1、 ffmpegzai conda环境里执行不了,在系统可以运行
import ffmpeg
stream = ffmpeg.input(r'D:\sound\222.mp4')
stream = ffmpeg.filter(stream, 'fps', fps=25, round='up')
stream = ffmpeg.output(stream, r'D:\sound\dummy2.mp4')
ffmpeg.run(stream)
会报错:
File “C:\Users\loong.conda\envs\nlp\lib\subprocess.py”, line 1435, in _execute_child
hp, ht, pid, tid = _winapi.CreateProcess(executable, args,
FileNotFoundError: [WinError 2] 系统找不到指定的文件。
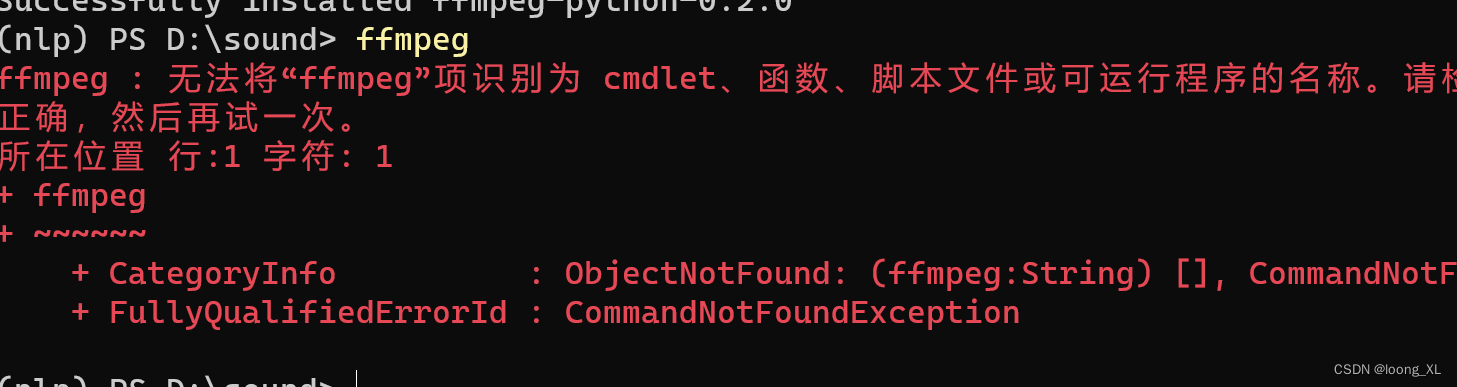
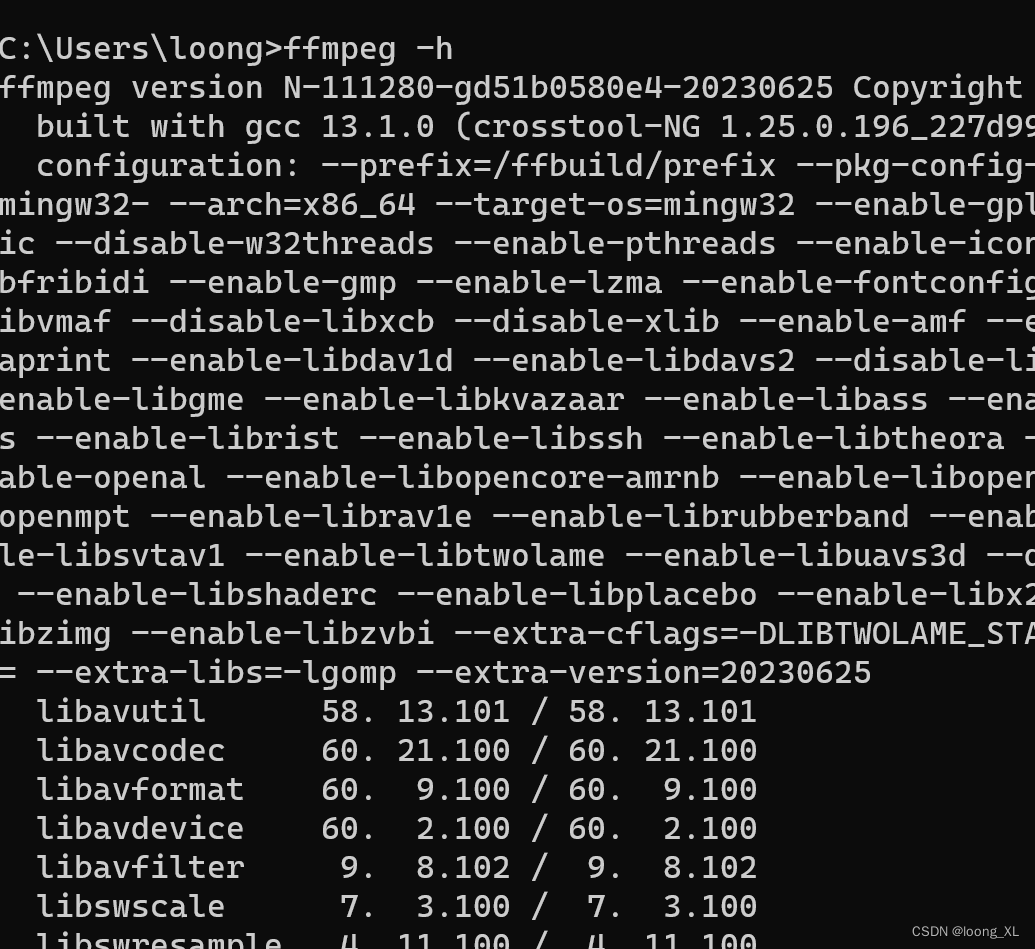
解决方法,用全部绝对路径执行可以正常运行
C:/Users/loong/.conda/envs/nlp/python.exe D:\sound\ffmpeg_sounddevice.py
2、ffmpeg调用本地windows麦克风读取
(这个用于后续其他数据对接,制定了 “-f”, “s16le”,
“-acodec”, “pcm_s16le”,
“-ar”, “16000”,采样数值)
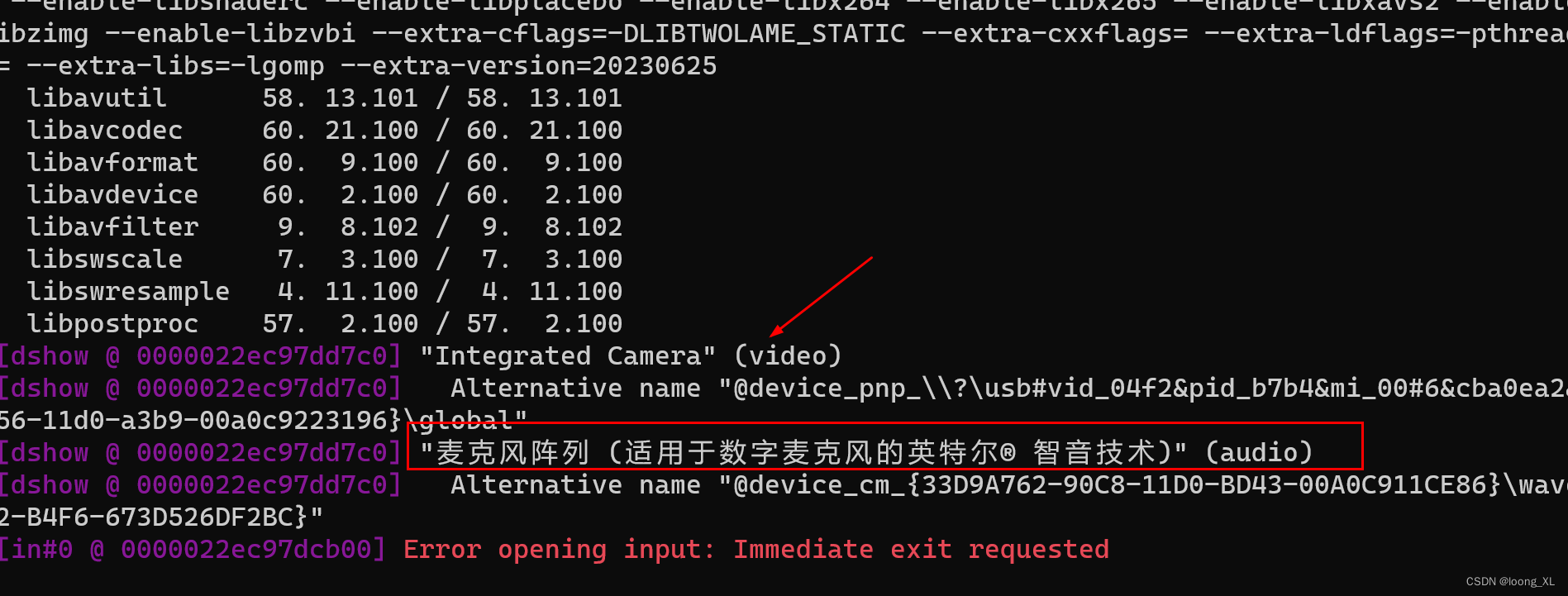
查看设备名称名称:ffmpeg -list_devices true -f dshow -i dummy
ffmpeg_cmd = [
"ffmpeg",
"-f", "dshow", # 使用alsa作为音频输入设备
"-i", "audio=麦克风阵列 (适用于数字麦克风的英特尔® 智音技术)", # 使用默认的音频输入设备(麦克风)
"-f", "s16le",
"-acodec", "pcm_s16le",
"-ar", "16000",
"-ac", "1",
"-"
]
ffmpeg_cmd = [
"ffmpeg",
"-f", "dshow", # 使用dshow作为音频输入设备(名字必须是这个,其他会报错)
"-i", "audio=Microphone", # 麦克风的设备名称
"-f", "s16le",
"-acodec", "pcm_s16le",
"-ar", "16000",
"-ac", "1",
"-"
]
这个命令将使用dshow作为音频输入设备,以及指定使用名为Microphone的麦克风设备。如果你使用的麦克风设备名称不同,你可以将其替换为你实际使用的设备名称。
其他参数的含义与之前提到的Linux示例相同:-f s16le指定输出音频格式为16位无压缩PCM音频,-acodec pcm_s16le指定音频编解码器为16位无压缩PCM音频,-ar 16000指定采样率为16000Hz,-ac 1指定声道数为1(单声道)。
最后,输出文件名被替换为-,表示音频数据将通过标准输出进行流式传输,而不是写入到文件中。
请注意,以上命令参数适用于Windows系统,并使用了DirectShow作为音频输入设备。如果你在其他操作系统上运行,请使用相应的音频输入设备和命令参数。
import subprocess
import numpy as np
ffmpeg_cmd = [
"ffmpeg",
"-f", "dshow", # 使用alsa作为音频输入设备
"-i", "audio=麦克风阵列 (适用于数字麦克风的英特尔® 智音技术)", # 使用默认的音频输入设备(麦克风)
"-f", "s16le",
"-acodec", "pcm_s16le",
"-ar", "16000",
"-ac", "1",
"-"
]
# 创建FFmpeg进程
process = subprocess.Popen(
ffmpeg_cmd,
stdout=subprocess.PIPE,
stderr=subprocess.DEVNULL,
bufsize=1600
)
# 读取和处理音频数据
while True:
# 从FFmpeg进程中读取音频数据
data = process.stdout.read(frames_per_read * channels * 2) # 每个样本16位,乘以2
if not data:
break
# 将音频数据转换为numpy数组
samples = np.frombuffer(data, dtype=np.int16)
samples = samples.astype(np.float32)
# samples = MinMaxScaler(feature_range=(-1, 1)).fit_transform(samples.reshape(-1, 1))
samples /= 32768.0 # 归一化到[-1, 1]范围
##数据后续处理逻辑
ffmpeg每几秒保存一份本地电脑
本地采样数值 “-f”, “wav”,
“-acodec”, “pcm_s16le”,
“-ar”, “44100”,
“-ac”, “2”, 本地电脑可以正常播放
import subprocess
import time
import numpy as np
i = 0
while True:
start_time = time.time()
output_file = f"D:\llm\output{i}.wav" # 创建输出文件名,例如output0.wav, output1.wav, ...
ffmpeg_cmd = [
"ffmpeg",
"-f", "dshow",
"-i", "audio=麦克风阵列 (适用于数字麦克风的英特尔® 智音技术)",
"-f", "wav",
"-acodec", "pcm_s16le",
"-ar", "44100",
"-ac", "2",
output_file,
]
process = subprocess.Popen(ffmpeg_cmd)
# 等待两秒
time.sleep(2)
# 终止ffmpeg进程
process.terminate()
i += 1