目录
redis可以存储五种数据结构:String(字符串)、List(列表)、Set(集合)、Hash(哈希)、Zset(有序集合)。del、type、rename等命令是通用的,另外,注意一点,这些结构都是一个key-数据结构的方式存储。即为所述:


Redis对象由redisObject结构体表示:
typedef struct redisObject {
unsigned type:4; // 对象的类型,包括 /* Object types */
unsigned encoding:4; // 底部为了节省空间,一种type的数据,可以采用不同的存储方式
unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */
int refcount; // 引用计数
void *ptr;
} robj;
注意上面说的主要是redis3.2,最新的redis5版本基本一致,但是有些文件找不到,可能有变更。
1,string类型
最大512M,String类型通过 int、SDS(simple dynamic string)作为结构存储,int用来存放整型数据,sds存放字节/字符串和浮点型数据。
在redis的源码中【sds.h】中看到sds的结构如下:
typedef char *sds;
redis3.2分支引入了五种sdshdr类型,目的是为了满足不同长度字符串可以使用不同大小的Header,从而节省内存,每次在创建一个sds时根据sds的实际长度判断应该选择什么类型的sdshdr,不同类型的sdshdr占用的内存空间不同。这样细分一下可以省去很多不必要的内存开销,下面是3.2的sdshdr定义,在5.0.7版本也是一样的:
typedef char *sds;
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 8表示字符串最大长度是2^8,长度为255 {
uint8_t len; /* used */ 表示当前sds的长度(单位是字节)
uint8_t alloc; /* excluding the header and null terminator */ 表示已为sds分配的内存空间大小(单位是字节)
unsigned char flags; /* 3 lsb of type, 5 unused bits */ 用一个字节表示当前sdshdr的类型,因为有sdshdr有五种类型,所以至少需要用3位来表示
char buf[]; sds的实际存放位置
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
sds图示:
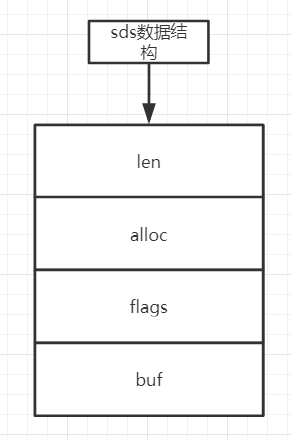
string类型数据结构可用于:用户邮箱、图片等内容。
操作小结:
127.0.0.1:6379> set a man
OK
127.0.0.1:6379> get a
"man"
127.0.0.1:6379> del a
(integer) 1
127.0.0.1:6379> get a
(nil)
2,list类型
列表采用双向链表实现,因此在两端添加比较快,时间复杂度为O(1)。
redis3.2之前,List类型的value对象内部以linkedlist或者ziplist来实现, 当list的元素个数和单个元素的长度比较小的时候,Redis会采用ziplist(压缩列表)来实现来减少内存占用。否则就会采用linkedlist(双向链表)结构。redis3.2之后,采用的一种叫quicklist的数据结构来存储list,列表的底层都由quicklist实现。
这两种存储方式都有优缺点,双向链表在链表两端进行push和pop操作,在插入节点上复杂度比较低,但是内存开销比较大; ziplist存储在一段连续的内存上,所以存储效率很高,但是插入和删除都需要频繁申请和释放内存;
quicklist仍然是一个双向链表,只是列表的每个节点都是一个ziplist,其实就是linkedlist和ziplist的结合,quicklist中每个节点ziplist都能够存储多个数据元素,在源码中的文件为【quicklist.c】,在源码第一行中有解释为:Adoubly linked list of ziplists意思为一个由ziplist组成的双向链表;
基本操作,lpush、rpush、lpop、rpop、lrange;lrange list-key 0 -1 表示取出全部。
quicklist:
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* total count of all entries in all ziplists */
unsigned long len; /* number of quicklistNodes */
int fill : 16; /* fill factor for individual nodes */
unsigned int compress : 16; /* depth of end nodes not to compress;0=off */
} quicklist;
quicklist的Node:
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl;
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
ziplist的总体布局如下:
<zlbytes> <zltail> <zllen> <entry> <entry> ... <entry> <zlend>
list的存储如下图所示:

使用场景:略
操作小节:
127.0.0.1:6379> lpush a 2
(integer) 1
127.0.0.1:6379> lpush a 3
(integer) 2
127.0.0.1:6379> rpush a 1
(integer) 3
127.0.0.1:6379> lrange a 0 -1
1) "3"
2) "2"
3) "1"
127.0.0.1:6379> lindex a 1
"2"
127.0.0.1:6379> lpop a
"3"
127.0.0.1:6379> rpop a
"1"
127.0.0.1:6379> lrange a 0 -1
1) "2"
3,hash类型
hash类型概念上就是map,实现通过hashtable或者ziplist,数据量小的时候用ziplist,数据量大的时候用hashtable,那么多小才会用ziplist?来看一看源码:
/* Check the length of a number of objects to see if we need to convert a
* ziplist to a real hash. Note that we only check string encoded objects
* as their string length can be queried in constant time. */
这一段代码用来判断是否要把ziplist转换成真是的hash,注意只检查字符编码对象
void hashTypeTryConversion(robj *o, robj **argv, int start, int end) {
int i;
if (o->encoding != OBJ_ENCODING_ZIPLIST) return;
如果o的编码不是OBJ_ENCODING_ZIPLIST就不处理
for (i = start; i <= end; i++) {
if (sdsEncodedObject(argv[i]) &&
sdslen(argv[i]->ptr) > server.hash_max_ziplist_value)
{
hashTypeConvert(o, OBJ_ENCODING_HT);
break;
}
}
}
转换还有一段代码:
/* Add a new field, overwrite the old with the new value if it already exists.
* Return 0 on insert and 1 on update.
* 新增一个字段,如果存在就覆盖
* By default, the key and value SDS strings are copied if needed, so the
* caller retains ownership of the strings passed. However this behavior
* can be effected by passing appropriate flags (possibly bitwise OR-ed):
*
* HASH_SET_TAKE_FIELD -- The SDS field ownership passes to the function.
* HASH_SET_TAKE_VALUE -- The SDS value ownership passes to the function.
*
* When the flags are used the caller does not need to release the passed
* SDS string(s). It's up to the function to use the string to create a new
* entry or to free the SDS string before returning to the caller.
*
* HASH_SET_COPY corresponds to no flags passed, and means the default
* semantics of copying the values if needed.
*
*/
#define HASH_SET_TAKE_FIELD (1<<0)
#define HASH_SET_TAKE_VALUE (1<<1)
#define HASH_SET_COPY 0
int hashTypeSet(robj *o, sds field, sds value, int flags) {
int update = 0;
if (o->encoding == OBJ_ENCODING_ZIPLIST) {
unsigned char *zl, *fptr, *vptr;
zl = o->ptr;
fptr = ziplistIndex(zl, ZIPLIST_HEAD);
if (fptr != NULL) {
fptr = ziplistFind(fptr, (unsigned char*)field, sdslen(field), 1);
if (fptr != NULL) {
/* Grab pointer to the value (fptr points to the field) */
vptr = ziplistNext(zl, fptr);
serverAssert(vptr != NULL);
update = 1;
/* Delete value */
zl = ziplistDelete(zl, &vptr);
/* Insert new value */
zl = ziplistInsert(zl, vptr, (unsigned char*)value,
sdslen(value));
}
}
if (!update) {
/* Push new field/value pair onto the tail of the ziplist */
zl = ziplistPush(zl, (unsigned char*)field, sdslen(field),
ZIPLIST_TAIL);
zl = ziplistPush(zl, (unsigned char*)value, sdslen(value),
ZIPLIST_TAIL);
}
o->ptr = zl;
/* Check if the ziplist needs to be converted to a hash table */
if (hashTypeLength(o) > server.hash_max_ziplist_entries)
hashTypeConvert(o, OBJ_ENCODING_HT);
} else if (o->encoding == OBJ_ENCODING_HT) {
dictEntry *de = dictFind(o->ptr,field);
if (de) {
sdsfree(dictGetVal(de));
if (flags & HASH_SET_TAKE_VALUE) {
dictGetVal(de) = value;
value = NULL;
} else {
dictGetVal(de) = sdsdup(value);
}
update = 1;
} else {
sds f,v;
if (flags & HASH_SET_TAKE_FIELD) {
f = field;
field = NULL;
} else {
f = sdsdup(field);
}
if (flags & HASH_SET_TAKE_VALUE) {
v = value;
value = NULL;
} else {
v = sdsdup(value);
}
dictAdd(o->ptr,f,v);
}
} else {
serverPanic("Unknown hash encoding");
}
/* Free SDS strings we did not referenced elsewhere if the flags
* want this function to be responsible. */
if (flags & HASH_SET_TAKE_FIELD && field) sdsfree(field);
if (flags & HASH_SET_TAKE_VALUE && value) sdsfree(value);
return update;
}
因此有两种情况会执行,一种是在检查值字符串长度是否大于64,另一个是检查所包含的entries大小,是否多于512,即和server.hash_max_ziplist_value、server.hash_max_ziplist_entries这两个值比较,这两个值可以在redis.conf中设置:
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
ziplist如前所示,针对hashTable的实现,有三个结构,在dict.h中:
dictEntry
typedef struct dictEntry {
void *key;
union { //因为value有多种类型,所以value用了union来存储
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; 下一个节点的地址,用来处理碰撞,分配到同一索引的元素,形成一个链表,记不记得HashMap里面,也是有一个entry,同样的概念
} dictEntry;
dictht
实现一个hash表会使用一个buckets存放dictEntry的地址,一般情况下通过hash(key)%len得到的值就是buckets的索引,这个值决定了我们要将此dictEntry节点放入buckets的哪个索引里,这个buckets实际上就是我们说的hash表。dict.h的dictht结构中table存放的就是buckets的地址
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table; buckets的地址
unsigned long size; buckets的大小,总保持为2^n
unsigned long sizemask; 掩码,用来计算hash值对应的buckets索引
unsigned long used; 当前dictht有多少个dictEntry节点
} dictht;
dict
dictht是hash的核心,但是只有一个dictht是不够的,比如rehash、遍历hash等操作,所以redis定义了一个dict用于支持字典的各种操作,当dictht需要扩容/缩容时,用来管理dictht的迁移,源码如下:
typedef struct dict {
dictType *type; dictType里存放的是一堆工具函数的函数指针
void *privdata; 保存type中的某些函数需要作为参数的数据
dictht ht[2]; 两个dictht,ht[0]平时用,ht[1] rehash时用(比如扩容时就要rehash)
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
当前rehash到buckets的哪个索引,-1时表示非rehash状态
unsigned long iterators; /* number of iterators currently running */
安全迭代器的计数。
} dict;
比如我们要讲一个数据存储到hash表中,那么会先通过murmur计算key对应的hashcode,然后根据hashcode取模得到bucket的位置,再插入到链表中。map简图:

使用小结:
127.0.0.1:6379> hset has tfield value
(integer) 1
127.0.0.1:6379> hset has tfield1 value1
(integer) 1
127.0.0.1:6379> hgetall has
1) "tfield"
2) "value"
3) "tfield1"
4) "value1"
127.0.0.1:6379> hget has tfield
"value"
127.0.0.1:6379> hdel has tfield
(integer) 1
127.0.0.1:6379> hgetall has
1) "tfield1"
2) "value1"
4,集合类型
集合set,无序且不重复。集合类型的常用操作是向集合中加入或删除元素、判断某个元素是否存在。由于集合类型在redis内部是使用的值为空的散列表(hash table),所以这些操作的时间复杂度都是O(1)。
Set在的底层数据结构以intset或者hashtable来存储。当set中只包含整数型的元素时,采用intset来存储,否则,采用hashtable存储,但是对于set来说,该hashtable的value值用于为NULL。通过key来存储元素。图则类似于hash,只不过entry里值用到了field。
使用小结:
127.0.0.1:6379> sadd b b
(integer) 1
127.0.0.1:6379> sadd b c
(integer) 1
127.0.0.1:6379> sadd c c
(integer) 1
127.0.0.1:6379> SMEMBERS b
1) "c"
2) "b"
127.0.0.1:6379> SISMEMBER b c
(integer) 1
127.0.0.1:6379> SREM b c
(integer) 1
127.0.0.1:6379> SMEMBERS b
1) "b"
5,有序集合
有序集合实际上就是给每个元素关联了一个分数,分数可以相同。有序集合对象的编码可以是ziplist或者skiplist。同时满足以下条件时使用ziplist编码:
元素数量小于128个
所有member的长度都小于64字节
以上两个条件的上限值可通过zset-max-ziplist-entries和zset-max-ziplist-value来修改。ziplist编码的有序集合使用紧挨在一起的压缩列表节点来保存,第一个节点保存member,第二个保存score。ziplist内的集合元素按score从小到大排序,score较小的排在表头位置。
skiplist编码的有序集合底层是一个命名为zset的结构体,而一个zset结构同时包含一个字典和一个跳跃表。跳跃表按score从小到大保存所有集合元素。而字典则保存着从member到score的映射,这样就可以用O(1)的复杂度来查找member对应的score值。虽然同时使用两种结构,但它们会通过指针来共享相同元素的member和score,因此不会浪费额外的内存。
那么什么是skiplist?
跳表(skip List)是一种随机化的数据结构,基于并联的链表,实现简单,插入、删除、查找的复杂度均为O(logN)。简单说来跳表也是链表的一种,只不过它在链表的基础上增加了跳跃功能,正是这个跳跃的功能,使得在查找元素时,跳表能够提供O(logN)的时间复杂度。

在这样一个链表中,如果我们要查找某个数据,那么需要从头开始逐个进行比较,直到找到包含数据的那个节点,或者找到第一个比给定数据大的节点为止(没找到)。也就是说,时间复杂度为O(n)。同样,当我们要插入新数据的时候,也要经历同样的查找过程,从而确定插入位置。
假如我们每相邻两个节点增加一个指针,让指针指向下下个节点,如下图:

这样所有新增加的指针连成了一个新的链表,但它包含的节点个数只有原来的一半(上图中是7, 19, 26)。现在当我们想查找数据的时候,可以先沿着这个新链表进行查找。当碰到比待查数据大的节点时,再回到原来的链表中进行查找。比如,我们想查找23,查找的路径是沿着下图中标红的指针所指向的方向进行的:
-
- 23首先和7比较,再和19比较,比它们都大,继续向后比较。
- 但23和26比较的时候,比26要小,因此回到下面的链表(原链表),与22比较。
- 23比22要大,沿下面的指针继续向后和26比较。23比26小,说明待查数据23在原链表中不存在,而且它的插入位置应该在22和26之间。
在这个查找过程中,由于新增加的指针,我们不再需要与链表中每个节点逐个进行比较了。需要比较的节点数大概只有原来的一半。
利用同样的方式,我们可以在上层新产生的链表上,继续为每相邻的两个节点增加一个指针,从而产生第三层链表。如下图:

在这个新的三层链表结构上,如果我们还是查找23,那么沿着最上层链表首先要比较的是19,发现23比19大,接下来我们就知道只需要到19的后面去继续查找,从而一下子跳过了19前面的所有节点。可以想象,当链表足够长的时候,这种多层链表的查找方式能让我们跳过很多下层节点,大大加快查找的速度。
skiplist正是受这种多层链表的想法的启发而设计出来的。实际上,按照上面生成链表的方式,上面每一层链表的节点个数,是下面一层的节点个数的一半,这样查找过程就非常类似于一个二分查找,使得查找的时间复杂度可以降低到O(log n)。但是,这种方法在插入数据的时候有很大的问题。新插入一个节点之后,就会打乱上下相邻两层链表上节点个数严格的2:1的对应关系。如果要维持这种对应关系,就必须把新插入的节点后面的所有节点(也包括新插入的节点)重新进行调整,这会让时间复杂度重新蜕化成O(n)。删除数据也有同样的问题。
skiplist为了避免这一问题,它不要求上下相邻两层链表之间的节点个数有严格的对应关系,而是为每个节点随机出一个层数(level)。比如,一个节点随机出的层数是3,那么就把它链入到第1层到第3层这三层链表中。为了表达清楚,下图展示了如何通过一步步的插入操作从而形成一个skiplist的过程:

从上面skiplist的创建和插入过程可以看出,每一个节点的层数(level)是随机出来的,而且新插入一个节点不会影响其它节点的层数。因此,插入操作只需要修改插入节点前后的指针,而不需要对很多节点都进行调整。这就降低了插入操作的复杂度。实际上,这是skiplist的一个很重要的特性,这让它在插入性能上明显优于平衡树的方案。这在后面我们还会提到。
skiplist,指的就是除了最下面第1层链表之外,它会产生若干层稀疏的链表,这些链表里面的指针故意跳过了一些节点(而且越高层的链表跳过的节点越多)。这就使得我们在查找数据的时候能够先在高层的链表中进行查找,然后逐层降低,最终降到第1层链表来精确地确定数据位置。在这个过程中,我们跳过了一些节点,从而也就加快了查找速度。
刚刚创建的这个skiplist总共包含4层链表,现在假设我们在它里面依然查找23,下图给出了查找路径:

需要注意的是,前面演示的各个节点的插入过程,实际上在插入之前也要先经历一个类似的查找过程,在确定插入位置后,再完成插入操作。
实际应用中的skiplist每个节点应该包含key和value两部分。前面的描述中我们没有具体区分key和value,但实际上列表中是按照key(score)进行排序的,查找过程也是根据key在比较。
执行插入操作时计算随机数的过程,是一个很关键的过程,它对skiplist的统计特性有着很重要的影响。这并不是一个普通的服从均匀分布的随机数,它的计算过程如下:
- 首先,每个节点肯定都有第1层指针(每个节点都在第1层链表里)。
- 如果一个节点有第i层(i>=1)指针(即节点已经在第1层到第i层链表中),那么它有第(i+1)层指针的概率为p。
- 节点最大的层数不允许超过一个最大值,记为MaxLevel。
skiplist与平衡树、哈希表的比较
skiplist和各种平衡树(如AVL、红黑树等)的元素是有序排列的,而哈希表不是有序的。因此,在哈希表上只能做单个key的查找,不适宜做范围查找。所谓范围查找,指的是查找那些大小在指定的两个值之间的所有节点。
在做范围查找的时候,平衡树比skiplist操作要复杂。在平衡树上,我们找到指定范围的小值之后,还需要以中序遍历的顺序继续寻找其它不超过大值的节点。如果不对平衡树进行一定的改造,这里的中序遍历并不容易实现。而在skiplist上进行范围查找就非常简单,只需要在找到小值之后,对第1层链表进行若干步的遍历就可以实现。
平衡树的插入和删除操作可能引发子树的调整,逻辑复杂,而skiplist的插入和删除只需要修改相邻节点的指针,操作简单又快速。
从内存占用上来说,skiplist比平衡树更灵活一些。一般来说,平衡树每个节点包含2个指针(分别指向左右子树),而skiplist每个节点包含的指针数目平均为1/(1-p),具体取决于参数p的大小。如果像Redis里的实现一样,取p=1/4,那么平均每个节点包含1.33个指针,比平衡树更有优势。
查找单个key,skiplist和平衡树的时间复杂度都为O(log n),大体相当;而哈希表在保持较低的哈希值冲突概率的前提下,查找时间复杂度接近O(1),性能更高一些。所以我们平常使用的各种Map或dictionary结构,大都是基于哈希表实现的。
从算法实现难度上来比较,skiplist比平衡树要简单得多。
使用小结:
127.0.0.1:6379> zadd zset-key 728 members1
(integer) 1
127.0.0.1:6379> zadd zset-key 733 members2
(integer) 1
127.0.0.1:6379> zadd zset-key 299 members3
(integer) 1
127.0.0.1:6379> ZRANGE zset-key 0 -1
1) "members3"
2) "members1"
3) "members2"
127.0.0.1:6379> ZRANGEBYSCORE zset-key 0 500
1) "members3"
127.0.0.1:6379> ZREM zset-key members3
(integer) 1
参考:https://www.jianshu.com/p/cc379427ef9d
参考:https://blog.csdn.net/qq_35433716/article/details/82177585
参考:《Redis实战》