文章目录
公有链
PoW - Proof of Work
简述:系统内节点竞争出块,谁先计算出符合要求的区块,谁获得出块奖励
缺点:费电、耗算力
优点:全员参与,完全去中心化
挖矿所得酬金来源:(1)新生比特币(2)交易费
典型场景:比特币
PoS - Proof of Stake
简述:选出一个记账节点,拥有股权大的,被选中的概率高
缺点:
(1)股权集中,拥有股权少的持股人,没有参与感;
(2)首富会一直掌握记账权;
(3)不能很好的处理分叉问题;
(4)“无利害关系”-(Nothing at stake)在每条分叉链上都挖矿,反正没有损失!招致 - 无差别攻击
优点:省算力,不用做无用功
POS被选中的记账人最后得到的报酬是根据其所拥有的币龄计算的;POS的最长链原则是币龄堆积的最长链。
典型场景:点点币(PP-coin)
点点币介绍:为了防止币龄堆积,限制使用时间。未使用至少30天的币可以参加竞争下一区块。一旦币的权益被用于签名下一区块,则币龄清空,再等待至少30天才能签署下一区块;同时,为了防止堆积币龄,寻找下一区块的最大概率在90天后达到最大值。购买51%及以上的币开销似乎超过获得51%算力的开销。

DPoS - Delegate Proof of Stake
大家投票选出101个候选记账人,然后轮流记账。
优点:所有持股人都参加了,参与度比较高
缺点:
(1)还是N个候选人可能一直是候选人;
(2)依赖代币(Token)

Bitshare(也称比特股)引入了“见证人”(witness)概念,见证人可以生成区块,每一个持有比特股的人都可以投票选举“见证人”。得到总同意票数的前N(N通常定义为101)个候选者可以当选为见证人,当选见证人的个数(N)满足:至少一半的参与投票者相信N已经充分的去中心化
“见证人”的候选名单,每个 - 维护周期(1天)- 更新一次,见证人然后随机排列,每个见证人按序有2s的权限时间生成区块,若见证人在给定的时间不能生成区块,区块生成权限交给下一个时间片段对应的见证人。DPOS充分利用了持股人的投票,以公平民主的形式达到共识,它们投票选出的N个见证人,可以视为N个矿池,N个矿池本次的权力是完全相等的,持股人可以随时更换“见证人”。
Bitshare还设计了另一种竞选:选出的代表拥有提出改变网络参数的特权,包括交易费用、区块大小、见证人费用和区块区间。若大多数代表 同意 提出的改变,持股人有两周的审查期,这期间,可以罢免代表并废止所提出的改变。这一设计确保代表技术上没有直接修改参数的权力以及所有的网络参数的改变最终需要得到持股人的同意。
PoA - Proof of Activity - 行动证明
来源于:PoW和PoS演化而来
其中addr:是奖励(报酬)的接收地址,最终报酬由获得记账权的节点和将交易写入区块体的节点共同瓜分。

PoB - Proof of Burn
PoB-proof of burn-燃烧证明
Silmcoin使用到,借鉴了PoS,燃烧矿工所持有的Silmcoin(矿工将Silmcoin发送到一个特定的、无法找回的地址),发送的越多,获得记账权的可能性就越大
联盟链
Paxos
Paxos算法的基本思路类似两阶段提交:
- 多个提案者先要争取到提案的权利(得到大多数决策者的支持);
- 成功的提案者发送提案给所有人进行确认,得到大部分人确认的提案成为批准的提案.
Paxos协议有三种角色
- Proposer(提议者)
- Acceptor(决策者)
- Learner(决策学习者)
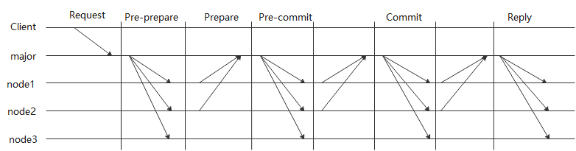
第一阶段:Prepare
- Proposer生成一个全局唯一的提案(Proposal)编号 N N N,然后向所有的Acceptor发送编号为 N N N的Prepare请求;
- 如果Acceptor收到一个编号为 N N N的Prepare请求,且 N N N大于本Acceptor已经响应过的所有Prepare请求的编号,那么本Acceptor就会将其已经接受过的编号最大的提案号作为响应反馈给Proposer,同时本Acceptor承诺不再接受比N小的提案。
第二阶段:Accept
- 如果Proposer收到半数以上Acceptor对其发出的编号为 N N N的Prepare请求的响应,那么Proposer就会发送一个针对 [ N , V ] [N,V] [N,V]提案的Accept请求给半数以上的Acceptor。 V V V就是收到的响应中编号最大的提案的value,如果响应中不包含任何提案,那么 V V V由Proposer自己决定。
2.如果Acceptor收到一个针对编号为 N N N的提案的Accept请求,只要该Acceptor没有对编号大于 N N N的Prepare请求做出过响应,Acceptor就接受该提案。
Paxos 并不保证系统总处在一致的状态。但由于每次达成共识至少有超过一半的节点参与,最终整个系统都会获知共识结果。如果提案者在提案过程中出现故障,可以通过超时机制来缓解。
Paxos 能保证在超过一半的节点正常工作时,系统总能以较大概率达成共识。
提案ID的生成算法
假设有 n n n个Proposer,每个编号为 I r ( 0 < I r < n ) I_r(0<I_r<n) Ir(0<Ir<n), Proposer 编号的任何值 s s s都应该大于它的已知的最大值,并且满足 s / n = I r , s = m ∗ n + I r s/n=I_r ,s = m*n +I_r s/n=Ir,s=m∗n+Ir
Proposal已知的最大值来自于两部分:Proposer自己对编号自增后的值和接收到的Acceptor的拒绝后所得到的值:
举例:3个Proposer P 1 , P 2 , P 3 P_1,P_2,P_3 P1,P2,P3,初始 m = 0 m=0 m=0,编号为0,1,2
(1) P 1 P_1 P1提交的时候发现了 P 2 P_2 P2已经提交, P 2 P_2 P2的编号1>P1的编号0,因此 P 1 P_1 P1重新计算编号:new P 1 = 1 ∗ 3 + 1 = 4 P_1 = 1*3 +1 = 4 P1=1∗3+1=4;
(2) P 3 P_3 P3以编号2提交,发现小于P1的4,因此P3重新编号:new P 3 = 1 ∗ 3 + 2 = 5 P_3= 1*3+2=5 P3=1∗3+2=5
Multi-Paxos
优点:简化了Paxos的二阶段,变成了一阶段
缺点:存在续租问题,时间到了,还要续租;
PBFT
优点:效率高于POW,算力消耗少
缺点:
- 不能实现节点动态的增加/删减
- 对作恶主节点没有惩罚机制
- 对网络带宽要求高,节点越多,带宽要求越高 – 对吞吐量进行改进
- 只适用于对等网络节点
目前存在的改进方法:
- 北邮论文中:PBFT+DPoS -> 先选出一批候选人,候选人之间进行PBFT。优点:减小了网络带宽
- 电子科技_张良嵩:DWA-BFT(真心觉得不错) - > 给共识节点增加权重,每次都会更新,权重大的,受信度就高,然后惰性节点或者拜占庭节点会被系统不断的减少权重 -对恶意节点的处理措施-可借鉴
- 山东大学_车正伟:EB-BFT –>根据积攒的交易数量和节点的物理状态,去选择共识节点的数量,同时给不同物理状态的共识节点分配不同的需要共识的区块(涉及到神经网络,反馈!)
DDBFT
动态授权的拜占庭容错算法:------3:2
优点:
- 提升了共识速度,因为不是全部的节点参与到共识,只有3/5的节点参与共识
缺点:
- 容错率降低为20%
- 节点工作量不均衡,非共识节点没有工作量
- 视图切换时消息复杂度没有降低
共识流程图:

IDBFT
主动动态授权的拜占庭容错算法 - 具体参考论文
优点:
- 在系统内节点全部可信的情况下,具有较好的性能表现
- 共识速度快。(因为并不是所有的节点都参与共识过程)
缺点
- 系统容错性下降(因为并不是所有的节点参与共识)
- 视图切换时的通信复杂度没有降低
共识流程分为两种情况
- 系统内节点全部可信 - 采取 简化共识流程(第一张图)
- 系统内存在拜占庭节点(第二张图)


Hotstuff
优点:
- 由传统的两阶段共识变为三阶段共识,视图切换时的消息复杂度将为多项式级别
- 节点间的通信复杂度降低,降低了通信开销
缺点:
- 数字签名算法 - ECDSA 进行聚合签名和门限签名 较为复杂,可以优化
应用场景:Libra(Facebook)
正常共识流程如图:
两阶段共识变为三阶段共识,使得两阶段共识中可能出现的视图切换的复杂度降低,O(N³)降低称为O(N);
关于三阶段共识的一些问题:
三阶段共识结果:视图切换时的消息复杂度降为多项式级别
关于视图切换:
为什么发生视图切换:系统主节点为拜占庭节点 或 系统发生大规模的网络故障
视图切换的结果:
主要解决了:视图更换时候消息复杂度的问题 –前一个区块B是否达成了共识
(二阶段共识)节点轮换机制:在需要节点轮换时,让所有节点广播自己收到的所有消息,然后新的区块发布者再广播收到的消息。造成了 O(N^3)的消息复杂度
当节点达到 time out 之后,请求出块节点轮换,相当于说:“我认为出块节点可能是恶意的,所以请求节点轮换”。然后,当新的出块节点收到 2f+1 条请求之后,它广播新的区块,并且广播这 2f+1 条请求,公告大家他的确收到了这些请求。
分析:
(1)可达成二阶段共识,只能保证视图没有被更换!
(2)不存在2f+1个节点位于“预备状态”,不会有节点对区块B进行了确认
(3)[一阶段共识]:节点收到2f+1个“收到区块B”的消息,直接对区块B进行确认;
(4)(二阶段共识):确保出块节点没有被更换!
算法框架(可以诞生多个衍生算法)采用了树 / 链式结构,十分类似区块链。另外,和传统区块链类似,一个结点当前也有被视作「主链」的一根链,投票只会投给当前认为主链上扩展的新部分。和区块链一样,如果侧链足够「好」,那么它就会变成新的主链。在区块链里面,这个是通过链长度来判定的(长者胜),而在 HotStuff 中,它通过最近一次成功获得大部分投票的块决
情况:诚实节点 a 顺利通过了预备阶段,并且,收到 2f+1 条区块 B 的确认消息(第二轮),这个时候他认为不会有另一个诚实节点确认不同的区块 B’,于是,他对 B 进行了确认。然而,在这个时候出现了大规模的网络异常,导致其他诚实节点没有在 timeout 之前成功收到 2f+1 个关于区块 B 的确认消息,于是大部分节点还没有对 B 进行确认的情况下,发了轮换出块节点请求。然后,新节点在 B 的高度出块 B’,造成不一致!
因为其实两轮共识已经提供了可以解决这个问题的基础 —— PBFT 做了如下的改动,解决了一致性与活性的矛盾:
所有节点在广播“更换出块节点”的申请的时候,需要同时广播自己的状态,同时给出自己处于这个状态的证据(例如,如果处于准备状态,就提交 2f+1 条来自不同节点的准备信息)。然后,新的出块节点根据收到的 2f+1 条信息中的状态决定是否替换掉 B:
(1)如果没有任何一个节点处于预备状态,则,至少有 f+1 个诚实节点还没有预备,于是不会有 2f+1 条确认消息,于是不会有任何一个诚实节点已经确认了区块 B。于是,这个时候,新的出块节点会将自己的新区块 B’放在同 B 一样的高度,替换掉 B。然后,广播区块 B’的同时,广播收到的所有轮换申请-向所有人说明这种情况。
(2)如果有一个节点处于预备状态,则说明至少有 f+1 个诚实节点已经收到过 B 并且准备进入预备状态。这个时候我们可以确认,不可能有一些诚实节点由于不同步(例如一直处于 timeout),以至于他们对于一条和 B 不一致的链进行了确认。那么,新的出块节点将新区块 B’连在 B 之后,并且广播收到的所有轮换申请。这时,由于处于预备状态的节点的轮换申请里包括 2f+1 条预备消息,所有收到新区块 B’的节点也同时收到了 2f+1 条预备消息,于是可以进入预备状态。换句话说,无论新的区块节点是谁,有没有恶意,或者是网络失活导致区块 B’没有达成共识都没关系。只要新区快的发布者采用这种方法,我们可以在保证活性的同时,保证不会和已经达成共识的区块出现不一致。
(5)(二阶段共识):首先,节点轮换的时候,每个节点需要广播一个轮换请求,这里就是 O(N²)的消息复杂度,然后,轮换请求中还需要包括自己之前所收到的所有预备消息来说明现在的状态,于是,这里就有了 O( N 3 N^3 N3)的消息复杂度。不仅如此,当下一个出块节点收到这些消息之后,他需要在发布区块的时候包含这些消息并且广播,于是,这里又有了 O(N^3)的消息复杂度。
(三阶段共识):诚实出块者广播区块 B,诚实节点收到后发送关于 B 的“预备消息”,然后,当节点收到 2f+1 条预备消息之后,节点进入预备状态并广播“预确认消息”;然后,当节点收到 2f+1 条预确认消息时,节点进入预确认状态并广播“确认消息”;最后,当节点收到 2f+1 条确认消息的时候,确认区块 B
(三阶段共识)节点轮换机制:当节点达到 timeout 还没有达成共识的时候,节点广播自己的状态并申请更换出块者。然后,下一个出块者收集这些状态来决定新区块的高度:如果没有 2f+1 个节点在预备状态,则换掉 B,如果有 2f+1 个节点在预备(或更高)状态,则把新区块出在 B 之后。
分析:
(1)不存在2f+1个节点在“预备状态”,不会有任何一个节点对区块B进行了确认;
(2)有2f+1个(或大于)节点处于“预备状态”及更高状态(预确认状态),不可能有一个诚实节点对区块B'进行了确认,不可能有一个诚实节点确认了一条不包括 B 的链,所以这个时候新的区块出在 B 之后。
(二阶段和三阶段的区别)可以这样理解:对于一个诚实节点,当他对于区块 B 达成了两轮共识,他就可以确认对于另一个冲突的区块 B’达不成共识。于是在两阶段共识中,如果在两阶段共识过程中进行了节点轮换,我们无法仅通过节点现在的状态就判定:(只能判定对区块进行了共识,但是哪个区块不知道!!!)(都是commit阶段,怎么判断对哪个区块commit了)
1、是否有节点已经对 B 进行了确认;
2、是否有节点对另一个区块 B’进行了共识。
于是,(二阶段共识)需要在节点轮换的时候,让所有节点广播自己收到的所有消息,然后新的区块发布者再广播收到的消息。
但是,如果采用三阶段共识,那么我们可以仅通过节点现在所处的状态来判定:
Zyzzyva
Leader是诚实节点:执行“一阶段共识”!
Leader非诚实节点:先判断出leader有恶意,然后去执行PBFT的“两阶段共识”
如果首领是可信的,直接做一轮 O(N)消息复杂度的普通广播就好了。然后,如果大家发现首领有问题,再退回 PBFT。所以说:“当首领是诚实的并且网络状况好的话,共识更快;然而,如果状况很糟糕的话,那么共识就会比 PBFT 慢,因为需要先等‘基于假设的’的算法跑完才能进入正题””
PoET
缺点:硬件限制 –Intel
优点:提升了共识效率,(因为参与共识的节点少了);减少了网络带宽
缺点:当节点数量过多的时候,需要考虑VBF函数对整体效率的影响
2018年提出:
本体区块链(ONT)
|-基本内容:在标准的三阶段之前,利用可验证随机函数(VRF)来选择每轮参加共识的节点
Casper
本质是:PoW产生区块,PoS作为参与共识节点的选择,BFT用来判断共识节点的投票有效情况
PoS的改进版本

Casper其实有两个版本:
不同之处就在于 FFG 更多的是作为一个过渡协议,使得以太坊能够从 PoW 成功过渡到PoS;而 CBC 则是以太坊切换到 PoS 后一个更好的版本.
1、Casper FFG:
FFG 的主要思想是借助 PoS 帮助 PoW 产生的区块最终确认,进而在减少矿工奖励的情况下来提高系统的安全性;
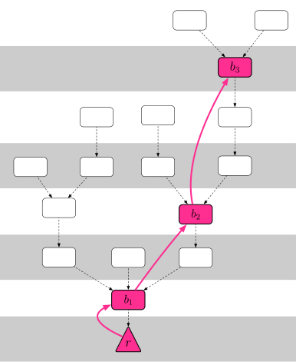
参与者通过抵押一定量的stake成为 Validator,Validator 负责运行 PoS 协议,为描述的便利性,假设在协议的过程中 Validator 保持不变。PoW 的以太坊会产生一棵树,如果 Validator 对每一个区块进行投票,会增加网络传播开销,为了减少 Casper 中投票的数量,将 100 个区块压缩成一个 checkpoint,如图1所示:

将区块压缩后我们得到了图2,并且为每一个 checkpoint 提供了一个高度函数:区块到根节点 r 的跳数:

首先,我们从整体上描述Casper的共识过程。参与共识的Validator会对上文中所述的checkpoint进行投票。每个Validator投的是一段checkpoint,从justified checkpoint开始到若干个checkpoint之后的一个checkpoint。我们规定第一个justified checkpoint是创世区块,当一个checkpoint收到了超过 2/3 的从justified checkpoint到它的投票,那么这个区块就变成了justified。
例如,在图2中存在超过了2/3的从创世块 r 到 的投票,那么就变成 justified;当存在超过 2/3 从到的投票,那么就是justified,以此类推。当一个justified checkpoint收到了超过 2/3 从它出发到它的某个子checkpoint的投票时,那么这个checkpoint以及其之前到所有的checkpoint 都已经被确认。
Validator 投票
在将 PoW 产生的区块压缩成checkpoint后,Validator 对这棵树进行投票,投票规则如“vote=<v,s,t,h(s),h(t)>”
(其中:
v :Validator的身份信息;
s :任意一个justified的checkpoint的hash,可以理解为源checkpoint。justified的定义我们之后会详细讲解;
t :任意一个s的子孙节点的hash;
h(s) : s的高度;
h(t) : t的高度;)
checkpoint 的两种关系
在定义了投票规则之后,定义任意两个checkpoint之间的关系:
supermajority link:对于一对checkpoint (a , b),写作(a→b),如果有超过2/3的validator投票, 可称 (a→b)是一条supermajority link,并且h(b)≥h(a)+1;
conflicting:如果两个checkpoint在不同的分支上称之为conflicting。

如图3所示,其中,(r→)→)(→)是supermajority link,,是conflicting。
checkpoint两种状态
定义checkpoint之间关系后,定义checkpoint-c 的两种状态:
1、c是 justified:
a)c = root :checkpoint c是根;
b)或 存在(c’→c),即 c’ 到 c 的 supermajority link,并且c’是 justified;(图四:r,四个checkpoint都是justified)
2、c 是finalized:
a)c 是justified;
b)存在(c→c’),c’ 到 c 的supermajority link;c , c’ not conflicting;h(c’)=h©+1;
在图3中,r,是 justified,是 finalized。
如果一个 checkpoint 状态是finalized,那么它以及它之前所有的block 都会确认。
惩罚机制
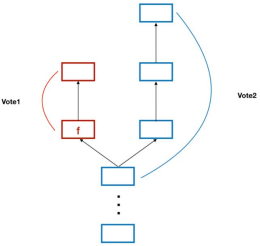
为了防止 Validator 在运行的过程中作恶,Casper 制定了一套惩罚机制如下:对于相同的Validator,发布了两个不同的投票<v,h(),h()>和<v,h(),h()>,如果存在以下两种情况则罚抵押的 stake。
1、h()= h():对于同一个目标高度,不能发起两个不同的投票。
2、h()< h()<h()< h()。
在合法交易的情况下,justified 和finalized是如何保证checkpoint的安全性的?当一个checkpoint : c成为了justified,说明有超过2/3的Validator支持c之前所有的checkpoint,配合着第一个惩罚条件,在h©有超过2/3的Validator 唯一支持checkpoint c。对于finalized的checkpoint : f,它会有一个从f出发,连接到f的子节点的 supermajority link。配合第二个惩罚条件,当一个checkpoint f成为了finalized,说明全网超过2/3的Validator不能发出跨越f的投票,这2/3的 Validator 只能对f之后的checkpoint 进行投票。如图4所示:对于任意一个 Validator,在投出了vote1之后就无法投 vote2,因此 f 之前的 checkpoint 将不会被改变,因为任意对于f之前 checkpoint 的投票都无法获得超过2/3的投票。
分叉选择机制:
为了让 PoS 能够提高 PoW 链的安全性,在如何进行分叉选择的时候,FFG 对最重链进行了些许的修改:首先在视图中找到高度最高的justified checkpoint,并在该checkpoint之后的区块上进行最重链选择。这样做有两个好处,第一个是相比于原有的GHOST算法,区块的确认是概率性的,等了足够多的高度之后,只有很低的概率颠覆之前的区块,虽然概率很低,但是还是有这种可能性;FFG 中只要是在 finalized 之前的区块都是被确认的,没有被颠覆的可能性。第二点是一个确认的区块的安全性是需要矿工不断将自己的工作量提供给该区块的,因此为了激励矿工需要更多的挖矿奖励;FFG中,只要是 finalized 的区块都是被确认了的,无需后续的矿工用工作量为已经确认的区块增加安全性,因此可以降低挖矿奖励,降低通胀率。
Validator的更换
我们刚开始说过,先假定 Validator 是固定的,但是一个真正的区块链系统肯定是能够让参与者自由进出的,因此 FFG 有一套自己的 Validator 出入原则。首先,定义区块b的 dynasty 为:从创始区块到b的父区块之间 finalized checkpoint的数量。
抵押:
用户想要成为 Validator 需要抵押一定的 stake,当用户v的抵押交易被包含在一个dynasty=d的区块中,那么定义一个Start Dynasty,写作SD(v) = d+2。
赎回:
Validator v想要取回抵押的 stake,需要发起一个赎回交易,当这个交易信息被包含在一个 dynasty为d的区块中, 那么定义一个End Dynasty,写作ED(v) =d +2。为了避免处理多个SD和ED,一个用户在赎回之后不能再抵押成为Validator。同时为了避免坏人作恶后立刻赎回stake,在赎回交易执行后stake仍需要锁定一定时间。对于一个区块b,假设其dynasty为d,只有d在ED和SD之间的Validator才可以进行投票(即加入到网络且没有退出的节点才可有投票权)。
Ourobros
待完善
PoSV
待完善
MG-DPoS
待完善
RPCA
待完善
Algorand
待完善
Tendermint
待完善
私有链
raft
待完善