目录
3: script标签中defer和async的区别是什么?
17.一个html可以引入多个js,一个HTML文件引入多个JS文件onload的问题
24.JavaScript中实现sleep睡眠函数的几种简单方法
25.plugin和loader执行时间的区别webpack
41、requireJS原理,ES6 import原理,两者区别
前言:本人亲历五家面试(技术面全过),面试内容和答案的整理,全部均为面试高频,如有错误,尽请指出。
1.HTML5新增
1.新增WebStorage, 包括localStorage和sessionStorage
2.src和href的区别是什么
当浏览器遇到href会并行下载资源并且不会停止对当前文档的处理。(同时也是为什么建议使用 link 方式加载 CSS,而不是使用 @import 方式)
当浏览器解析到src ,会暂停其他资源的下载和处理,直到将该资源加载或执行完毕。(这也是script标签为什么放在底部而不是头部的原因)
3: script标签中defer和async的区别是什么?
默认情况下,脚本的下载和执行将会按照文档的先后顺序同步进行。当脚本下载和执行的时候,文档解析就会被阻塞,在脚本下载和执行完成之后文档才能往下继续进行解析。
下面是async和defer两者区别:
1.当script中有defer属性时,脚本的加载过程和文档加载是异步发生的,等到文档解析完(DOMContentLoaded事件发生)脚本才开始执行。
2.当script有async属性时,脚本的加载过程和文档加载也是异步发生的。但脚本下载完成后会停止HTML解析,执行脚本,脚本解析完继续HTML解析。
3.当script同时有async和defer属性时,执行效果和async一致。
4:var、let、const三者区别
var、let、const三者区别可以围绕下面五点展开:
-
变量提升
-
暂时性死区
-
块级作用域
var`不存在块级作用域
let和const存在块级作用域 -
重复声明
var允许重复声明变量let和const在同一作用域不允许重复声明变量 -
修改声明的变量
var和let可以const声明一个只读的常量。一旦声明,常量的值就不能改变
5.ES6中数组新增了哪些扩展?
一、扩展运算符的应用
二、构造函数新增的方法
-
Array.from()
-
Array.of()
三、实例对象新增的方法
-
copyWithin()
-
find()、findIndex()
-
fill()
-
entries(),keys(),values()
-
includes()
-
flat(),flatMap()
6.新窗口打开网页
当没有框架嵌套时,self,top,parent三者效果一样,看起来都是在当前窗口打开网页;blank 在新窗口打开网页。
当有框架嵌套时,
_self:在当前框架内打开网页,不影响父框架的其他内容
_blank:在新窗口打开网页 _top: 在当前窗口打开网页,即替换掉当前框架的顶级父框架的所有内容
_parent: 在直接父窗口中打开网页,即替换掉当前框架的直接父框架的所有内容
7.浏览器运行机制
1、构建DOM树(parse):渲染引擎解析HTML文档,首先将标签转换成DOM树中的DOM node(包括js生成的标签)生成内容树(Content Tree/DOM Tree);
2、构建渲染树(construct):解析对应的CSS样式文件信息(包括js生成的样式和外部css文件),而这些文件信息以及HTML中可见的指令(如<b></b>),构建渲染树(Rendering Tree/Frame Tree);
3、布局渲染树(reflow/layout):从根节点递归调用,计算每一个元素的大小、位置等,给出每个节点所应该在屏幕上出现的精确坐标;
4、绘制渲染树(paint/repaint):遍历渲染树,使用UI后端层来绘制每个节点。
8.JS 哪些操作会造成内存泄露,对应的解决方法
1.意外的全局变量
上面的a变量应该是foo()内部作用域变量的引用,由于没有使用var来声明这个变量,这时变量a就被创建成了全局变量,这个就是错误的,会导致内存泄漏。
解决方式: 在js文件开头添加 ‘use strict’,开启严格模式。(或者一般将使用过后的全局变量设置为 null 或者将它重新赋值,这个会涉及的缓存的问题,需要注意)
2、未清理的DOM元素引用
不能回收,因为存在变量a对它的引用。虽然我们用removeChild移除了,但是还在对象里保存着#的引用,即DOM元素还在内存里面。解决方法: a = null;
3、被遗忘的定时器或者回调
定时器setInterval或者setTimeout在不需要使用的时候,没有被clear,导致定时器的回调函数及其内部依赖的变量都不能被回收,这就会造成内存泄漏。解决方式:当不需要interval或者timeout的时候,调用clearInterval或者clearTimeout
4、闭包
解决办法:将事件处理函数定义在外部
5.、console.log
9.JS实现继承的几种方法总结
1.原型链继承
Dog.prototype = new Animal(); //将Animal的实例挂载到了Dog的原型链上

2.构造继承:
//核心:使用父类的构造函数增强子类实例,等于是复制父类的实例属性给子类(没用到原型)
function Cat(name) { Animal.call(this); this.name = name || 'Tom'; }
3.实例继承
//核心:为父类实例添加新特性,作为子类实例返回
function Cat(name) { var instance = new Animal(); instance.name = name || 'Tom'; return instance; }
4.拷贝继承:
function Cat(name){ var animal = new Animal(); for(let i in animal) { Cat.prototype[i] = animal[i]; } Cat.prototype.name = name || 'Tom'; }
5.组合继承:
//核心:通过调用父类构造,继承父类的属性并保留传参的优点,然后通过将父类实例作为子类原型,实现函数复用 function Cat(name) { Animal.call(this); this.name = name || 'Tom'; } Cat.prototype = new Animal(); Cat.prototype.constructor = Cat;
6.寄生组合继承:
//核心:通过寄生方式,砍掉父类的实例属性,这样,在调用俩次父类的构造的时候,就不会初始化俩次实例方法/属性,避免了组合继承的缺点。 function Cat(name) { Animal.call(this); this.name = name || 'Tom'; } (function() { var Super = function() {}; //创建一个没有实例的方法类。 Super.prototype = Animal.prototype; Cat.prototype = new Super(); //将实例作为子类的原型。 })();
7.多继承
Object.assign
10.浏览器的缓存
POST 因为是「新增或提交数据」的操作,会修改服务器上的资源,所以是不安全的,且多次提交数据就会创建多个资源,所以不是幂等的。所以,浏览器一般不会缓存 POST 请求,也不能把 POST 请求保存为书签。
1.强缓存
-
Cache-Control, 是一个相对时间; -
Expires,是一个绝对时间;
如果 HTTP 响应头部同时有 Cache-Control 和 Expires 字段的话,Cache-Control 的优先级高于 Expires 。
2.协商缓存
如果带上了 ETag 和 Last-Modified 字段信息给服务端,这时 Etag 的优先级更高,也就是服务端先会判断 Etag 是否变化了
浏览器会获取该缓存资源的 header 中的信息,根据 response header 中的 expires 和 cache-control 来判断是否命中强缓存,如果命中则直接从缓存中获取资源。 如果没有命中强缓存,浏览器就会发送请求到服务器,这次请求会带上 IF-Modified-Since 或者 IF-None-Match, 它们的值分别是第一次请求返回 Last-Modified或者 Etag,由服务器来对比这一对字段来判断是否命中。如果命中,则服务器返回 304 状态码,并且不会返回资源内容,浏览器会直接从缓存获取;否则服务器最终会返回资源的实际内容,并更新 header 中的相关缓存字段。
协商缓存这两个字段都需要配合强制缓存中 Cache-Control 字段来使用,只有在未能命中强制缓存的时候,才能发起带有协商缓存字段的请求。
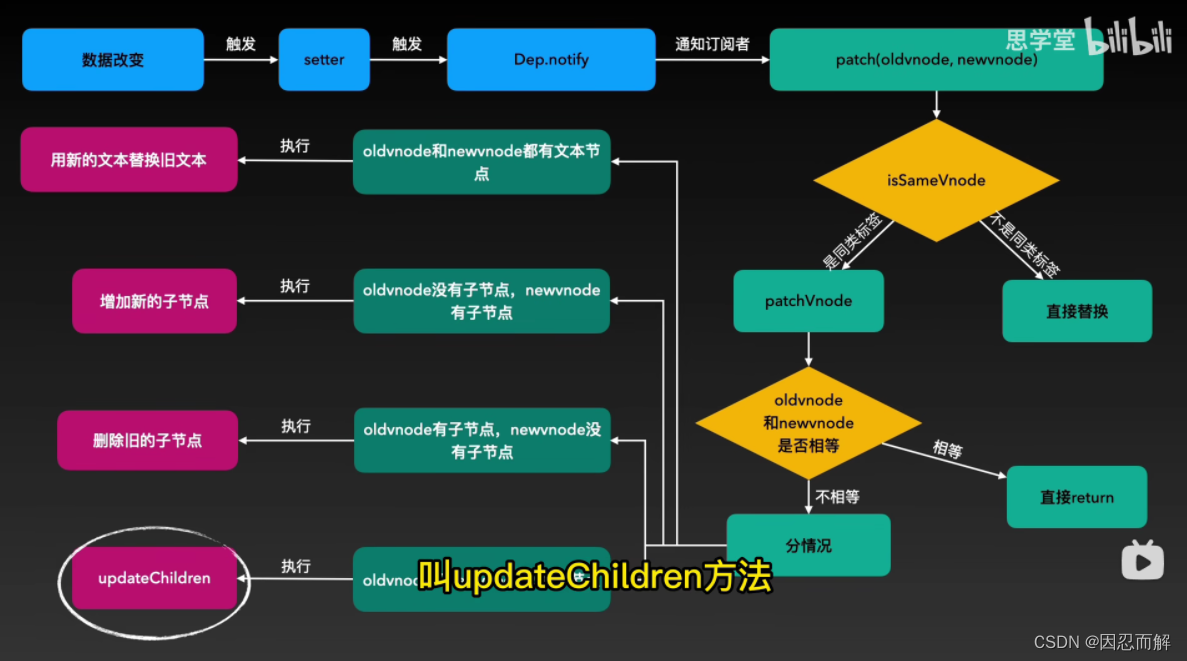
11.diff算法原理
1.diff是采用先序深度优先遍历得方式进行节点比较的
2.首先,代码初次运行,会走生命周期,当生命周期走到created到beforeMount之间的时候,会编译template模板成render函数。然后当render函数运行时,h函数被调用,而h函数内调用了vnode函数生成虚拟dom,并返回生成结果。故虚拟dom首次生成。 之后,当数据发生变化时会重新编译生成一个新vdom。再后面就等待新 旧两个vdom进行对比吧。我们后面就继续说对比的事情。
3.h函数内最主要得就是执行了 vnode函数,vnode函数得主要作用就是将h函数传进来得参数转行为了js对象(即虚拟dom)
4.通过diff算法,计算出两个前后两个虚拟dom之间的差异,得出一个更新的最优方法
5.虚拟dom,他是一个对象,下面有6个属性,sel表示当前节点标签名,data内是节点的属性,elm表示当前虚拟节点对应的真实节点(这里暂时没有),text表示当前节点下的文本,children表示当前节点下的其他标签
6.比较两个节点是否是相同节点,判断是否是相同节点的条件是,key和sel(选择器)必须都相同,这一步,只有比较根节点时,是在patch函数中进行的。非根节点都是在updateChildren函数中执行的,因为根节点只会有一个,可以直接比较
7.如果节点相同,那么进去第二部分,即比较两个节点的属性是否相同,节点是否存在文本,文本是否相同。是否存在子节点,子节点是否相同。这部分主要在patchVnode中执行
8.patch是比较的开始,相当于是diff的入口,diff就是从这一步开始的。那么既然是开始,说明patch函数比较的肯定就是两个新旧vdom的根节点了。所以,两个vdom直接的比较,patch是只会触发一次的。作用:比较两个虚拟dom根节点是否相同。
9.patchVnode 是用于比较两个相同节点的子级(文本,或子节点)的一个函数。故它的调用总是在sameVnode判断之后。只有判断当前比较的两个vnode相同时(这里我最后再解释一次,两个vnode相同仅仅代表key相同且sel选择器相同),才会被执行。 但,在比对之前,会先判断下oldVnode === vNode ,因为如果全等,代表子级肯定也完全相等,那么就没必要对比了,直接return;
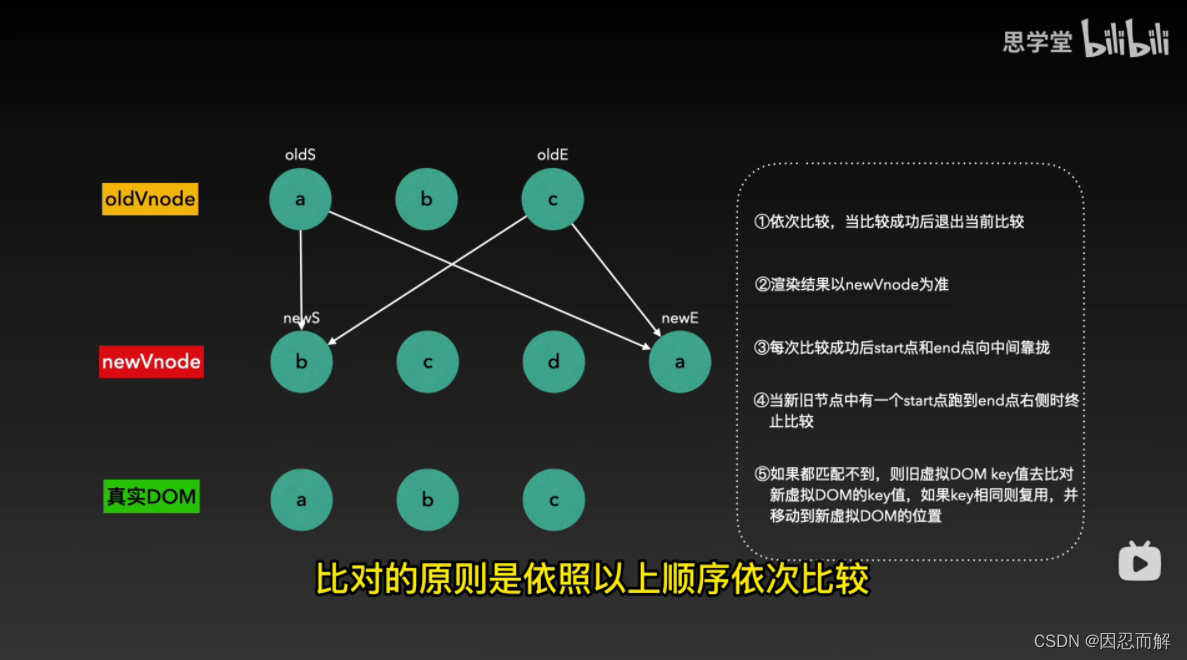
10.比较时,会优先拿oldStart<—>newStart,oldStart<—>newEnd,oldEnd<—>newStart,oldEnd<—>newEnd 两两进行对比。如果匹配上,那么会将旧节点对应的真实dom移到新节点的位置上。并将匹配上了的指针往中间移动。同时匹配上了的两个节点会继续指向patchVnode函数去进一步比对(指针的移动相当于永远保持指针中间的节点还是尚未匹配状态,已经匹配到的移到指针外面去)

12.事件循环和任务队列
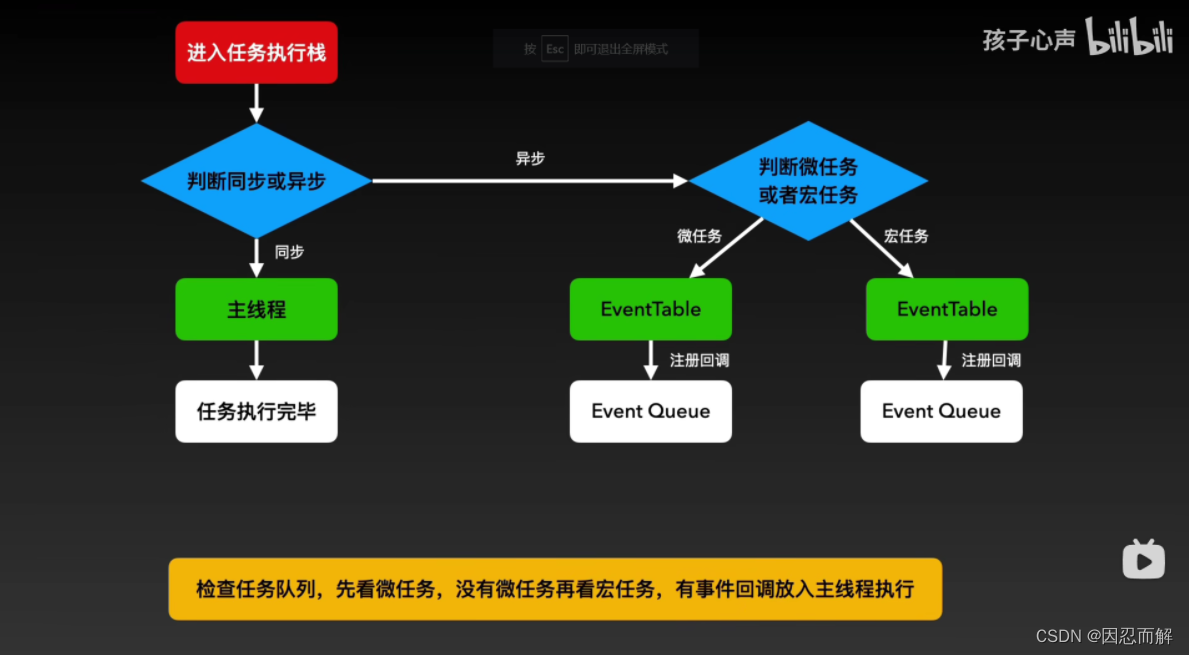
1.事件循环:JS 会创建一个类似于 while (true) 的循环,每执行一次循环体的过程称之为Tick。每次Tick的过程就是查看是否有待处理事件,如果有则取出相关事件及回调函数放入执行栈中由主线程执行。待处理的事件会存储在一个任务队列中,也就是每次Tick会查看任务队列中是否有需要执行的任务。
2.任务队列:异步操作会将相关回调添加到任务队列中。而不同的异步操作添加到任务队列的时机也不同,如onclick, setTimeout,ajax 处理的方式都不同,这些异步操作是由浏览器内核的webcore来执行的,webcore包含下图中的3种 webAPI,分别是DOM Binding、network、timer模块。
DOM Binding 模块处理一些DOM绑定事件,如onclick事件触发时,回调函数会立即被webcore添加到任务队列中。 network 模块处理Ajax请求,在网络请求返回时,才会将对应的回调函数添加到任务队列中。 timer 模块会对setTimeout等计时器进行延时处理,当时间到达的时候,才会将回调函数添加到任务队列中。
3.主线程:JS 只有一个线程,称之为主线程。而事件循环是主线程中执行栈里的代码执行完毕之后,才开始执行的。所以,主线程中要执行的代码时间过长,会阻塞事件循环的执行,也就会阻塞异步操作的执行。只有当主线程中执行栈为空的时候(即同步代码执行完后),才会进行事件循环来观察要执行的事件回调,当事件循环检测到任务队列中有事件就取出相关回调放入执行栈中由主线程执行。一个事件循环可以有多个任务队列,队列之间可有不同的优先级,同一队列中的任务按先进先出的顺序执行,但是不保证多个任务队列中的任务优先级,具体实现可能会交叉执行。
4.一个Promise的当前状态必须为以下三种状态中的一种:等待态(Pending)、执行态(Fulfilled)和拒绝态(Rejected)。
而上面的Promises规范就规定了,实践中要确保onFulfilled和onRejected异步执行,且应该在then方法被调用的那一轮事件循环以后的新执行栈中执行。
5.process.nextTick > promise.then > setTimeout > setImmediate。promise是同步态,resolve和reject是异步。
macrotask(按优先级顺序排列): script(你的全部JS代码,“同步代码”), setTimeout, setInterval, setImmediate, I/O,UI rendering microtask(按优先级顺序排列):process.nextTick,Promises(这里指浏览器原生实现的 Promise), Object.observe, MutationObserver 浏览器环境中,js执行任务的流程是这样的:
第一个事件循环,先执行script中的所有同步代码(即 macrotask 中的第一项任务) 再取出 microtask 中的全部任务执行(先清空process.nextTick队列,再清空promise.then队列) 下一个事件循环,再回到 macrotask 取其中的下一项任务 再重复2 反复执行事件循环…
13.宏任务、微任务
异步代码是在所有同步代码执行完毕以后才开始执行的。

14.XSS攻击与防范和CSRF攻击
1.xss
Cross-Site Scripting(跨站脚本攻击),简称XSS,是一种代码注入攻击。攻击者通过在目标网站上注入恶意脚本,使之在用户的浏览器上运行。利用这些恶意脚本,攻击者可获取用户的敏感信息如Cookie、SessionID等,
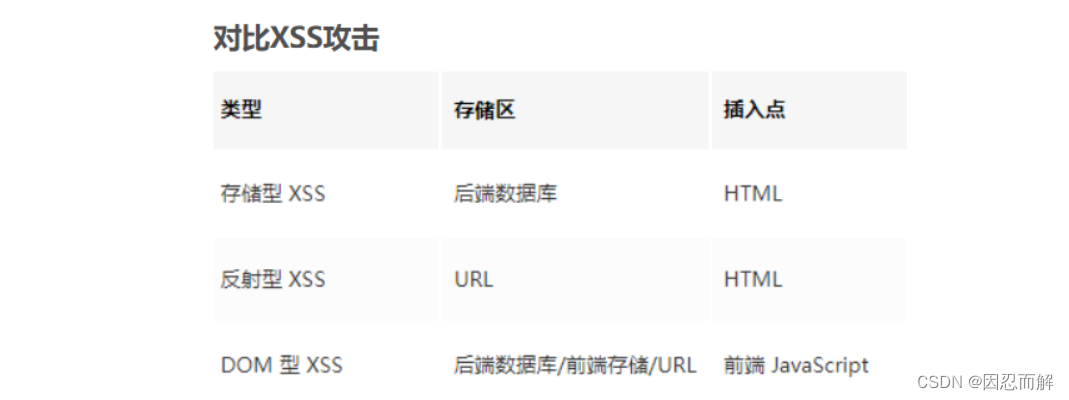
防御XSS攻击的方法 httpOnly:在cookie中设置HttpOnly属性后,js脚本将无法读取到cookie信息 输入过滤:一般是用于对于输入格式的检查,例如:邮箱,电话号码,用户名,密码……等,按照规定的格式输入。不仅仅是前端负责,后端也要做相同的过滤检查。因为攻击者完全可以绕过正常的输入流程,直接利用相关接口向服务器发送设置。 转义HTML:如果拼接 HTML 是必要的,就需要对于引号,尖括号,斜杠进行转义,但这还不是很完善.想对 HTML 模板各处插入点进行充分的转义,就需要采用合适的转义库
2.CSRF攻击
Cross-site request forgery(跨站请求伪造),是一种挟持用户在当前已登陆的Web应用程序上执行非本意的操作的攻击方法。如:攻击者诱导受害者进入第三方网站,在第三方网站中,向被攻击网站发送跨站请求。利用受害者在被攻击网站已经获取的注册凭证,绕过后台的用户验证,达到冒充用户对被攻击的网站执行某项操作的目的。
CSRF的特点 攻击一般发起在第三方网站,而不是被攻击的网站。被攻击的网站无法防止攻击发生。 攻击利用受害者在被攻击网站的登录凭证,冒充受害者提交操作;而不是直接窃取数据。 整个过程攻击者并不能获取到受害者的登录凭证,仅仅是“冒用”。 跨站请求可以用各种方式:图片URL、超链接、CORS、Form提交等等。部分请求方式可以直接嵌入在第三方论坛、文章中,难以进行追踪。
防御CSRF的方法 验证码;强制用户必须与应用进行交互,才能完成最终请求。此种方式能很好的遏制 csrf,但是用户体验比较差。
Referer check;请求来源限制,此种方法成本最低,但是并不能保证 100% 有效,因为服务器并不是什么时候都能取到 Referer,而且低版本的浏览器存在伪造 Referer 的风险。
token;token 验证的 CSRF 防御机制是公认最合适的方案。(具体可以查看本系列前端鉴权中对token有详细描述)若网站同时存在 XSS 漏洞的时候,这个方法也是空谈。
15.BOM
1.location
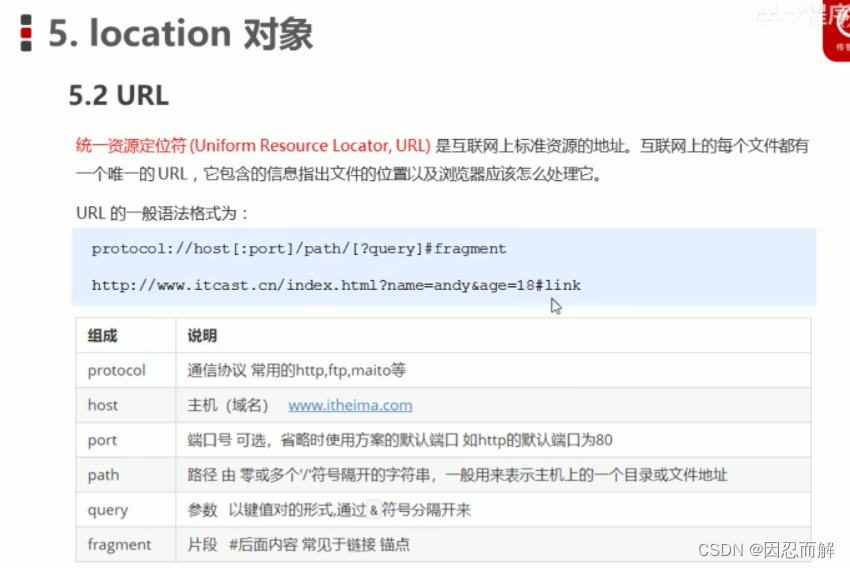

2.offset
offsetleft当元素没有设置css值时,可以动态的获取元素的宽高。


3.client

4.scroll
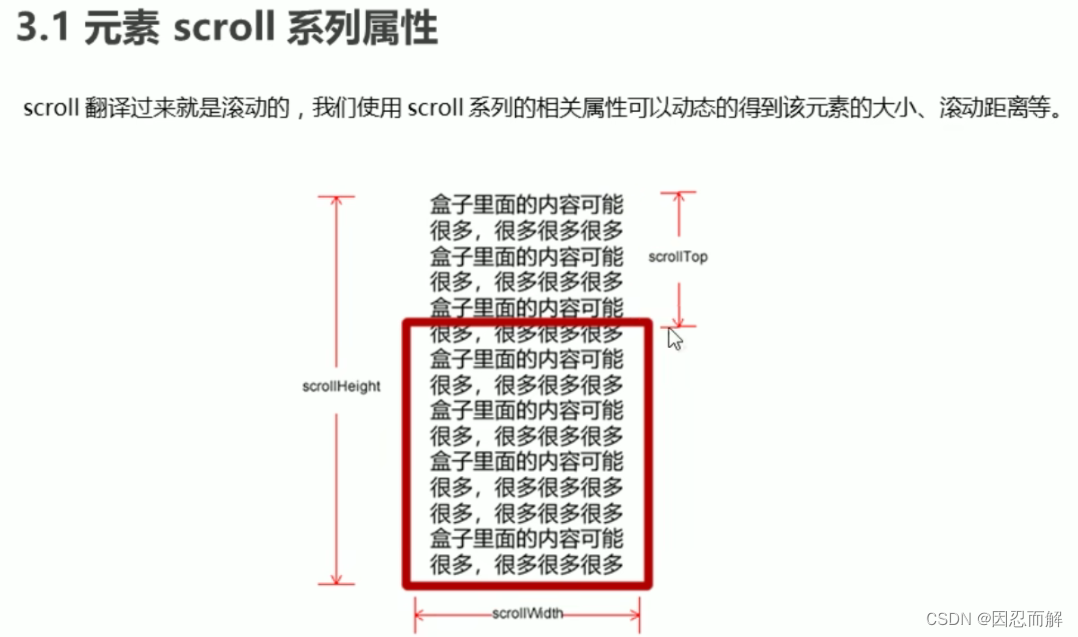
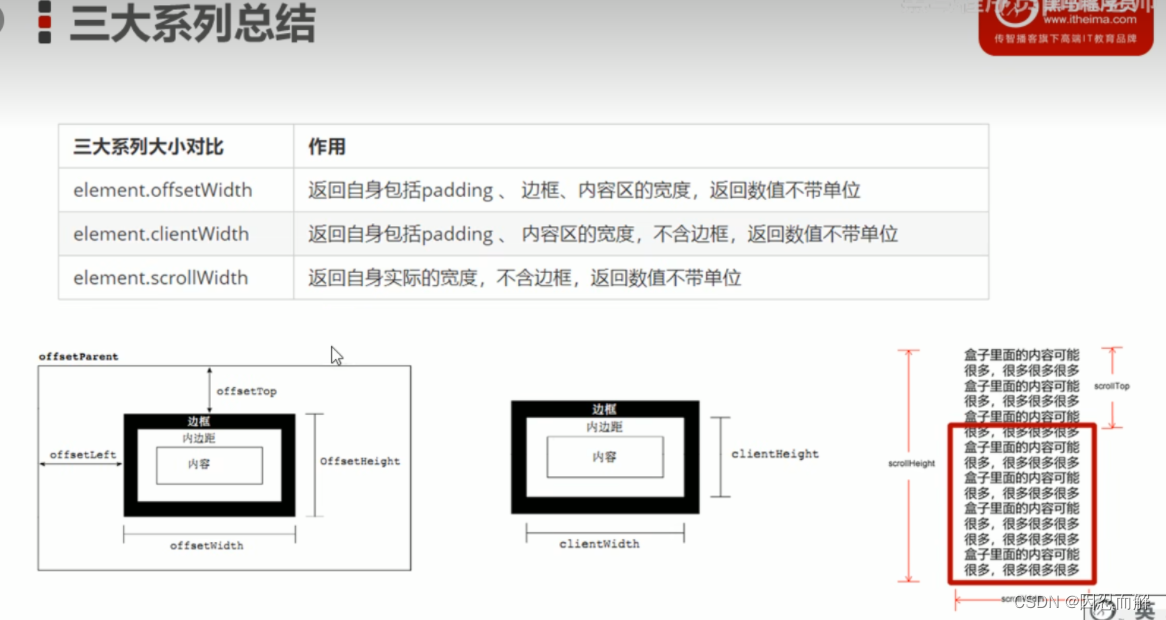
5.三大系列总结

16.浏览器输入url到页面展示出来的全过程
1、用户在浏览器中输入url地址
2、浏览器解析域名得到服务器ip地址
3、TCP三次握手建立客户端和服务器的连接
4、客户端发送HTTP请求获取服务器端的静态资源
5、服务器发送HTTP响应报文给客户端,客户端获取到页面静态资源
6、TCP四次挥手关闭客户端和服务器的连接
7、浏览器解析文档资源并渲染页面
① 强缓存
不会向服务器发送请求,直接从缓存中读取资源,在控制台的Network选项中可以看到该请求返回200的状态码,并且Size显示from disk cache 或 from memory cache。
-
If-None-Match 与Etag的值一致,则 代表 服务端的资源在上一次请求到这次请求的期间未发生更新,可 继续使用缓存文件,无须返回资源,状态码为304;
-
f-None-Match 与Etag的值不一致,则 代表 资源发生过更新,须重新返回资源文件,状态码为200;
17.一个html可以引入多个js,一个HTML文件引入多个JS文件onload的问题
一般我们这样子添加回调:
btn.onclick = func;
但是如果添加多个回调并且顺序执行肯定就不能这样了,因为这样后面的会覆盖前面的。
于是:
//element.addEventListener(type,listener,useCapture);
btn.addEventListener("click", func1, false);
btn.addEventListener("click", func2, false);
btn.addEventListener("click", func3, false);
18.什么是BFC,他有什么用?

(1)清除盒子垂直方向上外边距合并——盒子垂直方向的距离由margin决定。属于同一个BFC的两个相邻盒子垂直方向的margin会发生重叠。 解决方法: 根据属于同一个BFC的两个相邻盒子垂直方向的margin会发生重叠的性质,可以给其中一个盒子再包裹一个盒子父元素,并触发其BFC功能(例如添加overflow:hidden;)这样垂直方向的两个盒子就不在同一个BFC中了,因此也不会发生垂直外边距合并的问题了。 (2)在子元素设置成浮动元素的时候,会产生父元素高度塌陷的问题。 解决方法: 给父元素设置overflow:hidden;的时候会产生BFC 由于在计算BFC高度时,自然也会检测浮动的子盒子高度。所以当子盒子有高度但是浮动的时候,通过激发父盒子的BFC功能,会产生清除浮动的效果。
19.图片懒加载
20.是否是一个数组和对象的判断
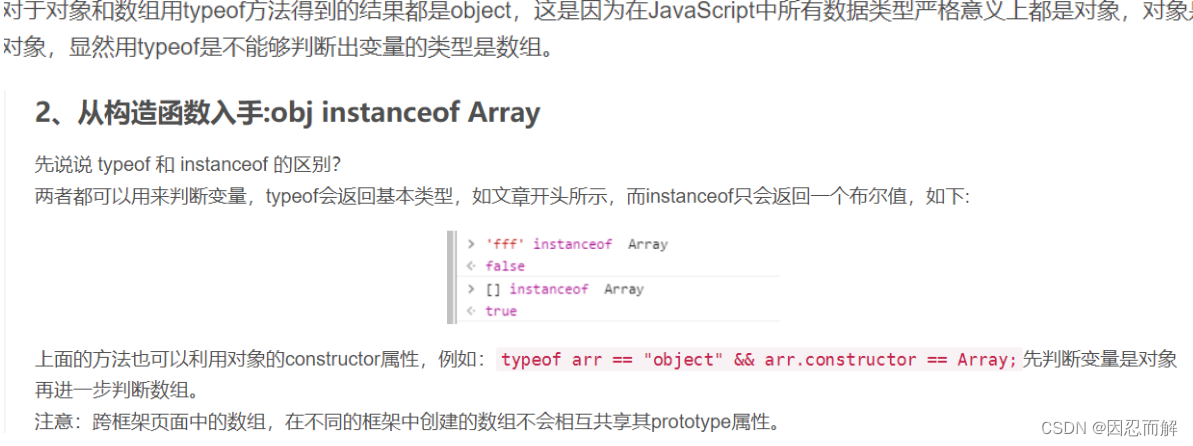
1、从原型入手:Array.prototype.isPrototypeOf(obj);
2、从构造函数入手:obj instanceof Array
3、跨原型链调用toString():Object.prototype.toString.call(obj)
4、ES6新增的方法:Array.isArray()
instanceof运算符可以用于区分对象和数组
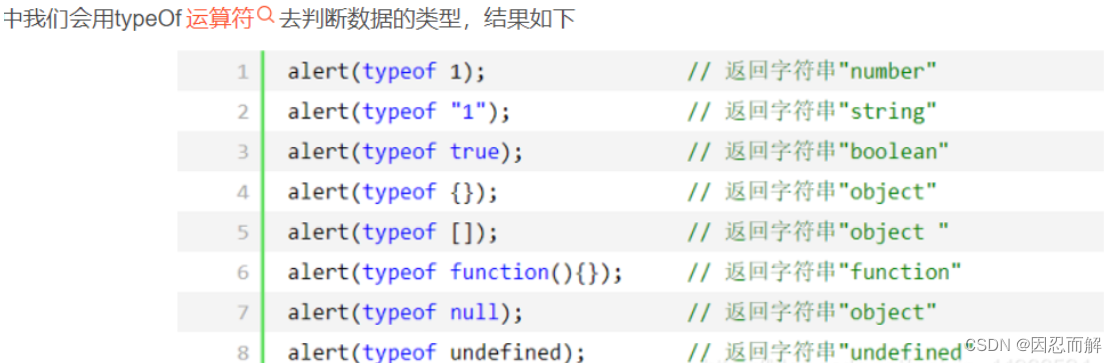
21.如何判断一个对象是空对象
如果我们调用Object.getOwnPropertyNames(myObj),它会返回一个数组,["name", "age", "city"]因为这些是对象自身的属性myObj。
请注意,Object.getOwnPropertyNames()不返回从对象的原型链继承的属性。要获取对象的所有属性,包括继承的属性,我们可以使用循环for...in或Object.keys()方法。
经典面试题,研发时也经常遇见的一个问题:如何判断一个对象是空对象?
方法一:将对象转换成字符串,再判断是否等于“{}”
let obj={};
console.log(JSON.stringify(obj)==="{}");
方法二:for in循环
let result=function(obj){
for(let key in obj){
return false;//若不为空,可遍历,返回false
}
return true;
}
console.log(result(obj));//返回true
方法三:Object.keys()方法,返回对象的属性名组成的一个数组,若长度为0,则为空对象(ES6的写法)
console.log(Object.keys(obj).length==0);//返回true
方法四:Object.getOwnPropertyNames方法获取对象的属性名,存到数组中,若长度为0,则为空对象
console.log(Object.getOwnPropertyNames(obj).length==0);//返回true
22.Vue3的七种组件通信方式
-
props
-
emit
-
v-model
-
<child-components v-model:list="list"></child-components>
-
<ChildComponent :list="pageTitle" @update:list="pageTitle = $event" />
-
const emits = defineEmits(['update:list'])
-
const props = defineProps({ list: { type: Array, default: () => [], }, })
-
-
refs
-
provide/inject
-
eventBus
-
vuex/pinia(状态管理工具)
23.捕获全局promise错误
window.addEventListener(‘unhandledrejection’, function (event) {}) event有个reason属性,里面有error的message和堆栈信息… 要event.preventDefault()阻止冒泡才行
24.JavaScript中实现sleep睡眠函数的几种简单方法
1.基于Date实现
通过死循环来阻止代码执行,同时不停比对是否超时。
function sleep(time){
var timeStamp = new Date().getTime();
var endTime = timeStamp + time;
while(true){
if (new Date().getTime() > endTime){
return;
}
}
}
console.time('runTime:');
sleep(2000);
console.log('1');
sleep(3000);
console.log('2');
sleep(2000);
console.log('3');
console.timeEnd('runTime:');
// 1
// 2
// 3
// runTime:: 7004.301ms
2.基于Promise的sleep
单纯的Promise只是将之前的纵向嵌套改为了横向嵌套:
function sleep(time){
return new Promise(function(resolve){
setTimeout(resolve, time);
});
}
console.time('runTime:');
console.log('1');
sleep(1000).then(function(){
console.log('2');
sleep(2000).then(function(){
console.log('3');
console.timeEnd('runTime:');
});
});
console.log('a');
// 1
// a
// 2
// 3
// runTime:: 3013.476ms
25.plugin和loader执行时间的区别webpack
plugin 通过webpack中Tapable事件流的生命周期进行广播
在webpack中,loader是在模块编译时执行的,而plugins则是在整个编译过程中执行的。因此,它们的执行时间上是有区别的。一般来说,loader用来对模块的源代码进行转换,而plugins则可以用来实现更高级别的任务,比如代码优化、资源管理等。
webpack:
-
初始化参数:从配置文件和 Shell 语句中读取与合并参数,得出最终的参数。
-
开始编译:用上一步得到的参数初始化 Compiler 对象,加载所有配置的插件,执行对象的 run 方法开始执行编译。
-
确定入口:根据配置中的 entry 找出所有的入口文件。
-
编译模块:从入口文件出发,调用所有配置的 Loader 对模块进行翻译,再找出该模块依赖的模块,再递归本步骤直到所有入口依赖的文件都经过了本步骤的处理。根据 entry 对应的 dependence 创建 module 对象,调用 loader 将模块转译为标准 JS 内容,调用 JS 解释器将内容转换为 AST 对象,从中找出该模块依赖的模块,再 递归 本步骤直到所有入口依赖的文件都经过了本步骤的处理
-
完成模块编译:在经过第 4 步使用 Loader 翻译完所有模块后,得到了每个模块被翻译后的最终内容以及它们之间的依赖关系。
-
输出资源:根据入口和模块之间的依赖关系,组装成一个个包含多个模块的 Chunk,再把每个 Chunk 转换成一个单独的文件加入到输出列表,这步是可以修改输出内容的最后机会。
-
输出完成:在确定好输出内容后,根据配置确定输出的路径和文件名,把文件内容写入到文件系统。
26.Vue响应式原理
vue实现数据响应式,是通过数据劫持侦测数据变化,发布订阅模式进行依赖收集与视图更新
所谓的依赖,其实就是Watcher。至于如何收集依赖,总结起来就一句话,在getter中收集依赖,在setter中触发依赖。先收集依赖,即把用到该数据的地方收集起来,然后等属性发生变化时,把之前收集好的依赖循环触发一遍就行了。
具体来说,当外界通过Watcher读取数据时,便会触发getter从而将Watcher添加到依赖中,哪个Watcher触发了getter,就把哪个Watcher收集到Dep中。当数据发生变化时,会循环依赖列表,把所有的Watcher都通知一遍。
最后我们对 defineReactive 函数进行改造,在自定义函数中添加依赖收集和派发更新相关的代码,实现了一个简易的数据响应式。 在修改对象的值的时候,会触发对应的 setter, setter通知之前依赖收集得到的 Dep 中的每一个 Watcher,告诉它们自己的值改变了,需要重新渲染视图。这时候这些 Watcher就会开始调用 update 来更新视图。
27.vue 父子组件的加载顺序
在beforeMounted调用时,虚拟DOM已经生成,但并未挂载到页面中
1、父子组件的加载顺序为 父beforeCreated ->父created ->父beforeMounted ->子beforeCreated ->子created ->子beforeMounted ->子mounted -> 父mounted
2、父组件更新顺序为 父beforeUpdate->父updated
3、子组件更新顺序为 父beforeUpdate->子beforeUpdate->子updated->父updated
4、父子组件销毁顺序为 父beforeDestroy->子beforeDestroy->子destroyed->父destroyed
28.小程序跳转到公众号页面的渲染机制
一、web-view方法
<!--pages/webview666/webview.wxml-->
<view class="ty_box">
<web-view src="{
{url}}">小程序跳转公众号</web-view>
</view>

二、official-account方法
首先要把公众号和小程序关联起来
在公众号中找到小程序管理----关联小程序
关联成功后
<!--pages/ceshi/ceshi.wxml--> <view style="margin-top:50%;"> <official-account></official-account> </view>
29.微信支付流程
APP用户点击进行支付,会向我们自己的订单服务发送请求,携带订单的相关信息 订单服务接收到请求之后需要保存订单,调用微信统一下单接口生成预支付订单,微信会返回预支付订单标识,订单服务会根据微信返回的标识生成带签名的支付信息 App端发起支付,向服务端查询带签名的支付信息,服务端返回带签名的支付信息 APP端使用带签名的支付信息,调用微信客户端唤醒微信APP 微信APP会向微信支付系统发起支付请求,微信支付系统会校验支付授权,返回授权结果 跳转微信支付界面,用户输入支付密码,提交授权,发送支付请求到微信支付系统,微信支付系统会验证授权,授权通过支付成功 支付成功微信支付系统会向微信APP返回支付成功标识,微信APP收到支付成功标识,会通知我们的APP,支付成功,APP收到支付成功信息之后,跳转到支付成功界面。
30.JavaScript的垃圾回收
JavaScript的垃圾回收就是定期找出这些不可达的对象,然后将其释放。那么找出这些不可达的对象有两种常用的策略:
-
标记清除法
标记清除法分为标记和清除两个阶段,标记阶段需要从根节点遍历内存中的所有对象,并为可达的对象做上标记,清除阶段则把没有标记的对象(非可达对象)销毁。
标记清除法的优点就是实现简单。
它的缺点有两个,首先是内存碎片化。这是因为清理掉垃圾之后,未被清除的对象内存位置是不变的,而被清除掉的内存穿插在未被清除的对象中,导致了内存碎片化。
-
引用计数法
引用计数法的优点是可以实现立即进行垃圾回收。当引用计数在引用值为0时,立即进行垃圾回收,这样可以达到立刻垃圾回收的效果。
它的缺点也有两个,首先它需要一个计数器,这个计数器可能要占据很大的位置,因为我们无法知道被引用数量的多少。
31、项目难点
从0开始做,讲背景,跟领导开发确认需求,然后不断改UI风格,promise.all,权限管理(两套方案),webpack数据上线优化。
uniapp:微信调用二维码,tab栏自定义
32、操作系统
软中断的处理
内核中的 ksoftirqd 线程专门负责软中断的处理,当 ksoftirqd 内核线程收到软中断后,就会来轮询处理数据。
ksoftirqd 线程会从 Ring Buffer 中获取一个数据帧,用 sk_buff 表示,从而可以作为一个网络包交给网络协议栈进行逐层处理。
1.系统调用


2、进程
操作系统中最核心的概念就是进程,进程是对正在运行中的程序的一个抽象,是系统进行资源分配和调度的基本单位
进程是一种抽象的概念,从来没有统一的标准定义看,一般由程序、数据集合和进程控制块三部分组成:
-
程序用于描述进程要完成的功能,是控制进程执行的指令集
-
数据集合是程序在执行时所需要的数据和工作区
-
程序控制块,包含进程的描述信息和控制信息,是进程存在的唯一标志
3、线程
线程(thread)是操作系统能够进行运算调度的最小单位,其是进程中的一个执行任务(控制单元),负责当前进程中程序的执行
一个进程至少有一个线程,一个进程可以运行多个线程,这些线程共享同一块内存,线程之间可以共享对象、资源,如果有冲突或需要协同,还可以随时沟通以解决冲突或保持同步
4、进程与线程的区别
-
本质区别:进程是操作系统资源分配的基本单位,而线程是任务调度和执行的基本单位
-
在开销方面:每个进程都有独立的代码和数据空间(程序上下文),程序之间的切换会有较大的开销;线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器(PC),线程之间切换的开销小
-
所处环境:在操作系统中能同时运行多个进程(程序);而在同一个进程(程序)中有多个线程同时执行(通过CPU调度,在每个时间片中只有一个线程执行)
-
内存分配方面:系统在运行的时候会为每个进程分配不同的内存空间;而对线程而言,除了CPU外,系统不会为线程分配内存(线程所使用的资源来自其所属进程的资源),线程组之间只能共享资源
-
包含关系:没有线程的进程可以看做是单线程的,如果一个进程内有多个线程,则执行过程不是一条线的,而是多条线(线程)共同完成的;线程是进程的一部分,所以线程也被称为轻权进程或者轻量级进程
-
进程间不会相互影响,一个线程挂掉将导致整个进程挂掉(一列火车不会影响到另外一列火车,但是如果一列火车上中间的一节车厢着火了,将影响到所有车厢)
-
5.文件操作
常见处理目录的命令如下:
-
ls(英文全拼:list files): 列出目录及文件名
-
cd(英文全拼:change directory):切换目录
-
pwd(英文全拼:print work directory):显示目前的目录
-
mkdir(英文全拼:make directory):创建一个新的目录
-
rmdir(英文全拼:remove directory):删除一个空的目录
-
cp(英文全拼:copy file): 复制文件或目录
-
rm(英文全拼:remove): 删除文件或目录
-
mv(英文全拼:move file): 移动文件与目录,或修改文件与目录的名称
6.重定向与管道
简单来讲,重定向就是把本来要显示在终端的命令结果,输送到别的地方,分成:
-
输入重定向:流出到屏幕如果命令所需的输入不是来自键盘,而是来自指定的文件
-
输出重定向:命令的输出可以不显示在屏幕,而是写在指定的文件中
管道就是把两个命令连接起来使用,一个命令的输出作为另一个命令的输入
两者的区别在于:
-
管道触发两个子进程,执行 | 两边的程序;而重定向是在一个进程内执行。
-
管道两边都是shell命令
-
重定向符号的右边只能是Linux文件
-
重定向符号的优先级大于管道
7.CPU缓存一致性
-
第一点,某个 CPU 核心里的 Cache 数据更新时,必须要传播到其他核心的 Cache,这个称为写传播(*Write Propagation*);
-
第二点,某个 CPU 核心里对数据的操作顺序,必须在其他核心看起来顺序是一样的,这个称为事务的串行化(*Transaction Serialization*)。
要实现事务串行化,要做到 2 点:
-
CPU 核心对于 Cache 中数据的操作,需要同步给其他 CPU 核心;
-
要引入「锁」的概念,如果两个 CPU 核心里有相同数据的 Cache,那么对于这个 Cache 数据的更新,只有拿到了「锁」,才能进行对应的数据更新。
MESI 协议
MESI 协议其实是 4 个状态单词的开头字母缩写,分别是:
-
Modified,已修改
-
Exclusive,独占
-
Shared,共享
-
Invalidated,已失效
这四个状态来标记 Cache Line 四个不同的状态。
-
-
34.ast 、JavaScript引擎工作原理解析
ast语法树
js 引擎包括 parser、解释器、gc 再加一个 JIT 编译器这几部分
parser: 负责把 javascript 源码转成 AST(抽象语法树,一种数据结构,实际上就是JSON对象) interperter:解释器, 负责转换 AST 成字节码,并解释执行 JIT compiler:对执行时的热点函数进行编译,把字节码转成机器码,之后可以直接执行机器码 gc(garbage collector):垃圾回收器,清理堆内存中不再使用的对象
35、http系列
0.HTTP1.0
1996年5月,HTTP/1.0 版本发布,内容大大增加。
首先,任何格式的内容都可以发送。这使得互联网不仅可以传输文字,还能传输图像、视频、二进制文件。这为互联网的大发展奠定了基础。
其次,除了GET命令,还引入了POST命令和HEAD命令,丰富了浏览器与服务器的互动手段。
再次,HTTP请求和回应的格式也变了。除了数据部分,每次通信都必须包括头信息(HTTP header),用来描述一些元数据。
其他的新增功能还包括状态码(status code)、多字符集支持、多部分发送(multi-part type)、权限(authorization)、缓存(cache)、内容编码(content encoding)等。
HTTP1.0的问题 HTTP/1.0 版的主要缺点是,每个TCP连接只能发送一个请求。发送数据完毕,连接就关闭,如果还要请求其他资源,就必须再新建一个连接。
TCP连接的新建成本很高,因为需要客户端和服务器三次握手,并且开始时发送速率较慢(slow start)。所以,HTTP 1.0版本的性能比较差。随着网页加载的外部资源越来越多,这个问题就愈发突出了。
1. HTTP1.1
的缺点有哪些?
无状态的坏处,对于无状态的问题,解法方案有很多种,其中比较简单的方式用 Cookie 技术。
不安全
HTTP 比较严重的缺点就是不安全:
-
通信使用明文(不加密),内容可能会被窃听。比如,账号信息容易泄漏,那你号没了。
-
不验证通信方的身份,因此有可能遭遇伪装。比如,访问假的淘宝、拼多多,那你钱没了。
-
无法证明报文的完整性,所以有可能已遭篡改。比如,网页上植入垃圾广告,视觉污染,眼没了。
管道网络传输*
HTTP/1.1 采用了长连接的方式,这使得管道(pipeline)网络传输成为了可能。
即可在同一个 TCP 连接里面,客户端可以发起多个请求,只要第一个请求发出去了,不必等其回来,就可以发第二个请求出去,可以减少整体的响应时间。
但是服务器必须按照接收请求的顺序发送对这些管道化请求的响应。
如果服务端在处理 A 请求时耗时比较长,那么后续的请求的处理都会被阻塞住,这称为「队头堵塞」。
所以,HTTP/1.1 管道解决了请求的队头阻塞,但是没有解决响应的队头阻塞。
-
请求 / 响应头部(Header)未经压缩就发送,首部信息越多延迟越大。只能压缩
Body的部分; -
发送冗长的首部。每次互相发送相同的首部造成的浪费较多;
-
服务器是按请求的顺序响应的,如果服务器响应慢,会招致客户端一直请求不到数据,也就是队头阻塞;
-
没有请求优先级控制;
-
请求只能从客户端开始,服务器只能被动响应。
2.HTTPS 解决了 HTTP 的哪些问题?
HTTP 由于是明文传输,所以安全上存在以下三个风险:
-
窃听风险,比如通信链路上可以获取通信内容,用户号容易没。
-
篡改风险,比如强制植入垃圾广告,视觉污染,用户眼容易瞎。
-
冒充风险,比如冒充淘宝网站,用户钱容易没。
-
混合加密的方式实现信息的机密性,解决了窃听的风险。
-
摘要算法的方式来实现完整性,它能够为数据生成独一无二的「指纹」,指纹用于校验数据的完整性,解决了篡改的风险。
-
将服务器公钥放入到数字证书中,解决了冒充的风险。
一般我们不会用非对称加密来加密实际的传输内容,因为非对称加密的计算比较耗费性能的。
所以非对称加密的用途主要在于通过「私钥加密,公钥解密」的方式,来确认消息的身份,我们常说的数字签名算法,就是用的是这种方式,不过私钥加密内容不是内容本身,而是对内容的哈希值加密。
HTTPS 采用的是对称加密和非对称加密结合的「混合加密」方式:
-
在通信建立前采用非对称加密的方式交换「会话秘钥」,后续就不再使用非对称加密。
-
在通信过程中全部使用对称加密的「会话秘钥」的方式加密明文数据。
采用「混合加密」的方式的原因:
-
对称加密只使用一个密钥,运算速度快,密钥必须保密,无法做到安全的密钥交换。
-
非对称加密使用两个密钥:公钥和私钥,公钥可以任意分发而私钥保密,解决了密钥交换问题但速度慢。
3.HTTP2
HTTP/2 协议是基于 HTTPS 的,所以 HTTP/2 的安全性也是有保障的。
那 HTTP/2 相比 HTTP/1.1 性能上的改进:
-
头部压缩
-
二进制格式
-
并发传输
针对不同的 HTTP 请求用独一无二的 Stream ID 来区分,接收端可以通过 Stream ID 有序组装成 HTTP 消息,不同 Stream 的帧是可以乱序发送的,因此可以并发不同的 Stream ,也就是 HTTP/2 可以并行交错地发送请求和响应。
-
服务器主动推送资源
客户端和服务器双方都可以建立 Stream, Stream ID 也是有区别的,客户端建立的 Stream 必须是奇数号,而服务器建立的 Stream 必须是偶数号。
缺点:
HTTP/2 通过 Stream 的并发能力,解决了 HTTP/1 队头阻塞的问题,看似很完美了,但是 HTTP/2 还是存在“队头阻塞”的问题,只不过问题不是在 HTTP 这一层面,而是在 TCP 这一层。
HTTP/2 是基于 TCP 协议来传输数据的,TCP 是字节流协议,TCP 层必须保证收到的字节数据是完整且连续的,这样内核才会将缓冲区里的数据返回给 HTTP 应用,那么当「前 1 个字节数据」没有到达时,后收到的字节数据只能存放在内核缓冲区里,只有等到这 1 个字节数据到达时,HTTP/2 应用层才能从内核中拿到数据,这就是 HTTP/2 队头阻塞问题。
4.HTTP3
QUIC 有以下 3 个特点。
-
无队头阻塞
QUIC 有自己的一套机制可以保证传输的可靠性的。当某个流发生丢包时,只会阻塞这个流,其他流不会受到影响,因此不存在队头阻塞问题。
-
更快的连接建立
HTTP/3 在传输数据前虽然需要 QUIC 协议握手,但是这个握手过程只需要 1 RTT,握手的目的是为确认双方的「连接 ID」,连接迁移就是基于连接 ID 实现的。
但是 HTTP/3 的 QUIC 协议并不是与 TLS 分层,而是 QUIC 内部包含了 TLS
-
连接迁移
那么当移动设备的网络从 4G 切换到 WIFI 时,意味着 IP 地址变化了,那么就必须要断开连接,然后重新建立连接。而建立连接的过程包含 TCP 三次握手和 TLS 四次握手的时延,以及 TCP 慢启动的减速过程,给用户的感觉就是网络突然卡顿了一下,因此连接的迁移成本是很高的。
而 QUIC 协议没有用四元组的方式来“绑定”连接,而是通过连接 ID 来标记通信的两个端点,客户端和服务器可以各自选择一组 ID 来标记自己,因此即使移动设备的网络变化后,导致 IP 地址变化了,只要仍保有上下文信息(比如连接 ID、TLS 密钥等),就可以“无缝”地复用原连接,消除重连的成本,没有丝毫卡顿感,达到了连接迁移的功能
QUIC 是一个在 UDP 之上的伪 TCP + TLS + HTTP/2 的多路复用的协议。
QUIC 是新协议,对于很多网络设备,根本不知道什么是 QUIC,只会当做 UDP,这样会出现新的问题,因为有的网络设备是会丢掉 UDP 包的,而 QUIC 是基于 UDP 实现的,那么如果网络设备无法识别这个是 QUIC 包,那么就会当作 UDP包,然后被丢弃。
36、浅拷贝与深拷贝
js的浅拷贝:
出现一个数组套数组的情况,数组的那几种方法一层的时候为深拷贝,二层的时候仍然为浅拷贝
slice() 、
concat() 、
…扩展运算符、
Array.from:Array.from()方法就是将一个类数组对象或者可遍历对象转换成一个真正的数组,也是ES6的新增方法
Object.assign():Object.assign方法的第一个参数是目标对象,后边的其他参数都是源对象
js的深拷贝:
-
_.cloneDeep() lodash中的
-
JSON.parse(JSON.stringify(obj)):
万能转换器 JSON.parse(JSON.stringify(obj))深拷贝已有对象,它可以深拷贝多层级的,不用担心嵌套
-
jQuery.extend()
37、==与===的区别
最大的区别就是==会进行类型的转换之后再判断两者是否相等;只有等式两边是全等(数据类型相同,值相同)的时候结果才会是true,否则全为false
==判断等式两边是否相等的情况:
(1)null、undefined和不同类型比较,都是false(null和undefined结果为true)
(2)NaN和任何数据进行比较,都是false(包括NaN和NaN相比较也为false)
(3)布尔值是转换为数字1或0再和其他数据进行比较
console.log(Boolean('')); //false
console.log(Boolean({})); //true
console.log(Boolean([])); //true
console.log(Boolean(null)); //false
console.log(Boolean(undefined)); //false
console.log(Boolean(NaN)); //false
console.log(Boolean(Object)); //true
(4)数字和其他简单数据类型进行比较时,会尝试将其他数据类型转换成数值型再进行比较
console.log(""==false); //true
console.log(parseInt("")); //NaN
console.log(Number("")); //0
console.log(""==0); //true
全等比较(===)不转换数据类型,数据类型和内容必须完全一致才是相等
全等比较(===)两边是否相等的情况:
(1)类型不同,一定不相等
(2)两个同为数值,并且相等,则相等;若其中一个为NaN,一定不相等
(3)两个都为字符串,每个位置的字符都一样,则相等
(4)两个同为true,或是false,则相等
(5)两个值都引用同一个对象或函数,则相等,否则不相等(引用类型地址空间可能不一样)
(6)两个值都为null,或undefined,则相等
(7*)两者同为引用类型时,必须是指向同一个引用地址才相等,否则不相等(5的补充)
(8)-0 === +0 结果为:true
38、变量提升、函数提升

最终会依次打印出:fn函数 20 10

39、undefined和null的区别
在JavaScript中将某个变量赋值为undefined或null,实际上没有太大的差别,两者都是表示某个变量的值为“空”
1、undefined不是关键字,而null是关键字;
2、undefined和null被转换为布尔值的时候,两者都为false;
3、undefined在和null进行==比较时两者相等,全等于比较时两者不等
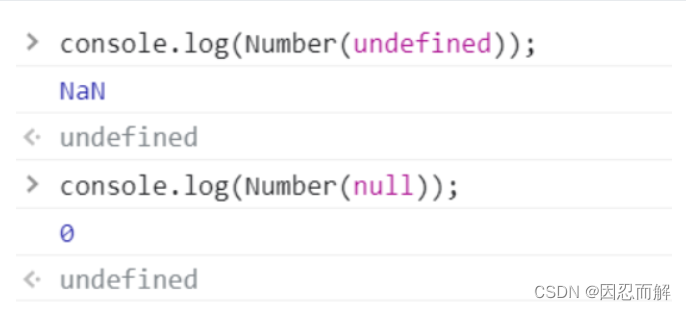
4、使用Number()对undefined和null进行类型转换
5、undefined本质上是window的一个属性,而null是一个对象;
6、undefined和null的用途
null表示没有对象,即不应该有值,经常用作函数的参数,或作为原型链的重点。
undefined表示缺少值,即应该有值,但是还没有赋予(变量提升时默认会赋值为undefined,函数参数未提供默认为undefined,函数的返回值默认为undefined)
40、js使用new创建对象的过程
1、 创建空对象; var obj = {}; 2、 设置新对象obj的constructor属性为构造函数的名称,设置新对象obj的proto属性指向构造函数的prototype对象; obj.proto = ClassA.prototype; 3、 使用新对象调用函数,函数中的this被指向新实例对象: ClassA.call(obj); //通过 call(),obj能够使用属于另一个对象的方法。 4、 将初始化完毕的obj返回,赋给变量p
41、requireJS原理,ES6 import原理,两者区别
AMD是 "Asynchronous Module Definition" 的缩写,意思就是 "异步模块定义"。它采用异步方式加载模块,模块的加载不影响它后面语句的运行。所有依赖这个模块的语句,都定义在一个回调函数中,等到加载完成之后,这个回调函数才会运行。
42、状态码
1xx 类状态码属于提示信息,是协议处理中的一种中间状态,实际用到的比较少。
2xx 类状态码表示服务器成功处理了客户端的请求,也是我们最愿意看到的状态。
-
「200 OK」是最常见的成功状态码,表示一切正常。如果是非
HEAD请求,服务器返回的响应头都会有 body 数据。 -
「204 No Content」也是常见的成功状态码,与 200 OK 基本相同,但响应头没有 body 数据。
-
「206 Partial Content」是应用于 HTTP 分块下载或断点续传,表示响应返回的 body 数据并不是资源的全部,而是其中的一部分,也是服务器处理成功的状态。
3xx 类状态码表示客户端请求的资源发生了变动,需要客户端用新的 URL 重新发送请求获取资源,也就是重定向。
-
「301 Moved Permanently」表示永久重定向,说明请求的资源已经不存在了,需改用新的 URL 再次访问。
-
「302 Found」表示临时重定向,说明请求的资源还在,但暂时需要用另一个 URL 来访问。
301 和 302 都会在响应头里使用字段 Location,指明后续要跳转的 URL,浏览器会自动重定向新的 URL。
-
「304 Not Modified」不具有跳转的含义,表示资源未修改,重定向已存在的缓冲文件,也称缓存重定向,也就是告诉客户端可以继续使用缓存资源,用于缓存控制。
4xx 类状态码表示客户端发送的报文有误,服务器无法处理,也就是错误码的含义。
-
「400 Bad Request」表示客户端请求的报文有错误,但只是个笼统的错误。
-
「403 Forbidden」表示服务器禁止访问资源,并不是客户端的请求出错。
-
「404 Not Found」表示请求的资源在服务器上不存在或未找到,所以无法提供给客户端。
5xx 类状态码表示客户端请求报文正确,但是服务器处理时内部发生了错误,属于服务器端的错误码。
-
「500 Internal Server Error」与 400 类型,是个笼统通用的错误码,服务器发生了什么错误,我们并不知道。
-
「501 Not Implemented」表示客户端请求的功能还不支持,类似“即将开业,敬请期待”的意思。
-
「502 Bad Gateway」通常是服务器作为网关或代理时返回的错误码,表示服务器自身工作正常,访问后端服务器发生了错误。
-
「503 Service Unavailable」表示服务器当前很忙,暂时无法响应客户端,类似“网络服务正忙,请稍后重试”的意思。
43、https连接建立:使用非对称加密和对称加密

44、为什么tcp要三次握手
TCP连接需要进行三次握手,是因为这样可以确保双方都能够正常通信。在第一次握手时,客户端向服务器发送一个连接请求报文,服务器收到请求后回复一个ACK确认报文;在第二次握手时,服务器向客户端发送一个确认报文,客户端收到后也回复一个ACK确认报文;在第三次握手时,客户端再次向服务器发送一个确认报文,服务器收到后也回复一个ACK确认报文。这样,双方都确认了对方的身份,并且建立了可靠的连接。
如果只进行两次握手,就可能会出现客户端发送请求后,服务器并未收到请求,但是客户端却认为连接已经建立,从而导致数据传输出现问题。因此,TCP连接需要进行三次握手,以确保连接的可靠性。
45、cookie
-
如何理解Cookie? 答:我理解的Cookie,就是服务器端用来区分访问用户的,一个用户发出HTTP请求, 服务端判断这个用户是不是第一次访问,如果是新用户,那么就得先登记, 然后把这个用户的一些信息用Key-Value键值对的形式保存起来, 通过HTTP响应让用户带回客户端,让用户保存着,下次访问时,捎带着把信息也带过来,一看是老熟人, 后台就不用登记直接处理业务了,方便而有效率。 2.Http中Cookie的HttpOnly和secure属性 1 secure属性 当设置为true时,表示创建的 Cookie 会被以安全的形式向服务器传输, 也就是只能在 HTTPS 连接中被浏览器传递到服务器端进行会话验证, 如果是 HTTP 连接则不会传递该信息,所以不会被窃取到Cookie 的具体内容。 2 HttpOnly属性 如果在Cookie中设置了"HttpOnly"属性,那么通过程序(JS脚本、 Applet等)将无法读取到Cookie信息,这样能有效的防止XSS攻击。 3.Cookie是什么? cookie时当前识别用户,实现持久化会话的最好方式。 简单点说就是服务器知道正在和哪个客户端通信,以及保持与已识别出的客户端通信。 Cookie的基本思想就是让浏览器积累一组服务器特有的信息,每次访问服务器时都将这些信息提供给它。 4.Cookie能做什么? 对连接另一端的用户有更多的了解,并且能在用户浏览页面时对其进行跟踪。 1 5.Cookie是怎么分类的? (1)会话cookie。临时cookie,记录了用户访问站点时的设置和偏好。用户退出浏览器时,会话cookie就被删除了。
(2)持久cookie。持久cookie的生存时间更长一些;它们存储在硬盘上, 浏览器退出,计算机重启时它们仍然存在。通常会用持久cookie维护某个用户会周期性访问的站点的配置文件或登录名。 唯一区别就是它们的过期时间。如果设置了Discard参数或没有设置Expires或没有设置Max-Age参数则说明这个cookie就是一个会话cookie。 6.Cookie的工作原理? (1)用户首次访问Web站点时,Web服务器对用户一无所知。
(2)Web服务器通过Set-Cookie首部将cookie存放到浏览器中的cookie数据库中。 cookie中包含了N个键值对,例如Cookie: id=“1234”。cookie中可以包含任意信息, 但它们通常都只包含一个服务器为了进行跟踪而产生的独特的识别码。
(3)将来用户再次访问同一站点时,浏览器会从cookie数据库中挑中那个服务器设置的cookie, 并在cookie请求首部中(Cookie: id=“1234”)将其传回给服务器。
(4)服务器可以通过id="1234"这个键值对来查找服务器为其访问积累的信息(购物历史、地址信息等)。
注意:cookie并不仅限与ID号。很多Web服务器都会将信息直接保存在cooki中。 比如Cookie: name=“Tom”; phone=“111-2222” 7.Cookie是怎么存储的 浏览器负责存储cookie信息。不同的浏览器会以不同的方式来存储cookie。 有的浏览器用cookis.txt存储。 有的浏览器存储在高速缓存目录下独立的文本文件中。 8.每次访问网站时,是不是将所有的cookie都发送所有的站点? 不是,浏览器通常只向每个站点发送2~3个cookie。原因如下:
(1)对所有这些cookie字节进行传输会严重降低性能。
(2)cookie中包含的时服务器特有的名值对,对大部分站点来说,大多数cookie都只是无法识别的无用数据。
(3)将所有的cookie发送给所有站点会引发潜在的隐私问题,那些你并不信任的站点也会获得你只想发给其他站点的信息。 9.cookie与缓存怎么取舍? cookie是私有的,浏览器不希望得到的cookie和其他浏览器的cookie相同。 一般缓存cookie图片而不缓存文本 10.cookie的缺点? 存在安全隐患。第三方Web站点使用持久cookie来跟踪用户就是对cookie一种最大的滥用。 将这种做法与IP地址和Referer首部信息结合在一起, 这些营销公司就可以构建起相当精确的用户档案和浏览模式信息。
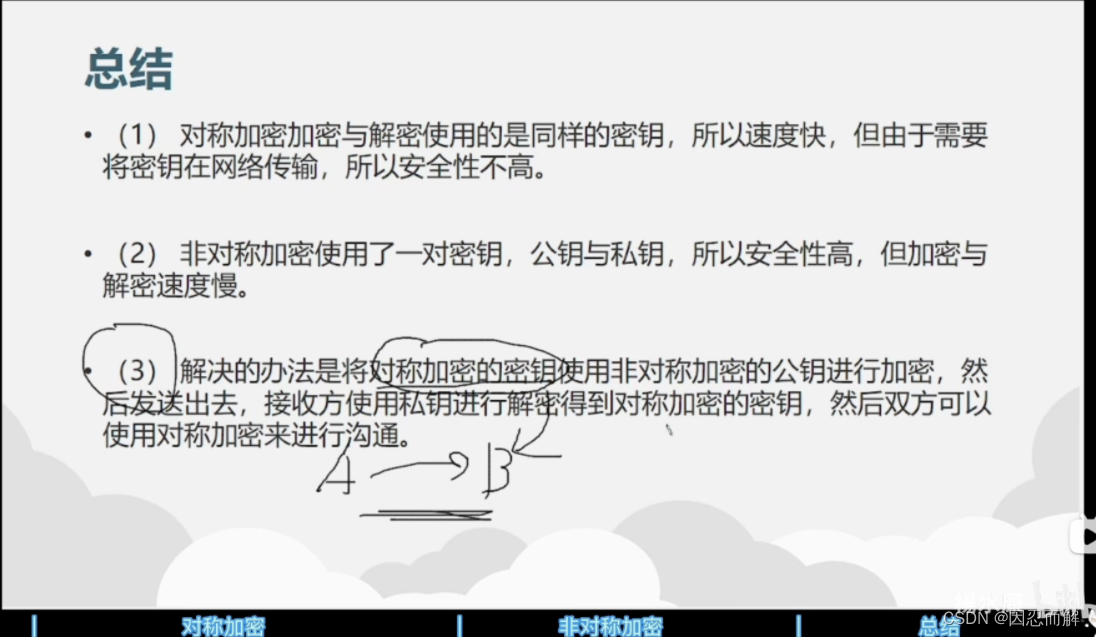
46、对称加密与非对称加密


47、babel
module.exports = {
"presets": [
"@vue/cli-plugin-babel/preset", ["@babel/preset-env", {
"useBuiltIns": "entry"
}]
],
"plugins": [
[
"component",
{
"libraryName": "element-ui",
"styleLibraryName": "theme-chalk"
}
]
]
}
babel-plugin-import
48、Worker
worker的使用 第一步判断浏览器是否支持worker,typeof (Worker) !== “undefined” 通过new Worker()构造方法创建一个worker线程,返回一个实例用于发送和接收数据 onmessage() 方法监听worker线程发送的数据
<!DOCTYPE html>
<html>
<body>
<p>点击Start Worker按钮启动web worker,可以看到web worker开始工作,且在web worker正常工作时,我们仍然可以在input输入框中输入信息,这表示页面并没有因为web
worker的运行而被阻塞:</p>
<p>计数: <output id="result"></output></p>
<button οnclick="startWorker()">Start Worker</button>
<button οnclick="stopWorker()">Stop Worker</button>
<input type="text" value="" />
<script>
var w;
function startWorker() {
//判断浏览器是否支持worker
if (typeof (Worker) !== "undefined") {
if (typeof (w) === "undefined") {
w = new Worker("./worker.js");
}
w.onmessage = function (event) {
document.getElementById("result").innerHTML = event.data;
};
} else {
document.getElementById("result").innerHTML = "Sorry, your browser does not support Web Workers...";
}
}
function stopWorker() {
w.terminate();
}
</script>
</body>
</html>
postMessage() 方法发送数据
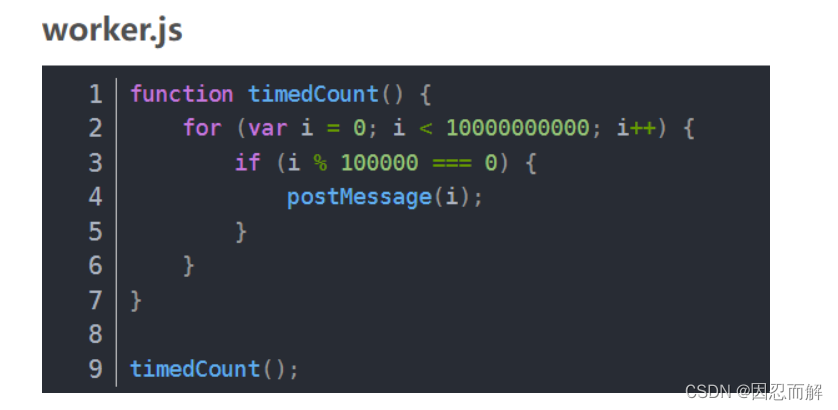
49、webpack热启动原理
通过webpack-dev-server创建两个服务器:提供静态资源的服务(express)和Socket服务
express server 负责直接提供静态资源的服务(打包后的资源直接被浏览器请求和解析)
socket server 是一个 websocket 的长连接,双方可以通信
当 socket server 监听到对应的模块发生变化时,会生成两个文件.json(manifest文件)和.js文件(update chunk)
通过长连接,socket server 可以直接将这两个文件主动发送给客户端(浏览器)
浏览器拿到两个新的文件后,通过HMR runtime机制,加载这两个文件,并且针对修改的模块进行更新
50、git
git cherry-pick 是 git 的一个命令,用于将特定提交的修改添加到当前分支中。使用方法为:
git cherry-pick <commit hash><commit hash> 是需要添加的提交的哈希值。
git cherry-pick 的一个常见用途是将其他分支的修改合并到当前分支中。例如,假设你有一个名为 feature 分支,它包含了一些修改,而你希望将这些修改合并到主分支中。此时,你可以在主分支上运行 git cherry-pick 命令,并将 feature 分支中需要合并的提交的哈希值作为参数。
51、mvc和mvvm的区别
1、MVC MVC是一种设计模式:
M(Model):模型层。是应用程序中用于处理应用程序数据逻辑的部分,模型对象负责在数据库中存取数据; V(View):视图层。是应用程序中处理数据显示的部分,视图是依据模型数据创建的; C(Controller):控制层。是应用程序中处理用户交互的部分,控制器接受用户的输入并调用模型和视图去完成用户的需求,控制器本身不输出任何东西和做任何处理。它只是接收请求并决定调用哪个模型构件去处理请求,然后再确定用哪个视图来显示返回的数据。
2、MVVM vue框架中MVVM的M就是后端的数据,V就是节点树,VM就是new出来的那个Vue({})对象
M(Model):模型层。就是业务逻辑相关的数据对象,通常从数据库映射而来,我们可以说是与数据库对应的model。 V(View):视图层。就是展现出来的用户界面。 VM(ViewModel):视图模型层。连接view和model的桥梁。因为,Model层中的数据往往是不能直接跟View中的控件一一对应上的,所以,需要再定义一个数据对象专门对应view上的控件。而ViewModel的职责就是把model对象封装成可以显示和接受输入的界面数据对象。 3、区别
View与ViewModel之间通过双向绑定建立联系,这样当View(视图层)变化时,会自动更新到ViewModel(视图模型),反之亦然。
MVVM与MVC的最大区别就是:它实现了View和Model的自动同步,也就是当Model的数据改变时,我们不用再自己手动操作Dom元素,来改变View的显示,而是改变数据后该数据对应View层显示会自动改变。MVVM并不是用VM完全取代了C,ViewModel存在目的在于抽离Controller中展示的业务逻辑,而不是替代Controller,其它视图操作业务等还是应该放在Controller中实现。
52、vite,如果有大量图片,会发生什么
如果有大量图片,Vite 在打包时可能会占用较多的内存和时间,导致构建速度减慢。因此,建议在开发时进行图片优化、压缩和懒加载等处理,以尽量减少图片的数量和大小。
53、js执行上下文和AO、VO

VO对象(Variable Object)
每一个执行上下文会关联一个VO (Variable object,变量对象),变量和函数声明会被添加到这个VO对象中。
每个执行环境都有一个变量对象,这个变量对象的属性绑定了在这个环境里定义的所有变量和函数,形参。VO理解为代码编译时产生。
VO绑定以下属性:
1.函数形参
2.函数申明
3.变量申明
在全局执行环境中,VO属性是可以被访问的,而进入函数执行环境后VO属性不能被直接访问,此时会生成活动对象AO替代VO,可以访问AO属性。
VO/AO产生的过程也是变量提升的过程,优先提升函数,然后是变量。
AO指的是Activation Object,是一个与执行环境相关联的变量对象,用于存储在函数执行过程中的变量和函数声明。
54、主线程和子线程
主线程是一个程序的入口点,负责执行程序的初始化操作和调度子线程的执行。子线程是由主线程创建的独立的执行流,可以并行执行程序中的不同任务。在操作系统中,主线程和子线程是通过线程调度程序进行管理和调度的。