首先注意,取每组最大的数据和取每组最大的一条记录是两个概念,前者很简单直接分组,max()即可。
sql如下
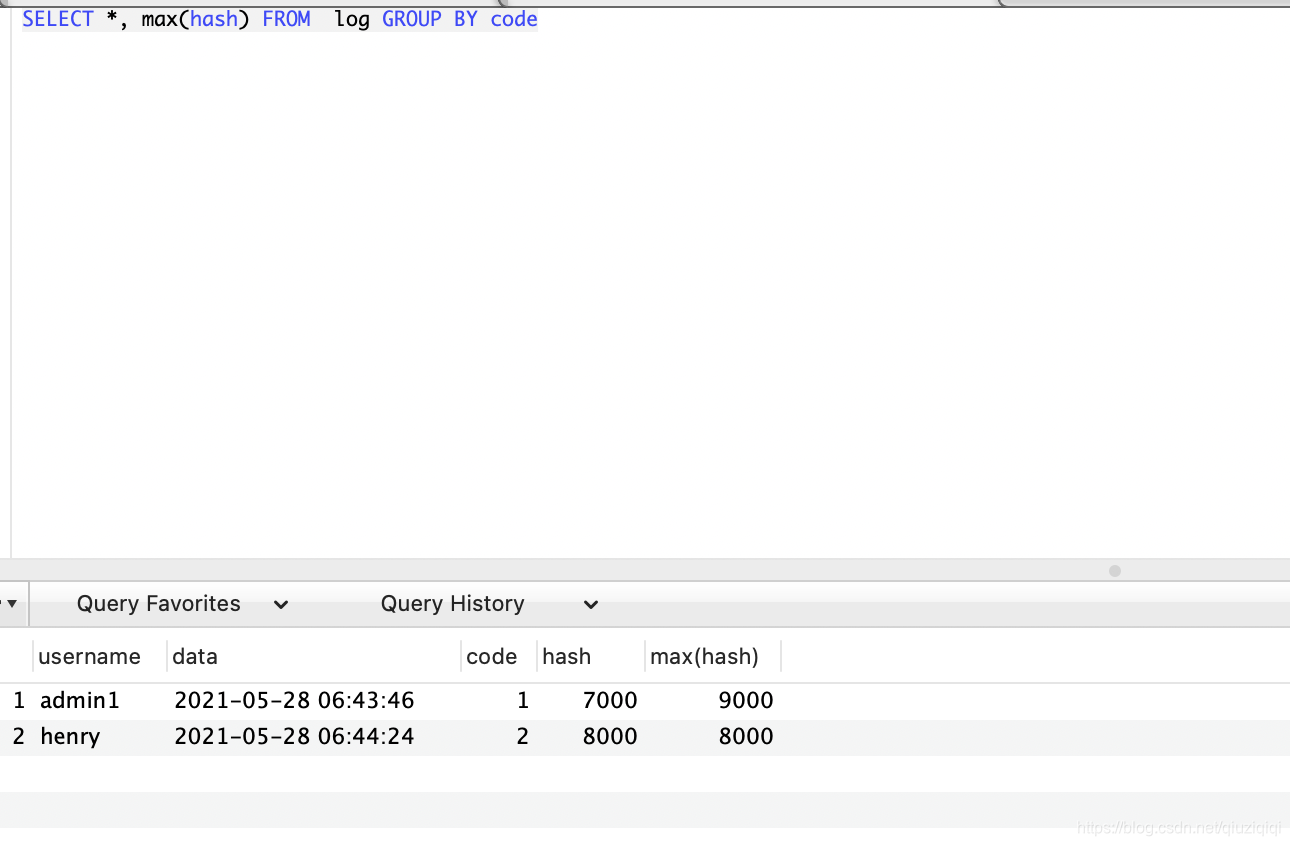
SELECT *, max(hash) FROM log GROUP BY code
回去取分组中的第一条数据的*内容,然后附加上max得出来的结果,但结果与那条数据不匹配
即只取出每组的最大数据(只需最大数据的话 改sql可满足,若要去除最大数据的那一条记录则不能简单的用此sql)

1.先排序后分组
然后很自然的想到用select * from log order by hash desc对其倒序排序
按照思路然后是把上面当做子查询即是
select * from (select * from log order by hash desc) as a group by code
查看资料发现原来排序后必须加limit ,如果不加的话,数据不会先进行排序。所以
select * from (select * from log order by hash desc limit 10000 ) as a group by code
2.子查询部分使用group by分组找到每组最大的,外层查询使用多字段的in查询。
select * from log where(code,hash) in (SELECT code,max(hash) hash FROM log group by code)
leetcode中的一道题 见识到了两个字段的in的用法
https://leetcode-cn.com/problems/department-highest-salary/
3.番外(通过max获取到单独数据的id 根据id去查对应的数据)
单表查询:
要id最小的一条,最简单的语句是:
select * from table order by id
如果一定要使用where条件,那么可以这样写:
select * from table where id=(select min(id) from table)
3.1番外2
A表为商品表,
B表为sku表,(每个商品有多个sku(规格))
查询所有商品中并且每个商品中sku的价格为最小的整条数据
select
A.id,A.goodsname as title,A.norms,A.status as gstatus,A.imgurls,A.uppertime,A.downtime,A.createtime as gcreatetime,A.updatetime as gupdatetime, A.isteam,B.id as defaultsku,B.price as minprice,B.preprice
from A
INNER JOIN B on A.id=B.goodsid
where B.price = ( select min(B.price) from B where B.goodsid=A.id)
and A.status=1 and B.status=1
group by A.id
order by A.id desc
————————————————
版权声明:本文为CSDN博主「solmee」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_40024174/article/details/99462595