本文为CVPR 2023 VAND Workshop Challenge赛道一和赛道二分别获得第一和第四成绩的方案。
在计算机视觉领域,无监督异常检测(AD)旨在使用仅在无异常图像上训练的模型识别异常图像并定位异常区域, 广泛应用于工业缺陷检测。目前大多数方法都集中在为每个类别训练专用模型,这依赖大量正常图像集合作为参考。然而在实际应用中,需要检测的工业产品种类繁多,很难为每个类别收集大量的训练图像。因此,零样本/小样本设置在将AD带入实际应用中起着至关重要的作用。
对于工业视觉检测而言,在没有或只有少数正常参考图像的情况下,构建一个能够快速适应众多类别的单一模型是一个很有价值的研究方向。
在zero-shot任务中,所提解决方案在CLIP模型上加入额外的线形层,使图像特征映射到联合嵌入空间,从而使其能够与文本特征进行比较并生成异anomaly maps。
当有参考图像可用时(few-shot),所提解决方案利用多个memory banks存储参考图像特征,并在测试时与查询图像进行比较。
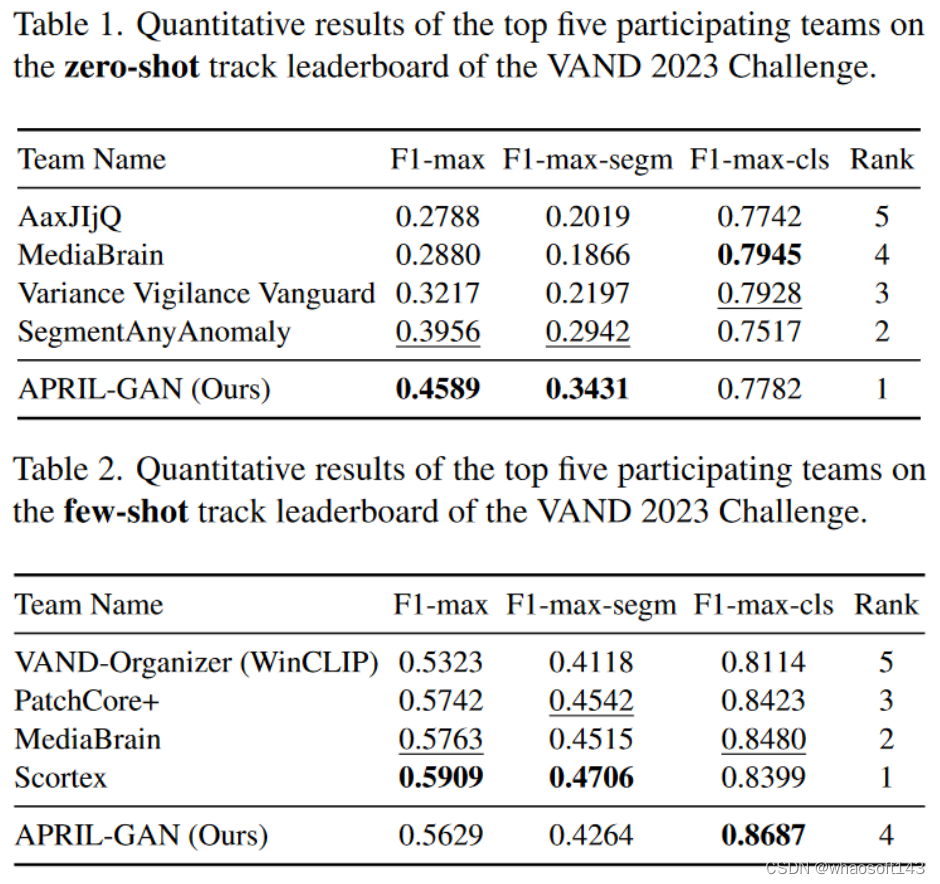
在ZS和FS两项挑战中,所提方案分别取得了第一和第四名的成绩。
具体来说,所提方案的几个要点是:
-
使用状态(state)和模板(template)的提示集成来制作文本提示。
-
为了定位异常区域,引入了额外的线性层,将从CLIP图像编码器提取的图像特征映射到文本特征所在的线性空间。
-
将映射的图像特征与文本特征进行相似度比较,从而得到相应的anomaly maps。
-
few-shot中,保留zero-shot阶段的额外线性层并保持它们的权重。此外,在测试阶段使用图像编码器提取参考图像的特征并保存到memory banks中,以便与测试图像的特征进行比较。
-
为了充分利用浅层和深层特征,同时利用了图像编码器不同stage的特征。
零样本异常检测设定
分类任务
state-level文本提示是使用通用的文本描述正常或异常的目标(比如flawless,damaged),而不会使用“chip around edge and corner”这种过于细节的描述;
所谓template-level文本提示,所提方案在CLIP中为ImageNet筛选了85个模板,并移除了“a photo of the weird [obj.]”等不适用于异常检测任务的模板。
 state-level和template-level的集成实现如下,最后的两组向量分别描述了正常/异常目标的文本提示。
state-level和template-level的集成实现如下,最后的两组向量分别描述了正常/异常目标的文本提示。
def encode\_text\_with\_prompt\_ensemble\(model, texts, device\):
prompt\_normal = \['\{\}', 'flawless \{\}', 'perfect \{\}', 'unblemished \{\}', '\{\} without flaw', '\{\} without defect', '\{\} without damage'\]
prompt\_abnormal = \['damaged \{\}', 'broken \{\}', '\{\} with flaw', '\{\} with defect', '\{\} with damage'\]
prompt\_state = \[prompt\_normal, prompt\_abnormal\]
prompt\_templates = \['a bad photo of a \{\}.',
'a low resolution photo of the \{\}.',
'a bad photo of the \{\}.',
'a cropped photo of the \{\}.',
'a bright photo of a \{\}.',
'a dark photo of the \{\}.',
'a photo of my \{\}.',
'a photo of the cool \{\}.',
'a close-up photo of a \{\}.',
'a black and white photo of the \{\}.',
'a bright photo of the \{\}.',
'a cropped photo of a \{\}.',
'a jpeg corrupted photo of a \{\}.',
'a blurry photo of the \{\}.',
'a photo of the \{\}.',
'a good photo of the \{\}.',
'a photo of one \{\}.',
'a close-up photo of the \{\}.',
'a photo of a \{\}.',
'a low resolution photo of a \{\}.',
'a photo of a large \{\}.',
'a blurry photo of a \{\}.',
'a jpeg corrupted photo of the \{\}.',
'a good photo of a \{\}.',
'a photo of the small \{\}.',
'a photo of the large \{\}.',
'a black and white photo of a \{\}.',
'a dark photo of a \{\}.',
'a photo of a cool \{\}.',
'a photo of a small \{\}.',
'there is a \{\} in the scene.',
'there is the \{\} in the scene.',
'this is a \{\} in the scene.',
'this is the \{\} in the scene.',
'this is one \{\} in the scene.'\]
text\_features = \[\]
for i in range\(len\(prompt\_state\)\):
prompted\_state = \[state.format\(texts\[0\]\) for state in prompt\_state\[i\]\]
prompted\_sentence = \[\]
for s in prompted\_state: # \[prompt\_normal, prompt\_abnormal\]
for template in prompt\_templates:
prompted\_sentence.append\(template.format\(s\)\)
prompted\_sentence = tokenize\(prompted\_sentence\).to\(device\)
class\_embeddings = model.encode\_text\(prompted\_sentence\)
class\_embeddings /= class\_embeddings.norm\(dim=\-1, keepdim=True\)
class\_embedding = class\_embeddings.mean\(dim=0\)
class\_embedding /= class\_embedding.norm\(\)
text\_features.append\(class\_embedding\)
text\_features = torch.stack\(text\_features, dim=1\).to\(device\).t\(\)
return text\_features

text\_probs = \(100.0 \* image\_features \@ text\_features.T\).softmax\(dim=\-1\)
results\['pr\_sp'\].append\(text\_probs\[0\]\[1\].cpu\(\).item\(\)\)
分割任务
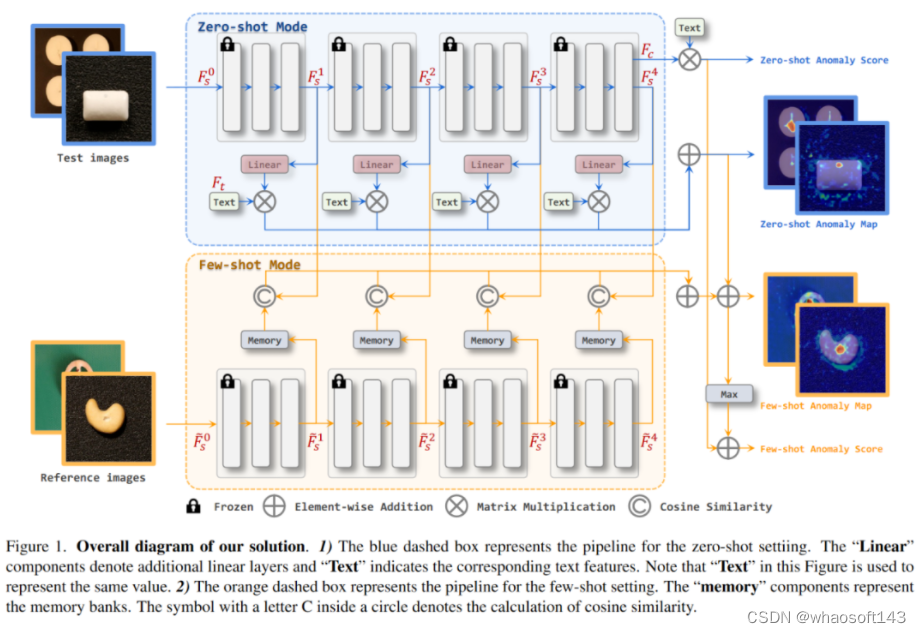 在zero-shot分割任务中,因为这个赛道允许使用外部数据,所以这里额外引入了linear layer去映射patch_tokens,然后基于每个patch_token去和文本特征做相似度计算,从而得到anomaly map。
在zero-shot分割任务中,因为这个赛道允许使用外部数据,所以这里额外引入了linear layer去映射patch_tokens,然后基于每个patch_token去和文本特征做相似度计算,从而得到anomaly map。
如上图中zero-shot Mode部分,这里将图像编码器拆分为n个stages,每个stage都分别计算了图像特征:

具体实现如下代码段:
patch\_tokens = linearlayer\(patch\_tokens\)
anomaly\_maps = \[\]
for layer in range\(len\(patch\_tokens\)\):
patch\_tokens\[layer\] /= patch\_tokens\[layer\].norm\(dim=\-1, keepdim=True\)
anomaly\_map = \(100.0 \* patch\_tokens\[layer\] \@ text\_features.T\)
B, L, C = anomaly\_map.shape
H = int\(np.sqrt\(L\)\)
anomaly\_map = F.interpolate\(anomaly\_map.permute\(0, 2, 1\).view\(B, 2, H, H\),
size=img\_size, mode='bilinear', align\_corners=True\)
anomaly\_map = torch.softmax\(anomaly\_map, dim=1\)\[:, 1, :, :\]
anomaly\_maps.append\(anomaly\_map.cpu\(\).numpy\(\)\)
anomaly\_map = np.sum\(anomaly\_maps, axis=0\)
Linear Layer的训练(CLIP部分的参数是冻结的)使用了focal loss和dice loss。
小样本异常检测设定
分类任务
对于few-shot设置,图像的异常预测来自两部分。第一部分与zero-shot设置相同。第二部分遵循许多AD方法中使用的常规方法,考虑anomaly map的最大值。所提方案将这两部分相加作为最终的异常得分。
分割任务
few-shot分割任务使用了memory bank,如图1中的黄色背景部分。
直白来说,就是查询样本和memory bank中的支持样本去做余弦相似度,再通过reshape得到anomaly map,最后再加到zero-shot得到的anomaly map上得到最后的分割预测。
另外在few-shot任务中没有再去fine-tune上文提到的linear layer,而是直接使用了zero-shot任务中训练好的权重。
实验
定性结果
 简单来说,在简单一些的图像中zero-shot和few-shot上效果差不多,但面对困难任务时,few-shot会改善一些。
简单来说,在简单一些的图像中zero-shot和few-shot上效果差不多,但面对困难任务时,few-shot会改善一些。
定量结果
 whaosoft aiot http://143ai.com
whaosoft aiot http://143ai.com