Moviattion
在公司的服务器上的GPU共同使用,我申请到了使用GPU编号为6和7两块GPU,一般情况下代码的默认使用GPU是0,如果GPU 0被其他人占用,那么就需要指定GPU 进行训练。
Method
我整理了两种方法去实现指定的GPU去训练:
1. 在你的Terminal中输入命令。
export CUDA_VISIBLE_DEVICES = 7
然后可以执行你的py文件进行训练。
2. 修改你的python代码。
在你的python代码 靠前的地方加上下面的代码:
os.environ["CUDA_VISIBLE_DEVICES"] = "7"
以上两种方法都可以达到使用第7块GPU学习的目的,很遗憾我的代码仅能使用一块GPU,以后我将学习如何使用多块GPU来同时训练模型。
补充,显存的使用关注的是Memory-Usage 这一列,不一定是Volatile GPU-util 利用率。 下面这个 就是显存占满了,但是却没有利用。 利用率为0%。
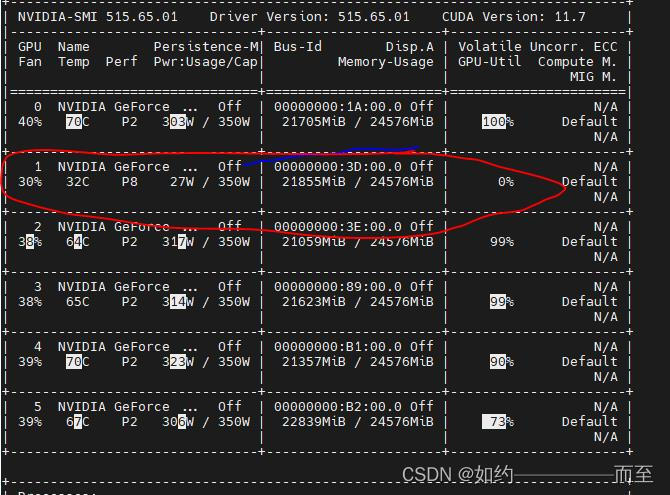
这里应该遇到了僵尸进程:
查看pid号
sudo fuser -v /dev/nvidia*
然后kill PId 的进程号
sudo kill -9 pid号码
如果自己不是root用户,那么输入以下指令查看GPU被哪个用户使用
ps -f -p pid_number
ps u pid_number
Torch1.8 和RTX3080 不兼容的问题:
NVIDIA GeForce RTX 3080 Ti with CUDA capability sm_86 is not compatible with the current PyTorch installation. The current PyTorch
install supports CUDA capabilities sm_37 sm_50 sm_60 sm_70.
解决方法:
安装环境的时候,先不要安装torch,使用如下命令去安装torch
> conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch
实时查看GPU 的使用情况
watch -n 1 -d nvidia-smi
实时查看nohup.out 的内容
tail -f nohup.out
Pycharm 中将一个代码部署到新的服务器上面:
记得右键设置 set as default 将对应的服务器的环境进行更新。