Coggle 30 Days of ML(23年7月)任务七:训练TextCNN模型
任务七:使用Word2Vec词向量,搭建TextCNN模型进行训练和预测
- 说明:在这个任务中,你将使用Word2Vec词向量,搭建TextCNN模型进行文本分类的训练和预测,通过卷积神经网络来进行文本分类。
- 实践步骤:
- 准备Word2Vec词向量模型和相应的训练数据集。
- 构建TextCNN模型,包括卷积层、池化层、全连接层等。
- 将Word2Vec词向量应用到模型中,作为词特征的输入。
- 使用训练数据集对TextCNN模型进行训练。
- 使用训练好的TextCNN模型对测试数据集进行预测
导入训练好的Word2Vec模型
由于上一部分我们已经训练好了我们的模型,所以这一部分我们直接导入即可
# 准备Word2Vec词向量模型和训练数据集
word2vec_model = Word2Vec.load("word2vec.model")
在数据分析的时候,我们已经发现,词语的数量是不一的,所以首先我们先对数据进行处理,将文本序列转化为词向量表示,并且填充为长度为200
# 获取Word2Vec词向量的维度
embedding_dim = word2vec_model.vector_size
# 转换训练数据集的文本序列为词向量表示,并进行填充
train_sequences = []
for text in train_data:
sequence = [word2vec_model.wv[word] for word in text if word in word2vec_model.wv]
padded_sequence = pad_sequences([sequence], maxlen=max_length, padding='post', truncating='post')[0]
train_sequences.append(padded_sequence)
# 转换测试数据集的文本序列为词向量表示,并进行填充
test_sequences = []
for text in test_data:
sequence = [word2vec_model.wv[word] for word in text if word in word2vec_model.wv]
padded_sequence = pad_sequences([sequence], maxlen=max_length, padding='post', truncating='post')[0]
test_sequences.append(padded_sequence)
构建TextCNN模型
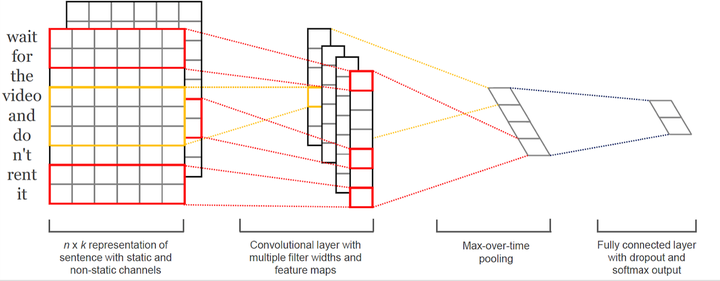
接下来我们就开始构建一下TextCNN模型,包括卷积层、池化层、全连接层等,这样我们就初步得到一个非常简单的模型了
# 构建TextCNN模型
model = tf.keras.Sequential()
model.add(layers.Conv1D(128, 5, activation='relu', input_shape=(max_length, embedding_dim)))
model.add(layers.GlobalMaxPooling1D())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(num_classes, activation='softmax'))
训练模型
接下来我们就可以开始训练我们的模型了,这里使用了SGD优化器进行操作,在训练之前,我们还需要把训练数据集的标签转换为one-hot编码
# 设置优化器和学习率
optimizer = optimizers.SGD(learning_rate=0.1) # 使用SGD优化器,并设置学习率为0.1
# 编译模型
model.compile(optimizer=optimizer, loss='categorical_crossentropy', metrics=['accuracy'])
# 转换训练数据集的标签为one-hot编码
train_labels = tf.keras.utils.to_categorical(train_labels)
# 训练模型
model.fit(np.array(train_sequences), train_labels, epochs=5, batch_size=32)
Epoch 1/5
438/438 [==============================] - 5s 6ms/step - loss: 0.4385 - accuracy: 0.8454
Epoch 2/5
438/438 [==============================] - 2s 5ms/step - loss: 0.4309 - accuracy: 0.8454
Epoch 3/5
438/438 [==============================] - 3s 6ms/step - loss: 0.4308 - accuracy: 0.8454
Epoch 4/5
438/438 [==============================] - 2s 6ms/step - loss: 0.4307 - accuracy: 0.8454
Epoch 5/5
438/438 [==============================] - 2s 6ms/step - loss: 0.4309 - accuracy: 0.8454
可能是模型太简单了,所以可以看到,通过训练以后,准确率也没有较大的提升,还可以继续改进
预测与提交
最后使用训练好的TextCNN模型对测试数据集进行预测,得到csv数据以后进行提交
# 预测测试数据集的分类结果
predictions = model.predict(np.array(test_sequences))
predicted_labels = predictions.argmax(axis=1)
# 读取提交样例文件
submit = pd.read_csv('ChatGPT/sample_submit.csv')
submit = submit.sort_values(by='name')
# 将预测结果赋值给提交文件的label列
submit['label'] = predicted_labels
# 保存提交文件
submit.to_csv('ChatGPT/textcnn.csv', index=None)
总结
这个TextCNN模型太过于简单,所以以至于可能没有学习到很多的数据,接下来可以进行调参和设置合理的模型结构,以期得到更好的结果,再接再厉,加油!!!