使用版本:https://github.com/Unity-Technologies/ml-agents/releases/tag/release_19
文件路径:ml-agents-release_19/docs/Learning-Environment-Create-New.md
20和19的在rollerBall上一样:https://github.com/Unity-Technologies/ml-agents/blob/develop/docs/Learning-Environment-Create-New.md
本文只涉及代码解析,对于unity的对应操作请看相应文档
目录
1. Initialization and Resetting the Agent
1.2.2 this.transform.localPosition.y < 0
1.2.3 this.transform.localPosition = new Vector3( 0, 0.5f, 0)
1.2.4 Target.localPosition = new Vector3(Random.value * 8 - 4, 0.5f, Random.value * 8 - 4); }
2.2.1 public override void CollectObservations(VectorSensor sensor)
2.2.2 sensor.AddObservation(Target.localPosition)
2.2.3 sensor.AddObservation(this.transform.localPosition)这一行代码将
2.2.4 sensor.AddObservation(rBody.velocity.x)
2.2.5 sensor.AddObservation(rBody.velocity.z)
3. Taking Actions and Assigning Rewards
3.2.1 public float forceMultiplier = 10
3.2.2 public override void OnActionReceived(ActionBuffers actionBuffers)
3.2.3 controlSignal.x = actionBuffers.ContinuousActions[0]
3.2.4 float distanceToTarget = Vector3.Distance(this.transform.localPosition, Target.localPosition)
1. Initialization and Resetting the Agent
1.1 代码总括
using System.Collections.Generic; // 导入命名空间 System.Collections.Generic
using UnityEngine; // 导入 Unity 引擎的命名空间
using Unity.MLAgents; // 导入 Unity 引擎的 Machine Learning Agents(ML-Agents)的命名空间
using Unity.MLAgents.Sensors; // 导入 Unity 引擎的 ML-Agents 的 Sensors 的命名空间
public class RollerAgent : Agent // 声明一个 RollerAgent 类,继承自 Agent 类
{
Rigidbody rBody; // 声明一个 Rigidbody 类型的变量 rBody
void Start () { // 声明一个 Start 方法,当脚本启动时会执行该方法
rBody = GetComponent<Rigidbody>(); // 获取当前 GameObject 的 Rigidbody 组件
}
public Transform Target; // 声明一个 Transform 类型的公共变量 Target,用于储存目标物体的位置信息
public override void OnEpisodeBegin() // 重写 OnEpisodeBegin 方法
{
// 如果智能体掉落,则将其动量归零
if (this.transform.localPosition.y < 0)
{
this.rBody.angularVelocity = Vector3.zero;
this.rBody.velocity = Vector3.zero;
this.transform.localPosition = new Vector3( 0, 0.5f, 0); // 将智能体放在起点
}
// 将目标物体移动到新的位置
Target.localPosition = new Vector3(Random.value * 8 - 4, 0.5f, Random.value * 8 - 4);
}
}
这段代码是一个简单的机器学习智能体(RollerAgent),用于学习如何控制一个球体移动到场景中随机位置的目标点。其中,using 语句用于导入所需的命名空间,public 关键字用于声明公共变量,Start 方法是 Unity 引擎中的一个特殊方法,当脚本启动时会自动执行,OnEpisodeBegin 方法则是重写了 Agent 类的该方法,用于在每个新的 episode(一次训练)开始时执行。
1.2 代码分解
1.2.1 导入包和命名空间
using System.Collections.Generic; // 导入命名空间 System.Collections.Generic
using UnityEngine; // 导入 Unity 引擎的命名空间
using Unity.MLAgents; // 导入 Unity 引擎的 Machine Learning Agents(ML-Agents)的命名空间
using Unity.MLAgents.Sensors // 导入 Unity 引擎的 ML-Agents 的 Sensors 的命名空间
using System.Collections.Generic 是一个 C# 中的命名空间,用于提供实现各种通用集合数据结构的类型。在使用 C# 中的 List、Dictionary 等数据结构时需要使用该命名空间。例如,当需要使用 List<T> 类型时,需要在代码文件的头部使用 using System.Collections.Generic; 声明该命名空间。
using UnityEngine 是 C# 编程语言中的一个关键字,用于引入 Unity 引擎的命名空间,使得在代码中可以直接使用 Unity 引擎提供的类和方法。这些类和方法包括用于创建游戏对象、控制游戏对象的位置、旋转、缩放、碰撞检测等等,以及访问 Unity 引擎中的其他功能。
Unity.MLAgents 是 Unity 官方提供的一个工具包,用于支持在 Unity 中训练机器学习模型,尤其是用于支持强化学习算法的训练。其中包含了许多用于强化学习的组件和类。通过使用这个工具包,开发者可以快速地在 Unity 中构建强化学习场景,训练自己的智能体,以及评估和部署训练好的模型。
using Unity.MLAgents.Sensors 引入了用于创建智能体感知信息的 ML-Agents 的 Sensor 类和相关组件。感知信息由智能体的观测(observation)和其他一些信息(如reward等)组成,用于训练智能体进行决策。该命名空间包含了许多不同类型的Sensor,例如VisualSensor和RayPerceptionSensor等,这些Sensor可用于感知不同类型的环境。
1.2.2 this.transform.localPosition.y < 0
this.transform.localPosition.y < 0这段代码用于检测智能体在环境中是否跌落。具体地,它检查智能体的本地坐标(local position)的y值是否小于0,如果是,说明智能体已经跌落到地面以下。
1.2.3 this.transform.localPosition = new Vector3( 0, 0.5f, 0)
this.transform.localPosition = new Vector3( 0, 0.5f, 0)this.transform.localPosition = new Vector3( 0, 0.5f, 0) 是将当前游戏对象的本地坐标设置为 (0, 0.5, 0)。其中 localPosition 是相对于父物体坐标系的位置,因此将其设置为 (0, 0.5, 0) 会将游戏对象相对于其父物体向上移动 0.5 个单位。
问:this.transform.localPosition 中的this ?
在这里,this指代当前脚本所在的游戏对象,即关键字this代表当前类的实例。transform是每个GameObject对象上都有的一个组件,表示该对象的变换组件,可以控制对象的位置、旋转和缩放等属性。localPosition是变换组件中的一个属性,表示对象相对于其父对象的本地坐标。因此,this.transform.localPosition指代当前对象相对于其父对象的本地坐标。
this 表示当前脚本实例所在的游戏对象。例如,如果一个脚本是挂载在名为 "Player" 的游戏对象上的,那么 this.transform.localPosition 就是指该游戏对象的本地位置。
1.2.4 Target.localPosition = new Vector3(Random.value * 8 - 4, 0.5f, Random.value * 8 - 4); }
Target.localPosition = new Vector3(Random.value * 8 - 4, 0.5f, Random.value * 8 - 4);
}这行代码的作用是在每个Episode(一次训练周期)开始时将Target的位置设置为一个新的随机位置。具体来说,它使用Random.value生成一个介于0和1之间的随机值,并将其乘以8。然后,从这个结果中减去4,以使得结果介于-4和4之间。这个结果被用作新位置的X和Z坐标,而Y坐标设置为0.5f。因此,这行代码将随机移动目标的位置,从而使智能体必须适应不同的目标位置来完成任务。
2. Observing the Environment
2.1 代码总括
public override void CollectObservations(VectorSensor sensor)
{
// 目标点和智能体位置
sensor.AddObservation(Target.localPosition);
sensor.AddObservation(this.transform.localPosition);
// 智能体速度
sensor.AddObservation(rBody.velocity.x);
sensor.AddObservation(rBody.velocity.z);
}
-
public override void CollectObservations(VectorSensor sensor): 重写了父类Agent中的CollectObservations方法,该方法用于收集智能体的观测数据,VectorSensor类型的参数sensor用于存储观测数据。 -
sensor.AddObservation(Target.localPosition): 将目标点的位置作为一个观测数据添加到sensor中。 -
sensor.AddObservation(this.transform.localPosition): 将智能体的位置作为一个观测数据添加到sensor中。 -
sensor.AddObservation(rBody.velocity.x): 将智能体在 x 轴方向的速度作为一个观测数据添加到sensor中。 -
sensor.AddObservation(rBody.velocity.z): 将智能体在 z 轴方向的速度作为一个观测数据添加到sensor中。
2.2 代码分解
2.2.1 public override void CollectObservations(VectorSensor sensor)
public override void CollectObservations(VectorSensor sensor)public override void CollectObservations(VectorSensor sensor) 是一个重写了父类 Agent 中的 CollectObservations 方法的公共方法。在这个方法中,我们可以定义 Agent 用于学习的所有观察。这些观察将成为 Agent 的状态信息,并用于在训练过程中决策其行动。
VectorSensor sensor 参数是一个用于添加观察的 VectorSensor 实例。
这个方法的主要目的是向传感器添加观察。这个方法的实现可以根据具体的场景和需求而有所不同。
2.2.2 sensor.AddObservation(Target.localPosition)
sensor.AddObservation(Target.localPosition)这行代码的作用是将 RollerAgent 脚本中定义的 Target(Unity Transform 组件)的本地位置添加到传感器观察中。在使用机器学习代理训练时,传感器负责向代理提供状态信息,这些信息可以是代理需要了解的任何东西,例如环境中其他物体的位置、速度、颜色等等。通过将目标的位置添加到传感器观察中,代理就可以了解到目标的位置。
2.2.3 sensor.AddObservation(this.transform.localPosition)这一行代码将
sensor.AddObservation(this.transform.localPosition);这一行代码将 RollerAgent 自身的位置信息添加到 Sensor 中,具体来说,会将该 Agent 在 x、y、z 轴上的本地坐标分别作为 3 个观测值加入 Sensor 中,以供智能体在后续的训练中学习和使用。
2.2.4 sensor.AddObservation(rBody.velocity.x)
sensor.AddObservation(rBody.velocity.x)这一行代码将 RollerAgent 的刚体在 x 轴上的速度信息添加到 Sensor 中,用于作为智能体的观测值。具体来说,它将 RollerAgent 的刚体在 x 轴上的速度值作为一个观测值加入到 Sensor 中,以供智能体在后续的训练中学习和使用。
问:sensor.AddObservation(rBody.velocity.x)中为什么rBody能代替物体对象本身?
并不是代替物体对象本身,在Unity中,每个游戏对象都有一个或多个组件。这些组件是实现游戏对象功能的核心部分。其中一个常见的组件是Rigidbody,它用于模拟物理行为。在脚本中,可以通过使用GetComponent函数来获取游戏对象上的组件。
在这种情况下,rBody表示与脚本相关联的Rigidbody组件。通过将rBody传递给AddObservation函数,我们可以获取与rBody关联的游戏对象的速度信息,而不是直接获取游戏对象本身。
问:this.Rigidbodey.velocity.x 和 rBody.velocity.x 等价吗?那为什么要用GetComponent函数来获取游戏对象上的组件?
this.Rigidbody.velocity.x 和 rBody.velocity.x 是等价的,它们都是获取了同一个游戏对象上的 Rigidbody 组件,并获取了该组件的 velocity 属性中的 x 值。其中的this指的是当前脚本所在的游戏对象,Rigidbody则是游戏对象上的一个组件,它可以让游戏对象具有物理特性,例如重力、速度等。使用this.Rigidbody可以访问游戏对象上的Rigidbody组件,从而获取其速度属性。
在 Unity 中,每个游戏对象可以添加不同的组件,例如 Rigidbody、Collider、Renderer 等等。这些组件是通过脚本中的 GetComponent 函数来获取的。在脚本中使用 GetComponent 函数可以在运行时动态地获取到游戏对象上的组件,并对组件进行操作,这样就可以方便地对游戏对象进行控制和修改。
问:脚本中使用 GetComponent 函数可以在运行时动态地获取到游戏对象上的组件?能具体举例子吗?
使用 GetComponent 函数可以在 Unity 中的脚本中在运行时动态地获取到游戏对象上的组件。这意味着在游戏运行时,脚本可以通过 GetComponent 函数获取到指定游戏对象上的组件,并对组件进行操作,如读取属性值、调用方法等。这种方式使得脚本可以在运行时与游戏对象的组件进行交互,实现动态控制和修改游戏对象的功能。
假设有一个场景中有一个名为 "Player" 的游戏对象,并且该游戏对象上挂载了一个名为 "PlayerController" 的脚本。在另一个脚本中,我们需要获取 "PlayerController" 组件上的一些信息。我们可以这样写:
// 在另一个脚本中使用 GetComponent 函数获取 "PlayerController" 组件
PlayerController playerController = GameObject.Find("Player").GetComponent<PlayerController>();
// 使用 playerController 对象来访问 "PlayerController" 组件的方法和属性
playerController.Move();在这个例子中,我们使用 GameObject.Find 函数获取名为 "Player" 的游戏对象,然后使用 GetComponent 函数获取该游戏对象上挂载的 "PlayerController" 组件,并将其赋值给 playerController 变量。然后,我们就可以使用 playerController 对象来访问 "PlayerController" 组件的方法和属性了。这样就可以在运行时动态地获取到游戏对象上的组件。
2.2.5 sensor.AddObservation(rBody.velocity.z)
sensor.AddObservation(rBody.velocity.z)这一行代码将 RollerAgent 的刚体在 z 轴上的速度信息添加到 Sensor 中,用于作为智能体的观测值。具体来说,它将 RollerAgent 的刚体在 z 轴上的速度值作为一个观测值加入到 Sensor 中,以供智能体在后续的训练中学习和使用。
3. Taking Actions and Assigning Rewards
3.1 代码总括
public float forceMultiplier = 10; // 添加一个 public 变量 forceMultiplier,用于调节施加的力的倍数
public override void OnActionReceived(ActionBuffers actionBuffers) // Override 基类 Agent 的 OnActionReceived 方法
{
// Actions, size = 2
Vector3 controlSignal = Vector3.zero; // 创建一个大小为 0 的 Vector3 变量 controlSignal
controlSignal.x = actionBuffers.ContinuousActions[0]; // 将连续控制输入的第一个元素赋值给 controlSignal 的 x 分量
controlSignal.z = actionBuffers.ContinuousActions[1]; // 将连续控制输入的第二个元素赋值给 controlSignal 的 z 分量
rBody.AddForce(controlSignal * forceMultiplier); // 施加力,乘以 forceMultiplier 调节施加力的大小
// Rewards
float distanceToTarget = Vector3.Distance(this.transform.localPosition, Target.localPosition); // 计算 Agent 与 Target 之间的距离
// Reached target
if (distanceToTarget < 1.42f) // 如果 Agent 到达了 Target 的范围内(1.42f 是指一个单位立方体的对角线长度)
{
SetReward(1.0f); // 奖励 Agent
EndEpisode(); // 结束 episode
}
// Fell off platform
else if (this.transform.localPosition.y < 0) // 如果 Agent 掉下了平台
{
EndEpisode(); // 结束 episode
}
}
这段代码是 RollerAgent 类的 OnActionReceived 方法,主要是处理智能体的行动和奖励等逻辑。在该方法中,首先解析智能体的行动,将其转换成控制信号,然后通过给定的力量系数将其施加在 RollerAgent 的刚体上。然后,根据智能体距离目标的距离计算奖励。如果智能体到达目标位置,则奖励为 1,并结束该 episode;如果 RollerAgent 掉落出平台,则直接结束该 episode。
为了解决向目标移动的任务,Agent (Sphere)需要能够在x和z方向上移动。因此,代理需要两个动作:第一个决定沿x轴施加的力;第二个决定了作用在z轴上的力。(如果我们允许Agent在三维空间中移动,那么我们就需要第三个动作。)
3.2 代码分解
3.2.1 public float forceMultiplier = 10
public float forceMultiplier = 10这段代码定义了一个名为forceMultiplier的公共变量,并将其初始化为10。该变量的作用是控制代理施加的力的强度。
3.2.2 public override void OnActionReceived(ActionBuffers actionBuffers)
public override void OnActionReceived(ActionBuffers actionBuffers)OnActionReceived 是 Agent 类的方法,表示 Agent 接收到一个 action 后需要执行的操作。在这个 RollerAgent 脚本中,它用于接收动作向量,并对其进行处理。
参数 actionBuffers 是一个 ActionBuffers 对象,代表着一个动作向量。此处的动作向量是一个连续的向量,包含两个浮点数,分别表示在 x 轴和 z 轴上的控制力。
因此,该函数的主要功能是对 actionBuffers 进行解析,并将其转化为 controlSignal 控制力,再将该力传递给物理引擎,以使得 RollerAgent 在场景中移动。
3.2.3 controlSignal.x = actionBuffers.ContinuousActions[0]
Vector3 controlSignal = Vector3.zero; // 创建一个大小为 0 的 Vector3 变量 controlSignal
controlSignal.x = actionBuffers.ContinuousActions[0]; // 将连续控制输入的第一个元素赋值给 controlSignal 的 x 分量
controlSignal.z = actionBuffers.ContinuousActions[1]; // 将连续控制输入的第二个元素赋值给 controlSignal 的 z 分量
rBody.AddForce(controlSignal * forceMultiplier); // 施加力,乘以 forceMultiplier 调节施加力的大小RollerAgent使用Rigidbody. addforce()将action[]数组中的值应用到它的Rigidbody组件rBody上:
这行代码定义了一个名为controlSignal的Vector3类型变量,初始值为(0,0,0),用于存储代理(Agent)的操作信号。Vector3.zero通常代表3D向量或点类或结构中的零向量,通常表示为(0, 0, 0)。在许多编程语言和库中,包括Unity3D,Vector3.zero是一个缩写或常量,可以用来创建所有分量初始化为零的新3D向量或点。
Vector3 myVector = Vector3.zero; // 创建一个新的Vector3,x = 0,y = 0,z = 0
这行代码将第一个连续动作的值设置为控制信号向量controlSignal的x分量。actionBuffers.ContinuousActions[0]获取代理的第一个连续动作的值。在这个RollerBall例子中,代理有两个连续动作,每个动作的值范围在-1到1之间,代表x和z轴上的力量。
这行代码设置了控制信号的z轴分量,它的值从ActionBuffers中获取,index为1,代表模型的前后运动方向。具体来说,模型根据这个分量来决定是向前还是向后运动。
这行代码是将计算出来的控制向量controlSignal乘上一个forceMultiplier系数,然后通过调用AddForce函数对物体施加一个力的作用,从而实现对RollerAgent物体的控制。在这个环境下,RollerAgent物体被控制的目标是移动到一个随机移动的目标位置。
注意,forcMultiplier 类变量是在方法定义之前定义的。因为 forcMultiplier 是公共的,所以您可以设置检查器窗口中的值。
3.2.4 float distanceToTarget = Vector3.Distance(this.transform.localPosition, Target.localPosition)
float distanceToTarget = Vector3.Distance(this.transform.localPosition, Target.localPosition)这段代码计算当前Agent和目标物体之间的距离,使用的是Vector3.Distance()方法,它返回两个向量之间的欧几里得距离(也称为长度)。
具体地说,它使用当前Agent位置this.transform.localPosition和目标物体位置Target.localPosition作为两个向量的参数,计算它们之间的距离,并将结果赋值给变量distanceToTarget。
4.问题
4.1 报错
4.1.1 解决报错1
这是在 Testing the Environment 的时候出现的问题,并不是实质意义上的报错,通过方向键可以控制agent,可以实现测试。
Couldn't connect to trainer on port 5004 using API version 1.5.0. Will perform inference instead.
UnityEngine.Debug:Log (object)
Unity.MLAgents.Academy:InitializeEnvironment () (at E:/ml-agents-release_19/com.unity.ml-agents/Runtime/Academy.cs:467)
Unity.MLAgents.Academy:LazyInitialize () (at E:/ml-agents-release_19/com.unity.ml-agents/Runtime/Academy.cs:286)
Unity.MLAgents.Academy:.ctor () (at E:/ml-agents-release_19/com.unity.ml-agents/Runtime/Academy.cs:255)
Unity.MLAgents.Academy/<>c:<.cctor>b__86_0 () (at E:/ml-agents-release_19/com.unity.ml-agents/Runtime/Academy.cs:117)
System.Lazy`1<Unity.MLAgents.Academy>:get_Value ()
Unity.MLAgents.Academy:get_Instance () (at E:/ml-agents-release_19/com.unity.ml-agents/Runtime/Academy.cs:132)
Unity.MLAgents.DecisionRequester:Awake () (at E:/ml-agents-release_19/com.unity.ml-agents/Runtime/DecisionRequester.cs:57)无法使用 API 版本 1.5.0 连接到端口 5004 上的训练器,将执行推断。在环境上执行 Academy 初始化,创建一个未初始化的单例实例。这是在 Unity.MLAgents.Academy.InitializeEnvironment() 和 Unity.MLAgents.Academy.LazyInitialize() 方法中完成的。在这段代码中,会通过访问 Unity.MLAgents.Academy.Instance 获取单例实例。当 DecisionRequester 对象被唤醒时,会触发 Unity.MLAgents.DecisionRequester.Awake() 方法。
这个错误提示说明 Unity ML-Agents 无法连接到本地端口 5004 的 Trainer,通常这是因为没有正确启动 Trainer。如果你没有启动 Trainer,可以忽略这个错误,Unity ML-Agents 将会自动切换到 Inference 模式,仍然可以在 Unity 中进行 Agent 行为的模拟和可视化。
如果你已经启动了 Trainer,那么请确保 Trainer 的端口号和 Unity 中 Academy 的端口号一致。你可以在 Unity 编辑器中的 ML-Agents 设置中查看 Academy 端口号,并在 Trainer 启动时指定相同的端口号。
4.1.2 解决报错2
[INFO] Listening on port 5004. Start training by pressing the Play button in the Unity Editor.
[INFO] Connected to Unity environment with package version 2.2.1-exp.1 and communication version 1.5.0
Traceback (most recent call last):
File "D:\RuanJianAnZhunangWeiZhi\anaconda\anaconda3\envs\mlagents\Scripts\mlagents-learn-script.py", line 33, in <module>
sys.exit(load_entry_point('mlagents', 'console_scripts', 'mlagents-learn')())
File "e:\ml-agents-release_19\ml-agents\mlagents\trainers\learn.py", line 260, in main
run_cli(parse_command_line())
File "e:\ml-agents-release_19\ml-agents\mlagents\trainers\learn.py", line 256, in run_cli
run_training(run_seed, options, num_areas)
File "e:\ml-agents-release_19\ml-agents\mlagents\trainers\learn.py", line 132, in run_training
tc.start_learning(env_manager)
File "e:\ml-agents-release_19\ml-agents-envs\mlagents_envs\timers.py", line 305, in wrapped
return func(*args, **kwargs)
File "e:\ml-agents-release_19\ml-agents\mlagents\trainers\trainer_controller.py", line 173, in start_learning
self._reset_env(env_manager)
File "e:\ml-agents-release_19\ml-agents-envs\mlagents_envs\timers.py", line 305, in wrapped
return func(*args, **kwargs)
File "e:\ml-agents-release_19\ml-agents\mlagents\trainers\trainer_controller.py", line 105, in _reset_env
env_manager.reset(config=new_config)
File "e:\ml-agents-release_19\ml-agents\mlagents\trainers\env_manager.py", line 68, in reset
self.first_step_infos = self._reset_env(config)
File "e:\ml-agents-release_19\ml-agents\mlagents\trainers\subprocess_env_manager.py", line 446, in _reset_env
ew.previous_step = EnvironmentStep(ew.recv().payload, ew.worker_id, {}, {})
File "e:\ml-agents-release_19\ml-agents\mlagents\trainers\subprocess_env_manager.py", line 101, in recv
raise env_exception
mlagents_envs.exception.UnityTimeOutException: The Unity environment took too long to respond. Make sure that :
The environment does not need user interaction to launch
The Agents' Behavior Parameters > Behavior Type is set to "Default"
The environment and the Python interface have compatible versions.
If you're running on a headless server without graphics support, turn off display by either passing --no-graphics option or build your Unity executable as server build.这个错误信息表明 Unity 环境没有响应,可能是因为以下原因之一:
- 确保环境不需要用户交互才能启动。
- 确保代理的行为参数 > 行为类型设置为 "Default"。
- 确保环境和 Python 接口版本兼容。
- 如果您正在运行无图形支持的无头服务器,请通过传递 --no-graphics 选项或构建 Unity 可执行文件作为服务器构建来关闭显示。
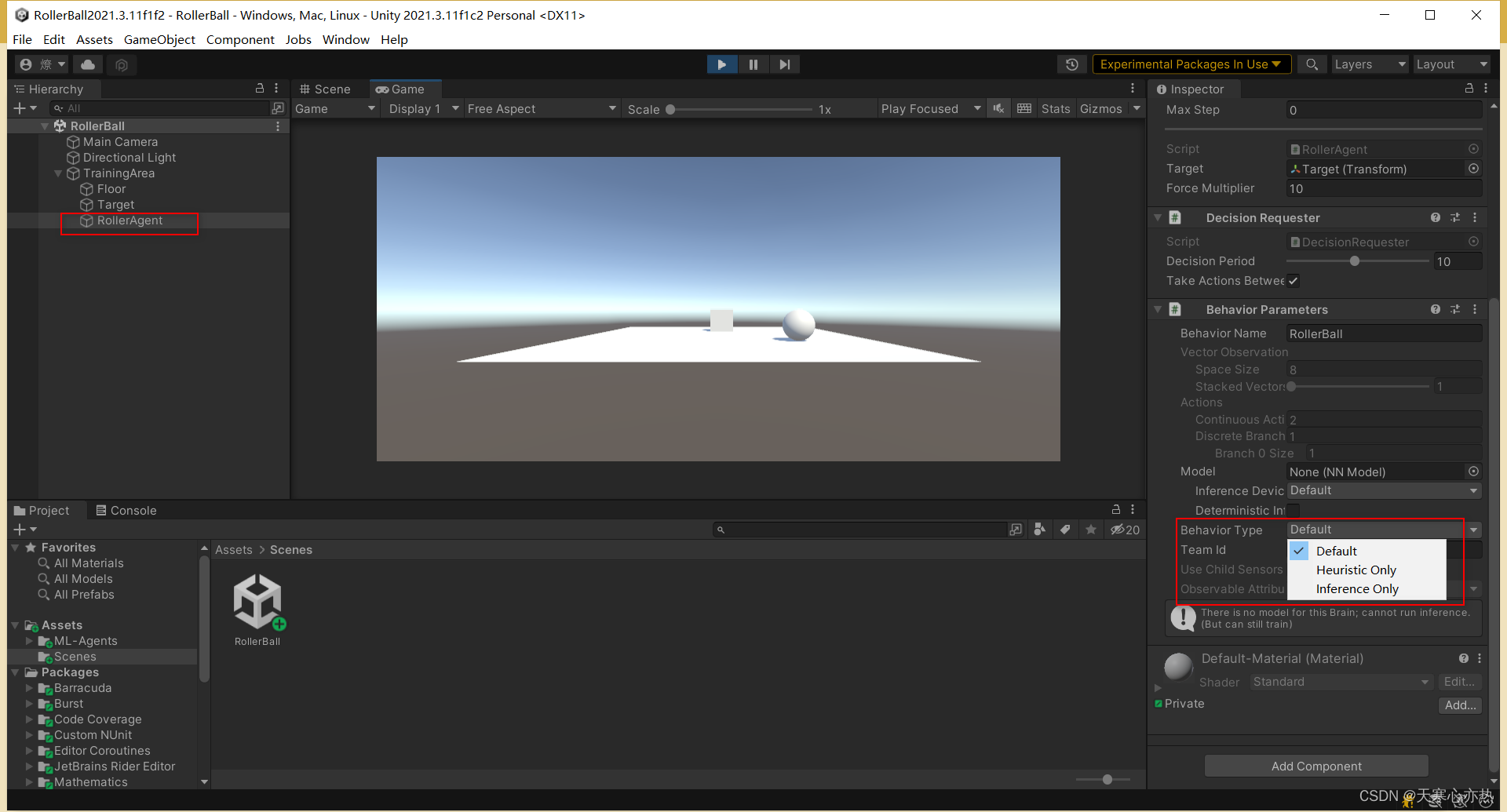
解决方式就是错误原因的第二点,确保代理的行为参数 > 行为类型设置为 "Default"。
是因为在测试的时候,将Behavior Type 设置成了Heuristic Only(仅启用启发式),训练时需要设置成default。
4.2智能体移动的连续动作和离散动作
在强化学习(Reinforcement Learning)中,智能体(Agent)通常需要根据当前环境状态做出动作来实现特定的目标。这些动作可以分为连续动作和离散动作两种类型。
连续动作(Continuous Actions)指的是智能体可以在一个连续的动作空间内选择动作,通常是一个实数范围内的值。例如,在一个自动驾驶汽车的控制问题中,连续动作可能包括控制车辆的加速度、刹车力度和转向角度等。连续动作可以有无限多的可能性,需要在连续范围内进行选择,通常通过一个连续函数来表示动作选择的策略。
离散动作(Discrete Actions)指的是智能体在有限的动作选项中进行选择,通常是一个离散的动作空间。例如,在一个电子游戏中,离散动作可能包括向左移动、向右移动、跳跃、攻击等动作。离散动作通常通过一个离散的动作空间来表示,例如一个离散的动作索引或一个独热编码的向量。
在强化学习中,智能体根据当前的环境状态选择动作,并通过与环境的交互来学习最优的动作策略。对于连续动作,智能体需要通过对连续动作空间进行采样或者使用优化算法来选择合适的动作。而对于离散动作,智能体可以通过在离散动作空间中选择具体的动作进行决策。
不同类型的动作空间(连续或离散)在强化学习中具有不同的特点和应用场景,需要根据具体问题的需求和环境的特性来选择合适的动作表示方式。