Hive分区和传统数据库的分区的异同:
分区技术是处理大型数据集经常用到的方法。在Oracle中,分区表中的每个分区是一个独立的segment段对象,有多少个分区,就存在多少个相应的数据库对象。而在Postgresql中分区表其实相当于分别建立了很多小表,其实和Oracle是异曲同工罢了。
在HIVE中的管理表其实就是在数据库目录下的一个和表名称一样的目录,数据文件都存放在该目录下,如果在Hive中查询一张表数据,那就需要遍历该目录下的所有数据文件,如果表的数据非常庞大,那查询性能会很不好。
管理表的分区:
在Hive中的分区表概念和传统数据库的类似,但也有一些不同。在Hive中如果对一个张管理表建立分区,那么将会在数据库的目录下的表目录下再建几层目录,这个根据分区键的个数而定,如果是一个分区键,那么就会多出来一层目录,如果是两个分区键,那么就会相应的多出来两层目录。Hive就是根据目录将Hive表中存放的数据进行了分割成多块。当查询的时候,where条件中遇到 了分区列条件限制,就会在这些目录上进行匹配,如果发现相应的目录,那就只会访问匹配的目录,而不会访问其他的分区目录,这样就大大的减少了数据的访问量。
我现在创建一张管理表emp
DROP TABLE IF EXISTS emp;
CREATE TABLE IF NOT EXISTS emp(
name STRING,
salary FLOAT,
subordinates ARRAY<STRING>,
deductions MAP<STRING,FLOAT>,
address STRUCT<street:STRING,city:STRING,province:STRING,zip:INT>
)
PARTITIONED BY (province STRING,city STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
COLLECTION ITEMS TERMINATED BY ','
MAP KEYS TERMINATED BY ':';
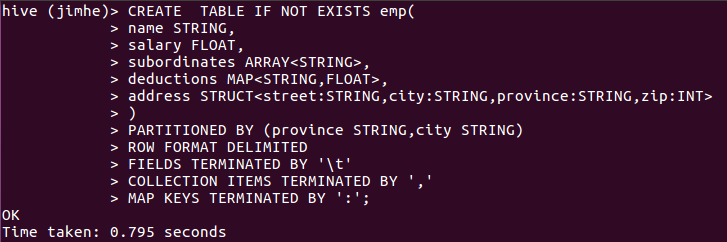
表创建成功。

然后创建管理表的分区,不创建分区的话,可以在导入数据的时候指向一个分区键的值,系统会自动创建分区

然后我向分区中导入本地数据文件:
数据文件emp_shanxi的数据如下所示:
vi emp_shanxi
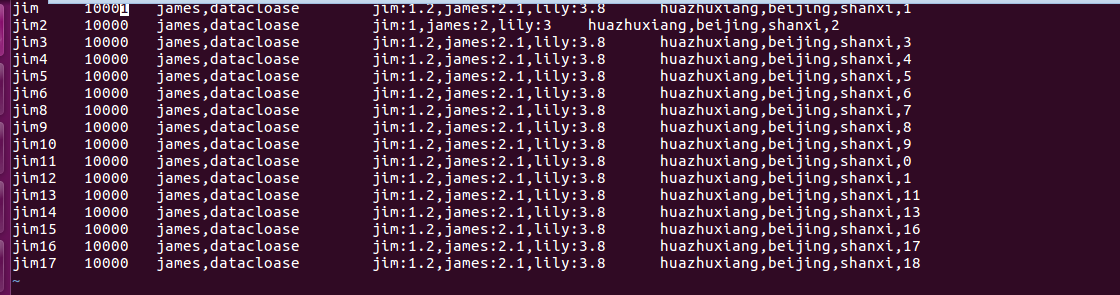
将该数据文件导入到hive。

对于其他数据也用同样的方法进行导入
LOAD DATA LOCAL INPATH './emp_shandong' OVERWRITE INTO TABLE emp
PARTITION(province='shandong',city='qingdao');
现在可以查看下hive数据库的目录结构:


emp数据库表下面产生了这么多的分区目录,继续进入分区目录中,会发现二级分区目录,二级目录下就是对应分区的数据文件;


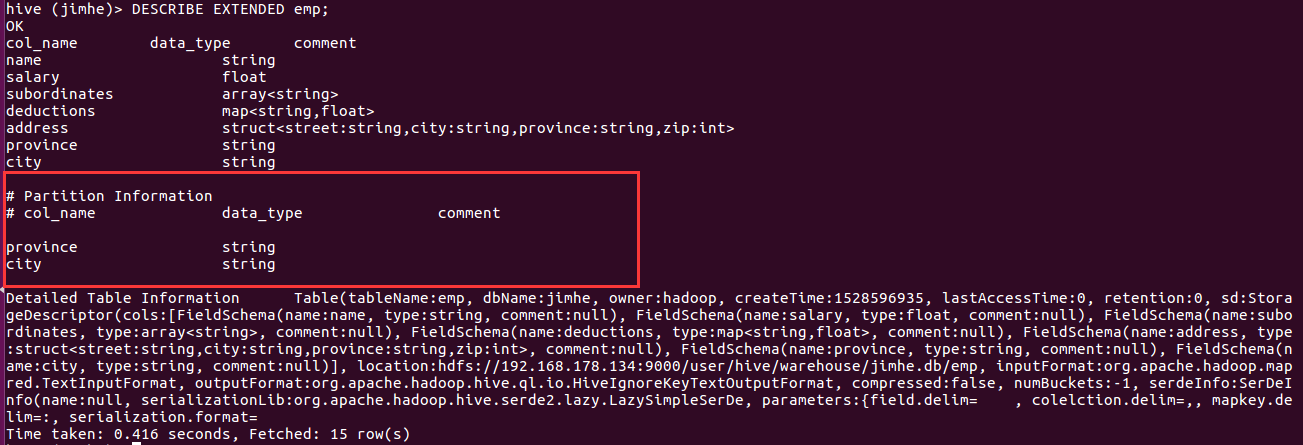
查看分区表的元数据信息:
现在执行Hsql看下分区裁剪效果:

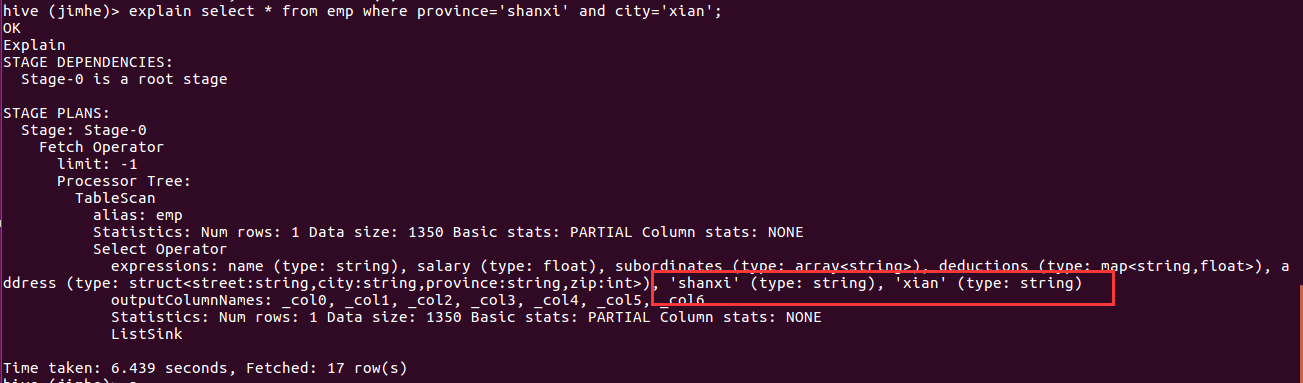
通过查看执行计划,可以看到分区列其实在Hive里面相当于虚拟列放到了普通列的后面。
也可以采用查询语句向表中插入数据,我参照《Hive编程指南》中的例子,jimdb库中的employees表和emp表表结构和分区键都一样。但是执行下来报错:
hive (jimhe)> INSERT OVERWRITE TABLE emp
> PARTITION(province='guangdong',city='shenzhen')
> SELECT * FROM jimdb.employees
> WHERE province='guangdong' AND city='shenzhen';
FAILED: SemanticException [Error 10044]: Line 1:23 Cannot insert into target table because column number/types are different ''shenzhen'': Table insclause-0 has 5 columns, but query has 7 columns.
根据错误提示,原因可能是Hive在识别select * from jimdb.employees WHERE province='guangdong' AND city='shenzhen' 这块语句时,select * 查询出来的列也包括了两列分区列,一共就7个字段,而insert 的表只能识别到5个字段,因此在这种情况下,只能对语句进行改造:
hive (jimhe)> INSERT OVERWRITE TABLE emp
> PARTITION(province='guangdong',city='shenzhen')
> SELECT name,salary,subordinates,deductions,address FROM jimdb.employees
> WHERE province='guangdong' AND city='shenzhen';
Query ID = hadoop_20180610093118_a335884d-778a-42a7-972c-590f5ff5019d
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Job running in-process (local Hadoop)
2018-06-10 09:31:22,390 Stage-1 map = 0%, reduce = 0%
2018-06-10 09:31:25,425 Stage-1 map = 100%, reduce = 0%
Ended Job = job_local1736204471_0001
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to: hdfs://192.168.178.134:9000/user/hive/warehouse/jimhe.db/emp/province=guangdong/city=shenzhen/.hive-staging_hive_2018-06-10_09-31-18_305_1073974836886037247-1/-ext-10000
Loading data to table jimhe.emp partition (province=guangdong, city=shenzhen)
Partition jimhe.emp{province=guangdong, city=shenzhen} stats: [numFiles=1, numRows=21504, totalSize=1951488, rawDataSize=1929984]
MapReduce Jobs Launched:
Stage-Stage-1: HDFS Read: 1904512 HDFS Write: 1951594 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
name salary subordinates deductions address
Time taken: 8.99 seconds
如果一个分区表的分区过多,可以使用一种将from 源表名放到最前面,然后将所有的insert ...select .....语句放到一个语句中进行执行。
FROM jimdb.employees
INSERT OVERWRITE TABLE emp
PARTITION(province='guangdong',city='shenzhen')
SELECT name,salary,subordinates,deductions,address
WHERE province='guangdong' AND city='shenzhen'
INSERT OVERWRITE TABLE emp
PARTITION(province='hainan',city='haikou')
SELECT name,salary,subordinates,deductions,address
WHERE province='hainan' AND city='haikou'
INSERT OVERWRITE TABLE emp
PARTITION(province='zhejiang',city='hangzhou')
SELECT name,salary,subordinates,deductions,address
WHERE province='zhejiang' AND city='hangzhou'
INSERT OVERWRITE TABLE emp
PARTITION(province='shandong',city='qingdao')
SELECT name,salary,subordinates,deductions,address
WHERE province='shandong' AND city='qingdao';
具体的执行过程如下:
hive (jimhe)> FROM jimdb.employees
> INSERT OVERWRITE TABLE emp
> PARTITION(province='guangdong',city='shenzhen')
> SELECT name,salary,subordinates,deductions,address
> WHERE province='guangdong' AND city='shenzhen'
> INSERT OVERWRITE TABLE emp
> PARTITION(province='hainan',city='haikou')
> SELECT name,salary,subordinates,deductions,address
> WHERE province='hainan' AND city='haikou'
> INSERT OVERWRITE TABLE emp
> PARTITION(province='zhejiang',city='hangzhou')
> SELECT name,salary,subordinates,deductions,address
> WHERE province='zhejiang' AND city='hangzhou'
> INSERT OVERWRITE TABLE emp
> PARTITION(province='shandong',city='qingdao')
> SELECT name,salary,subordinates,deductions,address
> WHERE province='shandong' AND city='qingdao';
Query ID = hadoop_20180610094833_3f5718bf-2082-46d2-b282-77f9b43c56a0
Total jobs = 9
Launching Job 1 out of 9
Number of reduce tasks is set to 0 since there's no reduce operator
Job running in-process (local Hadoop)
2018-06-10 09:48:36,639 Stage-4 map = 0%, reduce = 0%
2018-06-10 09:48:39,669 Stage-4 map = 100%, reduce = 0%
Ended Job = job_local832435077_0004
Stage-7 is selected by condition resolver.
Stage-6 is filtered out by condition resolver.
Stage-8 is filtered out by condition resolver.
Stage-13 is selected by condition resolver.
Stage-12 is filtered out by condition resolver.
Stage-14 is filtered out by condition resolver.
Stage-19 is selected by condition resolver.
Stage-18 is filtered out by condition resolver.
Stage-20 is filtered out by condition resolver.
Stage-25 is selected by condition resolver.
Stage-24 is filtered out by condition resolver.
Stage-26 is filtered out by condition resolver.
Moving data to: hdfs://192.168.178.134:9000/user/hive/warehouse/jimhe.db/emp/province=guangdong/city=shenzhen/.hive-staging_hive_2018-06-10_09-48-33_641_6266993806449569955-1/-ext-10000
Moving data to: hdfs://192.168.178.134:9000/user/hive/warehouse/jimhe.db/emp/province=hainan/city=haikou/.hive-staging_hive_2018-06-10_09-48-33_641_6266993806449569955-1/-ext-10002
Moving data to: hdfs://192.168.178.134:9000/user/hive/warehouse/jimhe.db/emp/province=zhejiang/city=hangzhou/.hive-staging_hive_2018-06-10_09-48-33_641_6266993806449569955-1/-ext-10004
Moving data to: hdfs://192.168.178.134:9000/user/hive/warehouse/jimhe.db/emp/province=shandong/city=qingdao/.hive-staging_hive_2018-06-10_09-48-33_641_6266993806449569955-1/-ext-10006
Loading data to table jimhe.emp partition (province=guangdong, city=shenzhen)
Loading data to table jimhe.emp partition (province=hainan, city=haikou)
Loading data to table jimhe.emp partition (province=zhejiang, city=hangzhou)
Loading data to table jimhe.emp partition (province=shandong, city=qingdao)
Partition jimhe.emp{province=guangdong, city=shenzhen} stats: [numFiles=1, numRows=0, totalSize=1951488, rawDataSize=0]
Partition jimhe.emp{province=hainan, city=haikou} stats: [numFiles=1, numRows=0, totalSize=1800960, rawDataSize=0]
Partition jimhe.emp{province=zhejiang, city=hangzhou} stats: [numFiles=1, numRows=0, totalSize=1929982, rawDataSize=0]
Partition jimhe.emp{province=shandong, city=qingdao} stats: [numFiles=1, numRows=0, totalSize=6263742, rawDataSize=0]
MapReduce Jobs Launched:
Stage-Stage-4: HDFS Read: 15481747 HDFS Write: 13898182 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
name salary subordinates deductions address
Time taken: 9.653 seconds
删除分区:
在未删除分区前查询分区province='guangdong' ,city='shenzhen'的数据条数
hive (jimhe)> select count(*) from emp where province='guangdong' and city='shenzhen';
Query ID = hadoop_20180610093523_f0ed58c9-e61a-44fa-aa32-ea81d0b94898
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Job running in-process (local Hadoop)
2018-06-10 09:35:25,828 Stage-1 map = 100%, reduce = 0%
2018-06-10 09:35:26,843 Stage-1 map = 100%, reduce = 100%
Ended Job = job_local223418669_0002
MapReduce Jobs Launched:
Stage-Stage-1: HDFS Read: 7712212 HDFS Write: 3903188 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
_c0
21504
Time taken: 3.121 seconds, Fetched: 1 row(s)
然后执行删除分区语句:
hive (jimhe)> ALTER TABLE emp DROP PARTITION(province='guangdong',city='shenzhen');
Dropped the partition province=guangdong/city=shenzhen
OK
Time taken: 1.092 seconds
查询分区的数据:
hive (jimhe)> select count(*) from emp where province='guangdong' and city='shenzhen';
Query ID = hadoop_20180610093848_2f009a64-e784-414d-a03d-5d5951b65783
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Job running in-process (local Hadoop)
2018-06-10 09:38:50,785 Stage-1 map = 100%, reduce = 100%
Ended Job = job_local1184300512_0003
MapReduce Jobs Launched:
Stage-Stage-1: HDFS Read: 7712212 HDFS Write: 3903188 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
_c0
0
Time taken: 1.854 seconds, Fetched: 1 row(s)
在数据库表目录中查询分区目录,看是否删除掉相应的目录:
hadoop@192-168-178-134:/usr/local/hive/hive-1.2.2/bin$ hdfs dfs -ls /user/hive/warehouse/jimhe.db/emp/province=guangdong
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2018-06-09 19:22 /user/hive/warehouse/jimhe.db/emp/province=guangdong/city=guangzhou
发现的确已经删除掉了。