目录
三、ClickHouse的表引擎介绍(ClickHouse的存储引擎)
5.1.1 采用Distribute表引擎多写的方式实现复制(1)
5.1.2 采用Distribute表引擎多写的方式实现复制(2)配置示例
5.1.3 采用Distribute表引擎多写的方式实现复制(3)-在分发表(Distribute)上读取数据的过程
5.1.4 采用Distribute表引擎多写的方式实现复制(4)-在分发表(Distribute)上写入数据的过程
5.2.1 采用复制表配合ZooKeeper的方式实现复制(1)
5.2.2 采用复制表配合ZooKeeper的方式实现复制(2) – 配置集群拓扑结构
5.2.3 采用复制表配合ZooKeeper的方式实现复制(3)-建立Local表的ReplicateMergeTree和Distribute表
5.2.4 采用复制表配合ZooKeeper的方式实现复制(4) –在分发表(Distribute)上读取数据的过程
5.2.5 采用复制表配合ZooKeeper的方式实现复制(5) –在分发表(Distribute)上写入数据的过程
一、ClickHouse是什么?
ClickHouse是一个面向列存储的开源的DBMS系统,能够使用SQL语句实时生成数据分析报告。主要面向AP应用。Clickhouse是俄罗斯Yandex公司的作品,与2016年5月开源,采用C++语言编写。Yandes号称俄罗斯的“百度”,是一家“大”公司。
适用场景:
- 绝大多数请求都是读访问。
- 数据以相当大的批量(大于1000行)写入,而不是以单行更新;或者根本没有更新操作。
- 数据会添加到数据库中,但不会被修改
- 读取多行少列
- 宽表,具有很多列
- 查询相对较少(通常每台服务器每秒查询数百次或更少)
- 单个查询高吞吐量(每台服务器每秒多达数十亿行)
- 对于简单的查询,允许大约50毫秒的延迟
- 列值相当小:数字和短字符串(例如,每个URL 60字节)
- 不需要事务
- 对数据一致性的要求较低。
- 每个查询有一个大表,其他都是小表
- 查询结果明显小于源数据;换句话说,数据被过滤或聚合,因此结果适合单个服务器的RAM。
缺点:
- 没有完整的事物支持。
- 不支持二级索引
- 缺少高频率,低延迟的修改或删除已存在数据的能力。仅能用于批量删除或修改数据。
- 稀疏索引使得ClickHouse不适合通过其键检索单行的点查询。
二、ClickHouse为什么快
1.IO层面
相对与行式存储,列式存储在查询时只会涉及到读取涉及到的列,显然这回大大减少查询时候的IO次数\开销。当然,采用列式存储后在进行数据记录写入的时候会麻烦一些。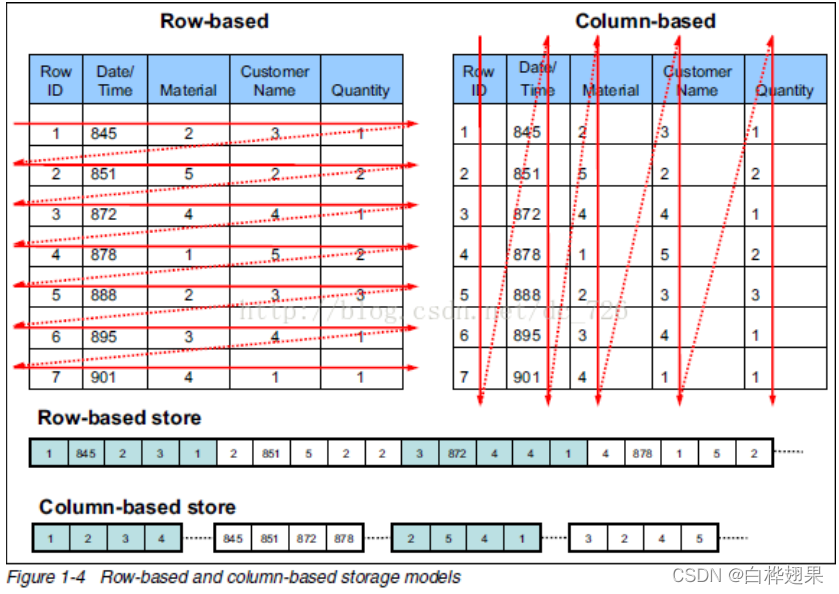
2.CPU指令集层面
现代CPU的扩展指令集支持SIMD。SIMD:单指令多数据流,也就是说在同一个指令周期可以同时处理多个数据。(例如:在一个指令周期内就可以完成多个数据单元的比较)。从早期的MMX到现在的SSE。因为ClickHouse采用了列式存储,这样就可以极大高效的利用CPU的高速缓存,也就是可以将同一列的数据高效的读取到CPU高速缓存的ScanLine中,继而加载到SIMD的寄存器中(如果采用行式存储无法做到这一点)。
3.单机并行读取层面
在传统的数据库( eg:MySQL)中,因为受到各种业务场景的限制,对一次查询请求,在服务端是由一个线程进行处理的。但在ClickHouse中,一次查询请求到了ClickHouse Server实例中是可以对表进行并行读取的,也就是一次查询到了服务端是由多个线程并行处理的。
后面我们会说到ClickHouse的表引擎,其中MergeTree系列的表引擎将数据表分割成为了多个单独的Part, 每个Part中的数据可以独立组织(每个Part有自己独立的索引)。这就会一个查询请求并行读表提供了支撑。也正因为如此,ClickHouse处理一个查询消耗的CPU资源和内存资源较大,故不适合高并发的场景。
4.分布式层面
这个层面就没有特别多可以进行说明的了基本现在主流的号称自己分布式数据库系统都具备相同的特性,无非就是分片和多副本分片进行性能的水平拓展,多副本可以做负载均衡和高可用。
三、ClickHouse的表引擎介绍(ClickHouse的存储引擎)
- Table Engines for Integrations
- 链接其他数据库或者存储系统
- ODBC,JDBC,MySQL,MongoDB,HDFS,S3,Kafka,EmbeddedRocksDB,RabbitMQ,PostgreSQL,SQLite,Hive
- MergeTree---数据是按照树状的层次进行组织,同时随着数据的写入,再服务器的后台按照一定的规则进行Merge.
- 高负载,快速数据写入
- 支持副本、分片、索引等
- Log---适合一次性写入多次读取的场景,它可以作为查询分析的一些中间表。
- 轻量级引擎
- 适合快速写入很多小表然后一次读取(小表100万条数据)
- Special Engines
- Distributed:自己不存储数据,多节点分布式处理,自动并行读取,使用远程表索引。需要结合其它的引擎进行数据分片Share, 可以将其看作某种视图
- Dictionary Table Engine:字典数据作为表
- Memory Table Engine:数据存储在RAM中,并发处理同步,读写不互相阻塞,不支持索引,并行读。数据完全存在与内存中(服务器关闭后数据就不复存在),适合对性能要求极高的小数据表统计分析场景。
据说,在实际的应用中有90%以上的表引擎采用MergeTree系列进行存储,后面我们着重介绍这一类引擎。
四、ClickHouse的表引擎-MergeTree
1、MergeTree引擎提供了根据日期进行索引和根据主键进行索引,同时提供了实时更新数据的功能(如,在写入数据的时候就可以对已写入的数据进行查询,不会阻塞。),mergetree是clickhouse里最先进的表引擎,不要跟merge引擎混淆。这个引擎接受参数形式如下:日期类型的列,可选的采样表达式,一个元组定义了这个表的主键,索引的间隔尺寸。
不包含采样表达式的MergerTree示例:
MergeTree(EventDate,(CounterID,EventDate),8192)
包含采样表达式的MergeTree:
MergeTree(EventDate,intHash32(UserId),(CounterID,EventDate,intHash32(UserID)),8192)
以MergeTree 作为引擎的数据表必须含有一个独立的Date 字段。比如说,EventDate 字段。这个日期字段必须是Date 类型的(非DateTime 类型)。
主键可以是任意表达式构成的元组(通常是列名称的元组),或者是单独一个字段。采样表达式(可选的)可以是任意表达式。一旦设定了这个表达式,那么这个表达式必须在主键中。上面的例子使用了UserID 的哈希intHash32 作为采样表达式,旨在近乎随机地在CounterID 和EventDate 内打乱数据条目。换而言之,当我们在查询中使用SAMPLE 子句时,我们就可以得到一个近乎随机分布的用户列表。
所谓的采样表达式。需要跟查询语句进行配合,目的是在全量数据集合中按照指定的规则进行采样得到采样的样本数据集合。我们在后续的介绍MergeTree的存储结构的时候先忽略这一点。
2、我们给一个具体的创建MergeTree表的例子
CREATE TABLE `ontime` (
`Year` UInt16,
`Quarter` UInt8,
`Month` UInt8,
`DayofMonth` UInt8,
`DayOfWeek` UInt8,
`FlightDate` Date,
`UniqueCarrier` FixedString(7),
...
)ENGINE = MergeTree(FlightDate, (Year, FlightDate), 8192)2.1 接下来我们看看MergeTree类型的ontime表是如何在磁盘上组织数据的。

在上面创建的ontime表的数据目录下,分为多个part。每个part对应一个子目录。目录的命名规则如下:(Start-Date)_(End-Date)_XX_XX_0
前面说过,MergeTree表必须有一个日期字段,数据表按照这个日期字段分割为多个不同的Part。每个Part内部存储的是Start Date到End Date之间的数据。
MergeTree分割数据最大的粒度是月,也就是说不同月份的数据不可能在同一个Part中。每个Part中的数据是独立组织的,有自己独立的索引。这就为单个查询进行并行读取表数据提供了支撑。命名规则中最后面的那一串数字是ClickHouse用来进行多版本控制的。
2.2 在ontime表的每一个part子目录中,存放如下文件下面这些文件,columns.txt记录列信息;每一列有一个bin文件和mrk文件, 其中bin文件是实际数据,primary.idx存储主键信息,结构与mrk一样,类似于稀疏索引。每个列数据文件都是按照主键字典序的方式排序存放的。
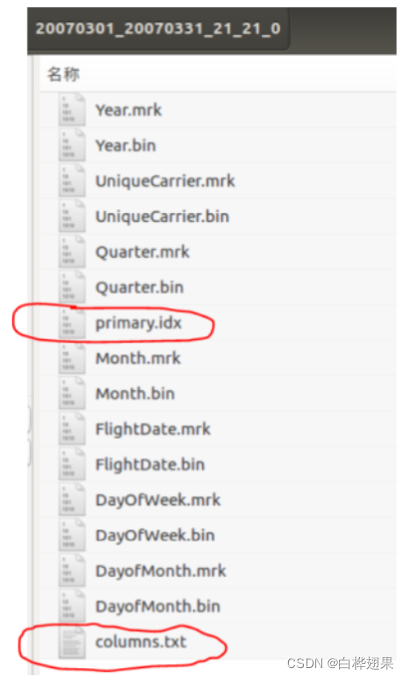
2.3 下面介绍以下稀疏索引方式从primary.idx 到列.mrk 在到列.bin的过程。
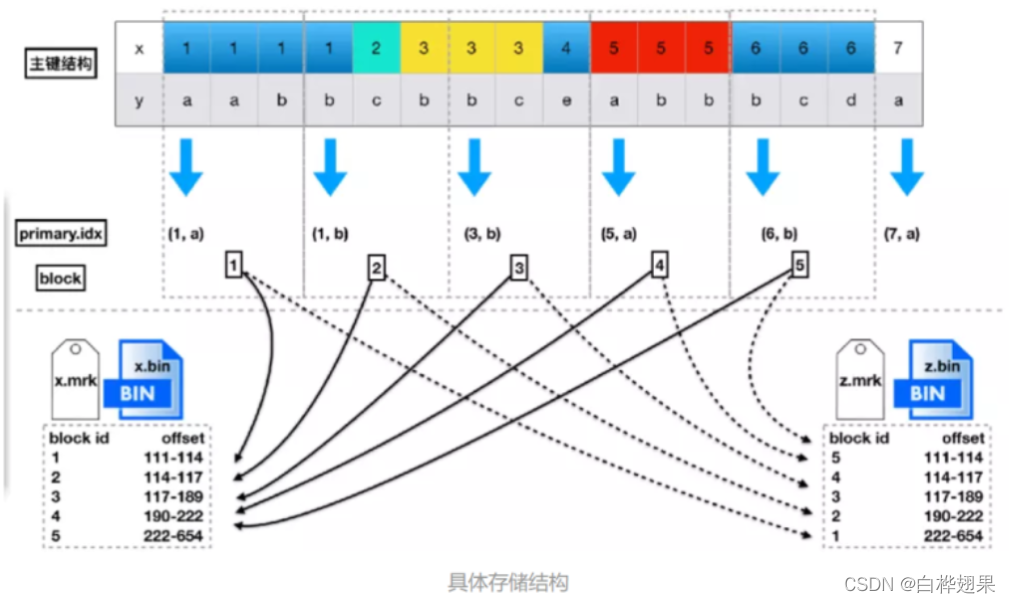
上图展示了mrk文件和primary文件的具体结构,可以看到,数据是按照主键排序的,并且会每隔一定大小分隔出很多个block。每个block中也会抽出一个数据作为索引,放到primary.idx和各列的mrk文件中。而利用mergetree进行查询时,最关键的步骤就是定位block,这里会根据查询的列是否在主键内有不同的方式。根据主键查询时性能会较好,但是非主键查询时,由于按列存储的关系,虽然会做一次全扫描,性能也没有那么差。所以索引在clickhouse里并不像mysql那么关键。实际使用时一般需要添加按日期的查询条件,保障非主键查询时的性能。找到对应的block之后,就是在block内查找数据,获取需要的行,再拼装需要的其他列数据。
2.4 后台Merge的过程:
当插入数据的时候(通常是批量插入),会将插入的数据创建在一个新的Part 之中。同时会在后台周期性的进行merge的过程,当merge的时候,很多个part会被选中,通常是最小的一些part,然后merge成为一个大的排好序的part。换句话说,整个这个合并排序的过程是在数据插入表的时候进行的。这个merge会导致这个表总是由少量的排序好的part构成,而且这个merge本身并没有做特别多的工作。
在插入数据的过程中,属于不同的month的数据会被分割成不同的part,这些归属于不同的month的part是永远不会merge到一起的。
这些part在进行合并的时候会有一个大小的阈值,所以不会有太长的merge过程。
2.5 在MergeTree系列表引擎中还有SummingMergeTree、AggregatingMergeTree这些都是在MergeTree的基础上增加一些统计功能,具体就不说了。
另外值得一提的是,MergeTree系列里面还有一写自带复制功能的表引擎ReplicatedMergeTree、ReplicatedSummingMergeTree、ReplicatedAggregatingMergeTree这些表引擎,是在原来的基础之上又增加了多副本复制功能(但该复制功能需要结合ZooKeeper一起才能实现)。这个在我们后面介绍集群功能的时候再讲一讲。
Clickhouse支持2中复制方式,一种是Distribute表引擎提供的多写复制模式,另外就是这种复制表(ReplicateXXXXMergeTree)提供的复制模式。(这一点一定要引起重视,这在集群搭建的时候非常重要)。
五、ClickHouse的集群
现代数据库的集群方式无外乎: 分片+多副本。
这里我们来看看ClickHouse集群具体该怎么玩?我们这里列举2个搭建集群方式,集群的模式都一样。分为3个分片(Shard),每个分片有3个副本。
上面示例数据表采用ClickHouse官网上提供的航班信息数据(ontime表)。
ClickHouse集群中的每一个实例,都知道完整的集群拓扑(通过配置文件)。所以,客户端可以连接到任意一个ClickHouse实例进行查询和数据批量写入。
这里区分的2种方式主要是副本之间复制的方式不同。一种是利用Distribure表引擎多写的方式实现(无法保证数据一致性);一种是利用ReplicateXXXXMergeTree这种复制表引擎配合ZooKeeper的方式实现复制。
注意:虽然采用了2种复制模式,但要实现分片,都需要在XXXXMergeTree或ReplicateXXXMergeTree之上定义Distribute引擎。
ClickHouse集群选择的是满足CAP原则的AP。也就是保证可用性,牺牲一致性。
5.1.1 采用Distribute表引擎多写的方式实现复制(1)

这种复制模式,被戏称为“穷人的复制模式”。也就是说当你项目经费紧张的时候无法购买更多的服务器另外部署ZooKeeper集群的时候可以采用这种模式。
5.1.2 采用Distribute表引擎多写的方式实现复制(2)配置示例
建立Local表(MergeTree)和Distribute表
配置集群拓扑信息

5.1.3 采用Distribute表引擎多写的方式实现复制(3)-在分发表(Distribute)上读取数据的过程 
5.1.4 采用Distribute表引擎多写的方式实现复制(4)-在分发表(Distribute)上写入数据的过程
前面说过,ClickHouse集群的每一个ClickHouse实例都知道完整的集群拓扑结构(每一个ClickHouse实例上都有一个Distibute引擎实例),所以客户端可以接入任何一个ClickHouse实例,进行分发表数据读取。
在all表上写数据时CH数据流程如下:
1.主Server的Distribute引擎选择合适的Shard写入数据。
(主Server就是接受到客户端查询命令的那台ClickHouse实例)
2.主Server的Distribute引擎将写入的数据发给该Shard的每一个副本实例
(这就是Distribute多写复制方式,但Distribute引擎不会确保每一个副本都写成功,这就可能导致数据的不一致性)
5.2.1 采用复制表配合ZooKeeper的方式实现复制(1)
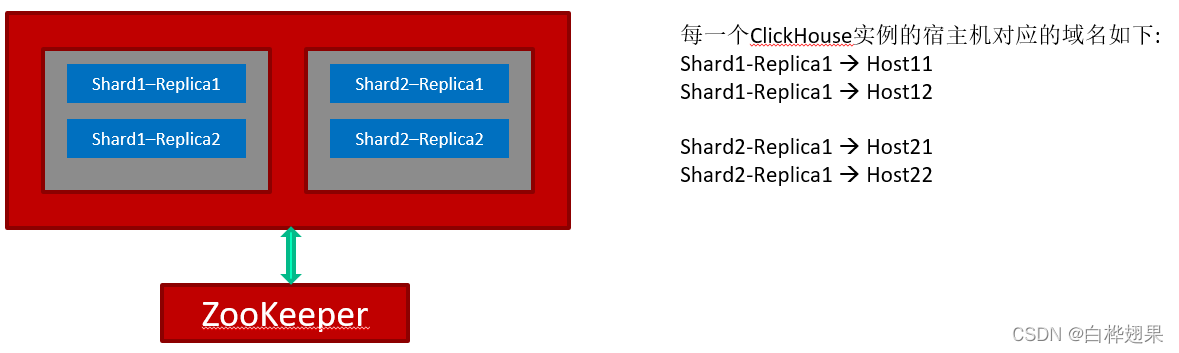
这是ClickHouse推荐的一种集群搭建模式,但该模式需要依赖额外的ZooKeeper集群
5.2.2 采用复制表配合ZooKeeper的方式实现复制(2) – 配置集群拓扑结构
5.2.3 采用复制表配合ZooKeeper的方式实现复制(3)-建立Local表的ReplicateMergeTree和Distribute表
5.2.4 采用复制表配合ZooKeeper的方式实现复制(4) –在分发表(Distribute)上读取数据的过程
数据读取过程跟前面那个复制模式是一样的
5.2.5 采用复制表配合ZooKeeper的方式实现复制(5) –在分发表(Distribute)上写入数据的过程
前面说过,ClickHouse集群的每一个ClickHouse实例都知道完整的集群拓扑结构(每一个ClickHouse实例上都有一个Distibute引擎实例),所以客户端可以接入任何一个ClickHouse实例,进行分发表数据读取。
在all表上写数据时CH数据流程如下:
1.主Server的Distribute引擎选择合适的Shard写入数据。
(主Server就是接受到客户端查询命令的那台ClickHouse实例)
2.主Server的Distribute引擎将选择一个该Shard中“健康的”副本实例,然后将写入数据发送给它
(所谓健康的广义上来说就是存货的,当前负载小的)
3.然后该副本配合ZooKeeper进行后台异步的数据复制
(通过ZooKeeper可以一定程度上的保证数据的一致性)