尽管 ChatGPT 仍然很受欢迎,但泄露的 Google 内部文件表明开源社区正在迎头赶上并取得重大突破。 我们现在能够在消费级 GPU 上运行大型 LLM 模型。
因此,如果你是一名开发人员,想要在本地环境中尝试这些 LLM 并用它构建一些应用程序,那么在本文中我将介绍一些可以帮助你的选项。

推荐:用 NSDT设计器 快速搭建可编程3D场景。
1、text-generation-webui
text-generation-webui是一个基于Gradio开发 Web UI, 可用于运行几乎所有可用的LLM。 它支持不同格式的LLM,例如GGML或GPTQ。
首先需要安装Ubuntu Server和CUDA。
- 安装 Ubuntu Server:搜索有关为你的特定硬件配置安装 Ubuntu Server 的详细指南。 请务必仔细按照说明进行操作,以确保安装过程顺利进行。
- 安装 CUDA:要在支持 GPU 的硬件上高效运行深度学习模型(例如 LLM),请从 NVIDIA 官方网站下载并安装 CUDA。 选择符合你的系统要求的教程并严格按照说明进行操作。
成功安装 Ubuntu Server 和 CUDA 后,下一步是设置 Oobabooga text-generate-webui 工具来管理你的自托管 LLM 模型。 为此,请按照以下说明操作:
- 访问 text- Generation-webui的 GitHub 仓库。
- 确保遵循 README.md 文件中的使用 Conda 指南进行手动安装来设置和配置 text-generate-webui 工具。
通过使用 Conda 的手动安装,你将可以灵活地修改源代码并对其进行定制以满足您的特定需求,确保与你的个人工作流程更好地集成。
现在,可以通过以下命令进行 Web UI,具体取决于你的硬件:
- 如果你没有 GPU 并且想在 CPU 上运行 GGML 版本 LLM,请使用以下命令。 根据CPU的能力调整线程数:
python server.py --chat --cpu --listen --thread 16
如果有 GPU,请运行以下命令来启动 UI
python server.py --chat --listen
使用这些命令之一启动服务器后,你可以使用 UI 下载模型并根据需要调整设置。
以下是我为令人印象深刻的 13 B Stable Vicuna 模型发现的设置的简要快照,该模型目前是最好的LLM之一:
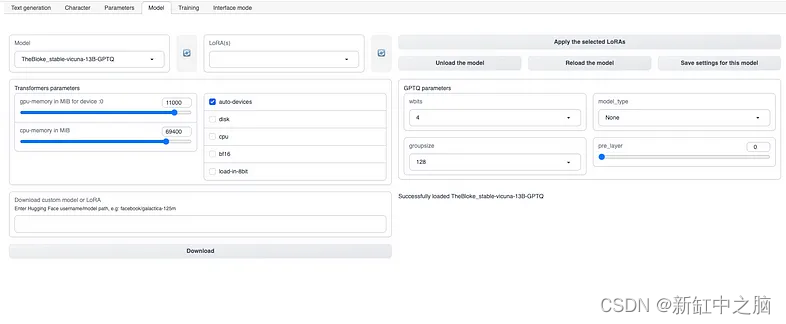
要下载 Vicuna 13B 模型,请在 Oobabooga text-generate-webui 工具中执行以下步骤:
- 导航到“模型”选项卡。
- 找到“下载自定义模型或 LoRA”输入框。
- 将 TheBloke/stable-vicuna-13B-GPTQ 复制并粘贴到输入框中。
- 单击“下载”按钮启动模型下载过程。
- 下载完成后,刷新模型选项卡。
- 从模型选择器中选择新下载的 Vicuna 13B 模型。
现在你已经设置了自托管LLM,是时候将其与你的工作流程集成了。 尽管 Oobabooga 的text-generation-webui 工具提供了一个漂亮的 Web UI,但拥有一个用于与其他应用程序无缝集成的 API 会更方便。 幸运的是,Oobabooga text-generation webui 工具包含一个内置的 API 扩展。 要启用 API,只需将 --api 标志添加到用于运行该工具的命令中即可。
要验证 API 是否正确运行,请打开浏览器并访问以下 URL,将 yourserveraddress 替换为服务器的实际地址:
http://yourserveraddress:5000/api/v1/model
如果 API 正常运行,你应该会看到确认当前使用的模型的响应。
2、llama.cpp
llama.cpp是一个基于 C/C++ 的库,专注于仅在 CPU 上运行 LLM 推理,但最近还添加了对 GPU 加速的支持。 它被设计为一个独立的库,因此如果你想构建一个与其集成的应用程序,可能必须构建自己的绑定或使用社区绑定库:
- Python: abetlen/llama-cpp-python
- Go: go-skynet/go-llama.cpp
- Node.js: hlhr202/llama-node
- Ruby: yoshoku/llama_cpp.rb
- C#/.NET: SciSharp/LLamaSharp
注意:对于 llama-cpp-python,如果你使用的是 Apple Silicon (M1) Mac,请确保已安装支持 arm64 架构的 Python 版本。 否则,安装时将构建 llama.ccp x86 版本,该版本在 Apple Silicon (M1) Mac 上速度会慢 10 倍。
3、GPTQ-for-LLaMA
如果您有一个不错的 GPU,VRAM 大于 8GB,你可以选择对 GPU 使用 GPTQ 量化,例如 GPTQ-for-LLaMa。
可以在此处查看 GPT-for-LLama 硬件要求的详细信息。
然而,GPTQ-for-LLaMa 仅提供了类似 CLI 的示例和有限的文档。 因此,我创建了一个示例仓库,它使用 GPTQ-for-LLaMa 实现并通过 HTTP API 提供生成的文本。
总之,无论是 Gradio Web UI、llama.cpp 还是 GPTQ-for-LLaMa,每个选项都满足本地运行 LLM 的不同硬件功能。 根据你的硬件资源进行选择。 潜入LLM的激动人心的世界,祝你愉快!