机器学习是人工智能领域的重要分支,它通过利用数据和统计方法让机器从经验中学习,提高其在特定任务上的性能。在机器学习中,选择适当的算法对问题进行建模是至关重要的一步。本文将介绍常见的机器学习算法以及它们适用的应用领域,帮助读者了解各种算法的特点和优势。
一、线性回归(Linear Regression)
线性回归是最简单和最常见的机器学习算法之一,适用于预测连续值的回归问题。它建立了输入特征与输出值之间的线性关系模型。线性回归常被用于房价预测、销量预测等问题。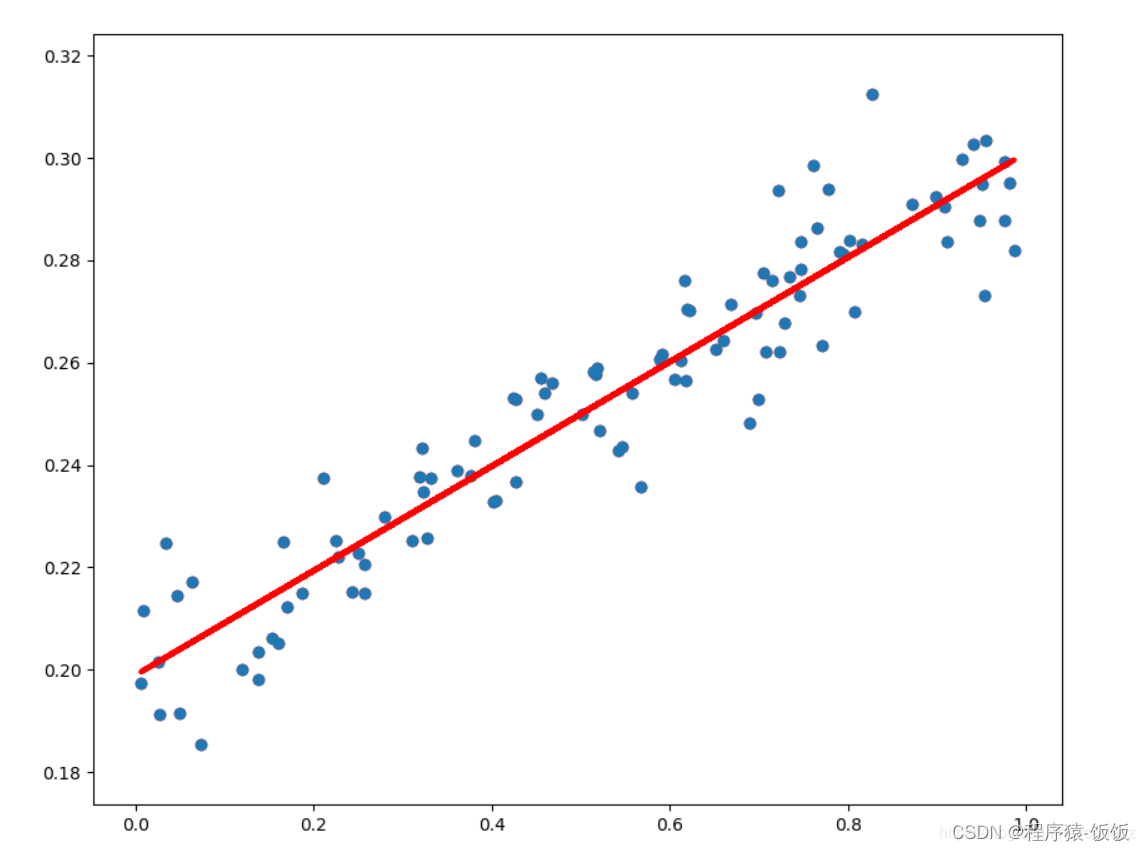
二、逻辑回归(Logistic Regression)
逻辑回归是一种分类算法,适用于二分类或多分类问题。它通过逻辑函数建立分类模型,并输出样本属于某一类别的概率。逻辑回归广泛应用于垃圾邮件过滤、客户流失预测等领域。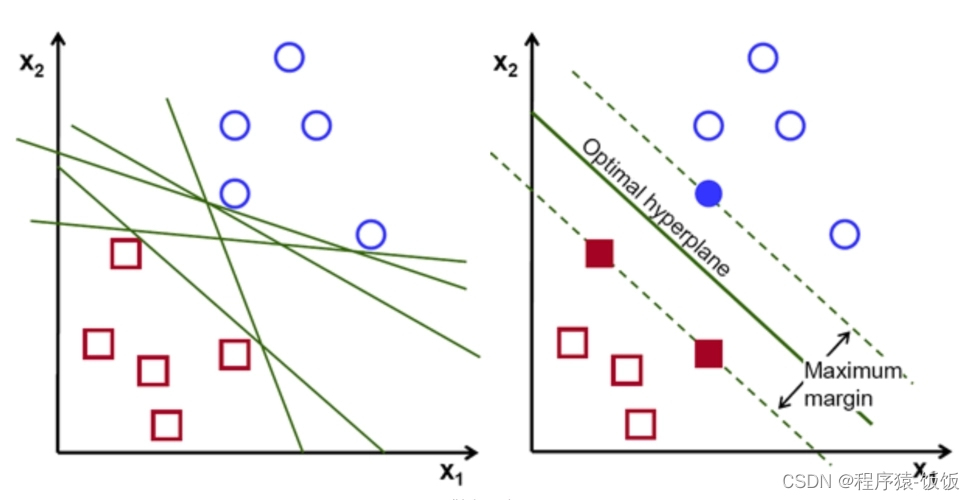
三、决策树(Decision Tree)
决策树是一种基于树结构的分类和回归算法。它通过从数据中学习简单的决策规则来进行预测。决策树易于理解和解释,常被用于金融风险评估、医学诊断等问题。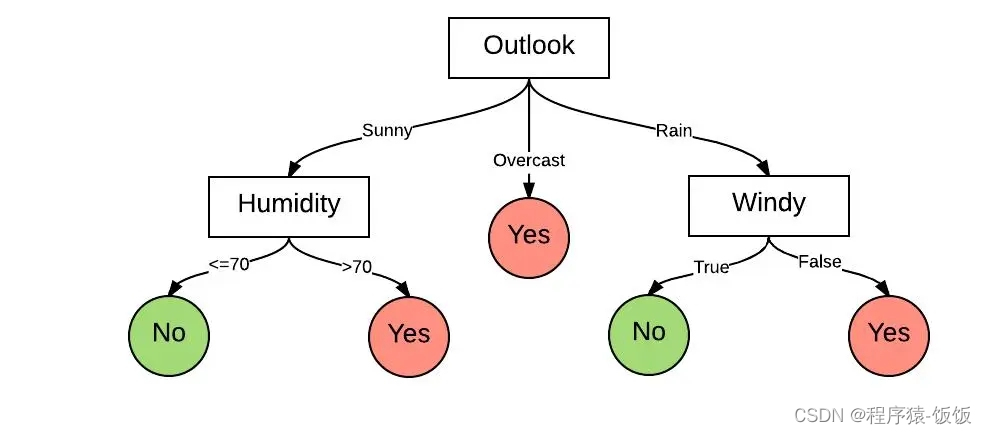
四、支持向量机(Support Vector Machine,SVM)
支持向量机是一种强大的分类算法,可以处理线性和非线性分类问题。它通过在特征空间中构建一个最优超平面来进行分类。支持向量机在文本分类、图像识别等领域有广泛应用。
五、朴素贝叶斯(Naive Bayes)
朴素贝叶斯是一种基于贝叶斯定理的分类算法,假设特征之间是相互独立的。它被广泛应用于文本分类、垃圾邮件过滤等问题。

六、K近邻算法(K-Nearest Neighbors,KNN)
K近邻算法是一种基于实例的学习方法,根据与其最接近的训练样本进行预测。K近邻算法适用于分类和回归问题,常被用于图像识别、推荐系统等领域。
七、神经网络(Neural Networks)
神经网络是一种模拟人脑神经系统的计算模型,可以用于解决复杂的模式识别和预测问题。它具有强大的表达能力,广泛应用于图像识别、语音识别、自然语言处理等领域。
总结: 本文介绍了常见的机器学习算法及其应用领域。线性回归和逻辑回归适用于预测和分类问题,决策树和支持向量机可以处理复杂的分类和回归问题,朴素贝叶斯适用于文本分类等领域,K近邻算法可用于近邻搜索和推荐系统,神经网络是解决复杂模式识别和预测问题的强大工具。选择适当的机器学习算法取决于问题的特性和数据的特点,深入理解各个算法的原理和应用场景,将帮助我们更好地应用机器学习解决实际问题。
需要机器学习相关z料可以关注威❤公众H【Ai技术星球】回复(123)领
还有500G人工智能学习资料包(有图像处理opencv\自然语言处理、机器学习、数学基础等人工智能资料,
深度学习神经网络+CV计算机视觉学习(两大框架pytorch/tensorflow+源码课件笔记)



代码示例:
# 导入相关库
from sklearn.linear_model import LinearRegression
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
# 加载数据集
boston = load_boston()
X = boston.data
y = boston.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建线性回归模型
model = LinearRegression()
# 拟合模型
model.fit(X_train, y_train)
# 预测测试集
y_pred = model.predict(X_test)
# 打印预测结果
print(y_pred)
