1、决策树概述(Decision Tree,DT)
决策树的思想类似于20个问题的游戏,游戏规则很简单:参与游戏的一方在脑子里想某个事物,其他参与者向他提问,问题的答案只用对错来回答。问问题的人通过推断分析,不断缩小待猜测事务的范围。决策树的重要任务就是从数据中提取出一系列规则,用于对新输入的数据进行分类。
2、决策树原理
如图所示,是在挑选时,依据不同的特征来判断西瓜好坏的一棵决策树:
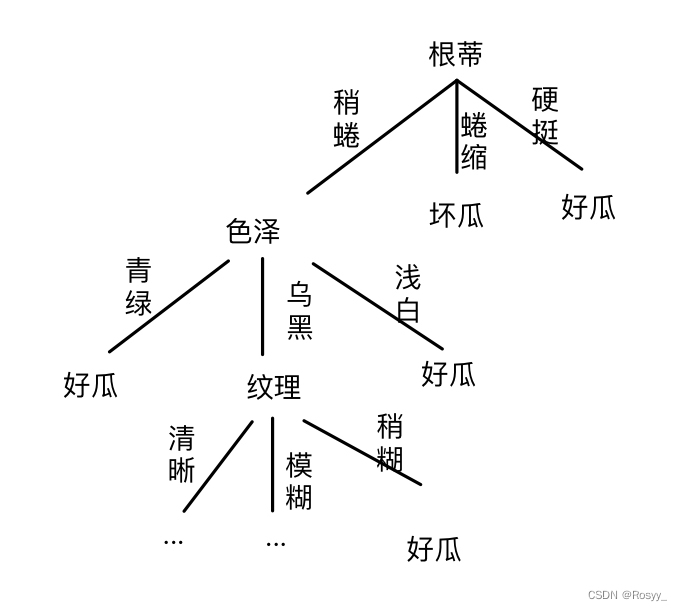
其中的每个分支结点都是我们对某个特征的判定,我们将选中的特征称作(最优)划分特征,判定的结果或者导出问题的结果,或者导出进一步的问题判定。
我们希望从已知数据中找到一组最优划分特征(也就是确定决策树的每个结点),构造出一棵决策树,从而对于一个新输入的数据,来判断它的类别。那么如何找最优划分特征呢?
3、决策树的构造
- 首先,要明白:
构造决策树的关键在于:选取特征,划分数据。
划分数据的原则是:将无序的数据变得有序。
方法是:基于某些指标,测试当前可选择的所有特征,选取最优划分特征,使数据尽量变得有序。 - 因此在构造决策树时,要解决的第一个问题就是,当前数据集上哪个特征在划分数据分类时起决定性作用。 为了找到决定性的特征,划分出最好的结果,我们必须评估每个特征。
- 将特征作为结点,数据集将会根据该决策点分布到不同分支里面去。
如果每个分支的数据属于同一类型,则数据将无需再进行进一步的划分。
如果数据子集中数据不属于同一个类型,则需要反复划分数据自己的过程。直到所有相同类型的数据均在一个数据子集中。
决策树的构造关键在于每个划分特征的选取,常用算法有:ID3算法、C4.5算法、CART算法。
(其中,CART算法包含CART生成和CART剪枝,ID3、C4.5均只包含决策树生成,其剪枝将在后文介绍。)
3.1 ID3算法
该算法的核心思想是:信息增益最大化。信息增益是什么?为什么最大化?
-
熵:度量样本集合纯度的指标。其值越小,表明数据的纯度越高。
-
信息增益:划分数据集之前之后信息纯度发生的变化。
计算方式:划分前的熵(大)-划分后的熵(小)=熵的减少=无序度的减小=纯度的提高。
其值越大,表示数据纯度提升越大,所以要最大化。
据此,我们从根节点处开始,计算每个特征在结点处进行划分前后的熵,进而得到信息增益,选取信息增益最大的那个特征作为该结点的划分特征,构造出决策树。
小结:
(1)ID3算法的核心思想就是:依据信息增益来生成决策树。
(2)缺点:生成的树容易过拟合。(因为我们在每个结点采用信息增益最大化来选择划分特征,也就一味的追求了生成的树在训练数据集上分类的准确度,从而造成了过拟合。)
3.2 C4.5算法
C4.5算法与ID3算法相比进行了改进,采用信息增益比来选择特征。信息增益比是什么?
- 信息增益比:某特征的信息增益与该特征各个取值所对应的熵的比值。(不用过度纠结概念)
目的:ID3算法之所以容易过拟合的原因是它偏向于选择取值较多的特征,举个栗子:特征1(色泽)有3种取值:青绿、乌黑、浅白;特征2(触感)有2种取值:软黏、硬滑。ID3算法会倾向于先选择特征1(色泽),这是因为如果数据中还存在取值多的特征未划分,那么数据无序度偏高,划分前后纯度提高幅度较大。所以,C4.5就对这一问题进行了矫正,缓解过拟合。
小结:
(1)C4.5算法的核心思想是:最大化信息增益比。但这里不是简单的最大化,因为最大化信息增益比又会导致偏向于选择取值较少的属性,所以这里用到一个启发式:先从候选划分特征中找出信息增益高于平均水平的特征,再从中选择信息增益比最高的特征。
(2)特点:缓解了ID3算法的过拟合问题。
3.3 CART算法
CART(Classification and Regression Tree)算法也叫分类回归树算法,既可以用于回归,也可以用于分类。CART算法的思想包括CART生成、CART剪枝两个步骤。
3.3.1 CART生成
生成回归树的核心思想是:平方误差最小化准则。
非直观的理解,就是每一步划分都遵从:sum(y-f(x))^2最小。
生成分类树的核心思想是:最小化基尼指数。基尼指数是什么?为什么最小化?
- 基尼指数:表示数据集合的不确定性(混乱程度)。
值越大,表示数据不确定性就越大,越混乱,纯度越低。
据此,我们计算每个特征进行划分后,各子集的基尼指数的加权和,得到划分后的基尼指数。其值越小,表示划分后的集合不确定性越低,纯度越高。所以选择那个使得划分后基尼指数最小的特征作为最优划分特征。
3.3.2 CART剪枝
CART剪枝算法从“完全生长”的决策树的底端剪去一些子树,使决策树变小(模型变简单),从而能够对未知数据有更加准确地预测。
CART剪枝算法由两部分组成:
1.首先从数的底端开始不断剪枝,直到树的根结点,形成一个子树序列;
2.然后通过交叉验证法在独立的验证数据集上对子树序列进行测试,从中选择最优子树。
4、决策树的剪枝
剪枝(puring)是决策树对付过拟合的主要手段,通过主动剪掉一些分支来降低过拟合的风险。
剪枝分为“预剪枝”(prepuring)和“后剪枝”(postpuring)。
4.1 预剪枝
在决策树生成过程中,对每个结点在划分前进行估计,若当前结点的划分不能带来决策树泛化能力的提升,那就停止划分并将该结点标记为叶结点。(泛化能力指模型在测试数据集上的预测能力)
- 好处:预剪枝使很多分支没有展开,不仅降低了过拟合风险,还减少了训练和测试时间开销。
- 坏处:但另一方面,有些分支的当前划分可能不会提升泛化能力,但其后续的划分可能会使泛化能力显著提升;基于“贪心”策略的预剪枝决策树可能会出现欠拟合的问题。
4.2 后剪枝
先从训练集生成一棵完整的决策树,然后自底向上地对非叶结点进行考查,若将该结点对应的子树替换成叶结点能提升决策树的泛化能力,则将该子树替换成叶结点。
- 好处:后剪枝通常比预剪枝保留更多的分支,欠拟合的风险较小,泛化能力较好。
- 坏处:后剪枝是在决策树生成之后进行的,要自底向上对每一个分支结点进行考查,训练时间较长。