUsecase,
const UINT numPruneVariants,
const PruneVariant* const pPruneVariants,
ChiUsecase** ppPrunedUsecase)
{
//1.为目的usecase描述分配空间
ChiUsecase *pPrunedUsecase =
static_cast<ChiUsecase*>(CHX_CALLOC(1*sizeof(ChiUsecase)));
ChiPipelineTargetCreateDescriptor* pPrunedTargetCreateDesc =
static_cast<ChiPipelineTargetCreateDescriptor*>(
CHX_CALLOC(pUsecase->numPipelines * sizeof(ChiPipelineTargetCreateDescriptor)));
ChiTarget** ppPrunedChiTargets = static_cast<ChiTarget**>(
CHX_CALLOC(pUsecase->numTargets * sizeof(ChiTarget*)));
pPrunedUsecase->pPipelineTargetCreateDesc = pPrunedTargetCreateDesc;
pPrunedUsecase->ppChiTargets = ppPrunedChiTargets;
*ppPrunedUsecase = pPrunedUsecase;
//2.填充目的usecase
pPrunedUsecase->pUsecaseName = pUsecase->pUsecaseName;
pPrunedUsecase->streamConfigMode = pUsecase->streamConfigMode;
pPrunedUsecase->numPipelines = pUsecase->numPipelines;
//3.组成usecase的pipeline的描述
for (UINT j = 0; j < pUsecase->numPipelines; j++)
{
ChiPipelineTargetCreateDescriptor& rTargetPrunedDesc =
pPrunedUsecase->pPipelineTargetCreateDesc[j];
ChiPipelineCreateDescriptor& rPrunedDesc = rTargetPrunedDesc.pipelineCreateDesc;
rTargetPrunedDesc.pPipelineName = rTargetCreateDesc.pPipelineName;
rTargetPrunedDesc.sinkTarget.pTargetPortDesc = static_cast<ChiTargetPortDescriptor*>(
CHX_CALLOC(rTargetCreateDesc.sinkTarget.numTargets *
sizeof(ChiTargetPortDescriptor)));
rTargetPrunedDesc.sourceTarget.pTargetPortDesc = static_cast<ChiTargetPortDescriptor*>(
CHX_CALLOC(rTargetCreateDesc.sourceTarget.numTargets *
sizeof(ChiTargetPortDescriptor)));
rPrunedDesc.isRealTime = rCreateDesc.isRealTime;
rPrunedDesc.pNodes = static_cast<CHINODE*>(
CHX_CALLOC(rCreateDesc.numNodes * size(CHINODE)));
rPrunedDesc.pLinks = static_cast<CHINODELINK*>(
CHX_CALLOC(rCreateDesc.numLinks * sizeof(CHINODELINK)));
const ChiPipelineCreateDescriptor& rCreateDesc =
rTargetCreateDesc.pipelineCreateDesc;
//3.1裁剪node
//3.2裁剪link
//3.3裁剪sourceTarget
}
}ppPrunedUsecase是裁剪后的usecase,pUsecase是裁剪的初始,pPruneVariants是裁剪参数。
举例子 - 裁剪ZSLSnapshotJpeg
工程中对usecase的裁剪基于xml中描述的usecase,通过裁剪参数将clone的usecase裁剪成业务需要的usecase。根据configure_streams阶段用户设置的相机参数和使用的相机设备会生成一组裁剪参数。
这里使用的用户裁剪参数:EIS :Disabled 、Snapshot:JPEG、FDIN:Disabled
1.ZSLSnapshotJpeg pipeline
xml中对ZSLSnapshotJpeg pipeline的描述如下,
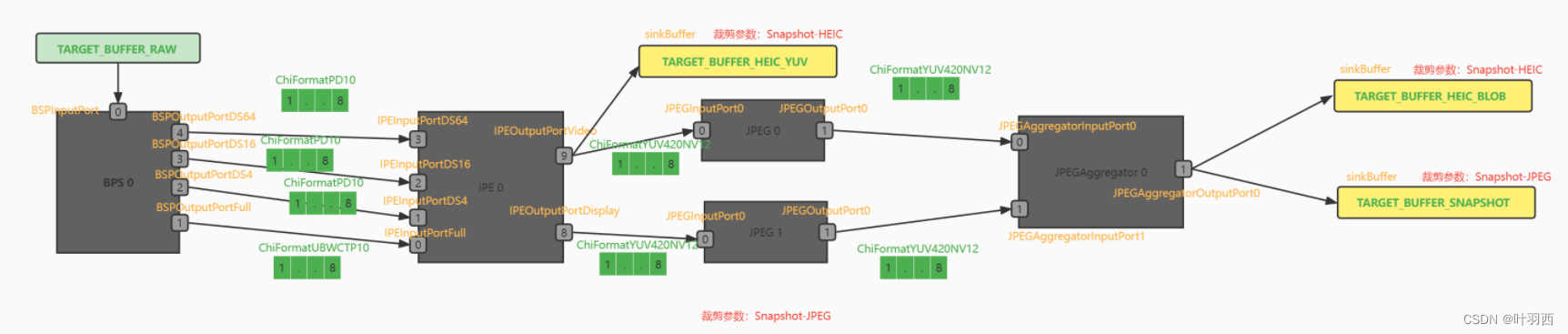
2.裁剪node

检索Jpeg node的裁剪参数group=Snapshot,然后查找到用户设置的裁剪参数中有group=Snapshot,比较Jpeg node和用户设置是一致的Jpeg,则当前Jpeg node不需要被剪掉。JPEG Node的描述信息将添加到目的pipeline描述的节点列表中。
3.裁剪link
link根据连接的内容有三种情况:
-
sourceTarget-->dstNode
-
srcNode-->dstNode
-
srcNode-->sinkTarget sinkTarget又有两种情况(sink buffer和sink no buffer)
对一条link裁剪主要是三个步骤:
-
[更新link的start]对于srcNode--> 这种部分,首先需要更新srcNode的端口信息
-
[更新link的end]对于-->dstNode这部分,如果不被剪掉添加dstNode信息;对于-->sinkTarget这部分,如果不被剪掉更新sinkTarget
-
[更新link]对于srcNode bypass nextNode这种情况,需要根据srcNode的bypass属性更新link的dstPort(修改link.dstPort dstNode.inputPortA为dstNode.outputPortB,绕过dstNode)
裁剪发生在第二步,根据dstNode或者sinkTarget的裁剪信息确定是不是要被剪掉,不被剪掉的dstNode或者sinkTarget被加到目的usecase.pipeline中。
情况一:sourceTarget-->dstNode

以BPS0[0].BPSOutputPortFull-->IFE0[0].IPEInputPortFull这条link为例子,
步骤1:因为BPS0 node没被剪掉,所以直接更新pipeline.node[BPS0].nodeAllPorts.pOutputPorts[1]的端口信息
步骤2:对于[1]BPSOutputPortFull-->[0]IPEInputPortFull这条link,dstNode是IPE0, 根据节点裁剪逻辑,IPE0是不被剪掉的,所以添加节点描述到目的pipeline.node[]
步骤3:对于[1]BPSOutputPortFull-->[0]IPEInputPortFull这条link,srcNode BPS0没有设置bypass属性,所以IPE0不需要绕过。
情况二:target-->dstNode
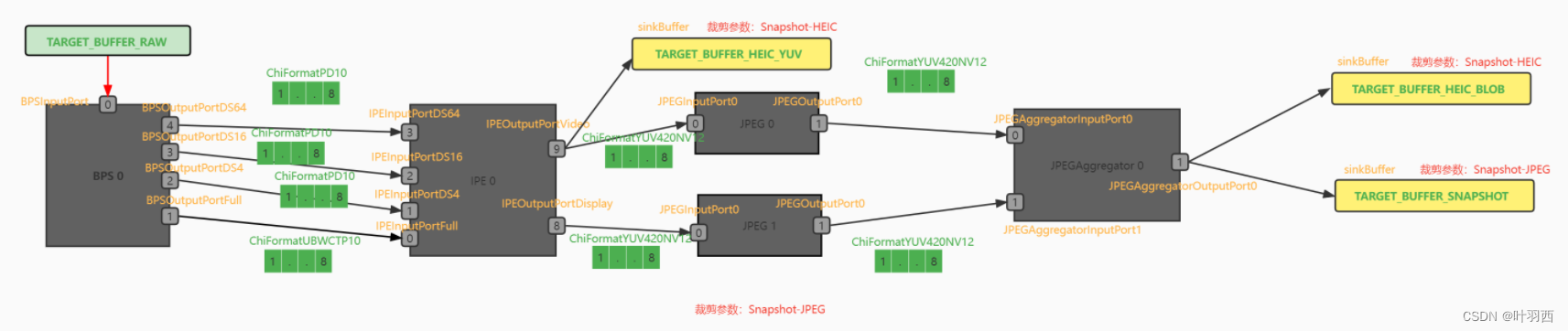
对于ZSLSnapshotJpeg pipeline的输入TARGET_BUFFER_RAW-->[0]BPSInputPort1这条link,裁剪过程:
步骤1:因为是sourceTarget输入,所以不存在port要更新
步骤2:是-->dstNode这种情况,dstNode是BPS, 根据BSP的裁剪参数,BPS0 Node不需要剪掉,所以添加节点到目的pipeline.node[]
步骤3:因为是sourceTarget输入,无bypass逻辑。
情况三:srcNode-->target
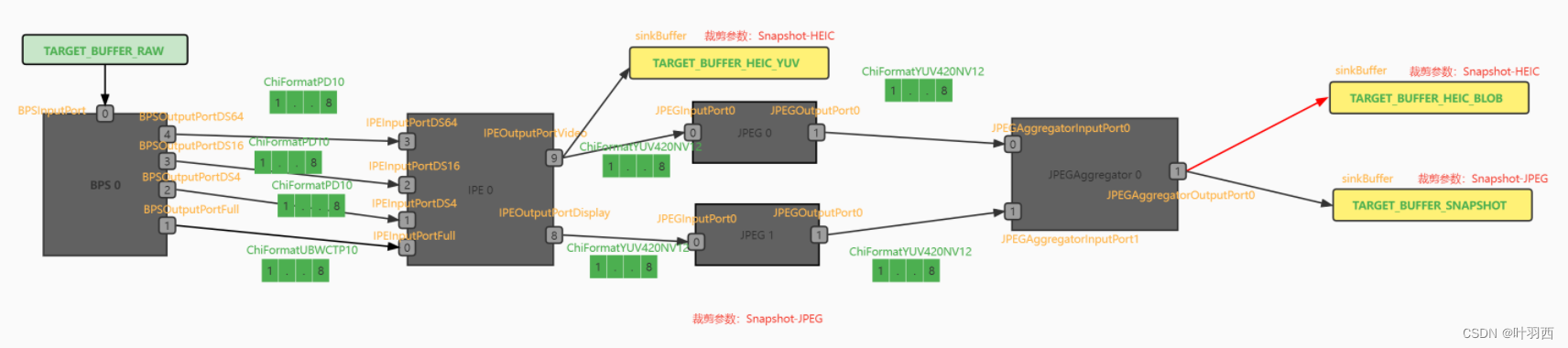
对于[1]JPEGAggregatorOutputPort0-->TARGET_BUFFER_BLOB这条link,裁剪过程:
步骤1:srcNode是JPEGAggregator,更新目的pipeline.node[JPEGAggregator0].nodeAllPorts.pOutputPorts[1]的端口信息
步骤2:是-->sinkTarget这种情况,TARGET_BUFFER_BLOB是sink buffer,根据target裁剪逻辑需要被剪掉(轻颜相机没有配置heic拍照)
步骤3:srcNode是JPEGAggregator,没有设置bypass,所以不存在bypass处理。
如果[1]JPEGAggregatorOutputPort0-->TARGET_BUFFER_BLOB JPEGAggregator有设置bypass属性处理逻辑是什么样的?这就不得不说下srcNode bypass处理,有两种情况:
-
srcNode-->dstNode, 这时更新srcNode link到对应的dstNode.outputPort
-
srcNode-->sinkTarget(也就是当前假设这种情况),这时由于sinkTarget不是dstNode所以不存在port这个概念,也就不存在bypass概念。
4.裁剪sourceTarget

TARGET_BUFFER_RAW这个sourceTarget不需要剪掉通过两个条件判断:
-
TARGET_BUFFER_RAW有接收
-
TARGET_BUFFER_RAW有接收,且接收不被剪掉。
所以裁剪sourceTarget可以分为两步:裁剪接收sourceTarget的node和裁剪sourceTarget和dstNode的连接。