目录
背景
深度学习三巨头 :2019年3月27日,ACM(美国计算机协会)宣布,有“深度学习三巨头”之称Yoshua Bengio(约书亚·本吉奥,法国巴黎)、Yann LeCun(杨立昆,法国人)、Geoffrey Hinton(杰弗里·辛顿)共同获得了2018年的图灵奖
“深度学习三巨头”发表的相关论文:https://github.com/longpeng2008/Awesome_DNN_Researchers
深度学习/机器学习/人工智能,计算机视觉/机器视觉/图像处理…的关系
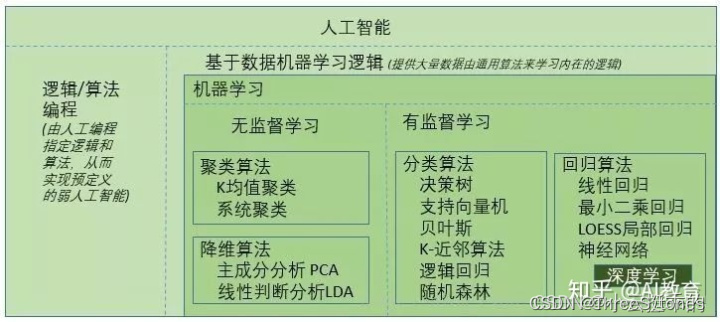
图不太准确,深度学习也可用于无监督学习。
人工智能、机器学习、深度学习是科学(或学科),机器视觉、图像处理是科技技术(或应用),计算机视觉可称为科学也可称为技术。
人工智能(Artificial Intelligence)是计算机科学的一个分支。它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器,该领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。人工智能是包括十分广泛的科学,它由不同的领域组成,如机器学习,计算机视觉等等。人工智能研究的一个主要目标是使机器能够胜任一些通常需要人类智能才能完成的复杂工作。
机器学习(Machine Learning)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。它是人工智能核心,是使计算机具有智能的根本途径。
传统机器学习方法大致可以包括:支持向量机,决策树,随机森林,隐马尔可夫模型,主成分分析等等。 在机器学习里面,不同的方法差别还是有点大的。 比如,SVM等是判别模型,隐马尔科夫等是生成模型;主成分分析等是无监督学习,随机森林等是有监督学习。
深度学习(DL, Deep Learning)是机器学习(ML, Machine Learning)领域中一个新的研究方向,它被引入机器学习使其更接近于最初的目标——人工智能(AI, Artificial Intelligence)。
深度学习是学习样本数据的内在规律和表示层次,这些学习过程中获得的信息对诸如文字,图像和声音等数据的解释有很大的帮助。它的最终目标是让机器能够像人一样具有分析学习能力,能够识别文字、图像和声音等数据。 深度学习是一个复杂的机器学习算法,在语音和图像识别方面取得的效果,远远超过先前相关技术。
深度学习在搜索技术,数据挖掘,机器学习,机器翻译,自然语言处理,多媒体学习,语音,推荐和个性化技术,以及其他相关领域都取得了很多成果。深度学习使机器模仿视听和思考等人类的活动,解决了很多复杂的模式识别难题,使得人工智能相关技术取得了很大进步。
深度学习:一种实现机器学习的技术。深度学习本来并不是一种独立的学习方法,其本身也会用到有监督和无监督的学习方法来训练深度神经网络。但由于近几年该领域发展迅猛,一些特有的学习手段相继被提出(如残差网络),因此越来越多的人将其单独看作一种学习的方法。
计算机视觉(Computer Vision)是一门综合性的学科。计算机视觉是使用计算机及相关设备对生物视觉的一种模拟。计算机视觉是一门研究如何使机器“看”的科学,更进一步的说,就是是指用摄影机和电脑代替人眼对目标进行识别、跟踪和测量等机器视觉,并进一步做图形处理,使电脑处理成为更适合人眼观察或传送给仪器检测的图像。
机器视觉(machine vision)是一种综合技术,包括图像处理。机器视觉是人工智能正在快速发展的一个分支。简单说来,机器视觉就是用机器代替人眼来做测量和判断。机器视觉系统是通过机器视觉产品(即图像摄取装置,分CMOS和CCD两种)将被摄取目标转换成图像信号,传送给专用的图像处理系统,得到被摄目标的形态信息,根据像素分布和亮度、颜色等信息,转变成数字化信号;图像系统对这些信号进行各种运算来抽取目标的特征,进而根据判别的结果来控制现场的设备动作。
图像处理(image processing),用计算机对图像进行分析,以达到所需结果的技术。又称影像处理。图像处理一般指数字图像处理。数字图像是指用工业相机、摄像机、扫描仪等设备经过拍摄得到的一个大的二维数组,该数组的元素称为像素,其值称为灰度值。图像处理技术一般包括图像压缩,增强和复原,匹配、描述和识别3个部分。
关系:
计算机视觉为机器视觉提供理论和算法基础,机器视觉是计算机视觉的部分工程实现。计算机视觉的理论比机器视觉多。而且两者应用场景不同。机器视觉偏向工业生产的,计算机视觉更偏向计算机获得图像后的分析
计算机视觉,主要是对质的分析,比如分类识别,这是一个杯子那是一条狗。或者做身份确认,比如人脸识别,车牌识别。或者做行为分析,比如人员入侵,徘徊,遗留物,人群聚集等。深度学习比较适合计算机视觉。而且光线,距离,角度等前提条件,往往是动态的,所以准确度要求一般来说要低。
机器视觉,主要侧重对量的分析,比如通过视觉去测量一个零件的直径,一般来说,对准确度要求很高。一般机器视觉的分辨率远高于计算机视觉,而且往往要求实时,所以处理速度很关键。机器视觉一般用商用库halcon或者VisionPro软件,而计算机视觉一般用opencv库。
现在对于计算机视觉和机器视觉的区分似乎越来越不明显。
不能简单地说深度学习是机器学习的一个进阶就完事儿了,一般说机器学习解决结构化的数据,深度学习解决非结构化的数据。
结构化的数据:https://worktile.com/kb/ask/4895.html、https://baike.baidu.com/item/结构化数据/5910594?fr=aladdin
基于深度学习的图像处理方法。用机器学习的方法去解决图像处理问题叫做机器视觉,目前主流的方式是深度学习。
机器视觉是深度学习的一类应用,机器学习是包括深度学习在内的一个学科,而图像处理则主要应用机器视觉的方法。
科学解决理论问题(是什么、为什么),技术解决实际问题(做什么,怎么做)。
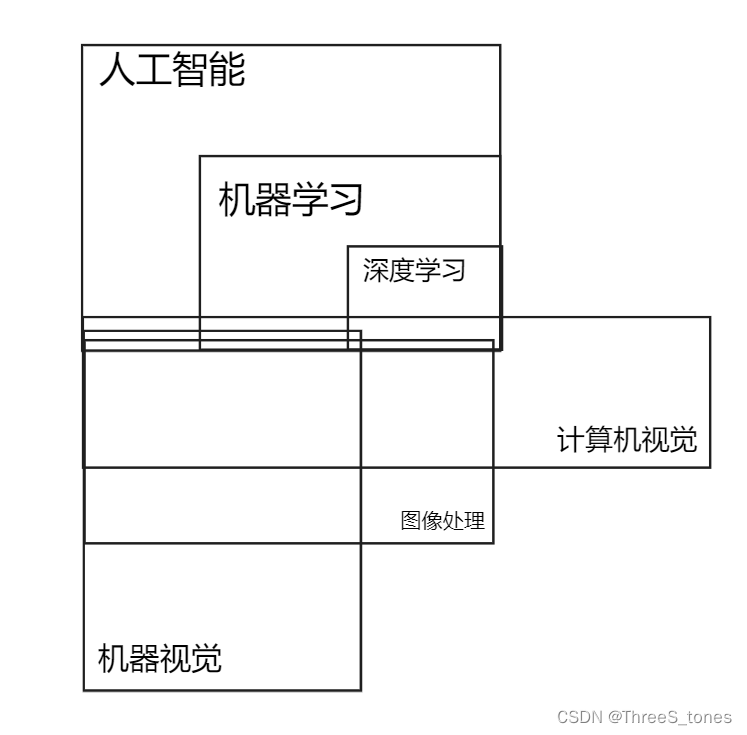
参考:看懂人工智能、机器学习、深度学习与神经网络之间的区别与关系
监督学习、无监督学习、半监督学习
监督学习:利用一组已知类别的样本调整分类器的参数,使其达到所要求性能的 过程。
https://baike.baidu.com/item/监督学习/9820109?fr=aladdin
监督学习方法有向量机(Support Vector Machine, SVM)、决策树、随机森林、神经网络、线性回归、KNN(K最邻近算法,可用于回归、分类或降维)、朴素贝叶斯算法。
K 近邻( K-nearest neighbor,KNN) 是在某一范围内找到与样本相似的目标。
SVM 是一种经典的二分类的广义线性分类器。
理解决策树:https://zhuanlan.zhihu.com/p/197476119
根据类别未知(没有被标记)的训练样本解决模式识别中的各种问题,称之为无监督学习。该方法利用训练样本的数据分布或样本间的关系将样本划分到不同的聚类簇或给出样本对应的低维结构。
无监督学习方法主要有主成分分析法(PCA)、K-means 、异常检测法、自编码算法、深度信念网络、赫比学习法、生成式对抗网络、自组织映射网络。
https://baike.baidu.com/item/无监督学习/810193?fr=aladdin
半监督学习使用大量的未标记数据,以及同时使用标记数据,来进行模式识别工作。当使用半监督学习时,将会要求尽量少的人员来从事工作,同时,又能够带来比较高的准确性。
https://baike.baidu.com/item/半监督学习/9075473?fr=aladdin
图像分类、目标检测、语义分割、实例分割
基础知识
激活函数
激活函数的作用
激活函数是神经网络中的一个重要组成部分,它的作用有以下几个方面:
-
引入非线性:激活函数是神经网络中引入非线性的主要手段,因为线性函数的组合仍然是线性的。通过使用非线性激活函数,神经网络可以学习到更加复杂的函数,从而提高模型的表达能力,更好地适应复杂的数据集。
-
归一化输出:激活函数可以将神经元的输出映射到一个特定的范围内,例如[0,1]或[-1,1],这样可以使得神经元的输出具有统一的尺度,方便进行比较和处理。
-
激活神经元:激活函数的名字来源于它的主要作用,即激活神经元。通过设置适当的激活函数,可以使神经元在输入信号达到一定阈值时输出1,否则输出0,从而实现对输入信号的分类。
-
防止梯度消失:激活函数还可以帮助解决梯度消失问题。在反向传播算法中,梯度需要不断传递回去,如果激活函数的导数在某些区域非常小,那么反向传播算法将无法有效地更新权重。通过使用一些具有恰当梯度的激活函数,例如ReLU函数,可以使得神经网络更容易训练和优化。
综上所述,激活函数在神经网络中扮演着关键的角色,它能够引入非线性、归一化输出、激活神经元和防止梯度消失等作用,对于神经网络的性能和训练效果有着重要的影响。
激活函数一般是非线性的
神经网络的激活函数必须是非线性的,因为如果使用线性函数作为激活函数,多个神经元的输出将只是输入的线性组合,再加上偏置项,这样就无法表达出非线性的特征,从而限制了神经网络的拟合能力。因此,使用非线性的激活函数可以使神经网络具有更强的表达能力,从而能够处理更加复杂的问题。
常见的激活函数
-
Sigmoid函数:Sigmoid函数将输入映射到0到1之间,具有平滑的非线性特性。函数的取值范围在0到1之间,梯度在输入为0时最大,但是对于大于或小于一定范围的输入,Sigmoid函数的梯度会趋近于0,这会导致梯度消失的问题。
-
ReLU函数:ReLU函数在输入为正数时输出该值,否则输出0。函数的取值范围为0到正无穷,具有简单的非线性特性,同时避免了梯度消失的问题。
-
Tanh函数:Tanh函数将输入映射到-1到1之间,具有平滑的非线性特性,但是与Sigmoid函数一样,也会存在梯度消失问题。
-
Leaky ReLU函数:Leaky ReLU函数在输入为负数时输出一个小的斜率,避免了ReLU函数的死神经元问题。
选择适当的激活函数可以显著影响神经网络的性能,通常需要根据具体的任务和数据集进行选择。例如,对于二元分类任务,可以使用Sigmoid函数;对于多元分类任务,可以使用Softmax函数;对于任何类型的回归问题,可以使用ReLU或Leaky ReLU函数。此外,激活函数的选择还应考虑到梯度消失和爆炸等问题,以及计算效率和数值稳定性等方面的因素。
- 对输入标准化之后梯度下降收敛更快,标准化就是对输入的x每行除以一行中元素的平方和开根号。
- 基本不使用sigmoid函数作为激活函数了,因为tanh函数基本都比sigmoid函数好,例外是二分类问题。经验法则:二分类问题或输出为0、1的问题用sigmoid函数,其他都用relu或leaky relu函数。因为sigmoid和tanh在z特别大或特别小的时候,导数的梯度或斜率会变得特别小,导致梯度下降的速度很慢。
- 如果只是用线性激活函数,那么神经网络知识把输入线性组合再输出,这时不论用多少隐藏层都没有效果,模型的复杂度与没有用任何隐藏层的标准逻辑回归是一样的。通常隐藏层都不用线性激活函数,唯一可以用线性激活函数的层是输出层。
- 随机初始化:训练神经网络的时候,要把权重随机初始化,否则所有隐藏单元将进行同样的计算,结果也相同,输出的权值也相同,经过多次迭代,所有隐藏层计算相同的函数,就无意义了,除非只有一个隐藏层。参数b没有对称破坏问题,所以不用随机初始化,直接使用0初始化就行。
- 为什么用深层的网络(隐藏层数量)而不是更大的网络(隐藏单元数多)更有效?
电路中的理论解释神经网络,它和你用电路元件计算哪些函数有分不开的联系,根据不同的基本逻辑门,譬如与门、或门、非门,同样一个函数(或表达式)可以用相对较小、但很深的神经网络计算,就像把基本逻辑门串并联比较深,但如果不能用很多隐藏层的话,就需要指数增长的单元数量才能达到同样的计算效果。所以很多数学函数用深度网络计算比浅层网络要容易得多。
训练集/验证集/测试集,交叉验证…
吴恩达:
- 训练集参与训练,模型从训练集中学习经验,从而不断减小训练误差。
- 验证集的目的就是验证不同的算法,检验哪种算法更有效。
- 测试集的目的是对最终所选定的神经网络系统做出无偏估计。
为了方便理解,人们常常把这三种数据集类比成学生的课本、作业和期末考:
训练集——课本习题,学生根据课本里的内容来掌握知识
验证集——作业题,通过作业可以知道不同学生实时的学习情况、进步的速度快慢
测试集——考试题,考的题是平常都没有见过,考察学生举一反三的能力
训练集
参与训练,普通参数用训练集训练,求出它们的梯度,不断更新参数来减小成本函数值。
指的是训练 模型中的可训练参数(如w,b)。
验证集(开发集)
不参与训练,通常用于模型选择和调整超参数,根据几组模型验证集上的表现决定哪组超参数拥有最好的性能,这个时候用的是训练集中已经训练过的普通参数。
一些理解:
- 同时验证集在训练过程中还可以用来监控模型是否发生过拟合,一般来说验证集表现稳定后,若继续训练,训练集表现还会继续上升,但是验证集会出现不升反降的情况,这样一般就发生了过拟合。所以验证集也用来判断何时停止训练。
- 如果没有验证集,直接在训练集上调整超参数,那么我们不知道它是否出现过拟合或者其真实性能如何。
- 验证集的目的就是来模拟测试集。如果你的超参数适用于验证集,那么它们也大概会适用于测试集。如果没有验证集,只有测试集。经过多次训练后模型在测试集上也有一定程度的过拟合,虽然这种过拟合可能并没有在训练数据上的过拟合严重。但这是我们用我们人工选出来的测试集上的最优评估指标已经不能再客观地评价模型地好坏了。
测试集
不参与训练,用于在训练结束后对模型进行评估,评估其泛化能力。
只是用于评估,只是用于评估,只是用于评估,估计模型实际使用过程的泛化能力。
一些理解:
- 测试集对最终所选定的神经网络模型进行评估,模型之前从没见过测试集。严格来讲,测试集只能用一次,否则就像是作弊。
- 在之前模型使用【验证集】确定了【超参数】,使用【训练集】调整了【可训练参数】,最后使用一个从没有见过的数据集来判断这个模型的好坏。 需要十分注意的是:测试集仅用于最终评价模型的好坏,在测试集上得到的指标可以用来和别人训练的模型做对比,或者用来向别人报告你的模型效果如何。切记千万不能根据模型在测试集上的指标调整模型超参数(这是验证集应该干的事情),这会导致模型对测试集过拟合,使得测试集失去其测试效果的客观性和准确性。
交叉验证
交叉验证的作用对小规模数据集更明显。
N折交叉验证有两个用途:模型评估、模型选择。
N折交叉只是一种划分数据集的策略。想知道它的优势,可以拿它和传统划分数据集的方式进行比较。它可以避免固定划分数据集的局限性、特殊性,这个优势在小规模数据集上更明显。
把这种策略用于划分训练集和测试集,就可以进行模型评估;把这种策略用于划分训练集和验证集,就可以进行模型选择。
不用N折交叉验证就不能进行模型评估和模型选择了吗?当然不是。只要有测试集,就能进行模型评估;只要有验证集,就能进行模型选择。所以N折交叉验证只是在做这两件事时的一种可选的优化手段。
目标检测
-
想看相关的经典和最新论文,查看github:https://github.com/amusi/awesome-object-detection
-
one-stage(单阶段目标检测):例如SSD、YOLO。
基于anchors直接进行分类和边界框的调整。 -
two-stage(两阶段目标检测):例如faster-RCNN
通过专门模块生成候选框(RPN),寻找前景以及调整边界框(基于anchors);
基于之前生成的候选框进行分类,并且进一步调整边界框(基于proposal)。
YOLO算法
YOLO算法发展过程
YOLO(You Only Look Once)是一种目标检测算法,由Joseph Redmon等人在2015年提出。它的主要思想是将目标检测任务看作是一个回归问题,并且可以在一个神经网络中同时预测目标的位置和类别。
自2015年YOLO第一次发布以来,YOLO系列经历了多次更新和改进,以下是YOLO系列的发展史:
YOLO v1:在2015年,Joseph Redmon等人首次提出了YOLO。YOLO v1采用单个卷积神经网络,将输入图像划分为网格,并在每个网格中预测目标的类别和位置。2016年发表了论文。https://arxiv.org/pdf/1612.08242.pdf
YOLO v2:在2016年,YOLO v2发布,它采用了一些改进策略,包括使用更深的网络结构、更高的分辨率输入图像、Batch Normalization等技术来提高检测精度和速度。
YOLO v3:在2018年,YOLO v3发布,它采用了更深的网络结构和多尺度检测策略,可以检测不同尺度的目标,并且精度和速度比YOLO v2更好。
YOLO v4:在2020年,YOLO v4发布,它采用了更多的技术,包括SPP(Spatial Pyramid Pooling)、CSP(Cross Stage Partial Network)、Mosaic Data Augmentation、Drop Block等,可以进一步提高检测精度和速度。
YOLO v5:在2020年,YOLO v5发布,它采用了轻量级网络结构和新的训练策略,可以在更快的速度下实现高精度目标检测。
总的来说,YOLO系列算法不断发展,不断提高了目标检测的精度和速度,成为目前广泛应用的目标检测算法之一。
原文链接:https://blog.csdn.net/qq_54372122/article/details/129537219
卷积
- 卷积运算:固定的卷积核和不同窗口内数据相乘称为卷积运算。
- 局部连接:与传统神经网络结构中的全连接不同,卷积层的节点仅仅和其前一层的部分节点相连接,只用来学习局部特征(局部相关性理论)。能够有效地减少权值参数的数量,加快模型的学习速率,并在一定程度上可以避免过拟合现象。
- 权值共享:卷积层在图像滑动中,其卷积核参数在整幅图像滑动时是一样的。
空洞卷积
空洞卷积(Dilated/Atrous Convolution),广泛应用于语义分割与目标检测等任务中,语义分割中经典的deeplab系列与DUC对空洞卷积进行了深入的思考。目标检测中SSD与RFBNet,同样使用了空洞卷积。
空洞卷积:在3*3卷积核中间填充0,有两种实现方式,第一,卷积核填充0,第二,输入等间隔采样。

作用:
扩大感受野:在deep net中为了增加感受野且降低计算量,总要进行降采样(pooling或s2/conv),这样虽然可以增加感受野,但空间分辨率降低了。为了能不丢失分辨率,且仍然扩大感受野,可以使用空洞卷积。这在检测,分割任务中十分有用。一方面感受野大了可以检测分割大目标,另一方面分辨率高了可以精确定位目标。
捕获多尺度上下文信息:空洞卷积有一个参数可以设置dilation rate,具体含义就是在卷积核中填充dilation rate-1个0,因此,当设置不同dilation rate时,感受野就会不一样,也即获取了多尺度信息。多尺度信息在视觉任务中相当重要啊。
从这里可以看出,空洞卷积可以任意扩大感受野,且不需要引入额外参数,但如果把分辨率增加了,算法整体计算量肯定会增加。
ps: 空洞卷积虽然有这么多优点,但在实际中不好优化,速度会大大折扣。
缺点:
局部信息丢失:由于空洞卷积的计算方式类似于棋盘格式,某一层得到的卷积结果,来自上一层的独立的集合,没有相互依赖,因此该层的卷积结果之间没有相关性,即局部信息丢失。
远距离获取的信息没有相关性:由于空洞卷积稀疏的采样输入信号,使得远距离卷积得到的信息之间没有相关性,影响分类结果。
参考:
总结-空洞卷积(Dilated/Atrous Convolution)
感受野
感受野就是输出featuremap某个节点的响应对应的输入图像的区域就是感受野。换句话说,CONV层每个输出节点的值仅依赖CONV层输入的一个区域,这个区域之外的其他输入值都不会影响输出值,该区域就是感受野。
padding并不影响感受野,stride只影响下一层featuremap的感受野,size影响的是该层的感受野。

第n层感受野大小=上一层感受野大小+(第n层卷积核大小-1)乘以本层以前所有stride的乘积。
任意两个层之间都有位置—感受野对应关系,但我们更常用的是feature map层到输入图像的感受野。
过拟合
过拟合现象的本质其实是模型学习到了训练数据自身的特性,非全局的特性。
噪声
对模型有误导作用的数据。
例子:
如果某张训练图片中既有老鼠也有猫,训练图片的标签是“猫”,而且我们想要识别的对象也是“猫”,那么图片中的老鼠就是噪音。如果深度学习错误地记住了“老鼠”、“高斯白噪声”作为标签对应的信息,那么就会导致模型训练失败。
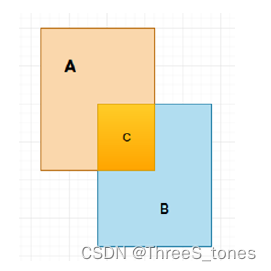
IOU
Intersection over Union(IOU)一般指代模型预测的建议框和真实框之间的交集和并集的比值。
A是建议框,B是真实框,集合A和集合B的并集包括了A和B的所有部分,集合C是集合A与集合B的交集。

搭建模型相关
Dropout方法
降低过拟合的倾向。
一般dropout方法用在全连接层与全连接层之间。Linear-非线性激活(如relu)-dropout。
展平
x = torch.flatten(x, start_dim=1)
从维度为1开始展平,pytorch中的维度是(N, C, H, W),从channel开始展平。
PyTorch相关
卷积操作
输出的H和W
根据公式计算N时,有时会出现N为非整数的情况(例如在alexnet,googlenet网络的第一层输出)),再例如输入的矩阵H=W=5,卷积核的F=2,S=2,Padding=1。经计算我们得到的N =(5-2+21)/2+1= 3.5此时在Pytorch中:在卷积过程中会直接将最后一行以及最后一列给忽略掉,以保证N为整数,此时N= (5-2+ 21-1)/2+1=3。 有人说pytorch中卷积和池化都是向下取整,还有人说卷积是向下取整,池化是向上取整(未验证)。
nn.Conv2d
(128,192,kernelsize=3,padding=1),
其中padding只能输入int或tuple。
例如tuple:(1,2)
1代表上下方各补一行零
2代表左右两侧各补两列零。
如果想要在左侧补一列,右侧补两列,使用nn.zeropad2d,见下方
nn.ZeroPad2d
实现左侧、上侧各补一列,右侧下侧各补两列。
经过一段时间的准备,发现原题目不能准确表达研究内容,需要将题目界定更加严谨。与指导老师协商后,申请修改题目。
Python中的一些函数用法
Import os
获得当前文件所在的根目录,data_root = os.getcwd()
或者data_root=os.path.abspath(os.path.join(os.path.abspath(file),“…/…/…”))
返回上级目录:…/
返回上上级目录:…/…
matplotlib.pyplot.imread函数介绍
matplotlib.pyplot.imread(path)用于读取一张图片,将图像数据变成数组array.
参数:
要读取的图像文件路径。
返回值:
如果是灰度图:返回(M,N)形状的数组,M表示高度,N表示宽度。
如果是RGB图像,返回(M, N, 3) 形状的数组,M表示高度,N表示宽度。
如果是RGBA图像,返回(M, N, 4) 形状的数组,M表示高度,N表示宽度。
此外,PNG 图像以浮点数组 (0-1) 的形式返回,所有其他格式都作为 int 型数组返回,位深由具体图像决定。
因此,在pytorch中如果需要读取文件,则需要通过 .permute(2, 0, 1) 将图像由HWC->CHW
参考:https://www.zhihu.com/question/265443164/answer/2417856431
参考:https://zhuanlan.zhihu.com/p/113623623
感受野参考:https://zhuanlan.zhihu.com/p/113487374、https://www.cnblogs.com/ocean1100/p/9864193.html