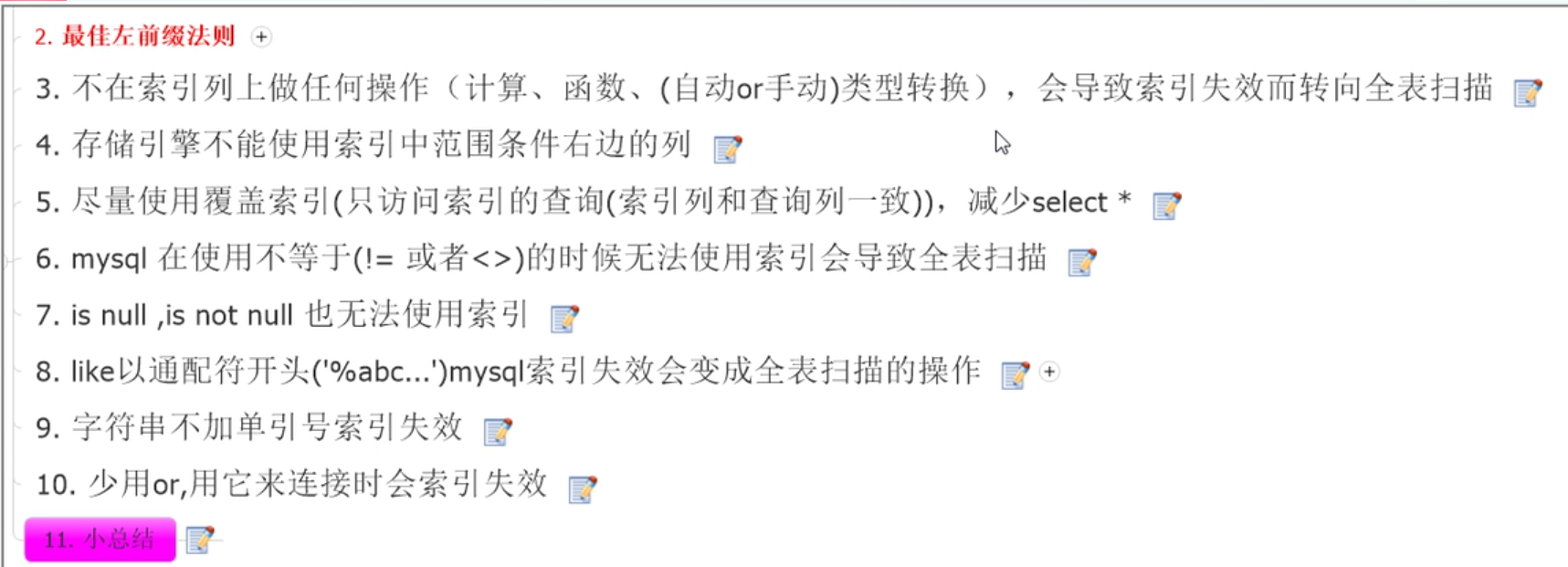
1、索引排好序的能够实现快速查找的数据结构,是存储在磁盘上的一种文件,是和数据库表在物理上分开而逻辑上相连的一种数据结构
2、B树不一定都是二叉树,而叫多路搜索树,大多数是B树索引,也有hash索引等其他的索引
创建成了索引,而且加上了唯一索引的限制(UNIQUE),那么该索引列上的所有的值必须不能重复,都是
唯一的,如果不加唯一索引限制,是可以重复的
数据的增删改的速度,因为一旦数据表中的数据发生变化,如果变化的列恰好也是索引列,那相应的索引
也要发生更改
5、经常更新的字段不要建索引,重复率太高的字段不要建索引,可以用一个公式来衡量一个列创建索引的选择性:一个列中不同值的数量/该列总记录的数量
6、mysql 是怎么优化的?执行 EXPLAIN 关键字 + SQL 语句得到:
id select_type table possible_keys key key_len ref rows Extra
7、要么别建索引,如果建索引,则group by 的顺序一定要和建索引的顺序相同,来避免产生:Extra 属性里面出现:using filesort 和 using temporary,特别是不要出现后者
8、在范围索引后面的索引是不起作用的(失效索引)
select * from employee LEFT JOIN dept on employee.deptID = dept.id
(员工表的部门 ID 等于部门表的主键 ID)这是一个左连接,employee 当做左表,dept 当做右表,所以需要在 dept 上创建索引如:alter table ‘dept’ ADD INDEX Y ('id')
10、索引最好建立在需要经常查询的字段中,对于JOIN 的优化,永远用小表驱动大表,也就是小表要在左边,大表在右边
11、优先优化内层子查询,也就是带括号的查询,只有内层查询快了,外层查询才能加速
12、如果用 explain 解析的 sql 语句的 key 属性值为 NULL,则有两种可能,一种是没创建索引第二是虽然创建了索引,但是索引失效
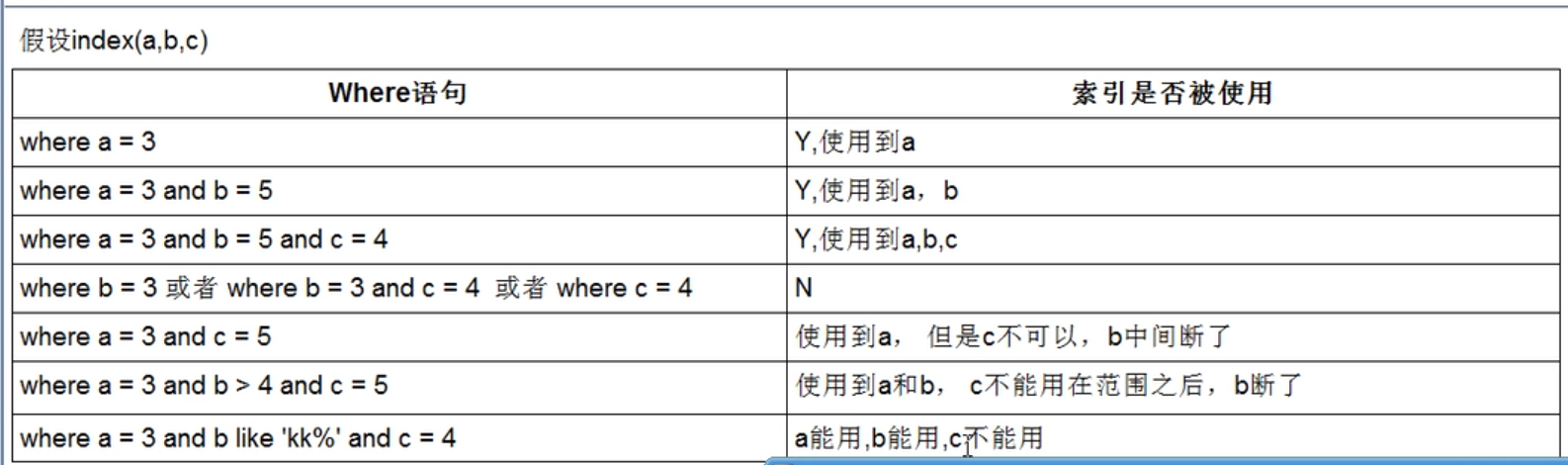
带头大哥不能倒:意思就是按索引创建的顺序,第一个被创建的索引列必须要用上,否则后面的索引不论怎么组合或者单独使用都是无效(也叫做最佳左前缀法则)
中间兄弟不能断:意思是不能隔空只用,比如没有用到中间的 b,而是使用的 a 和 c,则 c 索引失效,a 可以正常使用
14、范围之后全失效,比如:
select * from Employee Where name=July AND age>25 AND position=manager
这个 sql 中用到了 age>25 这个范围,所以 mysql 就会在这个索引层进行查找,后面的 position就失效了
15、尽量在索引列内做查询,少用 select *,比如可以用:
select a,b from Employee Where name=July AND age>25 AND position=manager
16、当使用不等于符号(!=或者<>)或者is NULL,或者 is not NULL的时候,会导致索引失效,全表扫描
****覆盖索引:查询的时候,选择的查询字段与创建复合索引的字段的名称相同,如果在查询的时候,查询字段的顺序和创建覆盖索引的顺序不一样,索引也能够正常使用,由于在 mysql 架构的第二层有一个优化器,会自动把顺序调整过来,所以一般要按照创建复合索引的顺序写查询字段,避免了一次数据库内部优化的过程,比如:
create INDEX abcd on Employee(a,b,c,d);
select a,b,c,d from Employee Where a=1,b=2,c=2,d=0 和 select a,b,c,d from Employee Where a=1,b=2,d=0,c=2
这两条 sql 的 explain 结果是相同的,只是第二条 sql 在 mysql 内部做了一次优化,先把 Where 后面的顺序根据创建复合索引的顺序排好
create INDEX abc on Employee (a,b,c);
select a,b,d from Employee Where name like %aa%;
其中 d 字段不是复合索引中的字段,因此该查询仍然是全表扫描,索引失效
18、字符串不加单引号索引会失效,比如:
select * from Employee Where name='2000',该 sql 的索引不会失效,但是如果2000上不加单引号,虽然能够查到结果,(mysql 在内部做了一个隐式的转换,把int型转为 string 型),但是索引会失效
19、少用 or,用 or 也会导致索引失效
总结:
带头大哥不能死
中间兄弟不能断
索引列上无计算(包括手动、自动、隐式的数据计算或类型转换)
like百分加右边
范围之后全失效
字符串里加引号