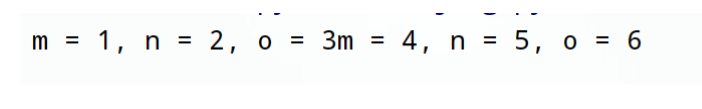线程简述
一个程序运行起来后,一定有一个执行代码的东西,这个东西就是线程;
一般计算(CPU)密集型任务适合多进程,IO密集型任务适合多线程;
一个进程可拥有多个并行的(concurrent)线程,当中每一个线程,共享当前进程的资源
以下是对发现的几种多线程进行的汇总整理,均已测试运行
多线程实现的四种方式分别是:
multiprocessing下面有两种:
from multiprocessing.dummy import Pool as ThreadPool # 线程池
from multiprocessing.pool import ThreadPool # 线程池,用法无区别,唯一区别这个是线程池
另外两种:
from concurrent.futures import ThreadPoolExecutor # python原生线程池,这个更主流
import threadpool # 线程池,需要 pip install threadpool,很早之前的
方式1 multiprocessing.dummy Pool()
-
非阻塞方法
multiprocessing.dummy.Pool.apply_async() 和 multiprocessing.dummy.Pool.imap()
线程并发执行 -
阻塞方法
multiprocessing.dummy.Pool.apply()和 multiprocessing.dummy.Pool.map()
线程顺序执行
from multiprocessing.dummy import Pool as Pool
import time
def func(msg):
print('msg:', msg)
time.sleep(2)
print('end:')
pool = Pool(processes=3)
for i in range(1, 5):
msg = 'hello %d' % (i)
pool.apply_async(func, (msg,)) # 非阻塞,子线程有返回值
# pool.apply(func,(msg,)) # 阻塞,apply()源自内建函数,用于间接的调用函数,并且按位置把元祖或字典作为参数传入。子线程无返回值
# pool.imap(func,[msg,]) # 非阻塞, 注意与apply传的参数的区别 无返回值
# pool.map(func, [msg, ]) # 阻塞 子线程无返回值
print('Mark~~~~~~~~~~~~~~~')
pool.close()
pool.join() # 调用join之前,先调用close函数,否则会出错。执行完close后不会有新的进程加入到pool,join函数等待所有子进程结束
print('sub-process done')
运行结果: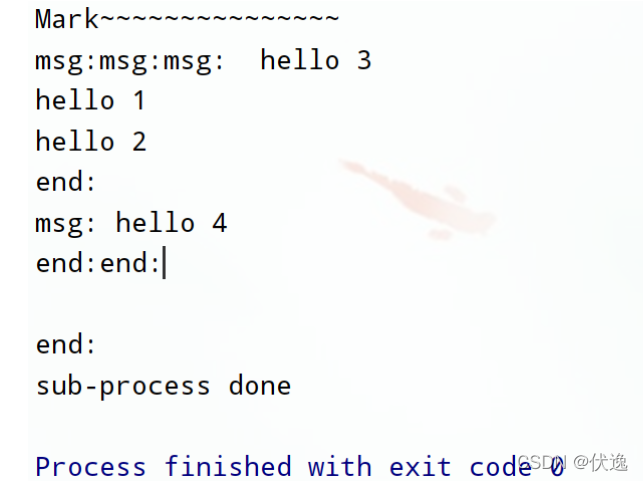
方式2:multiprocessing.pool ThreadPool Threading()
from multiprocessing.pool import ThreadPool # 线程池,用法无区别,唯一区别这个是线程池
from multiprocessing.dummy import Pool as ThreadPool # 线程池
import os
import time
print("hi outside of main()")
def hello(x):
print("inside hello()")
print("Proccess id: %s" %(os.getpid()))
time.sleep(3)
return x*x
if __name__ == "__main__":
p = ThreadPool(5)
pool_output = p.map(hello, range(3))
print(pool_output)
运行结果:

方式3:主流ThreadPoolExecutor
from concurrent.futures import ThreadPoolExecutor
import threading
import time
# 定义一个准备作为线程任务的函数
def action(max):
my_sum = 0
for i in range(max):
print(threading.current_thread().name + ' ' + str(i))
my_sum += i
return my_sum
# 创建一个包含2条线程的线程池
pool = ThreadPoolExecutor(max_workers=2)
# 向线程池提交一个task, 20会作为action()函数的参数
future1 = pool.submit(action, 20)
# 向线程池再提交一个task, 30会作为action()函数的参数
future2 = pool.submit(action, 30)
# 判断future1代表的任务是否结束
print(future1.done())
time.sleep(3)
# 判断future2代表的任务是否结束
print(future2.done())
# 查看future1代表的任务返回的结果
print(future1.result())
# 查看future2代表的任务返回的结果
print(future2.result())
# 关闭线程池
pool.shutdown()
运行结果:

方式4:threadpool
需要 pip install threadpool
import threadpool
def hello(m, n, o):
""""""
print("m = %s, n = %s, o = %s" % (m, n, o))
if __name__ == '__main__':
# 方法1
# lst_vars_1 = ['1', '2', '3']
# lst_vars_2 = ['4', '5', '6']
# func_var = [(lst_vars_1, None), (lst_vars_2, None)]
# 方法2
dict_vars_1 = {'m': '1', 'n': '2', 'o': '3'}
dict_vars_2 = {'m': '4', 'n': '5', 'o': '6'}
func_var = [(None, dict_vars_1), (None, dict_vars_2)]
# 定义了一个线程池,表示最多可以创建poolsize这么多线程
pool = threadpool.ThreadPool(2)
# 调用makeRequests创建了要开启多线程的函数,以及函数相关参数和回调函数,其中回调函数可以不写
requests = threadpool.makeRequests(hello, func_var)
[pool.putRequest(req) for req in requests] # 将所有要运行多线程的请求扔进线程池
pool.wait() # 等待所有线程完成工作后退出
"""
[pool.putRequest(req) for req in requests]等同于
for req in requests:
pool.putRequest(req)
"""
运行结果: