一、整体架构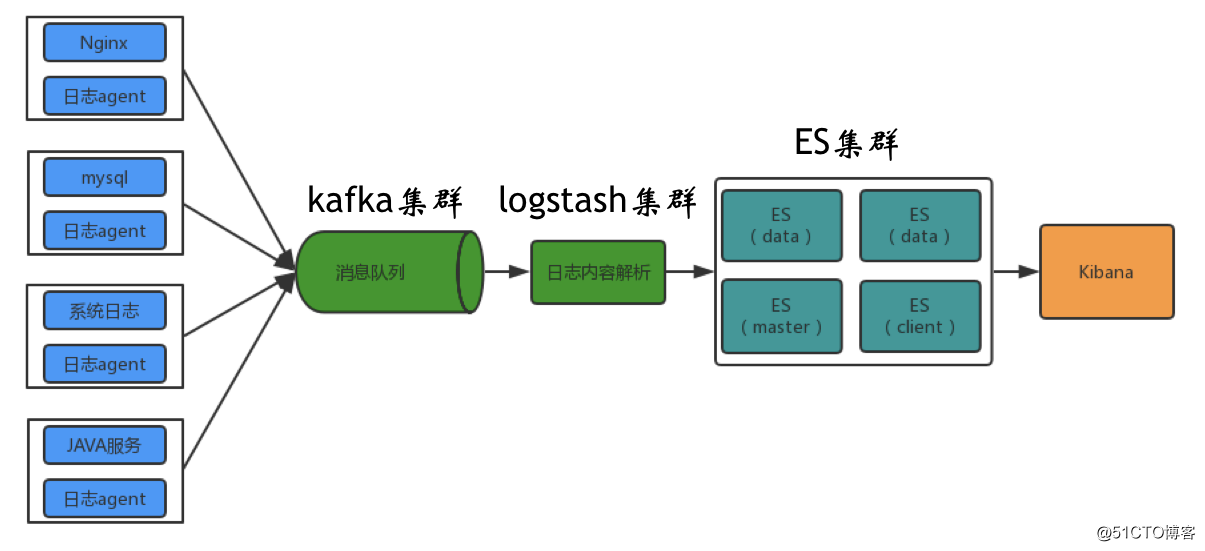
二、filebeat介绍
fielbeat是基于logstash-forwarder的源码改造而来,换句话说:filebeat就是最新版的logstash-forwarder。他负责从当前服务器获取日志然后转发给Logstash或Elasticserach进行处理。
Filebeat是一个日志文件托运工具,做为一个agent安装到服务器上,filebeat会监控日志目录或者指定的日志文件,追踪读取这些文件(追踪文件的变化,不停的读),并且转发这些信息到elasticsearch或者logstarsh中存放。
Filebeat包含两个主要的组件,prospectors(探测器)和harvesters(收割机)。
prospectors负责管理所有的harvesters,和发现所有的需要读取的日志源。
如果输入源是log(日志),prospectors根据配置路径,查找驱动器上的所有匹配的日志文件,并为每个文件启动一个收割机。
harvesters负责一行一行地读取日志文件,并将内容发送到指定的输出。
Filebeat目前支持两种prospector类型,log和stdin,每种类型都可以被定义多次。
三、filebeat特点
1、部署简单:二进制包,无其他依赖,直接下周使用;
2、配置简单:基于YAML,配置简单,格式明了;
3、轻量级:定位于docker和虚拟机的日志收集,运行占用资源在10M左右;单核CPU的消耗;
4、性能高:性能比logstash高很多;
5、记录收集位置:能记录收集的内容位置,重启后能基于在原基础上收集;
6、支持多行合并:保证java异常堆栈记录的完整性;
7、不支持事务;
8、功能单一:基于文件内容采集;能写入kafka、redis、es,但是不支持从其读;
四、filebeat安装
下载安装非常的简单:
1、rpm -vi filebeat-5.6.4-x86_64.rpm
2、下载tar包,tar -zxvf filebeat-5.6.4-x86_64.tar.gz
然后通过./filebeat -c filebeat.yml 命令启动
五、filebeat配置
#=========================== Filebeat prospectors =============================
filebeat.prospectors:
-
input_type: log
paths:- '/mnt/iss/service/order/nlogs/.log' #==监听日志文件全路径 全部监听用,否则直接写具体文件名,也可模糊匹配
encoding: utf-8 #==编码格式
exclude_files: [".gz$ | .gc."] #==排除监听的文件fields:
serverName: 'user-service-006' ##==额外添加的字段,用于区分服务器名称
type: service-log ##==多种服务日志时的区分字段
fields_under_root: true ##==是否直接添加这些字段到日志内容中
scan_frequency: 3s ##==扫描文件的频率
#===== Multiline options
multiline: ##==多行日志的合并配置,用于异常堆栈内容时的处理
pattern: '^{"date":'
negate: true
match: after
timeout: 2s
backoff: 1s
max_backoff: 3sclose_renamed: false ##文件重命名后是否停止监听
close_removed: true ##文件被删除后是否停止监听
tail_files: true ## 是否从文件末尾读取(启动时)
enabled: true
filebeat.spool_size: 2048 ## 事件发送的阀值,超过阀值,强制刷新网络连接
filebeat.idle_timeout: 2s ## 事件发送的超时时间,即使没有超过阀值,也会强制刷新网络连接ignore_older: 24h ##日志文件监听超时时间阀值
#================================ Outputs =====================================扫描二维码关注公众号,回复: 1582358 查看本文章
#-------------------------- kafka output ------------------------------
output.kafka:
#== initial brokers for reading cluster metadata
hosts: ["kafka1:9092", "kafka2:9092", "kafka3:9092"]
#== message topic selection + partitioning
topic: 'elk-service-log'
partition.round_robin:
reachable_only: false
required_acks: 1
compressmax_message_bytes: 1000000
compression: snappy
timeout: 5m
keep_alive: 30slogging.level: info