所谓的finetune,就是利用别人训练好的模型,进行少量修改,再输入自己的数据进行训练,对参数进行微调,从而达到事半功倍的效果。
基本的步骤如下:
1. 准备数据、计算均值
与上一篇文章的步骤相同
2.修改配置文件
把原模型的配置文件solver.prototxt和train_val.prototxt拷贝过来,并进行修改
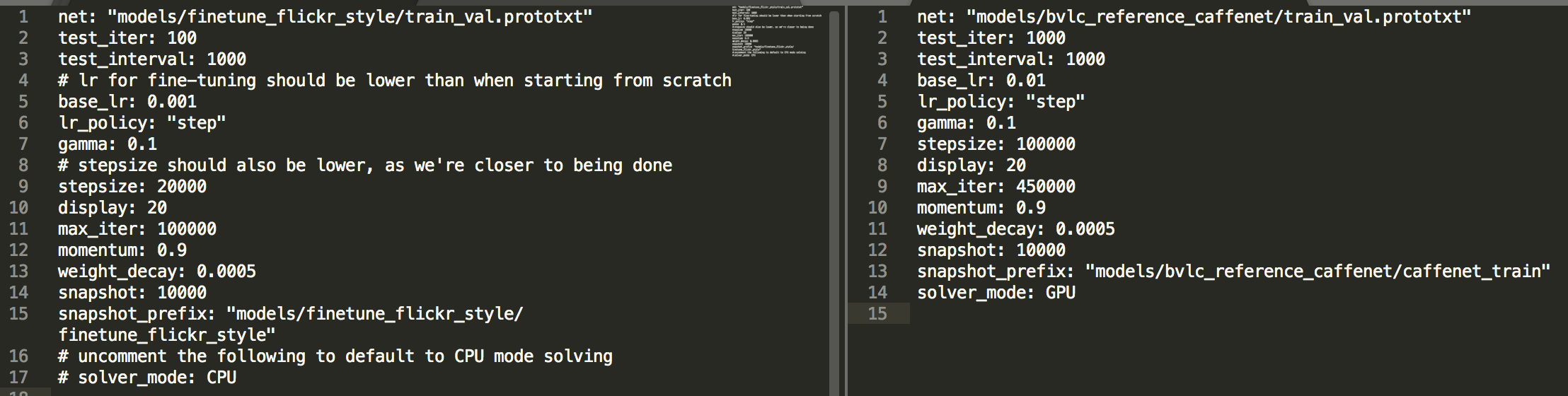
(1)solver.prototxt
原文件是用来训练的,而我们的目的是finetune,所以学习速率、步长、迭代次数都要进行适当的调整。具体可参考caffe自带的finetune的example(caffe/model/finetune_flickr_style,是在caffe/models/bvlc_reference_caffenet的caffenet的基础上进行训练的)。具体对比如下
(2)train_val.prototxt
网络的主体是一样的,主要修改有两部分:输入模块和输出模块
输入模块:修改mean_file和source等参数
输出模块:
把最后的全连接层的name改掉,让训练不加载原模型的参数。
把两个lr_mult和decay_mult增大10倍,因为该层的参数是重头开始训练,因此需要比其他参数的学习速率更快
把最后一个连接层的output参数修改为我们的数据集的类别数量
(3)开始训练
首先,把原模型的caffemodel文件下载好,放到本地文件夹,然后执行如下命令,进行finetune:
./build/tools/caffe train -solver path/to/your/file/solver.prototxt -weights path/to/your/caffemodel/XXX.caffemodel
至此,finetune训练完毕