1. shell中的函数
- 通俗地讲,函数就是将一组功能相对独立的代码集中起来,形成一个代码块,这个代码可以完成某个具体的功能(这里理解为命令的堆积也可以)。从本质上讲,函数是一个函数名到某个代码块的映射。也就是说,用户在定义了函数之后,就可以通过函数名来调用其所对应的一组代码(称为函数调用)。
- 函数是把一段代码整理到了一个小单元中,并给这个小单元起一个名字,当用到这段代码时直接调用这个小单元的名字即可。
格式:function f name(){
command
}
函数必须放在最前面
一、Shell中函数的定义
(1)、为了方便程序和管理和模块化并减少代码的重复,函数的确是一个好东西。而
<1>、Shell中函数的定义有两种方法,如下:
▲function fname {
command
command
}
▲fname {
command
command
}
注意,()内是没有参数的,它并不像C语言那样,在()里可以有参数。
<2>函数名不能和命令相同,命令优先级高于函数
<3>函数命名规则
不可与命令相同,否则命令无法正常使用。
函数优先级>命令
不可定义与函数名同名的别名,否则函数无法使用。
别名优先级>函数
所以优先级:别名 > 函数 > 命令
<4>函数中的变量设为局部变量,防止与shell的变量冲突
验证
# 创建函数文件fun2,定义test函数
[root@localhost ~]#vim fun2
function test()
{
a=first
echo "a=$a"
}
# 编写脚本testfun2.sh
[root@localhost ~]#vim testfun2.sh
#!/bin/bash
#
a=second
source fun2
test
echo "a=$a"
# 执行脚本
[root@localhost ~]#bash testfun2.sh
a=first
a=first
结果表明虽然脚本中定义了a=second,但是执行test函数之后,已经变成了first。为了解决脚本中变量和函数中变量的混淆,一般将函数中的变量定义为局部变量。
(2)、使用函数
<1>载入函数
子shell中如果需要使用父shell中的函数,需要将函数加载至本shell
加载方式
source FUNCTION
. FUNCTION
注:修改函数之后,必须重新载入shell才能生效
<2>调用函数
输入函数名再加参数即可
(3)、函数返回值return和exit的不同
return:退出当前函数
return :从函数中返回,用最后状态命令决定返回值
return 0 :无错误返回。
return 1-255 :有错误返回
exit:退出当前脚本
(4)、删除函数
unset FUNCTION:删除函数
set:查看所有定义的函数
注意:如果函数没有定义,就会报错。
(5)、打印函数
![]()
#!/bin/bash
function inp(){
echo "The first par is $1"
ehco "The second par is 2"
echo "The third par is $3"
echo "The scritp name is $0"
echo "The number of par is $#"
}
inp $1 $2 $3
~
打印出来的结果:
[root@localhost tmp]# sh 111.sh
The first par is
The second par is
The third par is
The scritp name is 111.sh
The number of par is 0
那大家可能就郁闷了,函数调用或多或少总是会需要一些参数,那么这些参数要怎么传递进来呢?其实参数传递方式为:fname;(不需要传递参数)或fname agr1 arg2(需要传递两个参数);
二、shell函数语法的定义
在Shell中可以通过下面的两种语法来定义函数,分别如下:
function_name ()
{
statement1
statement2
....
statementn
}或者
function function_name()
{
statement1
statement2
....
statementn
}
函数的调用
当某个函数定义好了以后,用户就可以通过函数名来调用该函数了。在Shell中,函数调用的基本语法如下,
function_name parm1 parm2三、作用域问题
函数的作用域与C/C++语言中的作用约束是一样的,
函数的定义一定要出现在函数的调用语句之前,
但是有一点跟C/C++中不一样的就是变量的作用域问题,经过本人的试验,在注释1的语句改为while [ $count -lt $n ];也是可行的,即函数可以使用本文件中出现的任何变量,但是本人还是建议使用上面例子中的方法,即while [ $count -lt $1 ],并且不要随意使用函数中的变量之外的变量,因为你并不一定知道你调用函数时函数外有什么变量存在也不知道它的值是什么,也不能保证别人在使用你的函数时会传递你在函数中使用到的变量名,如这里的n,别人在使用时可能传递的就是他自己定义的变量,如Count等。
注意:值得注意的是 $ . tinyscript.sh ,就是在当前shell下执行脚本,不加"."或source
则会在子shell下执行脚本,可能会有不同的情况发生,值得注意。
补充一下,就是:
$0:是脚本本身的名字;
$#:是传给脚本的参数个数;
$@:是传给脚本的所有参数的列表,即被扩展为"$1" "$2" "$3"等;
$*:是以一个单字符串显示所有向脚本传递的参数,与位置变量不同,参数可超过9个,即被扩展成"$1c$2c$3",其中c是IFS的第一个字符;
$$:是脚本运行的当前进程ID号;
$?:是显示最后命令的退出状态,0表示没有错误,其他表示有错误;
函数里面的$1 $2 与 脚本的$1 $2 参数怎么区分?
答:函数里用那就是函数里的$1 $2,不在函数里用,那就是shell脚本里面的$1,$2
特别注意,传递参数时,(这个例子中)一定要写成LoopPrint $n;而不能写成LoopPrint n。为什么?例如你输入的是20,则n的值($n)为20,前者表示的是把n的值,即20传递给函数LoopPrint,而后者则表示把字符n传递给函数LoopPrint。这点与在静态语言中的函数参数传递是很不同的,因为在Shell中变量的使用并不需要先定义,所以要使用变量,让Shell知道它是一个变量,并要传递它的值时,就是用$n,而不能直接用n,否则只把n当作一个字符来处理,而不是一个变量。
2. shell中的数组
shell中数组的使用主要是数组元素的创建,元素的增、删、改操作。
定义未知长度的数组,必须得指定长度,无论是通过下标还是直接通过元素。
- 定义数组 a=( 1 2 3 4 5);echo ${a[@]}
- echo ${#a[@]} 获取数组的元素个数
- echo ${#a[*} 显示整个数组
- 数组赋值
- a[1]=100;echo $a{a[@]}
- a[5]=2;echo ${a[@]}如果下标不存在则会自动添加一个元素。
- 数组的删除
- uset;unset a[1]
- 数组分片
- a=['seq 1 5']
- echo ${a[@]:0:3]从第一个元素开始,截取3个。
- echo ${a[@]:0:3]从倒数第三个元素开始,截取4个。
- 数组替换
- echo ${a[@]/3/100}
- a=(${a[@]/3/100})
对b进行定义、赋值。
[root@localhost tmp]# b=(1 2 3)
[root@localhost tmp]# echo $b
1
[root@localhost tmp]# echo ${b[*]}
1 2 3
数组分片
[root@localhost tmp]# a=('seq 1 10')
[root@localhost tmp]# echo ${a[*]}
[root@localhost tmp]# echo ${a[@]:3:4} #从数组的第三个开始数,数四个数字。
s4 5 6 7
[root@localhost tmp]# echo ${a[@]:0-3:} #从数组倒数的第两个开始数,数两个数字。
8 9
数组替换
[root@localhost tmp]# echo ${a[@]/8/6}
1 2 3 3 4 5 6 7 6 9 10
[root@localhost tmp]# a=(${a[@]/8/6})
1 2 3 3 4 5 6 7 6 9 10
[root@localhost tmp]# echo ${a[@]}
1 2 3 3 4 5 6 7 6 9 10
在Shell中,用括号来表示数组,数组元素用“空格”符号分割开。
定义数组的一般形式为: array_name=(value1 ... valuen)
例如:
array_name=(value0 value1 value2 value3)
或者
array_name=(
value0
value1
value2
value3
)
还可以单独定义数组的各个分量:
array_name[0]=value0
array_name[1]=value1
array_name[2]=value2
Shell中数据类型不多,比如说字符串,数字类型,数组。数组是其中比较重要的一种,其重要应用场景,可以求数组长度,元素长度,遍历其元素,元素切片,替换,删除等操作,使用非常方便。
Shell中的数组不像JAVA/C,只能是一维数组,没有二维数组;数组元素大小无约束,也无需先定义数组的元素个数;但其索引则像JAVA/C/Python,从0开始,下面其常用的方式进行总结.
【数组声明】

备注:
1) 不像JAVA/C等强编程语言,在赋值前必须声明;SHELL只是弱编程语言,可事先声明也可不声明;
2) 用unset来撤销数组,可用unset array_name[i]来删除里面的元素
【数组定义】

备注:
1) 数组中的元素,必须以"空格"来隔开,这是其基本要求;
2) 定义数组其索引,可以不按顺序来定义,比如说:names=([0]=Jerry [1]=Alice [2]=David [8]=Wendy);
3)字符串是SHELL中最重要的数据类型,其也可通过($str)来转成数组,操作起来非常方便;
【数组长度】

备注:
1) 使用${array_name[@]} 或者 ${array_name[*]} 都可以全部显示数组中的元素
2) 同样道理${#array_name[@]} 或者 ${#array_name[*]}都可以用来求数组的长度
3)求数组中元素的长度方法有很多,相当于求字符串的长度
【数组遍历】

脚本输出:

备注:
1) 可以使用标准的for循环,这种类C语言的方式来遍历数组中的元素
2) for 元素 in 元素集(数组) 这种类Python的方式来遍历数组
3)从代码可读性与执行速度来看,推荐使用第二种方式
【数组赋值】

备注:
1) 第一种是给已经存在的元素项重新赋值
2) 当然也可以给不存在的索引添加赋值,可以看下面的示例
【数组添加】

【数组切片】
数组切片

元素切片

备注:
1) 通用的格式${array[@]:起始位置:长度},中间以":"隔开,如果第二项省略的话,就取后面所有的项
2) 切片后返回的是字符串,可以通过 新数组=(${旧数组[@]:索引:长度})来索引,参见上面最后一个例子
3) 区别于Python之一:起始位置可以为负数,但必须以放在()中,长度不能为负数
4)区别于Python之二:第二项在Python里面是结束索引,在Shell则代表所取元素的长度
5) 区别于Python之三:Python可以通过 list[-1:-4:-2]来反向取数,在Shell则实现不了
【数组替换】
${array[@]/x/y} 最小匹配替换,每个元素只替换一次
${array[@]//x/y} 最大匹配替换,每个元素可替换多次
${array[@]/x/} 最小匹配删除,只删除一个符合规定的元素
${array[@]//x/} 最大匹配删除,可删除多个符合规定的元素

${array[@]/#x/y} 从左往右匹配替换,只替换每个元素最左边的字符
${array[@]/%x/y} 从右往左匹配替换,只替换每个元素最右边的字符

【数组删除】
# 每个元素,从左向右进行最短匹配
## 每个元素,从左向右进行最长匹配
% 每个元素,从右向左进行最短匹配
%% 每个元素,从右向左进行最长匹配

【数组应用】
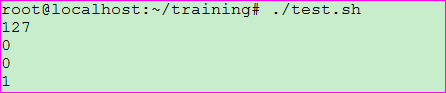
示例一: 将ifconfig命令取到的本地IP: 127.0.0.1逐行显示出来
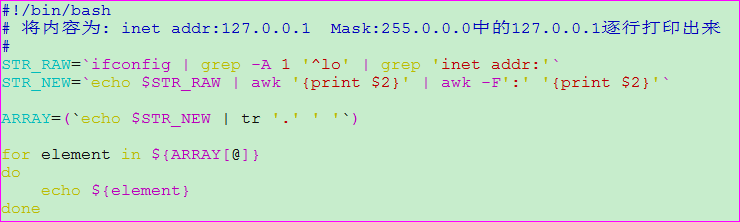
脚本输出:
示例二: 模拟堆栈的push,pop,shift,unshift操作

脚本输出:

示例三: 在1-10间,随机生成10个不重复的数,将其放置于数组中

脚本输出:

备注:
1) 生成[1,10]范围内不重复的随机整数,并保存到数组array中
2) seq 1 10 用于生成1~10的整数序列(包含边界值1和10)
3) awk中的rand()函数用于随机产生一个0到1之间的小数值(保留小数点后6位)
4)rand()只生成一次随机数,要使用srand()函数使随机数滚动生成
5) 括号里留空即默认采用当前时间作为随机计数器的种子,这样以秒为间隔,随机数就能滚动随机生成了
6) 由于以秒为间隔,所以如果快速连续运行两次脚本(1s内),你会发现生成的随机数还是一样的
示例四: 将字符串处理后转为为数组,再对其打印输出
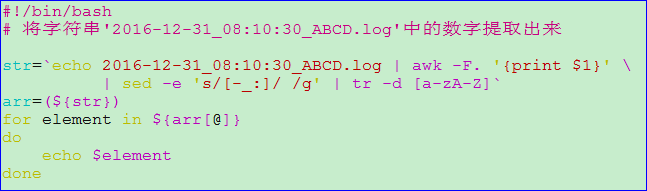
脚本输出:

示例五: 用read -a参数,从标准输入中读取数组,再做操作

脚本输出:

示例六: 判断某个变量,是否在数组中,在输出YES,否输出NO

脚本输出:

示例七: 对数组中的元素进行排序

示例八: 将/etc/passwd文件中以:分隔的第一列,即用户名放置于一个数组中

示例九: 将1-8,每个数自乘后输出

脚本输出:
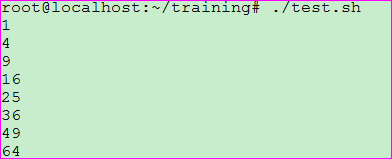
示例十: 借助数组来设置SHELLS的环境变量
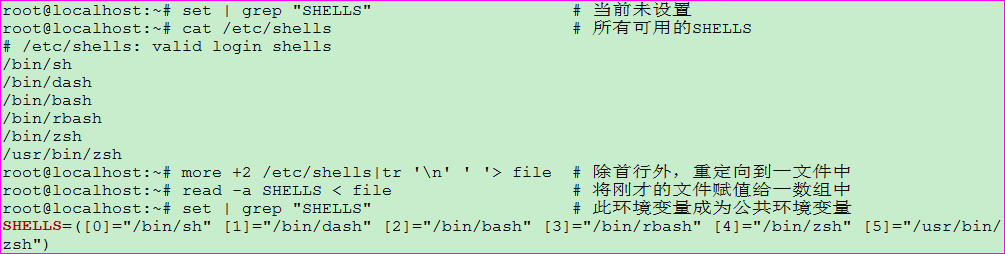
示例十一: 设置IFS,读取文件内容示例

示例十二: 利用eval,模拟实现数组的功能

脚本输出:

示例十三: 利用数组来实现冒泡排序
思路:会重复地走访过要排序的数组,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。越大的元素会经由交换慢慢“浮”到数列的顶端

脚本输出:
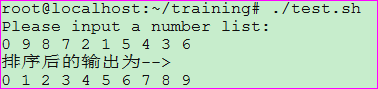
示例十四: 利用数组来求最大值

脚本输出

示例十五
- 数组定义法1:
- arr=(1 2 3 4 5) # 注意是用空格分开,不是逗号!!
- 数组定义法2:
- array
- array[0]="a"
- array[1]="b"
- array[2]="c"
- 获取数组的length(数组中有几个元素):
- ${#array[@]}
- 遍历(For循环法):
- for var in ${arr[@]};
- do
- echo $var
- done
- 遍历(带数组下标):
- for i in "${!arr[@]}";
- do
- printf "%s\t%s\n" "$i" "${arr[$i]}"
- done
- 遍历(While循环法):
- i=0
- while [ $i -lt ${#array[@]} ]
- do
- echo ${ array[$i] }
- let i++
- done
- 向函数传递数组:
- 由于Shell对数组的支持并不号,所以这是一个比较麻烦的问题。
- 翻看了很多StackOverFlow的帖子,除了全局变量外,无完美解法。
- 这里提供一个变通的思路,我们可以在调用函数前,将数组转化为字符串。
- 在函数中,读取字符串,并且分为数组,达到目的。
- fun() {
- local _arr=(`echo $1 | cut -d " " --output-delimiter=" " -f 1-`)
- local _n_arr=${#_arr[@]}
- for((i=0;i<$_n_arr;i++));
- do
- elem=${_arr[$i]}
- echo "$i : $elem"
- done;
- }
- array=(a b c)
- fun "$(echo ${array[@]})"
示例十六
可以不使用连续的下标,而且下标的范围没有限制。
读取数组
读取数组元素值的一般格式是:
${array_name[index]}
例如:
valuen=${array_name[2]}
举个例子:
#!/bin/sh
NAME[0]="Zara"
NAME[1]="Qadir"
NAME[2]="Mahnaz"
NAME[3]="Ayan"
NAME[4]="Daisy"
echo "First Index: ${NAME[0]}"
echo "Second Index: ${NAME[1]}"
运行脚本,输出:
$./test.sh
First Index: Zara
Second Index: Qadir
使用@ 或 * 可以获取数组中的所有元素,例如:
${array_name[*]}
${array_name[@]}
举个例子:
#!/bin/sh
NAME[0]="Zara"
NAME[1]="Qadir"
NAME[2]="Mahnaz"
NAME[3]="Ayan"
NAME[4]="Daisy"
echo "First Method: ${NAME[*]}"
echo "Second Method: ${NAME[@]}"
运行脚本,输出:
$./test.sh
First Method: Zara Qadir Mahnaz Ayan Daisy
Second Method: Zara Qadir Mahnaz Ayan Daisy
获取数组的长度
获取数组长度的方法与获取字符串长度的方法相同,例如:
复制纯文本新窗口
# 取得数组元素的个数
length=${#array_name[@]}
# 或者
length=${#array_name[*]}
# 取得数组单个元素的长度
lengthn=${#array_name[n]}
示例十七
数组元素的创建,元素的增、删、改操作。
1 #!/bin/bash
2
3 #基本数组操作
4 a=(1 2 3) ##()表示空数组
5 echo "第0个元素:"${a[0]}
6 echo "所有元素: "${a[@]}
7 echo "数组长度: "${#a[@]}
8 echo "----------------------------------------------"
9
10 #遍历数组
11 echo "遍历数组:"
12 for item in ${a[@]}
13 do
14 echo $item
15 done
16 echo "----------------------------------------------"
17
18 ##元素操作
19 a=(${a[@]} 4)
20 echo "末尾追加1个元素后: "${a[@]}
21 a[1]=5
22 echo "修改第1个元素后: "${a[@]}
23 unset a[1]
24 echo "删除第1个元素后: "${a[@]}
25 unset a
26 echo "删除所有元素后: "${a[@]}
27 echo "----------------------------------------------"
执行结果:
第0个元素:1
所有元素: 1 2 3
数组长度: 3
----------------------------------------------
遍历数组:
1
2
3
----------------------------------------------
末尾追加1个元素后: 1 2 3 4
修改第1个元素后: 1 5 3 4
删除第1个元素后: 1 3 4
删除所有元素后:
----------------------------------------------
示例十八
shell中数组的定义及遍历
示例:
- #!/bin/sh
- #定义方法一 数组定义为空格分割
- arrayWen=(a b c d e f)
- #定义方法二
- arrayXue[0]="m"
- arrayXue[1]="n"
- arrayXue[2]="o"
- arrayXue[3]="p"
- arrayXue[4]="q"
- arrayXue[5]="r"
- #打印数组长度
- echo ${#arrayWen[@]}
- #for 循环遍历
- for var in ${arrayWen[@]};
- do
- echo $var
- done
- #while循环遍历
- i=0
- while [[ i -lt ${#arrayXue[@]} ]]; do
- echo ${arrayXue[i]}
- let i++
- done
获取数组长度
- ${#arrayWen[@]}
3. 告警系统需求分析
1.告警系统需求分析
(虽然之前我们学习了zabbix,但有时候也不能满足我们的需求,比如比较冷门的监控项目需要写自定义脚本,或者服务器网络有问题,没有办法将客户端的数据发送到服务端。)
需求:使用Shell定制各种个性化告警系统,但需要统一化管理。
思路:制定一个脚本包,包含主程序,子程序,配置文件,邮件引擎,输出日志等。
主程序:作为整个脚本的入口,是整个系统的命脉。
配合文件:是一个控制中心,用它来开关各个子程序,指定哥哥相关联的日志文件。
子程序:这个才是真正的加农脚本。用来监控各个指标。
邮件引擎:是有一个python程序来实现的,它可以定义发邮件的服务器,发邮件人已经发件人的密码
输出日志:整个监控系统要有日志输入。
程序架构:
bin下是主程序文件
conf下是配置文件
shares下是各个监控脚本
mail下是邮件引擎
log下是日志

2.主脚本
1.创建相应的目录
[root@congji ~]# cd /usr/local/sbin/ #脚本放在这个目录中,方便以后查找。
[root@congji sbin]# mkdir mon #配置文件所存放的目录
[root@congji sbin]# cd mon/
[root@congji mon]# mkdir bin conf shares log mail
[root@congji mon]# cd bin/
2.编辑告警系统的主脚本
[root@congji bin]# vim main.sh
#!/bin/bash
#Written by litongyao.
# 是否发送邮件的开关
export send=1
# 过滤ip地址
export addr=`/sbin/ifconfig |grep -A1 "ens33: "|awk '/inet/ {print $2}'`
dir=`pwd`
# 只需要最后一级目录名
last_dir=`echo $dir|awk -F'/' '{print $NF}'`
# 下面的判断目的是,保证执行脚本的时候,我们在bin目录里,不然监控脚本、邮件和日志很有可能找不到
if [ $last_dir == "bin" ] || [ $last_dir == "bin/" ]; then
conf_file="../conf/mon.conf"
else
echo "you shoud cd bin dir"
exit
fi
exec 1>>../log/mon.log 2>>../log/err.log
echo "`date +"%F %T"` load average"
/bin/bash ../shares/load.sh
#先检查配置文件中是否需要监控502
if grep -q 'to_mon_502=1' $conf_file; then
export log=`grep 'logfile=' $conf_file |awk -F '=' '{print $2}' |sed 's/ //g'`
/bin/bash ../shares/502.sh
fi
告警系统配置文件
3.编辑告警系统配置文件
[root@congji mon]# cd conf/
[root@congji conf]# vim mon.conf
## to config the options if to monitor
## 定义mysql的服务器地址、端口以及user、password
to_mon_cdb=0 ##0 or 1, default 0,0 not monitor, 1 monitor
db_ip=10.20.3.13
db_port=3315
db_user=username
db_pass=passwd
## httpd 如果是1则监控,为0不监控
to_mon_httpd=0
## php 如果是1则监控,为0不监控
to_mon_php_socket=0
## http_code_502 需要定义访问日志的路径
to_mon_502=1
logfile=/data/log/xxx.xxx.com/access.log
## request_count 定义日志路径以及域名
to_mon_request_count=0
req_log=/data/log/www.discuz.net/access.log
domainname=
告警系统监控项目
Shell项目-子脚本
[root@congji shares]# pwd
/usr/local/sbin/mon/shares
监控系统平均负载
[root@congji shares]# vim load.sh
#! /bin/bash
##Writen by aming##
load=`uptime |awk -F 'average:' '{print $2}'|cut -d',' -f1|sed 's/ //g' |cut -d. -f1`
if [ $load -gt 10 ] && [ $send -eq "1" ]
then
echo "$addr `date +%T` load is $load" >../log/load.tmp
/bin/bash ../mail/mail.sh [email protected] "$addr\_load:$load" `cat ../log/load.tmp`
fi
echo "`date +%T` load is $load"
监控nginx报错502
[root@congji shares]# vim 502.sh
#! /bin/bash
d=`date -d "-1 min" +%H:%M`
c_502=`grep :$d: $log |grep ' 502 '|wc -l`
if [ $c_502 -gt 10 ] && [ $send == 1 ]; then
echo "$addr $d 502 count is $c_502">../log/502.tmp
/bin/bash ../mail/mail.sh $addr\_502 $c_502 ../log/502.tmp
fi
echo "`date +%T` 502 $c_502"
监控磁盘使用率
[root@congji shares]# vim disk.sh
#! /bin/bash
rm -f ../log/disk.tmp
for r in `df -h |awk -F '[ %]+' '{print $5}'|grep -v Use`
do
if [ $r -gt 90 ] && [ $send -eq "1" ]
then
echo "$addr `date +%T` disk useage is $r" >>../log/disk.tmp
fi
if [ -f ../log/disk.tmp ]
then
df -h >> ../log/disk.tmp
/bin/bash ../mail/mail.sh $addr\_disk $r ../log/disk.tmp
echo "`date +%T` disk useage is nook"
else
echo "`date +%T` disk useage is ok"
常见问题:
1、这里的log=$1定义为第一个参数,那下文的/tmp/$log 这个$log是指第一个参数(ip地址)呢,还是主程序main.sh中的log路径呢?这里的log变量为第一个参数。
(
export log=`grep 'logfile=' $conf_file |awk -F '=' '{print $2}' |sed 's/ //g'`
)
答: 这个$log是指主程序main.sh中的log路径,两个log不一样。
2.
问题:收件箱$1的问题?
拿disk.sh举例:/bin/bash ../mail/mail.sh $addr\_disk $r ../log/disk.tmp
log=$1 这里的$1就是$addr\_disk,那么问题来了:
mail.sh里面./mail.py $1 $2 $3 收件箱就是$1(也就是$addr\_disk),这邮件怎么发出去?
答:应该把log=$2吧,然后$1在监控脚本里面还是定义收件箱地址就可以了;
3.
./mail.py $1 $2 $3 这三个字符的意义
是不是和mail.py脚本中的
def main():
to=sys.argv[1]
subject=sys.argv[2]
content=sys.argv[3]
参数有关系?
答:定义发送的信息的内容:收件人、邮件名称、邮件内容