前言
上次笔记阐述了一般的线性回归模型实现的数学原理和整体思路,但不是每个样本数据集都适合用线性回归,比如说样本数据的分布呈振荡的曲线,我们就可以尝试更高次的曲线来拟合样本数据,这时候就要用多项式回归模型,但是阶数过多也会带来过拟合的风险,导致模型在其他数据集的表现比较差。
机器学习中的模型评估是一个重要的环节,它能显性地揭示不同的模型在不同的参数下完成任务的效果,给我们改进模型指明方向。
一、模型评估方法

模型评估我们主要用到sklearn库,sklearn是一个开源的基于python语言的机器学习工具包。它通过NumPy, SciPy和Matplotlib等python数值计算的库实现高效的算法应用,并且涵盖了几乎所有主流机器学习算法。sklearn中常用的模块有分类、回归、聚类、降维、模型选择、预处理。
1. 数据集切分重塑
数据集切分的工作主要是为了划分训练集和测试集,使得整个数据集既可用于训练模型又可以测试衡量模型的精度,切分的操作就是人为地传递数组的切片索引;数据集的重塑是为了打乱数据,因为数据之间是相互独立的而不会因为排序的位置改变它的独立性,重塑操作直接传入shuffle_index的索引就可以实现索引洗牌的操作
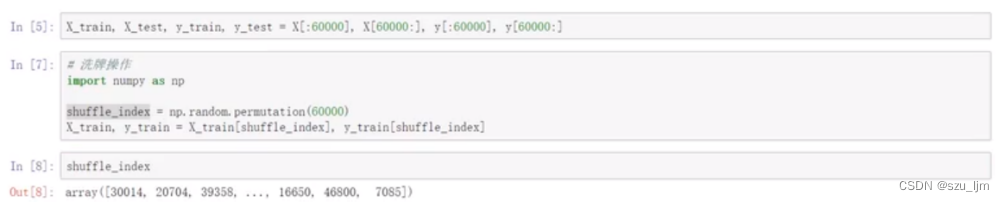
2. 交叉验证
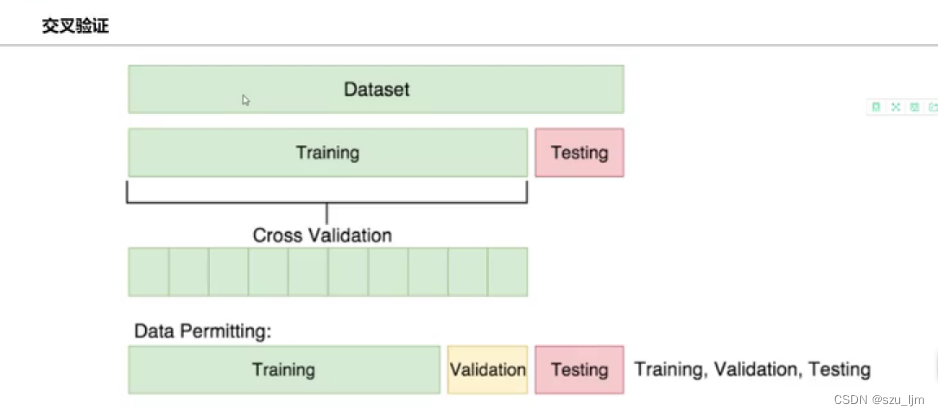
交叉验证需要在数据集切分的基础上对训练集进行再切分,最后变为训练集、验证集和测试集,训练集和验证集按一定的比例对原先的训练集进行占比分配。K折交叉验证把训练集数据随机分为K份,每次随机的选择K-1份作为训练集,剩下的1份作为测试集。当这一轮完成后,重新随机选择K-1份来训练数据,进行多次循环后(次数小于K),选择损失函数评估最优的模型和参数。
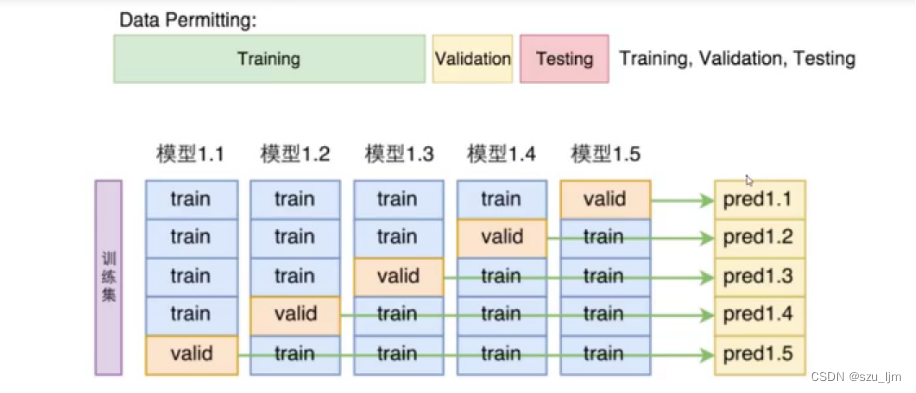
合适的交叉验证在一定程度上能提高模型对其他样本数据的适应能力,提高模型自身的精度和准确度。
3. 混淆矩阵
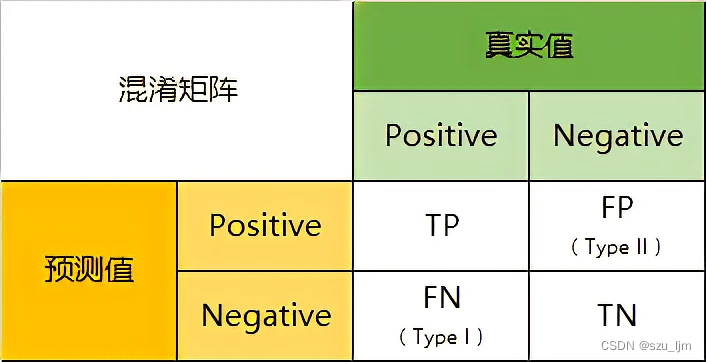
混淆矩阵可以清晰的反映出真实值与预测值相互吻合的部分,也可以反映出与预测值不吻合的部分。混淆矩阵主要用于有监督的二分类任务或者多分类任务,可以量化真实的指标和预测的指标间的关系。

以上面的为例,在一个总人数为100的班级中有80个男生和20个女生,二分类器最终选择了50人才完成了挑选出所有女生的任务目标。TP表示机器在执行任务中做对的数量,FP表示机器在执行任务中做错的数量,FN表示机器在没执行的任务中做错的数量,TN表示机器在没执行任务中做对的数量。由于该任务是选出所有女生,所以选出男生就是未执行的任务。在机器执行任务选出的50人中有20个女生,30个男生,所以TP = 20,FP = 30;在机器未执行任务的50人中全是男生,所以FN = 0,TN = 50。
4. 评估指标
由混淆矩阵我们可以引申出两种重要的衡量指标:精确率和召回率
精确率:模型预测到结论的特征与预测总之的比重
召回率:真实值中预测正确的特征占预测总数的比例
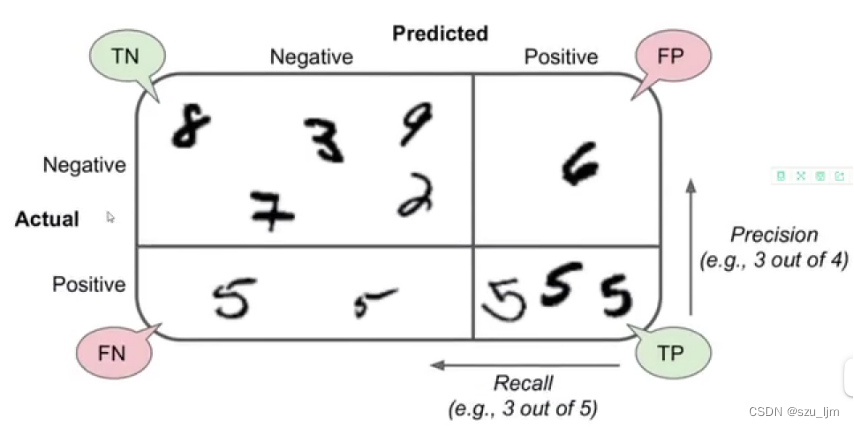
通俗易懂的理解,精确率是希望该模型在执行任务过程中命中目标的概率率越高越好,就像你射箭时希望把把十环;召回率是希望该模型在执行任务过程中遗漏目标的概率率越低越好,就像预测地震时允许你过度预警但不希望你漏掉任何一次预警。下面是精确率和召回率的数学表达式
p r e c i s i o n = T P T P + F P precision = \frac{TP}{TP + FP} precision=TP+FPTP
r e c a l l = T P T P + F N recall = \frac{TP}{TP + FN} recall=TP+FNTP
当 T P TP TP 一定时, F P FP FP 越小也就是犯错越少你的精度越高;当 T P TP TP 一定时, F N FN FN 越小也就是遗漏越少你的召回越高。最后我们使用调和平均数将两个指标统一为一个指标 F 1 F1 F1,改指标可以给分类器打一个分数来评估分类器的任务完成效果
F 1 = 2 ∗ p r e c i s i o n ∗ r e c a l l p r e c i s i o n + r e c a l l = T P T P + F N + F P 2 F1 = \frac{2 * precision * recall}{precision + recall} = \frac{TP}{TP + \frac{FN + FP}{2}} F1=precision+recall2∗precision∗recall=TP+2FN+FPTP
二、进阶回归分析
1. 多项式回归模型
多项式回归是利用原有数据进行维度拓展,假设原来传进来是特征 x x x 和标签 y y y ,如果样本数据分布比较复杂,我们需要对特征进行变换,使特征的维度更复杂更丰富,输出 x x x, x 2 x^{2} x2 等特征,但也不是特征越复杂越好,我们需要对特征的复杂度有个大概的评判,才能达到比较理想的效果
用python实现时先导入几个常用库,接着生成一些随机点,我们这里用二次曲线加上波动来模拟数据分布,然后对多项式特征、标准化、线性回归、pipe管道模块进行实例化,然后在不同的特征复杂度下进行模型训练模型测试,最后做可视化。下面是用python实现的多项式回归
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
m = 200
x = 5 * np.random.randn(m, 1) + 3
y = 0.3 * x ** 2 + x + np.random.randn(m, 1)
x_new = np.linspace(-10, 10, 200).reshape(200, 1)
plt.figure(figsize=(12, 8))
for style, width, degree in (('g-', 2, 100), ('y--', 2, 2), ('r-+', 2, 1)):
poly_fea = PolynomialFeatures(degree=degree, include_bias=False)
std = StandardScaler()
lin_reg = LinearRegression()
poly_reg = Pipeline([('poly_fea', poly_fea), ('StandardScaler', std), ('LinearRegression', lin_reg)])
poly_reg.fit(x, y)
y_new_n = poly_reg.predict(x_new)
plt.plot(x_new, y_new_n, style, label=str(degree), linewidth=width)
plt.plot(x, y, 'b.')
plt.axis([-10, 15, -20, 50])
plt.title('Polynomial Regression')
plt.legend(loc='best')
plt.show()
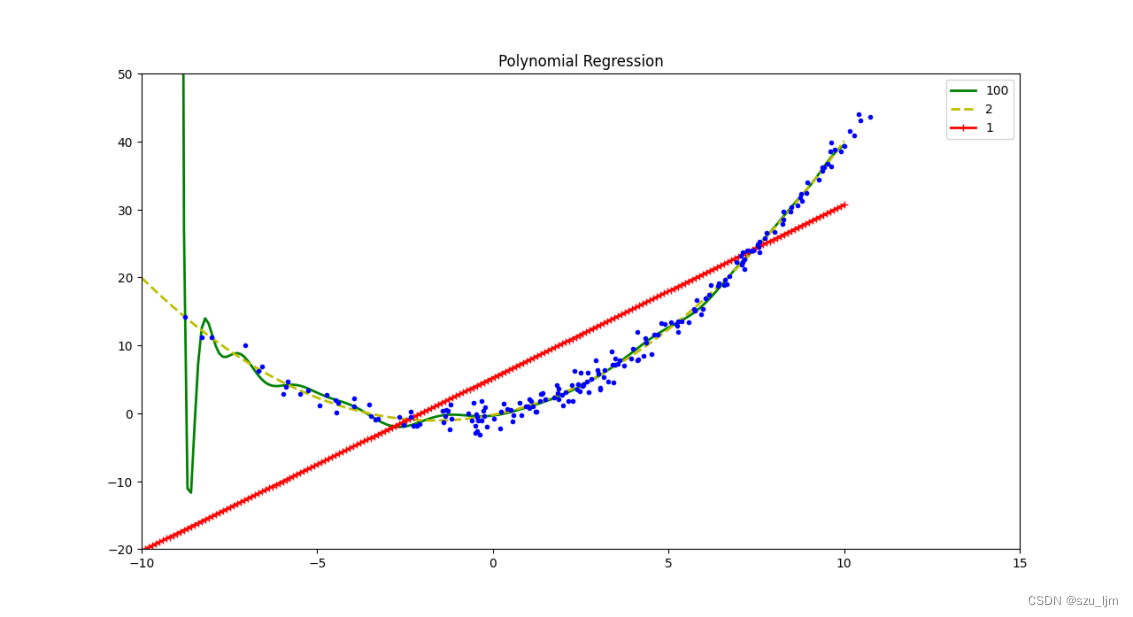
我们可以看到并不是特征越多越好,特征复杂度越高过拟合风险越高,所以多项式拟合前应该有个合理的预判选取合理的复杂度。
2. 岭回归模型
岭回归模型其实是对基础的线性回归模型做了一个损失函数的改善,即利用正则化的方式去改良最小二乘估计法,通过放弃最小二乘法的无偏性,以损失部分信息、降低精度为代价获得回归系数更为符合实际、更可靠的回归方法,对病态数据的拟合要强于最小二乘法。岭回归的损失函数表达式
J ( θ ) = M S E ( θ ) + α 2 ∑ i = 1 n θ i 2 J(\theta) = MSE(\theta) + \frac{\alpha}{2}\sum_{i = 1}^n \theta_{i}^2 J(θ)=MSE(θ)+2αi=1∑nθi2
用python实现岭回归首先要导入几个常见库,接着模拟一个分布比较离散的数据样本,然后定义一个画模型函数,把多项式回归里面的创建pipe管道的代码移过来,模型函数里面要判断是否对特征进行多项式变换,然后训练模型再测试模型,最后plot画两个子图
from sklearn.linear_model import Ridge
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import PolynomialFeatures
import numpy as np
import matplotlib.pyplot as plt
m = 100
x = 5 * np.random.randn(m, 1)
y = 0.3 * x + np.random.randn(m, 1) + 1
x_new = np.linspace(-8, 8, 200).reshape(200, 1)
def plt_model(model_class, poly, alphas, **model_kargs):
for alpha, style in zip(alphas, ('b-', 'y--', 'r:')):
model = model_class(alpha, **model_kargs)
if poly:
model = Pipeline([('poly_fea', PolynomialFeatures(degree=15, include_bias=False)), ('StandardScaler', StandardScaler()), ('LinearRegression', model)])
model.fit(x, y)
y_new_r = model.predict(x_new)
lw = 3 if alpha > 0 else 1
plt.plot(x_new, y_new_r, style, linewidth=lw, label='alpha = {}'.format(alpha))
plt.plot(x, y, 'g.', linewidth=3)
plt.legend()
plt.figure(figsize=(12, 8))
plt.subplot(121)
plt_model(Ridge, poly=False, alphas=(0, 1000, 10000))
plt.subplot(122)
plt_model(Ridge, poly=True, alphas=(0, 10**-5, 5))
plt.show()
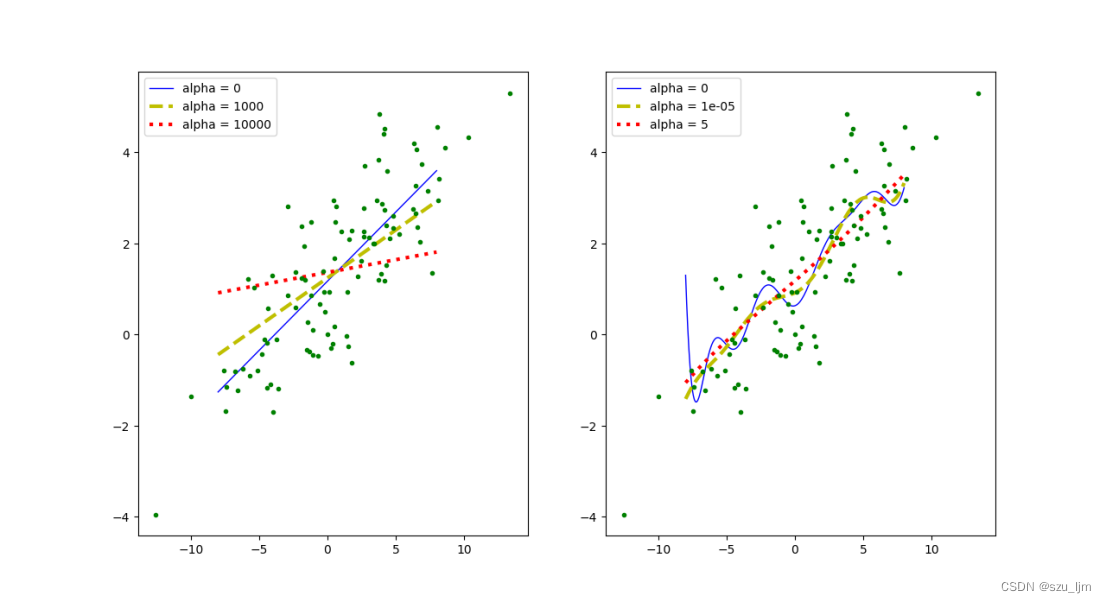
我们可以看到,在普通线性回归中正则化惩罚反而会降低拟合的精确度,但在复杂的多项式回归中正则化惩罚会让模型的过拟合风险降低,提高模型整体的适应能力,特别是对分布比较杂乱的数据样本。
3. Lasso回归模型
Lasso回归和岭回归模型其实原理一样,只不过它们在损失函数中加入的正则化算子不一样
J ( θ ) = M S E ( θ ) + α ∑ i = 1 n ∣ θ i ∣ J(\theta) = MSE(\theta) + \alpha\sum_{i = 1}^n |\theta_{i}| J(θ)=MSE(θ)+αi=1∑n∣θi∣
Lasso回归用python实现的流程和岭回归也一样
rom sklearn.linear_model import Lasso
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import PolynomialFeatures
import numpy as np
import matplotlib.pyplot as plt
m = 100
x = 5 * np.random.randn(m, 1)
y = 0.6 * x + 4*np.random.randn(m, 1) + 1
x_new = np.linspace(-10, 10, m).reshape(m, 1)
def plt_model(model_class, poly, alphas, **model_kargs):
for alpha, style in zip(alphas, ('b-', 'y--', 'r:')):
model = model_class(alpha, **model_kargs)
if poly:
model = Pipeline([('poly_fea', PolynomialFeatures(degree=100, include_bias=False)), ('StandardScaler', StandardScaler()), ('LinearRegression', model)])
model.fit(x, y)
y_new_r = model.predict(x_new)
lw = 3 if alpha > 0 else 1
plt.plot(x_new, y_new_r, style, linewidth=lw, label='alpha = {}'.format(alpha))
plt.plot(x, y, 'g.', linewidth=3)
plt.legend()
plt.figure(figsize=(12, 8))
plt.subplot(121)
plt_model(Lasso, poly=False, alphas=(0, 5, 25))
plt.subplot(122)
plt_model(Lasso, poly=True, alphas=(0, 10**-1, 1))
plt.show()
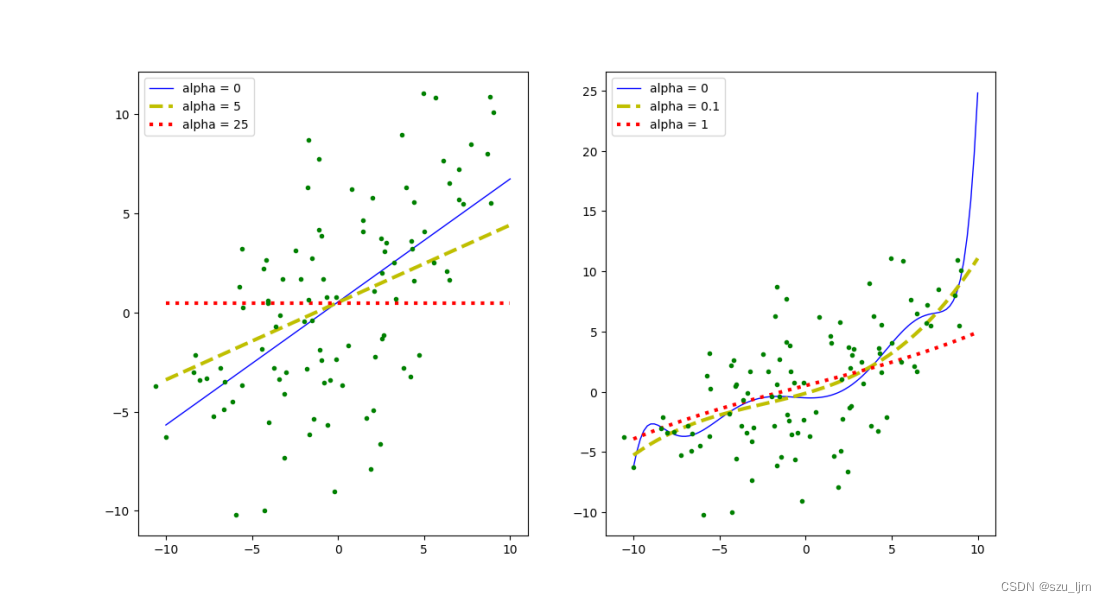
我们也可以看到,在普通线性回归中正则化惩罚反而会降低拟合的精确度,但在复杂的多项式回归中适当的正则化惩罚会让模型的过拟合风险降低,提高模型整体的适应能力,特别是对分布比较杂乱的数据样本。
总结
以上就是机器学习模型评估和进阶回归的学习笔记,其中多项式回归这种非线性回归在真实情况中也经常用到,但总之越简单的模型对不同样本数据的适用能力越强,过拟合风险也越低,所以我们会经常用一次函数或者二次三次曲线来拟合样本数据,再高次的曲线就很少用了。这和《终极算法》中作者的猜想很像,是否能有一种至简的算法模型,能概括宇宙中一切的真理,这种算法模型将让人类获得过去、现在、未来一切的知识。