目录
前言
前段时间老师推荐过进行LSTM方向的研究,且笔者考虑到transformer在NLP领域的火热现状,于是选择了seq2seq作为切入点。seq2seq具有和transformer一样的encoder和decoder结构,但缺少attention部分,同时seq2seq模型中的encoder和decoder一般采用LSTM进行实现,因此笔者认为学习seq2seq模型能同时有利于对LSTM和Transformer的理解和学习。本文对基于seq2seq的机器翻译系统从原理和代码上进行了分析和实现,并在代码部分进行了详尽的注释和解析,方便读者理解。
1.模型结构
seq2seq模型由encoder和decoder两部分构成,以下分别对两部分进行模型原理的说明。
1.1 encoder
如下图所示,对于encoder层,假设想要翻译的英文句子为“Hi.”,其对应的汉语意思为"你好。"。
encoder的输入中,将英文句子中的每个符号作为一次输入,利用LSTM模型提取英文句子的语义,即图中最后一个hidden层。
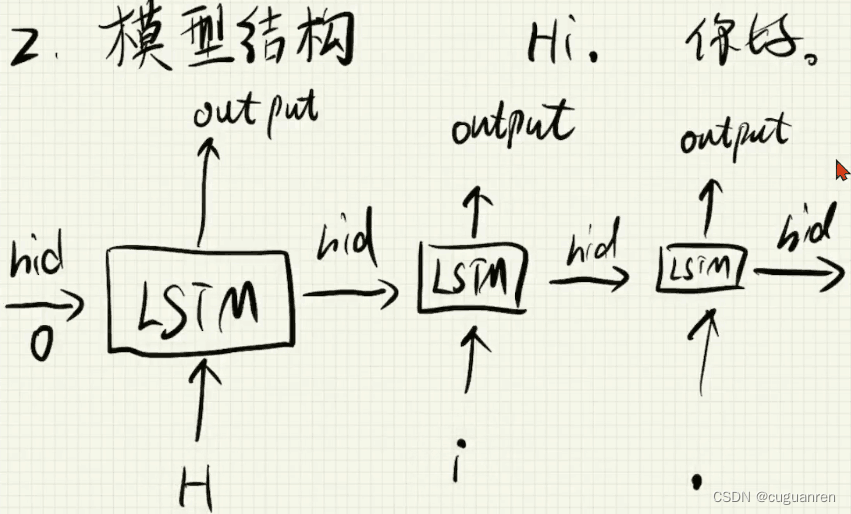
1.2 decoder
训练时:
将encoder层提取的语义作为decoder层的初始hidden层输入,此时在训练中会在汉语译文中增加BOS和EOS用以训练。decoder层的训练输入为BOS+汉语译文各个字,对应的标签数据为汉语译文各个字+EOS。

也就是用红框中的内容作为decoder层的输入,绿框部分作为Label进行训练。注意在测试集上的预测中,decoder层的输入只有BOS,因为实际使用中预测的就是汉语译文,自然不会有汉语译文供参考了。

2.数据处理
2.1 数据集
本系统采用的数据集是含有两万多条的中英句子,具体形式如下图所示:

2.2 字典构建
依据数据集,分别提取汉字,英文符号去重后分别构造词典(字符到数字索引的键值对)en_word_2_index,ch_word_2_index,以及en_index_2_word,ch_index_2_word(数字索引到字符的列表,因为列表排序序号可以替代数字,因此用列表表示即可)。
2.3 特殊符号
系统中增加了PAD,BOS,EOS分别进行数据填充和译文修饰。
3.参数加载
3.1 库的导入
2.2中提到过对原始数据进行去重并构造字典,这里提供处理完成后的pickle类型文件直接供使用。对于pickle文件的提取也需要在之后 import pickle。
import torch
import torch.nn as nn
import pandas as pd
from torch.utils.data import Dataset,DataLoader
import pickle3.2 词典导入
#读取提前构建好的双语字符与数字索引的字典
with open("datas\\ch.vec","rb") as f1:
_, ch_word_2_index,ch_index_2_word = pickle.load(f1)
with open("datas\\en.vec","rb") as f2:
_, en_word_2_index, en_index_2_word = pickle.load(f2)word_2_index,index_2_word的类型分别是字典和列表,后者是列表因为其默认序号可以替代数字,因而省略了数字部分。提取出的四个序列如下所示,此处并不是构造one-hot向量,而是作为数字索引,在之后直接构造对应的embbding。两个pickle文件中各自有三列数据,第一列是字向量,因此只需要提取后两列数据即可。

4.准备训练集
4.1 导入原始训练数据
从csv文件中分别取出训练集数据,并将该过程封装为一个函数,同时增加了nums参数用来选择读取的数据样本数量。考虑到读者的机器性能,本系统对nums进行了较小的取值,因此预测准确率会受到相应的影响,读者可根据自己机器的性能对nums进行扩值或者忽略(默认是导入所有数据样本进行训练)。
def get_datas(file = "datas\\translate.csv",nums = None):
all_datas = pd.read_csv(file)
# 从csv文件中分别读取英语和汉语译文,并分别列表化
en_datas = list(all_datas["english"])
ch_datas = list(all_datas["chinese"])
# 因为总数据比较多,因此在初期做测试的时候设置nums参数,限制取出的数据数量,取少了会影响训练的效果
if nums == None:
return en_datas,ch_datas
else:
return en_datas[:nums],ch_datas[:nums]提取出的ch_datas,en_datas如下所示:

4.2词典修改
在中英文词典中增加PAD,BOS,EOS三个符号,因为最开始的导入文件中没有这三种符号,也可以直接修改文件,省略这一部分。
# 在字典中添加PAD,BOS,EOS三个新字符,也可以对字典进行处理,就不用再添加了
ch_corpus_len = len(ch_word_2_index)
en_corpus_len = len(en_word_2_index)
ch_word_2_index.update({"<PAD>":ch_corpus_len,"<BOS>":ch_corpus_len + 1 , "<EOS>":ch_corpus_len+2})
en_word_2_index.update({"<PAD>":en_corpus_len})
ch_index_2_word += ["<PAD>","<BOS>","<EOS>"]
en_index_2_word += ["<PAD>"]
#直接增加长度或者自增len的长度都可以
ch_corpus_len += 3
en_corpus_len = len(en_word_2_index)4.3 加载数据集
①使用pytorch提供的Dataloader加载数据集。在代码中的“return en_index,ch_index”部分,pytorch会自动将同一batch的结果进行自动组合,因此要通过自定义 vatch_data_process函数来完成对各结果的padding填充,BOS,EOS的增加等自定义操作。
通过修改Dataloader里对应的collate_fn参数,实现自动组合前对各结果的自定义修改功能。

②batch_data_process函数有两个作用。第一,实现对encoder层输入的padding,否则一条一条输入太慢,将一个batch的数据作为矩阵输入更高效。这里的padding对象也是同一batch各样本的输入,因为考虑所有样本时,句子长度差异较大,效果不好。参数中的batch_datas也就是上文en_index,ch_index的batch-size个组合成的迭代器。
③第二,实现在训练集上decoder层输入的修改,即输入层的句子前加上BOS标志开始,标签最后加上EOS标志结束,参考1.2中的图示。加上BOS是因为预测时不知道中文,如果不加上BOS,则输入为空;加上EOS则是标志着预测过程的停止。
④结果:下两图分别代表经处理后返回的encoder,decoder层输入。
假设batch为3,则英语句子对应索引经padding后,长度相等,且padding体现为77。
![]()
汉语译文经处理后,最开始都是表示BOS的3590,末尾是padding3589和表示EOS的3591。

总代码如下:
#对数据进行处理,①将每个英语和汉语句子中的字符对应通过字典对应为数字索引,②对各组数字索引进行pad处理,③对汉字句子进行BOS和EOS处理
class MyDataset(Dataset):
def __init__(self,en_data,ch_data,en_word_2_index,ch_word_2_index):
# 导入双语原始句子
self.en_data = en_data
self.ch_data = ch_data
# 导入双语字符与数字索引的字典
self.en_word_2_index = en_word_2_index
self.ch_word_2_index = ch_word_2_index
# 将一对双语句子从字符状态转换为数字索引状态,形式是将一个句子中的各个字符转换为数字索引的列表
def __getitem__(self,index):
en = self.en_data[index]
ch = self.ch_data[index]
en_index = [self.en_word_2_index[i] for i in en]
ch_index = [self.ch_word_2_index[i] for i in ch]
return en_index,ch_index
# pytorch会自动地把batch-size个双语句子组合在一起,参数中的batch_datas也就是上文en_index,ch_index的batch-size个组合成的迭代器
# 此处添加的函数作为Dataloader的一个参数,意在对数字索引格式进行再处理,也就是pad,EOS,BOS这些
def batch_data_process(self,batch_datas):
global device
en_index , ch_index = [],[]
en_len , ch_len = [],[]
for en,ch in batch_datas:
en_index.append(en)
ch_index.append(ch)
en_len.append(len(en))
ch_len.append(len(ch))
max_en_len = max(en_len)
max_ch_len = max(ch_len)
# 在每一句英文句子的数字索引列表后添加PAD统一大小,在每一句汉语句子的数字索引列表前加BOS,后加EOS,再添加PAD统一大小
en_index = [ i + [self.en_word_2_index["<PAD>"]] * (max_en_len - len(i)) for i in en_index]
ch_index = [[self.ch_word_2_index["<BOS>"]]+ i + [self.ch_word_2_index["<EOS>"]] + [self.ch_word_2_index["<PAD>"]] * (max_ch_len - len(i)) for i in ch_index]
#tensor化并且布置到GPU上训练
en_index = torch.tensor(en_index,device = device)
ch_index = torch.tensor(ch_index,device = device)
#返回的是一个batch的经过padding,BOS,EOS修改的句子中各字符对应的数字索引构成的列表
return en_index,ch_index
# 判断提取的双语句子的数量是否相等,不相等肯定是提取出问题了
def __len__(self):
assert len(self.en_data) == len(self.ch_data)
return len(self.ch_data)5.Encoder
利用pytorch构造英文字符对应的词向量embbding,然后将输入句子的数字索引形式转化为对应的词向量,以词向量的形式输入,词向量的维度由超参数指定。
#对数字索引形式的句子进行Embedding处理和基于LSTM的语义提取
class Encoder(nn.Module):
def __init__(self,encoder_embedding_num,encoder_hidden_num,en_corpus_len):
super().__init__()
# 基于英文语料库建立Embedding
self.embedding = nn.Embedding(en_corpus_len,encoder_embedding_num)
# batch-first设置为True是因为torch中dataset处理后的batch批次的样本,其向量维度是batch,input-size,hidden-size,因此不符合默认的input-size,batch,hidden-size
# 顺序,通过该参数的设置实现参数的匹配
self.lstm = nn.LSTM(encoder_embedding_num,encoder_hidden_num,batch_first=True)
def forward(self,en_index):
# 将输入的句子进行Embbdeing处理,同时得到Encoder层的输出:encoder_hidden
en_embedding = self.embedding(en_index)
_,encoder_hidden =self.lstm(en_embedding)
return encoder_hidden6.Decoder
这部分和Encoder的思路基本相同,主要区别在于decoder部分的输入依据当前是训练还是测试有所不同,上文已经提及,此处不再赘述。
class Decoder(nn.Module):
def __init__(self,decoder_embedding_num,decoder_hidden_num,ch_corpus_len):
super().__init__()
self.embedding = nn.Embedding(ch_corpus_len,decoder_embedding_num)
self.lstm = nn.LSTM(decoder_embedding_num,decoder_hidden_num,batch_first=True)
# decoder_input和encoder部分那个en_index是一个意思,都是数字索引格式的句子,
# 但因为汉语句子进行了BOS和EOS处理,我们要对Decoder的输入额外地进行去除末尾EOS的处理
def forward(self,decoder_input,hidden):
embedding = self.embedding(decoder_input)
decoder_output,decoder_hidden = self.lstm(embedding,hidden)
return decoder_output,decoder_hidden
7.模型训练
将超参数传入Encoder和Decoder,构造损失函数,优化器,调用两层得到输出,并对输出进行线性变换得到预测结果,与实际标签比较。
7.1输入格式
注意到在decoder层的输入前,将汉语译文作了两次处理,分别是保留BOS和保留EOS,因为之前增加这两个符号时没有区别输入和标签,在此处进行分类。
7.2 线性映射层
增加classifier,实现将decoder层输出的维度变换。
7.3超参数设置
encoder_embedding_num和decoder_embedding_num依据英汉词典的大小设置,encoder_hidden_num = 100和decoder_hidden_num = 100则是对LSTM隐层维度的设置,应保持两者一致,否则应另增加一层线性变换用以修改维度。
# 超参数的设置
en_datas,ch_datas = get_datas(nums=200)
encoder_embedding_num = 50
encoder_hidden_num = 100
decoder_embedding_num = 107
decoder_hidden_num = 100
batch_size = 2
epoch = 40
lr = 0.0017.4具体训练
在loss函数求值过程中,en_index,ch_index的维度分别为3和2,因此将en_index的前两维拉成一维,ch_index同理,从而求loss,否则对一个batch的数据单独求loss会相对更加麻烦。
for e in range(epoch):
for en_index,ch_index in dataloader:
loss = model(en_index,ch_index)
loss.backward()
opt.step()
opt.zero_grad()
print(f"loss:{loss:.3f}")总代码如下:
class Seq2Seq(nn.Module):
def __init__(self,encoder_embedding_num,encoder_hidden_num,en_corpus_len,decoder_embedding_num,decoder_hidden_num,ch_corpus_len):
super().__init__()
self.encoder = Encoder(encoder_embedding_num,encoder_hidden_num,en_corpus_len)
self.decoder = Decoder(decoder_embedding_num,decoder_hidden_num,ch_corpus_len)
# 将Decoder的输出从Embedding维度映射到汉字词典的维度,匹配对应的汉字
self.classifier = nn.Linear(decoder_hidden_num,ch_corpus_len)
self.cross_loss = nn.CrossEntropyLoss()
def forward(self,en_index,ch_index):
# 将汉语句子分别去首尾的BOS和EOS作为Decoder层的输入和标签
decoder_input = ch_index[:,:-1]
label = ch_index[:,1:]
encoder_hidden = self.encoder(en_index)
# 预测模型只需要各cell的hidden,不需要最后cell的hidden
decoder_output,_ = self.decoder(decoder_input,encoder_hidden)
pre = self.classifier(decoder_output)
# label是[batch,len],pre是[batch,len,Embedding],因此要进行维度处理,此处是把一个batch里的句子都放在一个维度
loss = self.cross_loss(pre.reshape(-1,pre.shape[-1]),label.reshape(-1))
return loss8.模型预测
应注意预测阶段中decoder的输入只有BOS符号
#供用户使用的API接口
def translate(sentence):
global en_word_2_index,model,device,ch_word_2_index,ch_index_2_word
# 将英文句子中的字母转换为数字索引,此处进行维度增加的处理并tensor化,方便传参
en_index = torch.tensor([[en_word_2_index[i] for i in sentence]],device=device)
result = []
# 与训练时不同,预测时decoder的输入是“空”,能利用的只有encoder传入的语义hidden,因此之前会设置汉语句子首位为BOS,此处直接将BOS作为初始输入,并将cell的预测结果作为下一个cell
# 的输入,实现汉语语义的预测
encoder_hidden = model.encoder(en_index)
decoder_input = torch.tensor([[ch_word_2_index["<BOS>"]]],device=device)
# 将encoder层的输入作为decoder层的初始hidden
decoder_hidden = encoder_hidden
while True:
decoder_output,decoder_hidden = model.decoder(decoder_input,decoder_hidden)
pre = model.classifier(decoder_output)
w_index = int(torch.argmax(pre,dim=-1))
word = ch_index_2_word[w_index]
if word == "<EOS>" or len(result) > 50:
break
result.append(word)
# 将cell的预测结果作为下一个cell的输入,实现汉语语义的预测
decoder_input = torch.tensor([[w_index]],device=device)
hanyu="".join(result)
return hanyu
# print(hanyu)
# print("*****")
# print("译文: ","".join(result))9.图形交互界面
本系统的图形交互界面采用PySimpleGUI实现,该库的具体使用参考另一篇博客即可,最终的实现效果如下:

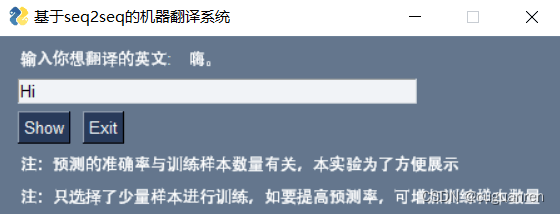
总代码如下:
from seq2seq import translate
import PySimpleGUI as sg
layout = [[sg.Text('输入你想翻译的英文:'), sg.Text(size=(15,1), key='-OUTPUT-')],
[sg.Input(key='-IN-')],
[sg.Button('Show'), sg.Button('Exit')],
[sg.Text('注:预测的准确率与训练样本数量有关,本实验为了方便展示')],
[sg.Text('注:只选择了少量样本进行训练,如要提高预测率,可增加训练样本数量')]
]
#第一行留有一个用以更新的变量区域,键名自定义设置,此处设置为-OUTPUT-
window = sg.Window('基于seq2seq的机器翻译系统', layout)
while True: # Event Loop
event, values = window.read()
print(event, values)
if event in (None, 'Exit'):
break
if event == 'Show':
text_input = values['-IN-']
hanju = translate(text_input)
# Update the "output" text element to be the value of "input" element
window['-OUTPUT-'].update(hanju)
#将输入的值更新在OUTPUT区域
window.close()