统计学习关于数据的基本假设是同类数据具有一定的统计规律性。
统计学习的目的是对数据进行预测和分析。
统计学习关于数据的基本假设是同类数据具有一定的统计规律性。
统计学习的目的是对数据进行预测和分析。
统计学习分为:监督学习,非监督学习,半监督学习,和强化学习
统计学习三要素:模型、策略和算法
实现统计学习的步骤:
① 得到一个有限的数据集合;
② 确定包含所有可能的模型的假设空间,即学习模型的集合;
③ 确定模型选择的准则,即学习策略;
④ 实现求解最优模型的算法,即学习的算法;
⑤ 通过学习方法选择最优模型;
⑥ 利用学习的最优模型对数据进行预测或分析
统计学习研究分类
1.统计学习方法:旨在开发新的学习方法
2.统计学习理论:探求学习方法的有效性与效率,以及统计学习的基本理论问题
3.统计学习应用:将统计学习方法应用到实际问题中去,解决实际问题
统计学习的重要性
1.统计学习是处理海量数据的有效方法
2.统计学习是计算机智能化的有效手段
3.统计学习是计算机科学发展的一个重要组成部分。可以认为计算机科学由三维组成:系统、计算、信息。统计学习主要属于信息这一维,并起核心作用。
监督学习的任务是学习一个模型,使模型能够对任意给定的输入,对其相应的输出做出一个好的预测。
每个具体的输入是一个实例,通常由特征向量表示。这时,所有特征向量存在的空间称为特征空间。模型实际上都是定义在特征空间上的。
对预测任务给与不同的名称:
1) 输入变量与输出变量均为连续变量的预测问题称为回归问题;
2) 输出变量为有限个离散变量的预测问题称为分类问题;
3) 输入变量与输出变量均为变量序列的预测问题称为标注问题;
监督学习的目的在于学习一个由输入到输出的映射,这一映射由模型来表示。
统计学习的目标在于从假设空间中选取最优模型。
损失函数:度量模型一次损失的好坏。风险系数度量平均意义下模型预测的好坏。
损失函数:是定义在单个样本上的,算的是一个样本的误差。
代价函数: 是定义在整个训练集上的,是所有样本误差的平均,也就是损失函数的平均。
目标函数: 代价函数(经验风险) + 正则化项。
正则化是结构风险最小化策略的实现,是在经验风险上加一个正则化项。正则化的作用是选择经验风险与模型复杂度同时较小的模型。
通常将学习方法对未知数据的预测能力称为泛化能力,这是学习方法本质上重要的性质。
监督模型又可分为生成方法和判断方法,所学到的模型分别称为生成模型和判别模型。
生成模型,就是生成(数据的分布)的模型;
判别模型,就是判别(数据输出量)的模型;
生成方法:由数据学习联合概率分布P(X,Y),然后求出条件概率分布P(Y|X)作为预测的模型即生成模型。典型的生成模型有朴素贝叶斯和隐马尔可夫模型。
判别方法:由数据直接学习决策函数f(X)或者条件概率分布P(Y|X)作为预测模型即判别模型。判别方法关心的事对给定的输入X应该预测什么样的输出Y。典型的判别模型包括:kNN,感知机,决策树,LR,最大熵模型,支持向量机,提升方法和条件随机场等。
在监督学习中,生成方法和判别方法各有优缺点:生成方法可以还原联合概率分布,判别方法不能;生成方法收敛速度快;生成方法可以学习存在隐变量的模型,判别方法就不能用;判别方法学习的准确率更高且可以简化学习问题。
分类器的性能指标:
1.准确率(Aaccuracy):对整个样本集的判定能力,即将正的判定为正、负的判定为负
2.灵敏度(Sensitivity):将正样本预测为正样本的能力
3.特异度(Specificity):将负样本预测为负样本的能力
准确率(accuracy)
准确率是最常用的分类性能指标。拿最常见的二分类问题来说,我们的模型无非是想要把正类和负类预测识别出来。在测试集中识别对的数量(不论是把正样本识别为正样本还是把负样本识别为负样本)除以测试集的数据总量就是准确率。在用scikit-learn调用分类器进行分类的时候,模型返回的score值其实就是准确率。
精确率(precision)和召回率(recall)以及F值
精确率容易和准确率被混为一谈。其实,精确率只是针对预测正确的正样本而不是所有预测正确的样本。它可以由预测正确的正样本数除以模型所有预测为正样本的数目之比来计算出来。表现为预测出是正的里面有多少真正是正的。
而召回率是由预测正确的正样本数目除以测试集中真正的实际正样本数目之比计算得出。表现出所有真正是正样本中分类器能召回多少。
哈哈,是不是晕了?下面盗一张图:
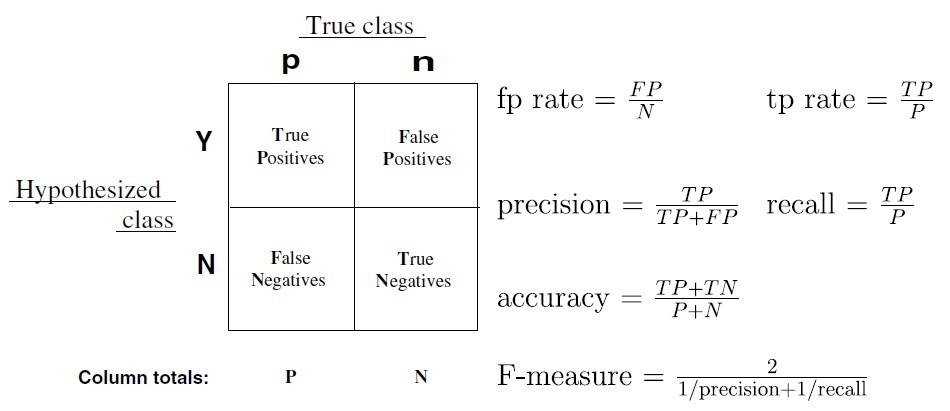
精确率 precision = TP / (TP+FP)
召回率 recall = TP / (TP+FN)
还有一个指标是F值,它是精确率和召回率的调和值,如上图。很多推荐系统的评测指标就是用F值的。
标注问题也是一个监督学习问题,可以认为标注问题是分类问题的一个推广。
标注问题的输入是一个观测序列,输出的是一个标记序列或状态序列。也就是说,分类问题的输出是一个值,而标注问题输出是一个向量,向量的每个值属于一种标记类型。
标注常用的机器学习方法有:隐性马尔可夫模型、条件随机场。
自然语言处理中的词性标注(part of speech tagging)就是一个典型的标注问题:给定一个由单词组成的句子,对这个句子中的每一个单词进行词性标注,即对一个单词序列预测其对应的词性标记序列。
回归问题也属于监督学习中的一类。回归用于预测输入变量与输出变量之间的关系,特别是当输入变量的值发生变化时,输出变量的值随之发生的变化。
回归模型正是表示从输入变量到输出变量之间映射的函数。回归问题的学习等价于函数拟合:选择一条函数曲线,使其很好地拟合已知数据且很好地预测未知数据。
回归问题按照输入变量的个数,可以分为一元回归和多元回归;按照输入变量与输出变量之间关系的类型,可以分为线性回归和非线性回归。
回归学习最常用的损失函数是平方损失,在此情况下,回归问题可以由著名的最小二乘法求解。
一个回归学习用于股票预测的例子:假设知道一个公司在过去不同时间点的市场上的股票价格(或一段时间的平均价格),以及在各个时间点之间可能影响该公司股份的信息(比如,公司前一周的营业额)。目标是从过去的数据学习一个模型,使它可以基于当前的信息预测该公司下一个时间点的股票价格。具体地,将影响股价的信息视为自变量(输入特征),而将股价视为因变量(输出的值)。将过去的数据作为训练数据,就可以学习一个回归模型,并对未来股份进行预测。实际我们知道想做出一个满意的股价预测模型是很难的,因为影响股份的因素非常多,我们未必能获得那些有用的信息。
分类和回归的区别在于输出变量的类型。
定量输出称为回归,或者说是连续变量预测;
定性输出称为分类,或者说是离散变量预测。
举个例子:
预测明天的气温是多少度,这是一个回归任务;
预测明天是阴、晴还是雨,就是一个分类任务。