文章目录
前言
驱动程序加载成功的一个关键因素,就是内核能够为驱动程序分配足够的内存空间。这些控件一部分用于驱动程序必要的数据结构,另一部分用于数据交换。同时,内核也应该具有访问外部设备端口的能力。一般来说,外部设备被连接到内存空间或者I/O空间中。本章将对内外存设备的访问进行详细的介绍。
内存分配
本节主要介绍内存分配的一些函数,包括kmalloc()函数和vmalloc()函数等。在介绍完这两个重要的函数之后,将重点讲解后备高速缓存的内容,这些知识对于驱动开发来说非常重要,需要引起注意。
kmalloc函数
在C语言中,经常会遇到malloc()和free()这两个函数“冤家”。malloc()函数用来进行内存分配,free()函数用来释放内存。kmalloc()函数类似于malloc()函数,不同的是kmalloc()函数用于内核态的内存分配。kmalloc()函数是一个功能强大的函数,如果内存充足,这个函数将运行的非常快。
kmalloc()函数在物理内存中为程序分配一个连续的存储空间。这个存储空间的数据不会被清零,也就是保存内存中原有的数据,在使用的时候需要引起注意。kmalloc()函数运行很快。可以传递标志给它,不允许其在分配内存时阻塞。kmalloc()函数原型如下:
static inline void *kmalloc(size_t size, gfp_t flags)
kmalloc()函数的第一个参数是size,表示分配内存的大小。第2个参数是分配标志,可以通过这个标志控制kmalloc()函数的多种分配方式。和其他函数不同,kmalloc()函数的这两个参数非常重要,下面将对这两个参数详细的解释。
1.size参数
size参数涉及内存管理的问题,内存管理是Linux子系统中非常重要的一部分。Linux的内存管理方式限定了内存只能按照页面的大小进行内存分配。通常,页面大小为4K。如果使用kmalloc()函数为某个驱动程序分配4字节的内存空间,则Linux会返回一个页面4K的内存空间,这显然是一种内存浪费。
因为空间浪费的原因,kmalloc()函数与用户空间malloc()函数的实现完全不同。malloc()函数在堆中分配内存空间,分配的空间大小非常灵活,而kmalloc()函数分配内存空间的方法比较特殊,下面对这种方法进行简要的解释。
Linux内核对kmalloc()函数的处理方式是,先分配一系列不同大小的内存池,每个池中的内存大小是固定的。当分配内存时,将包含足够大的内存池中的内存传递给kmalloc()函数。在分配内存时,Linux内核只能分配预定义、固定大小的字节数。如果申请的内存大小不是2的整数倍,则会多申请一些内存,将大于申请内存的内存区块返回给请求者。
Linux内核为kmalloc()函数提供了大小为32字节、64字节、128字节、256字节、512字节、1024字节、2048字节、4096字节、8KB、16KB、32KB、64KB和128KB的内存池。所以程序员应该注意,kmalloc()函数最小能够分配32字节的内存,如果请求的内存小于32字节,那么也会返回32字节。kmalloc()函数能够分配的内存块的大小,也存在一个上限。为了代码的可移植性,这个上限一般是128KB。如果希望分配更多的内存,最好使用其他的内存分配方法。
2.flags参数
flags参数能够以多种方式控制kmalloc()函数的行为。最常用的申请内存的参数是GFP_KERNEL。使用这个参数运行调用它的进程在内存较少时进入睡眠,当内存充足时再分配页面。因此,使用GFP_KERNEL标志可能会引起阻塞,对于不允许阻塞的应用,应该使用其他的申请内存标志。在进程睡眠时,内核子系统会将缓冲区的内容写入磁盘,从而为睡眠的进程留出更多的空间。
在中断处理程序、等待队列等函数中不能使用GFP_KERNEL标志,因为这个标志可能会引起调用者的睡眠。当睡眠之后再唤醒,很多程序会出现错误。这种情况下可以使用GFP_ATOMIC标志,表示原子性的分配内存,也就是在分配内存的过程中不允许睡眠。为什么GFP_ATOMIC标志不会引起睡眠呢?这是因为内核为这种分配方式预留了一些内存空间,这些内存空间只有在kmalloc()函数传递标志为GFP_ATOMIC时,才会使用。在大多数情况下,GFP_ATOMIC标志的分配方式会成功,并即时返回。
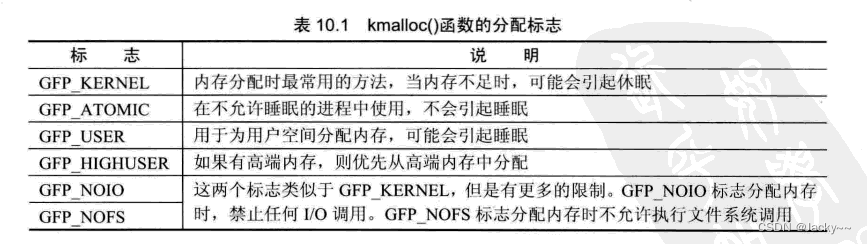
除了GFP_KERNEL和GFP_ATOMIC标志外,还会有一些其他的标志,但其他的标志并不常用。这些标志的意义和使用方法如下表。
vmalloc()函数
vmalloc()函数用来分配虚拟地址连续但是物理地址不连续的内存。这就是说,用vmalloc()函数分配的页在虚拟地址空间中是连续的,而在物理地址空间中是不连续的。这是因为如果需要分配200M的内存空间,而实际的物理内存中现在不存在一块连续的200M内存空间,但是内存有大量的内存碎片,其容量大于200M,那么就可以使用vmalloc()函数将不连续的物理地址空间映射层连续的虚拟地址空间。
从执行效率上来讲,vmalloc()函数的运行开销远远大于__get_free_pages()函数。因为vmalloc()函数会建立新的页表,将不连续的物理内存映射成连续的虚拟内存,所以开销比较大。另外,由于新页表的建立,vmalloc()函数也更浪费CPU时间,而且需要更多的内存来存放页表。一般来说,vmalloc()函数用来申请大量的内存,对于少量的内存,最好使用__get_free_pages()函数来申请。
1.vmalloc()函数申请和释放
vmalloc()函数定义在mm\vmalloc.c文件中,该函数的原型如下:
void *vmalloc(unsigned long size)
vmalloc()函数接收一个参数,size是分配连续内存的大小。如果函数执行成功,则返回虚拟地址连续的一块内存区域。为了释放内存,Linux内核也提供了一个释放由vmalloc()函数分配的内存,这个函数是vfree()函数,其代码如下:
void vfree(const void *addr)
2.vmalloc()函数举例
vmalloc()函数在功能上与kmalloc()函数不同,但在使用上基本相同。首先使用vmalloc()函数分配一个内存空间,并返回一个虚拟地址。内存分配是一项要求严格的任务,无论什么时候,都应该对返回值进行检测。当分配内存后,可以使用copy_from_user()对内存进行访问。也可以将返回的内存空间转换为一个结构体,像下面代码的12~15行一样使用vmalloc()分配的内存空间。在不需要使用内存时,可以使用20行的vfree()函数释放内存。在驱动程序中,使用vmalloc()函数的一个实例如xxx()函数所示:
static int xxx(...)
{
... /*省略代码*/
cpuid_entires - vmalloc(sizeof(struct kvm_cpuid_entry) * cpuid->nent );
if(!cpuid_entries)
goto out;
if(copy_from_user(cpuid_entries, entries, cpuid->nent * sizeof(struct kvm_cpuid_entry)))
goto out_free;
for(i=0; i< cpuid->nent; i++){
vcpu->arch.cpuid_emtries[i].eax = cpuid_entries[i].eax;
vcpu->arch.cpuid_emtries[i].ebx= cpuid_entries[i].ebx;
vcpu->arch.cpuid_emtries[i].ecx= cpuid_entries[i].ecx;
vcpu->arch.cpuid_emtries[i].edx= cpuid_entries[i].edx;
vcpu->arch.cpuid_emtries[i].index= 0;
}
.... /*省略代码*/
out_free:
vfree(cpuid_entries);
out:
return r;
}
后备高速缓存
在驱动程序中,会经常反复地分配很多同一大小的内存块,也会频繁的将这些内存块给释放掉。如果频繁的申请和释放内存,很容易产生内存碎片,使用内存池很好地解决了这个问题。在Linux中,为一些反复分配和释放的结构体预留了一些内存空间,使用内存池来管理,管理这种内存池的技术叫做slab分配器。这种内存叫做后备高速缓存。
slab分配器的相关函数定义在<linux/slab.h>文件中,使用后备高速缓存前,需要创建一个kernel_cache的结构体。
1.创建slab缓存函数
在使用slab缓存前,需要先调用kmem_cache_create()函数创建一块slab缓存,该函数的代码如下:
struct kmem_cache *kmem_cache_create(const char *name, size_t size, size_t align, unsigned long flags, void (*ctor)(void))
该函数创建一个新的后备高速缓存对象,这个缓存区中可以容纳指定个数的内存块。内存块的数目由参数size来指定。参数name表示该后备高速缓存对象的名字,以后可以使用name来表示使用那个后备高速缓存。
kmem_cache_create()函数的第3个参数align是后备高速缓存中第一个对象的偏移值,这个值一般情况下被置为0。第4个参数flage是一个位掩码,表示控制如何完成分配工作。第5个参数ctor是一个可选的函数,用来对加入后备高速缓存中的内存块进行初始化。
unsigned int sz = sizeof(struct bio) + extra_size;
slab = kmem_cache_create("DRIVER_NAME", sz, 0, SLAB_HWCACHE_ALIGN, NULL);
2.分配slab缓存函数
一旦调用kmem_cache_create()函数创建了后备高速缓存,就可以调用kmem_cache_alloc()函数创建内存块对象。kmem_cache_alloc()函数原型如下:
void *kmem_cache_alloc(struct kmem_cache *cachep, gfp_t flags)
该函数的第1个参数cachep是开始分配的后备高速缓存。第二个参数flags与传递给kmalloc()函数的参数相同,一般为GFP_KERNEL。
与kmem_cache_alloc()函数对应的释放函数是kmem_cache_free()函数,该函数释放一个内存块对象。其函数原型如下:
void kmem_cache_free(struct kmem_cache *cachep, void *objp)
3.销毁slab缓存函数
与kmem_cache_create()函数对应的释放函数是kmem_cache_destroy()函数,该函数释放一个后备高速缓存。其函数的原型如下:
void kmem_cache_destroy(struct kmem_cache *c)
该函数只有在后备高速缓存区中的所有内存块对象都调用kmem_cache_free()函数释放后,才能销毁后备高速缓存。
4.slab缓存举例
一个使用后备高速缓存的例子如下代码所示,这段代码创建了一个存放struct thread_info结构体的后备高速缓存,这个结构体表示线程结构体。在Linux中,涉及大量线程的创建和销毁,如果使用__get_free_pages()函数会造成内存的大量浪费,而且效率也比较低。对于线程结构体,在内核初始化阶段,就创建了一个名为thread_info的后备高速缓存,代码如下:
/*以下两行创建slab缓存*/
static struct kmem_cache *thread_info_cache;
/*声明一个struct kmem_cache的指针*/
thread_info_cache = kmem_cache_create("thread_info", THREAD_SIZE,
THREAD_SIZE, 0, NULL); /*创建一个后备高速缓存区*/
/*以下两行分配slab缓存*/
struct thread_info *ti; /*线程结构体指针*/
ti = kmem_cache_alloc(thread_info_cache, GFP_KERNEL); /*分配一个结构体*/
/*省略了使用slab缓存的函数*/
/*以下两行释放slab缓存*/
kmem_cache_free(thread_info_cache, ti); /*释放一个结构体*/
kmem_cache_destroy(thread_info_cache); /*销毁一个结构体*/
页面分配
在Linux中提供了一系列的函数用来分配和释放页面。当一个驱动程序进程需要申请内存时,内核会根据需要分配请求的页面数给申请者。当驱动程序不需要申请内存时,必须释放申请的页面数,以防止内存泄漏。本节将对页面的分配方法进行详细的讲述,这些知识对驱动程序开发非常重要。
内存分配
Linux内核内存管理子系统提供了一系列函数用来进行内存分配和释放。为了管理方便,Linux中是以页为单位进行内存分配的。在32为机器上,一般一页的大小为4KB;在46位的机器上,一般一页的大小为8KB,具体根据平台而定。当驱动程序的一个进程申请空间时,内存管理子系统会分配所请求的页数给驱动程序。如果驱动程序不需要内存时,也可以释放内存,若将内存归还给内核为其他程序所用。下面介绍内存管理子系统提供了那些函数进行内存的分配和释放。
1.内存分配函数的分类
从内存管理子系统提供的内存管理函数的返回值将函数分为两类:第一类函数向内存申请者返回一个struct page结构的指针,指向内核分配给申请者的页面。第二类函数返回一个32位的虚拟地址,该地址是分配的页面的虚拟首地址。虚拟地址和物理地址在大多数计算机组成和原理课上都有讲解,希望引起读者的注意。
其次,可以根据函数返回的页面数目对函数进行分类:第一类函数只返回一个页面,第二类函数可以返回多个页面,页面的数目可以由驱动程序开发人员自己指定。内存分配函数分类如下图所示:

2.alloc_page()和alloc_pages()函数
返回struct page结构体函数主要有两个:alloc_page()函数和alloc_pages()函数。这两个函数定义在/include/linux/gfp.h文件中。alloc_page()函数分配一个页面,alloc_pages()函数根据用户需要分配多个页面。需要注意的是,这两个函数都返回一个struct page结构体的指针。这两个函数的代码如下:
/*alloc_page()函数分配一个页面,调用alloc_pages()实现分配一个页面的功能*/
#define alloc_page(gfp_mask) alloc_pages(gfp_mask, 0)
/*alloc_pages()函数分配多个页面,调用alloc_pages_node()实现分配一个页面的功能*/
#define alloc_pages(gfp_mask, order) \
alloc_pages_node(numa_node_id(), gfp_mask, order)
/*该函数是真正的内存分配函数*/
static inline struct page *alloc_pages_node(int nid, gfp_t gfp_mask, unsigned int order)
{
if(unlikely(order >= MAX_ORDER))
return NULL;
if(nid < 0)
nid = numa_node_id();
return __alloc_pages(gfp_mask, order, node_zonelist(nid, gfp_mask));
}
下面对这些函数进行详细的解释。
alloc_pages()函数功能是分配多个页面。第一个参数表示分配内存的标志。这个标志与kmalloc()函数的标志相同。准确的说,kmalloc()函数是由alloc_pages()函数实现的,所以它们有相同的内存分配标志。第二个参数order表示分配页面的个数,这些页面是连续的。页面的个数由2的order次方来表示,例如如果只分配一个页面,order的值应该为0。alloc_pages()函数调用如果成功,会返回指向第一个页面的struct page结构体的指针;如果分配失败,则返回一个NULL值。任何时候内存分配都有可能失败,所以应该在内存分配之后检查其返回值是否合法。alloc_page()函数定义在2行,其只分配一个页面。这个宏只接收一个gfp_mask参数,表示内存分配的标志。默认情况下order被设置为0,表示函数将分配2的0次方等于1个物理页面给申请进程。
3.__get_free_page()和__get_free_pages()函数
第二类函数执行后,返回申请的页面的第一个页面虚拟地址。如果返回多个页面,则只返回第一个页面的虚拟地址。__get_free_page()函数和__get_free_pages()函数就返回一个页面虚拟地址。其中__get_free_page()函数只返回一个页面,__get_free_pages()函数则返回多个页面。这两个函数或宏的代码如下:
#define __get_free_page(gfp_mask) \
__get_free_pages((gfp_mask), 0)
__get_free_page宏最终调用__get_free_pages()函数实现的,在调用__get_free_pages()函数时将order的值直接赋为0,这样就只返回一个页面。__get_free_pages()函数不仅可以分配多个连续的页面,而且可以分配一个页面,其代码如下:
unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order)
{
struct page *page;
page = alloc_pages(gfp_mask, order);
if(!page)
return 0;
return (unsigned long)page_address(page);
}
下面对该函数进行详细的解释:
__get_free_pages()函数接收两个参数。第一个参数与kmalloc()函数的标志是一样的,第二个函数用来表示申请多少页的内存,页数的计算公式为:页数=2的order次方。如果要分配一个页面,那么只需要order等于0就可以了。- 3行,定义了一个
struct page的指针。 - 4行,调用了
alloc_pages()函数分配了2的order次方页的内存空间。 - 5、6行,如果内存不足分配失败,返回0。
- 7行,调用
page_address()函数将物理地址转换为虚拟地址。
4.内存释放函数
当不再需要内存时,需要将内存还给内存管理系统,否则可能会造成资源泄露。Linux提供了一个函数用来释放内存。在释放内存时,应该给释放函数传递正确的struct page指针或者地址,都在会使内存错误的释放,导致系统崩溃。内存释放函数或宏的定义如下:
#define __free_page(page) __free_pages((page), 0)
#define __free_pages(addr) free_pages((addr), 0
这两个函数的代码如下:
void free_pages(unsigned long addr, unsigned int order)
{
if(addr != 0){
VM_BUG_ON(!virt_addr_valid((void *)addr));
__free_pages(virt_to_page((void *)addr), order);
}
}
void __free_pages(struct page *page, unsigned int order)
{
if(put_page_testzero(page)){
if(order == 0)
free_hot_page(page);
else
__free_pages_ok(page, order);
}
}
从上面的代码可以看出,free_pages()函数是调用__free_pages()函数完成内存释放的。free_pages()函数的第一个参数是指向内存页面的虚拟地址,第二个参数是需要释放的页面数目,应该和分配页面时的数目相同。
物理地址和虚拟地址之间的转换
在内存分配的大多数函数中,基本都涉及物理地址和虚拟地址之间的转换。使用virt_to_phys()函数可以将内核虚拟地址转换为物理地址。virt_to_phys()函数定义如下:
#define __pa(x) ((x) - PAGE_OFFSET)
static inline unsigned long virt_to_phys(volatile void *address)
{
return __pa((void *)address);
}
virt_to_phys()函数调用了__pa宏,__pa宏会将虚拟地址address减去PAGE_OFFSET,通常在32位平台上定义为3GB。
与virt_to_phys()函数对应的函数是phys_to_virt(),这个函数将物理地址转化为内核虚拟地址。phys_to_virt()函数的定义如下:
#define __va(x) ((x) + PAGE_OFFSET)
static inline void * phys_to_virt(unsigned long address)
{
return __va(address);
}
phys_to_virt()函数调用了__va宏,__va宏会将物理地址address加上PAGE_OFFSET,通常在32为平台上定义为3GB。
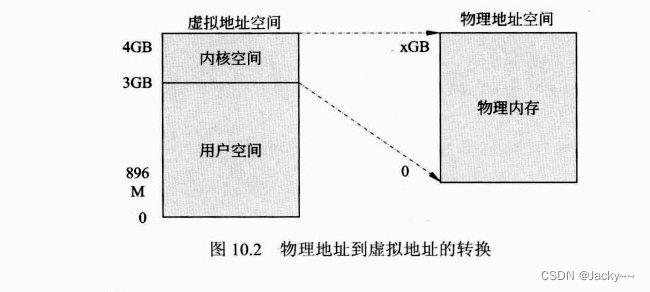
Linux中,物理地址和虚拟地址的关系如下图。在32位计算机中,最大的虚拟地址空间大小是4GB。0~3GB表示用户空间,PAGE_OFFSET被定义为3GB,就是用户空间和内核空间的分界点。Linux内核中,使用3GB~4GB的内核空间来映射实际的物理地址。物理内存可能大于1GB的内核空间,甚至可能大很多。目前,主流的计算机物理内存在4GB左右。这种情况下,Linux使用一种非线性的映射方法,用1GB大小的内核空间来映射有可能大于1GB的物理内存。
设备I/O端口的访问
设备有一组外部寄存器用来存储和控制设备的状态。存储设备状态的寄存器叫做数据寄存器;控制设备状态的寄存器叫做控制寄存器。这些寄存器可能位于内存空间,也可能位于I/O空间,本节将介绍这些空间的寄存器访问方法。
Linux I/O端口读写函数
设备内部集成了一些寄存器,程序可以通过寄存器来控制设备。大部分外部设备都有多个寄存器,例如看门狗控制寄存器(WTCON)、数据寄存器(WTDAT)和计数寄存器(WTCNT)等;有如IIC设备也有4个寄存器来完成所有IIC操作,这些寄存器是IICCON、IICSTAT、IICADD、IICCDS。
根据设备需要完成的功能,可以将外部设备连接到内存地址空间上或者连接到I/O地址空间。无论是内存地址空间还是I/O地址空间,这些寄存器的访问都是连续的。一般台式机在设计时,因为内存地址空间比较紧张,所以一般将外部设备连接到I/O地址空间上。而对于嵌入式设备,内存一般是64M或者128M,大多数嵌入式处理器支持1G的内存空间,所以可以将外部设备连接到多余的内存空间上。
在硬件设计上,内存地址空间和I/O地址空间的区别不是很大,都是由地址总线、控制总线和数据总线连接到CPU上的。对于非嵌入式产品的大型设备使用的CPU,一般将内存地址和I/O地址空间分开,对其进行单独访问,并提供相应的读写指令。例如在x86平台上,对I/O地址空间的访问,就是使用in、out指令。
对于简单的嵌入式设备的CPU,一般将I/O地址空间合并在内存地址空间中。ARM处理器可以访问1G的内存地址空间,可以将内存挂接在低地址空间,将外部设备挂接在未使用的内存地址空间中。可以使用与访问内存相同的方法来访问外部设备。
I/O内存读写
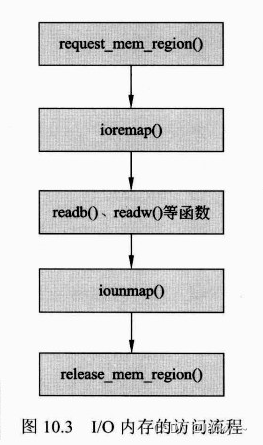
可以将I/O端口映射到I/O内存空间来访问。如下图所示是I/O内存的访问流程,在设备驱动模块的加载函数或者open()函数中可以调用request_mem_region()函数来申请资源。使用ioremap()函数将I/O端口所在的物理地址映射到虚拟地址上,之后,就可以调用readb()、readw()、readl()等函数读写寄存器中的内容了。当不再使用I/O内存时,可以使用ioummap()函数释放物理地址到虚拟地址的映射。最后,使用release_mem_region()函数释放申请的资源。
1.申请I/O内存
在使用形如readb()、readw()、readl()等函数访问I/O内存前,首先需要分配一个I/O内存区域。完成这个功能的函数是request_mem_region(),该函数原型如下:
#define request_mem_region(start, n , name)
__request_region(&iomem_resource, (start), (n), (name), 0)
request_mem_region被定义为一个宏,内部调用了__request_region()函数。宏request_mem_region带3个参数,第一个参数start是物理地址的开始区域,第2个参数n是需要分配内存的字节长度,第3个参数name是这个资源的名字。如果函数成功,返回一个资源指针;如果函数失败,则返回一个NULL值。在模块卸载函数中,如果不再使用内存资源,可以使用release_region()宏释放内存资源,该函数的原型如下:
#define release_region(start, n) __release_region(&ioport_resource, (start), (n))
2.物理地址到虚拟地址的映射函数
在使用读写I/O内存的函数之前,需要使用ioremap()函数,将外部设备的I/O端口物理地址映射到虚拟地址。ioremap()函数的原型如下:
void __iomem *ioremap(unsigned long phys_addr, unsigned long size)
ioremap()函数接收一个物理地址和一个整个I/O端口的大小,返回一个虚拟地址,这个虚拟地址对应一个size大小的物理地址空间。使用ioremap()函数后,物理地址被映射到虚拟地址空间中,所以读写I/O端口中的数据就像读取内存中的数据一样简单。通过ioremap()函数申请的虚拟地址,需要使用iounmap()函数来释放,该函数的原型如下:
void iounmap(volatile void __iomem *addr)
iounmap()函数接收ioremap()函数申请的虚拟地址作为参数,并取消物理地址到虚拟地址的映射。虽然ioremap()函数是返回的虚拟地址,但是不能直接当作指针使用。
3.I/O内存的读写
内核开发者准备了一组函数用来完成虚拟地址的读写,这些函数如下:
ioread()函数和iowrite8()函数用来读写8位I/O内存。
unsigned int ioread8(void __iomem *addr)
void iowrite8(u8 b, void __iomem *addr)
ioread16()函数和iowrite16()函数用来读写16位I/O内存。
unsigned int ioread16(void __iomem *addr)
void iowrite16(u16 b, void __iomem *addr)
ioread32()函数和iowrite()32函数用来读写32位I/O内存。
unsigned int ioread32(void __iomem *addr)
void iowrite32(u32 b, void __iomem *addr)
- 对于大存储的设备,可以通过以上函数重复读写多次来完成大量数据的传送。Linux内核也提供了一组函数用来读写一系列的值,这些函数是上面函数的重复调用,函数原型如下:
/*以下3个函数读取一串I/O内存的值*/
#define ioread8_rep(p,d,c) _raw_readsb(p,d,c)
#define ioread16_rep(p,d,c) _raw_readsw(p,d,c)
#define ioread32_rep(p,d,c) _raw_readsl(p,d,c)
/*以下3个函数写入一串I/O内存的值*/
#define iowrite8_rep(p,s,c) __raw_writesb(p,s,c)
#define iowrite16_rep(p,s,c) __raw_writesw(p,s,c)
#define iowrite32_rep(p,s,c) __raw_writesl(p,s,c)
在阅读Linux内核源代码时,会发现有些驱动程序使用readb()、readw()、readl()等较古老的函数。为了保证驱动程序的兼容性,内核仍然使用这些函数,但是在新的驱动代码中鼓励使用前面提到的函数。主要原因是新函数在运行时,会执行类型检查,从而保证了驱动程序的安全性。旧的函数或宏原型如下:
u8 readb(const volatile void __iomem *addr)
void writeb(u8 b, volatile void __iomem *addr)
u8 readw(const volatile void __iomem *addr)
void writew(u16 b, volatile void __iomem *addr)
u8 readl(const volatile void __iomem *addr)
void writel(u32 b, volatile void __iomem *addr)
readb()函数与ioread8()函数功能相同;writeb()函数和iowrite8()函数功能相同;其他同理。
4.I/O内存的读写举例
一个使用I/O内存的完成实例可以从rtc实时时钟驱动程序中看到。在rtc实时时钟驱动程序的探测函数s3c_rtc_probe()中。首先调用了platform_get_resource()函数从平台设备中获得I/O端口的定义,主要是I/O端口的物理地址。然后先后使用request_mem_region()和ioremap()函数将I/O端口的物理地址转换为虚拟地址,并存储在一个全局变量s3c_rtc_base中,这样就可以通过这个变量访问rtc寄存器的值了。s3c_rtc_probe()函数的代码如下:
static void __iomem *s3c_rtc_base; /*定义一个全局变量,存放虚拟内存地址*/
static int __devint s3c_rtc_probe(struct platform_device *pdev)
{
... /*省略部分代码*/
/*从平台设备中获得I/O端口的定义*/
res = platform_get_resource(pdev, IORESOURCE_MEM, 0);
if(res == NULL){
dev_err(&pdev->dev, "failed to get memory region resource\n")
return -ENPENT;
}
s3c_rtc_mem = request_mem_region(res->start,
res->end - res->start+1,
pdev->name); /*申请内存资源*/
if(s3c_rtc_mem == NULL){
/*如果有错误,则跳转到错误处理代码中*/
dev_err(&pdev->dev, "failed to reserve memory region\n");
ret = -ENOENT;
goto err_nores;
}
s3c_rtc_base = ioremap(res->start, res->end - res->start + 1);
/*申请物理地址映射成虚拟地址*/
if(s3c_rtc_base == NULL){
/*如果错误,则跳转到错误处理代码中*/
dev_err(&pdev->dev, "failed ioremap()\n");
ret = -EINVAL;
goto err_nomap;
}
... /*省略部分代码*/
err_nomap:
iounmap(s3c_rtc_base); /*如果错误,则取消映射*/
err_nortc:
release_resource(s3c_rtc_mem); /*如果错误,则释放资源*/
err_norse:
return ret;
}
使用request_mem_region()和ioremap()函数将I/O端口的物理地址转换为虚拟地址,这样就可以使用readb()和writeb()函数向I/O内存中写入数据了。rtc实时时钟的s3c_rtc_setpie()函数就使用了者两个函数向S3C2410_TICNT中写入数据。s3c_rtc_setpie()函数的源代码如下:
static int s3c_rtc_setpie(struct device *dev, int enable)
{
unsigned int tmp;
pr_debug("%s:pie=%d\n",__func__, enabled);
spin_lock_irq(&s3c_rtc_pie_lock);
tmp = readb(s3c_rtc_base + S3Cs410_TICNT) & ~S3C2410_TICNT_ENABLE;
if(enabled)
tmp |= S3C2410_TICNT_ENABLE;
writeb(tmp, s3c_rtc_base + S3C2410_TICNT);
spin_unlock_irq(&s3c_rtc_pie_lock);
return 0;
}
当不再使用I/O内存时,可以使用iounmap()函数释放物理地址到虚拟地址的映射。最后,使用release_mem_region()函数释放申请的资源。rtc实时时钟的s3c_rtc_remove()函数就使用iounmap()和release_mem_region()函数释放申请的内存空间。s3c_rtc_remove()函数代码如下:
static int __devexit s3c_rtc_remove(struct platform_device *dev)
{
struct rtc_device *rtc = platform_get_drvdata(dev);
platform_set_drvdata(dev, NULL);
rtc_device_unregister(&dev->dev, 0);
s3c_rtc_setpie(0);
iounmap(s3c_rtc_base);
release_resource(s3c_rtc_mem);
kfree(s3c_rtc_mem);
return 0;
}
使用I/O端口
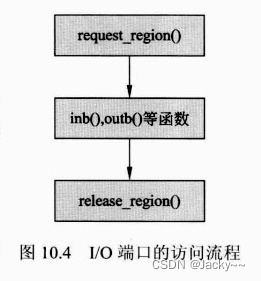
对于使用I/O地址空间的外部设备,需要通过I/O端口和设备传输数据。在访问I/O端口前,需要向内核申请I/O端口使用的资源。如下图所示,在设备驱动模块的加载函数或者open()函数中可以调用request_region()函数请求I/O端口资源;然后使用inb()、outb()、intw()、outw()等函数来读写外部设备的I/O端口;最后,在设备驱动程序的模块卸载函数或者release()函数中,释放申请的I/O内存资源。
1.申请和释放I/O端口
如果要访问I/O端口,那么就需要先申请一个内存资源来对应I/O端口,在此之前,不能对I/O端口进行操作。Linux内核提供了一个函数来申请I/O端口的资源,只有申请了该端口资源之后,才能使用该端口,这个函数是request_region(),函数代码如下:
#define request_region(start,n,name) __request_region(&ioport_resource,
(start), (n), (name), 0)
struct resource * __request_region(struct resource *parent,
resource_size_t start, resource_size_t n,
const char *name, int flags)
request_region()函数是一个宏,由__request_region()函数来实现。这个宏接收3个参数,第一个参数start是要使用的I/O端口的地址,第2个参数表示从start开始的n个端口,第3个参数是设备的名字。如果分配成功,那么request_region()函数会返回一个非NULL值;如果失败,则返回NULL值,此时,不能使用这些端口。
__request_region()函数用来申请资源,这个函数有5个参数。第1个参数是资源的父资源,这样所有系统的资源被连接成一棵资源树,方便内核的管理。第2个参数是I/O端口的开始地址。第3个参数表示需要映射多少个I/O端口。第4个参数是设备的名字。第5个参数是资源的标志。
如果不再使用I/O端口,需要在适当的时候释放I/O端口,这个过程一般在模块的卸载函数中,释放I/O端口的宏是release_region(),其代码如下:
#define release_region(start, n) __release_region(&ioport_resource, (start), (n))
void __release_region(struct resource *parent, resource_size_t start, reosurce_size_t n)
release_region是一个宏,由__release_region()函数来实现。第一个参数start是要使用的I/O端口的地址,第2个参数表示从start开始的n个端口。
2.读写I/O端口
当驱动程序申请了I/O相关的资源后,可以对这些端口进行数据的读取或写入。对不同功能的寄存器写入不同的值,就能够使外部设备完成相应的工作。一般来说,大多数外部设备将端口的大小设为8位、16位或者32位。不同大小的端口需要使用不同的读取和写入函数,不能将这些函数混淆使用。如果用一个读取8位端口的函数读一个16位的端口,会导致错误。读取端口数据的函数如下所示。
inb()和outb()函数是读写8位端口的函数。inb()函数第一个参数是端口号,其是一个无符号的16位端口号。outb()函数用来向端口写入一个8位的数据,第1个参数是要写入的8位数据,第2个参数是I/O端口。
static inline u8 inb(u16 port)
static inline void outb(u8 v, u16 port)
inw()和outw()函数是读写16位端口的函数。inb()函数第一个参数是端口号,其是一个无符号的16位端口号。outw()函数用来向端口写入一个16位的数据,第1个参数是要写入的16位数据,第2个参数是I/O端口。
static inline u6 inw(u16 port)
static inline void outw(u16 v, u16 port)
inl()和outl()函数是读写32位端口的函数。inl()函数第一个参数是端口号,其是一个无符号的32位端口号。outl()函数用来向端口写入一个32位的数据,第1个参数是要写入的32位数据,第2个参数是I/O端口。
static inline u8 inl(u32 port)
static inline void outl(u32 v, u16 port)
上面的函数基本是一次传送1、2和4字节。在某些处理器上也实现了一次传输一串数据的功能,串中的基本单位可以是字节、字和双字。串传输比单独的字节传输速度要快很多,所以对于处理需要传输大量数据时非常有用。一些串传输的I/O函数原型如下:
void insb(unsigned long addr, void *dst, unsigned long count)
void outsb(unsigned long addr, void *src, unsigned long count)
insb()函数从addr地址向dst地址读取count个字节,outsb()函数从addr地址向src地址写入count个字节。
void insw(unsigned long addr, void *dst, unsigned long count)
void outsw(unsigned long addr, void *src, unsigned long count)
insw()函数从addr地址读取countx2个字节,outsw()函数从addr地址向dst地址写入countx2个字节。
void insl(unsigned long addr, void *dst, unsigned long count)
void outsl(unsigned long addr, void *src, unsigned long count)
insw()函数从addr地址读取countx4个字节,outsw()函数从addr地址向dst地址写入countx4个字节。
需要注意的是,串传输函数直接从端口中读出或者写入指定长度的数据。因此,如果当外部设备和主机之间有不同的字节序时,则会导致意外的错误。例如主机使用小端字节序,外部设备使用大端字节序,在进行数据读写时,应该交换字节序,使彼此互相理解。
小结
外部设备可以处于内存空间或者I/O空间中,对于嵌入式产品来说,一般外部设备处于内存空间中。本章对外部设备处于内存空间和I/O空间的情况分别进行了讲解。在Linux中,为了方便编写驱动程序,对内存空间和I/O空间的访问提供了一套统一的方法,这个方法是“申请资源->映射内存空间->访问内存->取消映射->释放资源”。
Linux中使用了后备高速缓存来频繁地分配和释放同一种对象,这样不但减少了内存碎片的出现,而且还提高了系统的性能,为驱动程序的高效性打下基础。
Linux中提供了一套分配和释放页面的函数,这些函数可以根据需要分配物理连续或者不连续的内存,并将其映射到虚拟地址空间中,然后对其进行访问。