模型融合和预测结果融合
文章目录
1. 模型融合提升技术
- 模型融合,即先产生一组个体学习器,再用某种策略将它们结合起来,以加强模型效果。
- 为什么要进行模型融合呢?分析表明,随着集成中个体分类器数目 T 的增加,集成学习器的错误率将呈指数级下降,最终趋于0。通过融合可以达到“取长补短”的效果,综合个体学习器的优势能降低预测误差、优化整体模型性能。而且,
个体学习器的准确性越高、多样性越大,模型融合的提升效果就越好。 - 按照个体学习器的关系,模型融合技术可以分为两类:
- 个体学习器间
不存在强依赖关系可同时生成的并行化方法,代表是Bagging 方法和随机森林。 - 个体学习器间
存在强依赖关系必须串行生成的序列化方法,代表是Boosting 方法。
- 个体学习器间
1. Bagging 方法和随机森林
- Bagging 方法是从训练集中
抽样得到每个基模型所需要的子训练集,然后对所有基模型预测的结果继续综合,产生最终的预测结果,如下图所示:
 * Bagging 方法采用的是自助采样法(Bootstrap sampling),即对于 m 个样本的原始训练集,每次先
* Bagging 方法采用的是自助采样法(Bootstrap sampling),即对于 m 个样本的原始训练集,每次先随机采集一个样本放入采样集,接着把该样本放回,也就是说下次采样时该样本仍有可能被采集到,这样采集 m 次,最终可以得到 m 个样本的采样集。由于是随机采样,因此每次的采样集和原始的训练集不同,和其他采样集也不同,这样就可以得到多个不同的弱学习器。(注意,原始数据集 m 个样本,采集的新数据集也是 m 个样本)
*随机森林是对 Bagging 方法的改进,其改进之处有两点:基本学习器限定为决策树;除了在 Bagging 的样本上加扰动,在属性上也加上扰动,相当于在决策树学习的过程中引入了随机属性选择。对基决策树的每个节点,先从该结点的属性集合中随机选择一个包含 k 个属性的子集,然后从这个子集中选择一个最优属性用于划分。
2. Boosting 方法
- Boosting 方法的训练过程为阶梯状,即基模型按照次序一一进行训练(实现上可以做到并行),基模型的训练集按照某种策略每次进行一定的转换,然后对所有基模型的预测结果进行线性综合,产生最终的预测结果,如下图所示:
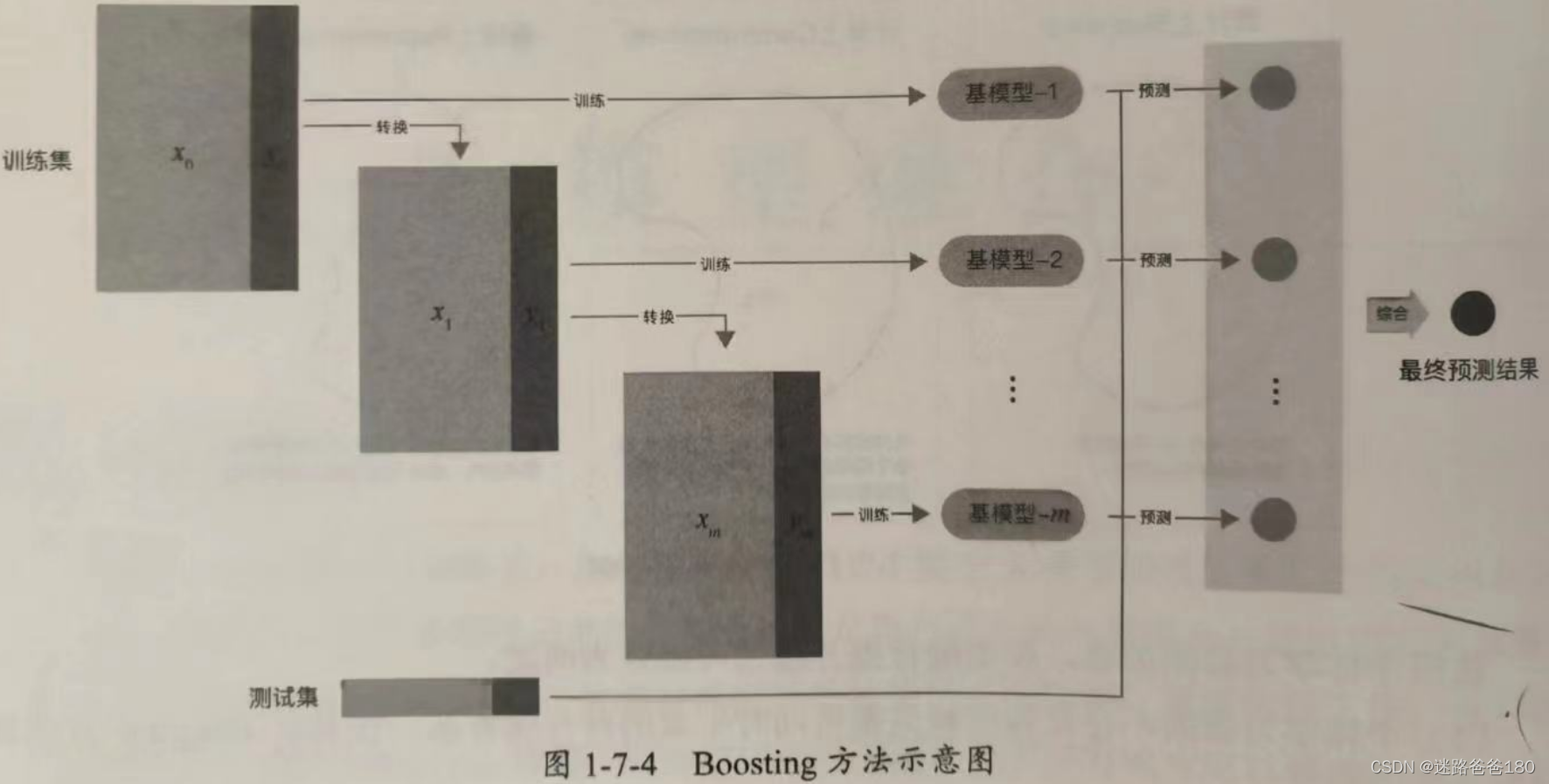
- Boosting 方法中著名的算法有 AdaBoost 算法和提升数(Boosting Tree)系列算法。在提升树系列算法中,应用最广泛的是梯度提升树(Gradient Boosting Tree),下面逐一简要介绍。
- AdaBoost 算法:是加法模型、损失函数为指数函数、学习算法为前向分布算法时的二分类算法。
- 提升树:是加法模型、学习算法为前向分布算法时的算法,基本学习器限定为决策树。对于二分类问题,损失函数为指数函数,就是把 AdaBoost 算法中的基本学习器限定为二叉决策树;对于回归问题,损失函数为平方误差,此时拟合的时当前模型的残差。
- 梯度提升树:是对提升树算法的改进。提升树算法只适合于误差函数为指数函数和平方误差,而对于一般的损失误差,梯度提升数算法可以将损失函数的负梯度在当前模型的值作为残差的近似值。
2. 预测结果融合策略
1. Voting
- Voting(投票机制)分为软投票和硬投票两种,其原理采用少数服从多数的思想,此方法可用于解决分类问题。
- 硬投票:对多个模型直接进行投票,最终投票数最多的类为最终被预测的类。
- 软投票:和硬投票原理相同,其增加了设置权重的功能,可以为不同的模型设置不同的权重,进而区别模型不同的重要程度。
2. 软投票代码示例:
3. Averaging 和 Ranking
- Averaging 的原理是将模型结果的平均值作为最终的预测值,也可以使用加权平均的方法。但其也存在问题:如果不同回归方法预测结果的波动幅度相差比较大,那么波动小的回归结果在融合时起的作用就比较小。
- Ranking 的思想和 Averaging 的一致。因为上述平均法存在一定的问题,所以这里采用了把排名平均的方法。如果有权重,则求出 n 个模型权重比排名之和,即为最后的结果。
4. Blending
- Blending 是把原始的训练集先分成两部分,如70%的数据作为新的训练集,剩下的30%的数据作为测试集。
- 在第一层中,我们用70%的数据训练多个模型,然后去预测剩余30%数据的 label 。在第二层中,直接用30%的数据在第一层的结果作为新特则会给你继续训练即可。
- Blending 的优点:Blending 比 Stacking 简单(不用进行 k 次交叉验证来获得 stacker feature),避开了一些信息泄露问题,因为 generlizers 和 stacker 使用了不一样的数据集。
- Blending 的缺点:
- 使用了很少的数据(第二阶段的 blender 只是用了训练集10%的数据量)。
- blender 可能会过拟合。
说明:对于实践中的结果而言,Stacking 和 Blending 的效果差不多。
5. Stacking
- Stacking 的基本原理是用训练好的所有基模型对训练集进行预测,
将第 j 个基模型对第 i 个训练样本的预测值作为新的训练集中第 i 个样本的第 j 个特征值,最后基于新的训练集进行训练。同理,预测的过程也要先经过所有基模型的预测形成新的测试集,最后对测试集进行预测,如下图所示:
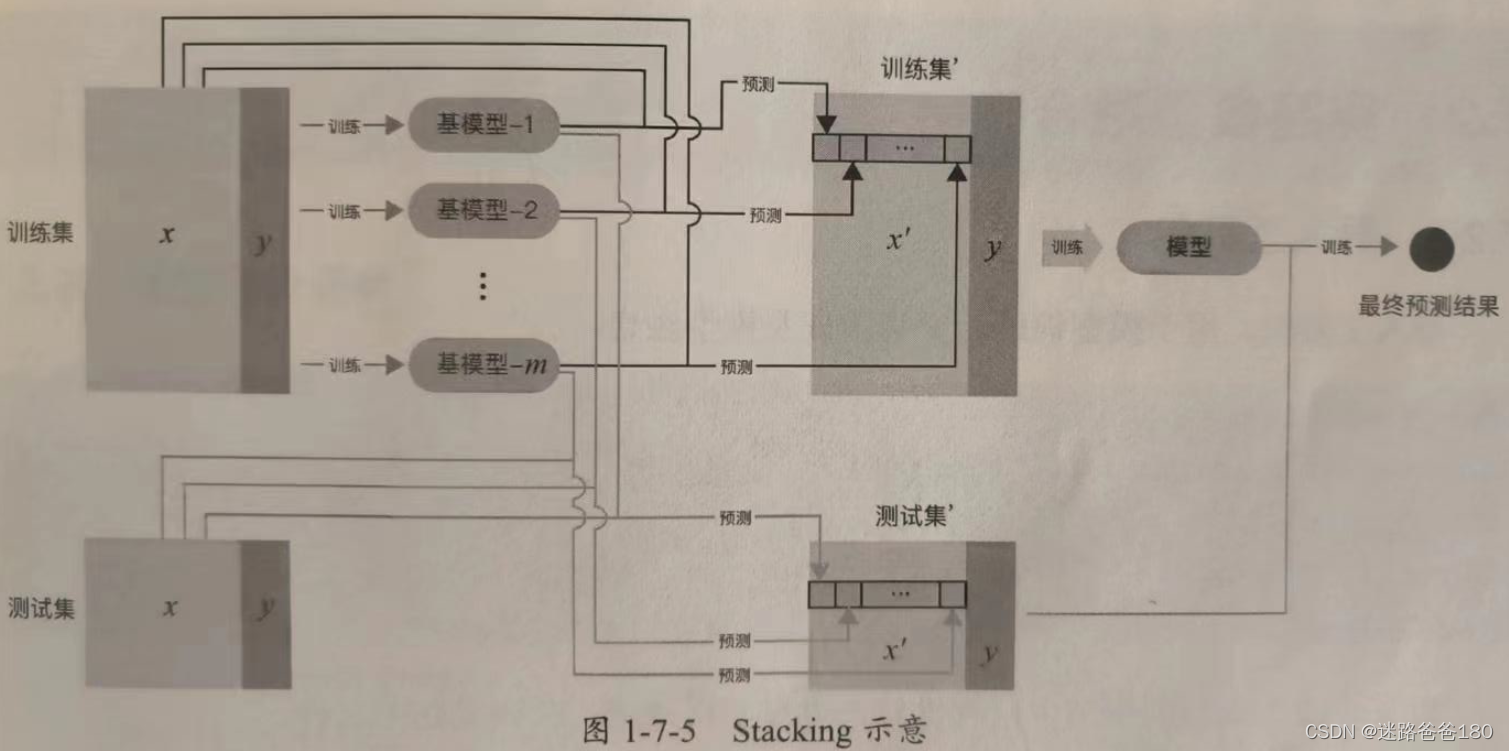
- Stacking 是一种分层模型集成框架。以两层为例:第一层由多个基学习器组成,其输入为原始的训练集;第二层的模型则是以第一层学习器的输出作为训练集进行训练,从而得到完整的 Stacking 模型。Stacking 两层模型都使用了全部的训练集数据。
- 下面举例进一步说明:
- 有训练集和测试集两组数据,并将训练集分成5份:train1, train2, train3, train4, train5。
- 选定基模型。这里假定我们选择了 xgboost,lightgbm,randomforest 作为基模型。比如 xgboost 模型部分,依次用 train1, train2, train3, train4, train5 作为验证集,其余4份作为训练集,然后5折交叉验证进行模型训练,再在测试集上进行预测。这样会在得到在练集上由 xgboost 模型训练出来的5份 predictions 和测试集上的1份预测值 B1,然后将5份 predictions 纵向重叠合并起来得到 A1。lightgbm 和 randomforest 模型部分同理,如下图所示:
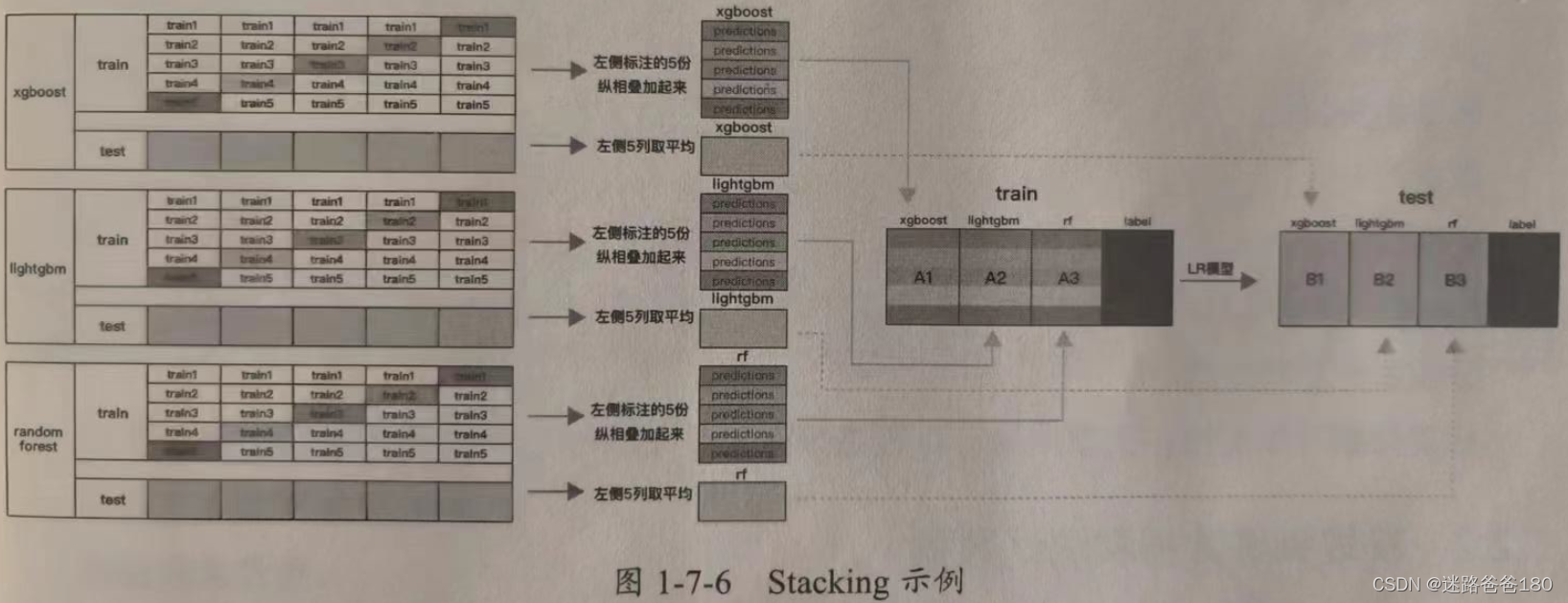
- 在三个基模型训练完毕后,将三个模型在训练集上的预测值分别作为3个“特征” A1,A2,A3,然后使用 LR 模型进行训练并建立了 LR 模型。
- 使用训练好的 LR 模型,在三个基模型的测试集上预测得到“特征”值(B1,B2,B3)的基础上进行预测,得出最终的预测类别或概率。
说明:在做 stacking 的过程中,如果将第一层模型的预测值和原始特征合并加入第二层模型的训练中,则可以使模型的效果更好,还可以防止模型的过拟合。
3. 其他提升方法
- 通过对权重或者特征重要性的分析,可以准确找到重要的数据和字段及相关的特征方向,并可以朝着此方向继续细化,同时寻找这个方向更多的数据,还可以做相关的特征组合,这些都可以提高模型的性能。
- 通过 Bad-Case 分析,可以有效找到预测不准确的样本点,进而回溯分析数据,寻找相关的原因,从而找到提升模型精度的方法。