1.Glusterfs简介
GlusterFS是Scale-Out存储解决方案Gluster的核心,它是一个开源的分布式文件系统,具有强大的横向扩展能力,通过扩展能够支持数PB存储容量和处理数千客户端。GlusterFS借助TCP/IP或InfiniBandRDMA网络将物理分布的存储资源聚集在一起,使用单一全局命名空间来管理数据。
说起glusterfs可能比较陌生,可能大家更多的听说和使用的是NFS,GFS,HDFS之类的,这之中的NFS应该是使用最为广泛的,简单易于管理,但是NFS以及后边会说到MooseFS都会存在单点故障,为了解决这个问题一般情况下都会结合DRBD进行块儿复制。但是glusterfs就完全不用考虑这个问题了,因为它是一个完全的无中心的系统。
2.Glusterfs特点
扩展性和高性能
GlusterFS利用双重特性来提供几TB至数PB的高扩展存储解决方案。Scale-Out架构允许通过简单地增加资源来提高存储容量和性能,磁盘、计算和I/O资源都可以独立增加,支持10GbE和InfiniBand等高速网络互联。Gluster弹性哈希(ElasticHash)解除了GlusterFS对元数据服务器的需求,消除了单点故障和性能瓶颈,真正实现了并行化数据访问。
高可用性
GlusterFS可以对文件进行自动复制,如镜像或多次复制,从而确保数据总是可以访问,甚至是在硬件故障的情况下也能正常访问。自我修复功能能够把数据恢复到正确的状态,而且修复是以增量的方式在后台执行,几乎不会产生性能负载。GlusterFS没有设计自己的私有数据文件格式,而是采用操作系统中主流标准的磁盘文件系统(如EXT3、ZFS)来存储文件,因此数据可以使用各种标准工具进行复制和访问。
弹性卷管理
数据储存在逻辑卷中,逻辑卷可以从虚拟化的物理存储池进行独立逻辑划分而得到。存储服务器可以在线进行增加和移除,不会导致应用中断。逻辑卷可以在所有配置服务器中增长和缩减,可以在不同服务器迁移进行容量均衡,或者增加和移除系统,这些操作都可在线进行。文件系统配置更改也可以实时在线进行并应用,从而可以适应工作负载条件变化或在线性能调优。
(以上部分内容来源互联网)
- #安装依赖工具
- yum install xfsprogs wget
- yum install fuse fuse-libs
- #格式化磁盘并创建GFS分区
- fdisk /dev/sdb
- mkfs.xfs -i size=512 /dev/sdb1
- mount /dev/sdb1 /mnt/sdb1
- #安装gluster
- wget http://download.gluster.org/pub/gluster/glusterfs/LATEST/CentOS/gluster-epel.repo -O /etc/yum.repo.d/glusterfs.repo
- yum install glusterfs{,-server,-fuse,-geo-replication}
- #启动glusterfs
- /etc/init.d/glusterd start
- /etc/init.d/glusterd stop
- #如果需要在系统启动时开启glusterd
- chkconfig glusterd on
- $gluster peer probe host|ip
- $gluster peer status #查看除本机外的其他设备状态
- $gluster peer detach host|ip #如果希望将某设备从存储池中删除
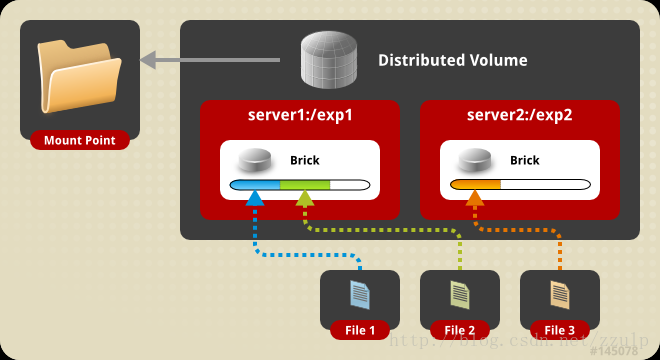
- $gluster volume create mamm-volume node1:/media node2:/media node3:/media ...
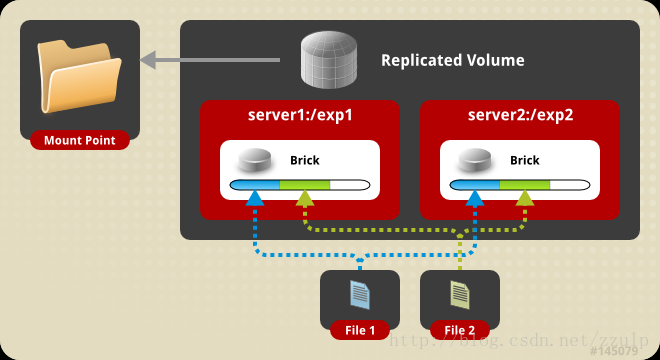
- $gluster volume create mamm-volume repl 2 node1:/media node2:/media
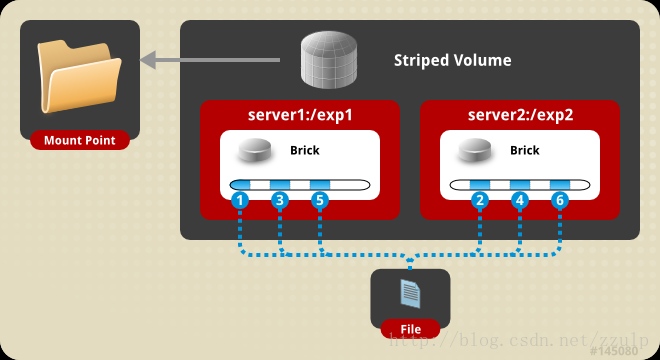
- $gluster volume create mamm-volume stripe 2 node1:/media node2:/media
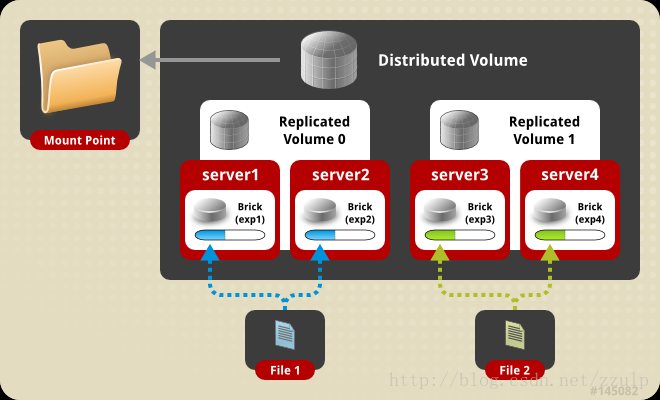
- $gluster volume create dr-volume repl 2 node1:/exp1 node2:/exp2 node3:/exp3 node4:/exp4
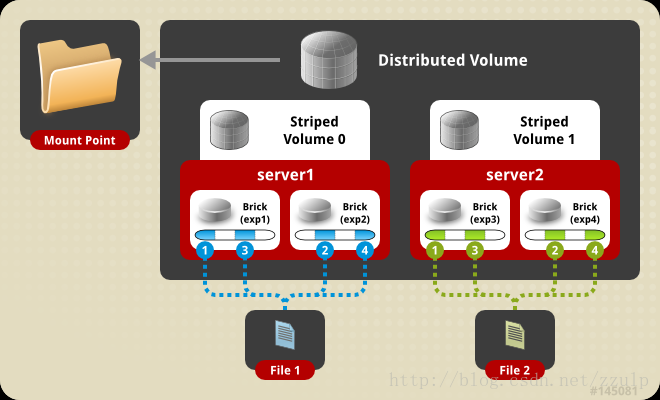
- $gluster volume create ds-volume stripe 2 node1:/exp1 node1:/exp2 [&] node2:/exp3 node2:/exp4
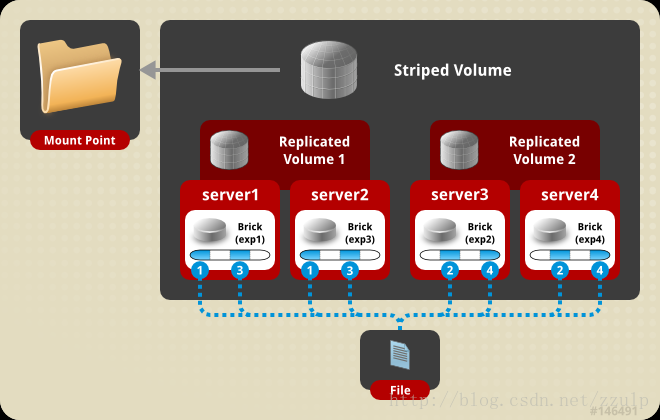
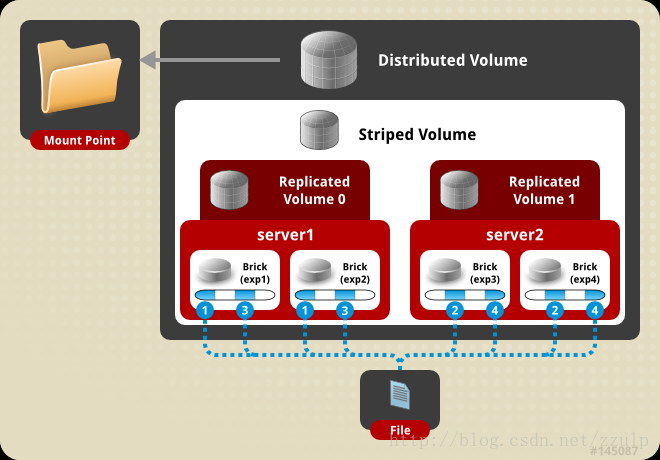
- $gluster volume create test-volume stripe 2 replica 2 server1:/exp1 server2:/exp2 server3:/exp3 server4:/exp4
- $gluster volume create test-volume stripe 2 replica 2 server1:/exp1 server2:/exp2 server3:/exp3 server4:/exp4 server5:/exp5 server6:/exp6 server7:/exp7 server8:/exp8
- $gluster volume start mamm-volume
- $gluster volume stop mamm-volume
- $gluster volume delete mamm-volume
- $gluster volume add-brick mamm-volume [strip|repli <count>] brick1...
- $gluster volume remove-brick mamm-volume [repl <count>] brick1...
- gluster volume replace-brick mamm-volume old-brick new-brick [start|pause|abort|status|commit]
- #迁移需要完成一系列的事务,假如我们准备将mamm卷中的brick3替换为brick5
- #启动迁移过程
- $gluster volume replace-brick mamm-volume node3:/exp3 node5:/exp5 start
- #暂停迁移过程
- $gluster volume replace-brick mamm-volume node3:/exp3 node5:/exp5 pause
- #中止迁移过程
- $gluster volume replace-brick mamm-volume node3:/exp3 node5:/exp5 abort
- #查看迁移状态
- $gluster volume replace-brick mamm-volume node3:/exp3 node5:/exp5 status
- #迁移完成后提交完成
- $gluster volume replace-brick mamm-volume node3:/exp3 node5:/exp5 commit
- $gluster volume rebalane mamm-volume start|stop|status
- $gluster volume heal mamm-volume #只修复有问题的文件
- $gluster volume heal mamm-volume full #修复所有文件
- $gluster volume heal mamm-volume info#查看自愈详情
- $gluster volume heal mamm-volume info healed|heal-failed|split-brain
- $gluster volume set mamm-volume key value
- path=$1 #参数为待添加目录绝对路径
- rm -rf $path/.glu*
- setfattr -x trusted.glusterfs.volume-id $path
- setfattr -x trusted.gfid $path
- #service nfs stop # 关闭Linux内核自带的NFS服务
- #service rpcbind start # 启动rpc端口映射管理
- #rpc.statd
- mount -t nfs -o vers=3 host/ip:/path mnt-port
- gluster volume profile mamm-vol start
- gluster volume profile info
- gluster volume profile mamm-vol stop
- gluster volume top mamm-vol {open|read|write|opendir|readdir} brick node1:/exp1 list-cnt 1
- gluster volume top mamm-vol read-perf|write-perf bs 256 count 10 brick node1:/exp1 list-cnt 1
- gluster volume statedump mamm-vol
- gluster volume set server.statedump-path /var/log/
- gluster volume info dumpfile
- gluster volume status [all|volname] [detail|clients|mem|fd|inode|callpoll]
出处:https://blog.csdn.net/JackLiu16/article/details/80635353