InnoDB引擎聚簇索引
InnoDB聚簇索引
InnoDB聚簇索引实际上再同意结构中保存了B-Tree索引和数据行,实际上这里的B-Tree是一种B+Tree。关于B和B+Tree自行翻阅有关资料。
所谓的聚簇索引,就是指主键和数据行聚集在一起保存,提高了数据的密集性,但因为聚簇索引已经保存了数据行,所以一个表只能使用一个聚簇索引。
被索引的列就是主键,若没有选择主键,InnoDB会选择一个唯一的非空索引来替代。
优点:
1、相关数据可以保存在一起,例如用户邮件使用ID做聚簇索引,则经过少数几次的IO就可以拿到与该ID相关的邮件
2、效率高而且稳定
3、使用覆盖索引扫描查询可以直接使用叶节点中的主键值
缺点:
1、若数据全部存放在内存中,则访问顺序变得不太重要,聚簇索引的优势也不明显了
2、插入和更新不规则的数据可能会导致频繁的索引重构,也就是页分裂问题,这会导致插入或者更新时的性能下降
3、当数据不太密集或不连续的时候,反而会导致遍历速度下降
4、对二级索引的性能有一定的影响,因为二级索引中保存的不是数据行的实际地址,而是行的主键值,所以需要拿着主键值再进行一次查找,InnoDB自适应哈希索引能够降低该问题的影响
MyISAM与InnoDB储存数据时的索引对比
InnoDB:

pk:主键、rb pointer:回滚指针、tx id:事务id、npk:剩下的非主键列
实际上可以看出InnoDB聚簇索引基本上等同于实际储存数据的表
顺便一提,InnoDB的二级索引,也就是非聚簇索引,主要的区别就是在叶子节点的部分储存的是数据行的主键,而不是数据行的实际物理地址
MyISAM:
MyISAM将所有列分开建立索引,每一列都有一个独立的索引,数据行独立保存,每一个非聚簇索引的叶子节点都指向某一数据行的某一个单元,例如:
假设数据行的结构是这样的:
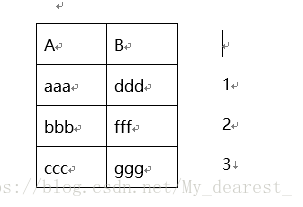
对列A的索引:

该索引与列B的索引组成了整张表的索引,主键索引与二级索引并没有什么不同