ANTLR提供了优秀的错误报告功能和复杂的错误恢复机制,基于此,ANTLR生成的语法分析器能够自动地在遇到句法错误时产生丰富的错误信息,并且能够在大多数的情况下成功地完成重新同步(resynchronize)。这样的语法分析器甚至能够保证只为每个句法错误产生一条错误信息。
一、错误处理入门
描述ANTLR的错误恢复策略,最好的方法是观察一个ANTLR自动生成的语法分析器对错误输入产生的响应。下面让我们通过一个简单的类Java语言的语法来进行错误处理入门学习。
grammar Simple;
prog: classDef+ ; // match one or more class definitions
classDef
: 'class' ID '{' member+ '}' // a class has one or more members
{System.out.println("class "+$ID.text);}
;
member
: 'int' ID ';' // field definition
{System.out.println("var "+$ID.text);}
| 'int' f=ID '(' ID ')' '{' stat '}' // method definition
{System.out.println("method: "+$f.text);}
;
stat: expr ';'
{System.out.println("found expr: "+$ctx.getText());}
| ID '=' expr ';'
{System.out.println("found assign: "+$ctx.getText());}
;
expr: INT
| ID '(' INT ')'
;
INT : [0-9]+ ;
ID : [a-zA-Z]+ ;
WS : [ \t\r\n]+ -> skip ;
首先,我们使用IDEA的Test Rule工具来运行语法分析器,先给出一些正确的输入,观察此时的输出。

我们没有从语法分析器中得到任何错误,它正常执行了任务并生成了语法分析树。
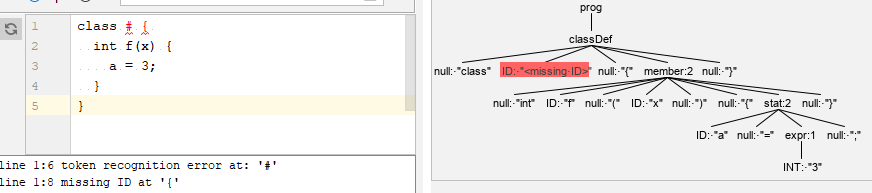
现在,让我们试着输入一个类,它的方法定义中包含一个非法的赋值语句。

在符号"4"处,语法分析器没有发现期望的";",因此报告了一个错误。在这个例子中,输入包含了两个多余的词法符号(4 & 5),因此,词法分析器对这样的错误给出了一个通用的错误信息。不过,如果输入仅有一个多余的词法符号,语法分析器就能够表现得更加智能,指出存在一个多余的词法符号。

这里,语法分析器是通过单词法符号移除(single-token deletion)特性实现的。所谓的单词法符号移除就是让词法分析器假设多余的那个词法符号不存在,然后继续解析即可。
同样,在词法分析器检测到词法符号缺失时,它也可以完成单词法符号补全(single-token insertion)。下面让我们去掉最后的“}”,看看会发生什么。

如果我们没有给出一个有效的类名,单词法符号补全机制还能自动为我们生成一个missing ID作为类名。如果需要控制语法分析器对这样的词法符号的生成机制,覆盖DefaultErrorStrategy类中的getMissingSymbol()方法即可。