网络协议的基本要素
一个完备的网络协议需要具备哪些基本要素
- 魔数:魔数是通信双方协商的一个暗号,通常采用固定的几个字节表示。魔数的作用是防止任何人随便向服务器的端口上发送数据。
- 协议版本号:随着业务需求的变化,协议可能需要对结构或字段进行改动,不同版本的协议对应的解析方法也是不同的。所以在生产级项目中强烈建议预留协议版本号这个字段。
- 序列化算法:表示数据发送方应该采用何种方法将请求的对象转化为二进制,以及如何再将二进制转化为对象
- 报文类型:报文可能存在不同的类型。例如在 RPC 框架中有请求、响应、心跳等类型的报文,在 IM 即时通信的场景中有登陆、创建群聊、发送消息、接收消息、退出群聊等类型的报文。
- 长度域字段:代表请求数据的长度,接收方根据长度域字段获取一个完整的报文。
- 请求数据:通常为序列化之后得到的二进制流
- 状态:状态字段用于标识请求是否正常。一般由被调用方设置。例如一次 RPC 调用失败,状态字段可被服务提供方设置为异常状态。
- 保留字段:保留字段是可选项,为了应对协议升级的可能性,可以预留若干字节的保留字段,以备不时之需。
lua
复制代码
+---------------------------------------------------------------+ | 魔数 2byte | 协议版本号 1byte | 序列化算法 1byte | 报文类型 1byte | +---------------------------------------------------------------+ | 状态 1byte | 保留字段 4byte | 数据长度 4byte | +---------------------------------------------------------------+ | 数据内容 (长度不定) | +---------------------------------------------------------------+
举例如下:
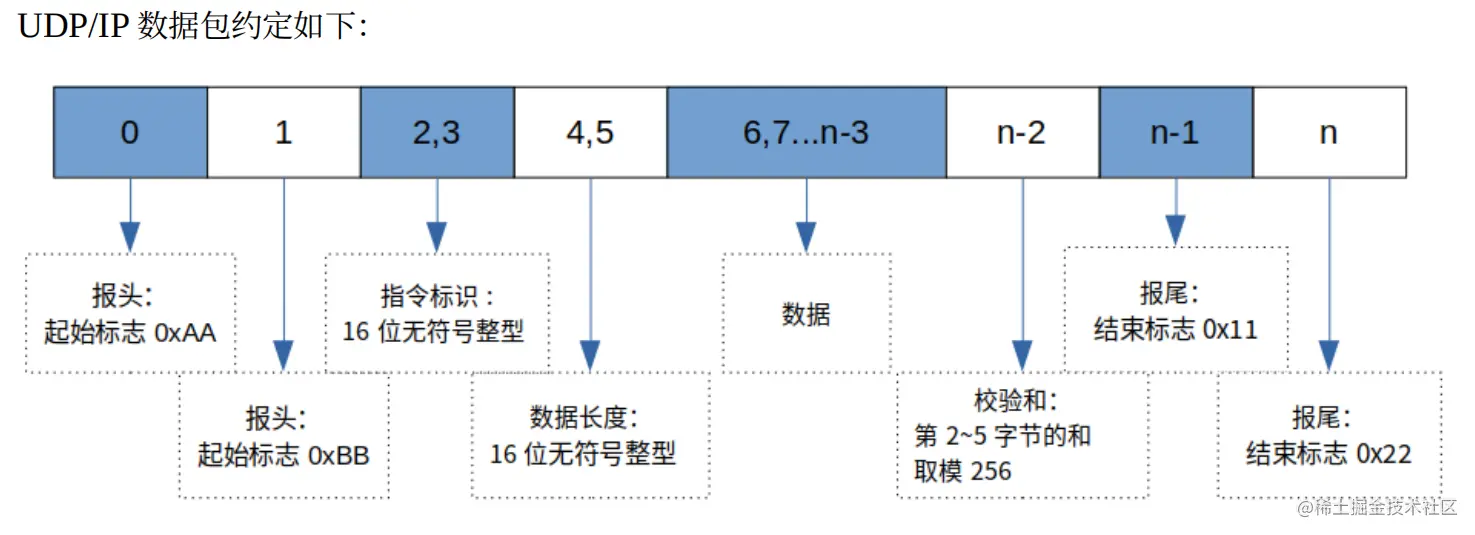
如何实现自定义通信协议
Netty 作为一个非常优秀的网络通信框架,已经为我们提供了非常丰富的编解码抽象基类,帮助我们更方便地基于这些抽象基类扩展实现自定义协议。 Netty 常用编码器类型:
-
MessageToByteEncoder 对象编码成字节流;
-
MessageToMessageEncoder 一种消息类型编码成另外一种消息类型。
Netty 常用解码器类型:
-
ByteToMessageDecoder/ReplayingDecoder 将字节流解码为消息对象;
-
MessageToMessageDecoder 将一种消息类型解码为另外一种消息类型。
编解码器可以分为一次解码器和二次解码器,一次解码器用于解决 TCP 拆包/粘包问题,按协议解析后得到的字节数据。如果你需要对解析后的字节数据做对象模型的转换,这时候便需要用到二次解码器,同理编码器的过程是反过来的。 一次编解码器:MessageToByteEncoder/ByteToMessageDecoder。 二次编解码器:MessageToMessageEncoder/MessageToMessageDecoder。
抽象编码类

通过抽象编码类的继承图可以看出,编码类是 ChanneOutboundHandler 的抽象类实现,具体操作的是 Outbound 出站数据。
MessageToByteEncoder
MessageToByteEncoder 用于将对象编码成字节流,MessageToByteEncoder 提供了唯一的 encode 抽象方法,我们只需要实现encode 方法即可完成自定义编码。 编码器实现非常简单,不需要关注拆包/粘包问题。如下例子,展示了如何将字符串类型的数据写入到 ByteBuf 实例,ByteBuf 实例将传递给 ChannelPipeline 链表中的下一个 ChannelOutboundHandler。
java
复制代码
public class StringToByteEncoder extends MessageToByteEncoder<String> { @Override protected void encode(ChannelHandlerContext channelHandlerContext, String data, ByteBuf byteBuf) throws Exception { byteBuf.writeBytes(data.getBytes()); } }
encode什么时候被调用的
MessageToByteEncoder 重写了 ChanneOutboundHandler 的 write() 方法,其主要逻辑分为以下几个步骤:
-
acceptOutboundMessage 判断是否有匹配的消息类型,如果匹配需要执行编码流程,如果不匹配直接继续传递给下一个 ChannelOutboundHandler;
-
分配 ByteBuf 资源,默认使用堆外内存;
-
调用子类实现的 encode 方法完成数据编码,一旦消息被成功编码,会通过调用 ReferenceCountUtil.release(cast) 自动释放;
-
如果 ByteBuf 可读,说明已经成功编码得到数据,然后写入 ChannelHandlerContext 交到下一个节点;如果 ByteBuf 不可读,则释放 ByteBuf 资源,向下传递空的 ByteBuf 对象。
java
复制代码
@Override public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception { ByteBuf buf = null; try { if (acceptOutboundMessage(msg)) { // 1. 消息类型是否匹配 @SuppressWarnings("unchecked") I cast = (I) msg; buf = allocateBuffer(ctx, cast, preferDirect); // 2. 分配 ByteBuf 资源 try { encode(ctx, cast, buf); // 3. 执行 encode 方法完成数据编码 } finally { ReferenceCountUtil.release(cast); } if (buf.isReadable()) { ctx.write(buf, promise); // 4. 向后传递写事件 } else { buf.release(); ctx.write(Unpooled.EMPTY_BUFFER, promise); } buf = null; } else { ctx.write(msg, promise); } } catch (EncoderException e) { throw e; } catch (Throwable e) { throw new EncoderException(e); } finally { if (buf != null) { buf.release(); } } }
MessageToMessageEncoder
MessageToMessageEncoder 与 MessageToByteEncoder 类似,同样只需要实现 encode 方法。
MessageToMessageEncoder常用的实现子类有StringEncoder、LineEncoder、Base64Encoder等。
以StringEncoder为例看下MessageToMessageEncoder 的用法。
源码示例如下:将 CharSequence 类型(String、StringBuilder、StringBuffer 等)转换成 ByteBuf 类型,结合 StringDecoder 可以直接实现 String 类型数据的编解码。
java
复制代码
@Override protected void encode(ChannelHandlerContext ctx, CharSequence msg, List<Object> out) throws Exception { if (msg.length() == 0) { return; } out.add(ByteBufUtil.encodeString(ctx.alloc(), CharBuffer.wrap(msg), charset)); }
抽象解码类
解码类是 ChanneInboundHandler 的抽象类实现,操作的是 Inbound 入站数据。解码器实现的难度要远大于编码器,因为解码器需要考虑拆包/粘包问题。
由于接收方有可能没有接收到完整的消息,所以解码框架需要对入站的数据做缓冲操作,直至获取到完整的消息。

ByteToMessageDecoder
使用 ByteToMessageDecoder,Netty 会自动进行内存的释放,我们不用操心太多的内存管理方面的逻辑。 首先,我们看下 ByteToMessageDecoder 定义的抽象方法:
java
复制代码
public abstract class ByteToMessageDecoder extends ChannelInboundHandlerAdapter { protected abstract void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception; protected void decodeLast(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception { if (in.isReadable()) { decodeRemovalReentryProtection(ctx, in, out); } } }
我们只需要实现一下decode()方法,这里的 in 大家可以看到,传递进来的时候就已经是 ByteBuf 类型,所以我们不再需要强转,第三个参数是List类型,我们通过往这个List里面添加解码后的结果对象,就可以自动实现结果往下一个 handler 进行传递,这样,我们就实现了解码的逻辑 handler。

为什么存取解码后的数据是用List
由于 TCP 粘包问题,ByteBuf 中可能包含多个有效的报文,或者不够一个完整的报文。
Netty 会重复回调 decode() 方法,直到没有解码出新的完整报文可以添加到 List 当中,或者 ByteBuf 没有更多可读取的数据为止。
如果此时 List 的内容不为空,那么会传递给 ChannelPipeline 中的下一个ChannelInboundHandler。
java
复制代码
static void fireChannelRead(ChannelHandlerContext ctx, CodecOutputList msgs, int numElements) { for (int i = 0; i < numElements; i ++) { //循环传播 有多少调用多少 ctx.fireChannelRead(msgs.getUnsafe(i)); } }
decodeLast
ByteToMessageDecoder 还定义了 decodeLast() 方法。为什么抽象解码器要比编码器多一个 decodeLast() 方法呢?
因为 decodeLast 在 Channel 关闭后会被调用一次,主要用于处理 ByteBuf 最后剩余的字节数据。Netty 中 decodeLast 的默认实现只是简单调用了 decode() 方法。如果有特殊的业务需求,则可以通过重写 decodeLast() 方法扩展自定义逻辑。
ReplayingDecoder
ByteToMessageDecoder 还有一个抽象子类是 ReplayingDecoder。它封装了缓冲区的管理,在读取缓冲区数据时,你无须再对字节长度进行检查。因为如果没有足够长度的字节数据,ReplayingDecoder 将终止解码操作。ReplayingDecoder 的性能相比直接使用 ByteToMessageDecoder 要慢,大部分情况下并不推荐使用 ReplayingDecoder。
MessageToMessageDecoder
与 ByteToMessageDecoder 不同的是 MessageToMessageDecoder 并不会对数据报文进行缓存,它主要用作转换消息模型。 比较推荐的做法是使用 ByteToMessageDecoder 解析 TCP 协议,解决拆包/粘包问题。解析得到有效的 ByteBuf 数据,然后传递给后续的 MessageToMessageDecoder 做数据对象的转换,具体流程如下图所示:

案例如下:
java
复制代码
public class MyTcpDecoder extends ByteToMessageDecoder { @Override protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception { // 检查ByteBuf数据是否完整 if (in.readableBytes() < 4) { return; } // 标记ByteBuf读取索引位置 in.markReaderIndex(); // 读取数据包长度 int length = in.readInt(); // 如果ByteBuf中可读字节数不足一个数据包长度,则将读取索引位置恢复到标记位置,等待下一次读取 if (in.readableBytes() < length) { in.resetReaderIndex(); return; } // 读取数据 ByteBuf data = in.readBytes(length); // 将数据传递给下一个解码器进行转换,转换后的数据对象添加到out中 ctx.fireChannelRead(data); } } public class MyDataDecoder extends MessageToMessageDecoder<ByteBuf> { @Override protected void decode(ChannelHandlerContext ctx, ByteBuf msg, List<Object> out) throws Exception { // 将读取到的ByteBuf数据转换为自定义的数据对象 MyData data = decode(msg); if (data != null) { // 将转换后的数据对象添加到out中,表示解码成功 out.add(data); } } private MyData decode(ByteBuf buf) { // 实现自定义的数据转换逻辑 // ... return myData; } }
实战案例
如何判断 ByteBuf 是否存在完整的报文? 最常用的做法就是通过读取消息长度 dataLength 进行判断。如果 ByteBuf 的可读数据长度小于 dataLength,说明 ByteBuf 还不够获取一个完整的报文。在该协议前面的消息头部分包含了魔数、协议版本号、数据长度等固定字段,共 14 个字节。 固定字段长度和数据长度可以作为我们判断消息完整性的依据,具体编码器实现ByteToMessageDecoder逻辑示例如下:
java
复制代码
/* +---------------------------------------------------------------+ | 魔数 2byte | 协议版本号 1byte | 序列化算法 1byte | 报文类型 1byte | +---------------------------------------------------------------+ | 状态 1byte | 保留字段 4byte | 数据长度 4byte | +---------------------------------------------------------------+ | 数据内容 (长度不定) | +---------------------------------------------------------------+ */ @Override public final void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) { // 判断 ByteBuf 可读取字节 if (in.readableBytes() < 14) { return; } // 标记 ByteBuf 读指针位置 in.markReaderIndex(); // 跳过魔数 in.skipBytes(2); // 跳过协议版本号 in.skipBytes(1); byte serializeType = in.readByte(); // 跳过报文类型 in.skipBytes(1); // 跳过状态字段 in.skipBytes(1); // 跳过保留字段 in.skipBytes(4); // 验证报文长度,不对的话就重置指针位置 int dataLength = in.readInt(); if (in.readableBytes() < dataLength) { in.resetReaderIndex(); // 重置 ByteBuf 读指针位置,这一步很重要 return; } byte[] data = new byte[dataLength]; in.readBytes(data); // 方式一:在解码器中就将数据解码成具体的对象 SerializeService serializeService = getSerializeServiceByType(serializeType); Object obj = serializeService.deserialize(data); if (obj != null) { out.add(obj); } // 方式二:这一步可以不在解码器中处理,将请求数据读取到一个新的byteBuf然后丢给handler处理 // 创建新的 ByteBuf 对象来存储有效负载数据 ByteBuf payload = Unpooled.buffer((int) dataSize); // 读取有效负载数据并写入到 payload 中 in.readBytes(payload); if (payload.isReadable()) { out.add(payload); } }
扩展
什么是字节序
字节顺序,是指数据在内存中的存放顺序 使用16进制表示:0x12345678。在内存中有两种方法存储这个数字,

不同在于,对于某一个要表示的值,是把值的低位存到低地址,还是把值的高位存到低地址。
字节顺序分类
字节的排列方式有两种。例如,将一个多字节对象的低位放在较小的地址处,高位放在较大的地址处,则称小端序;反之则称大端序。 典型的情况是整数在内存中的存放方式(小端/主机字节序)和网络传输的传输顺序(大端/网络字节序)
1. 网络字节序(Network Order):TCP/IP各层协议将字节序定义为大端(Big Endian) ,因此TCP/IP协议中使用的字节序通常称之为网络字节序。
- 所以当两台主机之间要通过TCP/IP协议进行通信的时候就需要调用相应的函数进行主机序列(Little Endian)和网络序(Big Endian)的转换。这样一来,也就达到了与CPU、操作系统无关,实现了网络通信的标准化。
2. 主机字节序(Host Order): 整数在内存中保存的顺序,它遵循小端(Little Endian)规则(不一定,要看主机的CPU架构,不过大多数都是小端)。
- 同型号计算机上写的程序,在相同的系统上面运行是没有问题的。
结论
Java中虚拟机屏蔽了大小端问题,如果是Java之间通信则无需考虑,只有在跨语言通信的场景下才需要处理大小端问题。
回到本文的重点,我们在编解码时也要注意大小端的问题,一般来说如果是小端序的话,我们用Netty取值的时候都要用LE结尾的方法。