承蒙各位抬爱,鄙人的一篇关于Spring Batch的博客《Spring Batch之进阶》有很多人浏览。说明有很多人工作中用到这个spring batch框架进行批量任务处理,也说明对这个框架还有不少不熟悉的地方,鄙人也是。That is to say,我们有必要加强学习,不然三天不学习,赶不上×××。这里就来继续说说Spring Batch Scaling and Parallel Processing那些事。这个标题的确不小,可伸缩和并行处理,的确是批量处理的很重要的特性,只有很好解决这些问题,才能成为一个完整的批量处理框架。本人GIT了一个项目:https://github.com/stylelyl/webatch.git,里面做了几个模式的实践,可以作为一个很好的理解,实际动手跑一跑。
Spring Batch的官方说明文档:https://docs.spring.io/spring-batch/trunk/reference/html/scalability.html
Multi-threaded Step (single process)
Parallel Steps (single process)
Remote Chunking of Step (multi process)
Partitioning a Step (single or multi process)
一般来说,这四种是很重要的可伸缩和并行处理方式。我们可以:1,多线程(单进程) 2,并行步骤(单进程) 3,远程步骤分块(多进程) 4,分区步骤(单/多进程)。他们的优点自然不用多说,单进程处理的时候一个线程不能充分利用,那就启动多个线程或者并行任务来处理,当然处理的任务之间是分隔的,结果直接不能有调用或者依赖关系(不要和我说到MR之类的处理,那是另外一回事)。还不够,使用多进程来处理,即将任务分配到多个进程/节点上面来并行处理,或者将数据分区/片,综合几种方式来处理。下面按照这几种方式来分别说下怎么实践。
1,Multi-threaded Step
这个文档上面说的很清楚,做起来也很简单,在step定义的时候指定task-executor,默认使用的是SimpleAsyncTaskExecutor。如果每个线程都要读数据库,当然这个limit不要超过数据库连接数。
<step id="loading">
<tasklet task-executor="taskExecutor" throttle-limit="20">...</tasklet>
</step>2,Parallel Steps
这个可以按照文档上面的配置:
<job id="job1">
<split id="split1" task-executor="taskExecutor" next="step4">
<flow>
<step id="step1" parent="s1" next="step2"/>
<step id="step2" parent="s2"/>
</flow>
<flow>
<step id="step3" parent="s3"/>
</flow>
</split>
<step id="step4" parent="s4"/>
</job>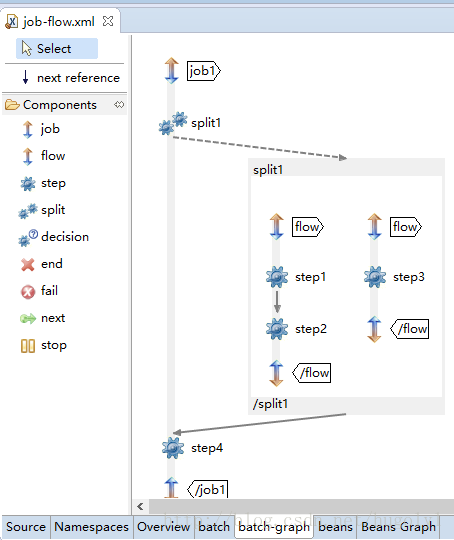
使用STS的插件,来图形化的看看处理的流程图是什么样的。这样看起来就是一目了然了。我们一般把可以同时并行跑的步骤分别通过split来并行来跑。
3,Remote Chunking
上面的文章里面贴了Remote Chunking模式的处理流程。一般通过Master Step来获取要处理的数据,然后把要处理的数据通过中间件分配给远程的多个Slave进程,Master来跟踪任务,根据最终处理的结果来决定步骤是不是处理完成了。如文档所说,The middleware has to be durable, with guaranteed delivery and single consumer for each message. JMS is the obvious candidate, but other options exist in the grid computing and shared memory product space (e.g. Java Spaces).
4,Partitioning
这个说白了就是通过PartitionStep来进行的,执行的时候,有两个策略需要制定,PartitionHandler and StepExecutionSplitter,即怎么进行分区处理和每个步骤里面该怎么跟踪处理结果。这种处理方式和3的不同在于,分区的结果给slave的时候不需要持久化,在batch_step_execution和batch_step_execution_context里面会保存meta-data ,这样来确保每个slave只运行一次。
上面所说的,可以通过代码https://github.com/stylelyl/webatch.git来实践下。
具体的项目怎么跑起来,不多说,说说里面的几个关键的类:
CardInfoPagingItemReader:这个类使用了DAO的方式来查询,然后使用com.github.pagehelper来分页。
KeyListReader:首先读取所有的keys,loadKeys() 然后一条条记录处理,loadItem(KEY key)
* 通过keyIterator来遍历所有的keys