Linear Regression with One Variable (a.k.a univariate linear regression)
在学习机器学习的过程中,我发现即使有代数和统计的基础,不靠具体的例子就想深入理解每个算法到底在干什么是比较困难的。在这份重新整理的笔记中,我会以案例开头,以加深对每个算法应用场景的了解。当然,数学推导还是不能少的。
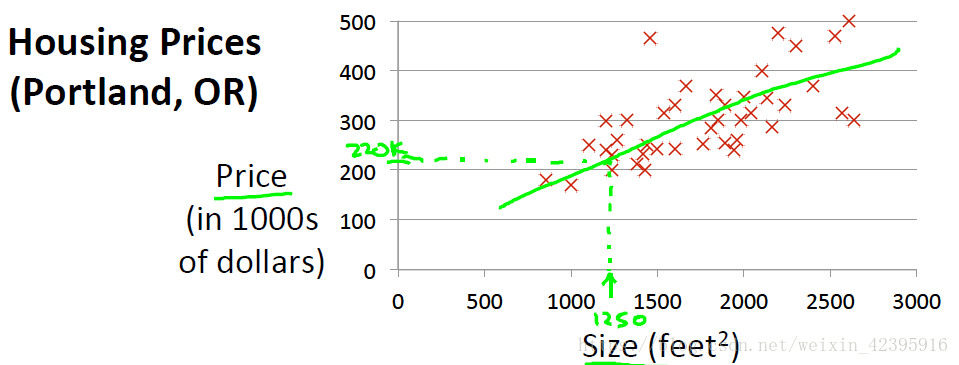
Task: Give a training set of (x,y)=(housing size, housing price), predict y given a new x.
1. Model
1.1 Notation
m=number of training examples
x=”input” variable/features
y=”output” variable/”target” variable
training example
1.2 Hypothesis
在上述房价预测问题中,我们很自然地会想到建立如下猜想:
这就是一个典型的单变量线性回归问题(linear regression with one variable),问题的求解关键在于如何找到合适的 .
1.3 Cost function
To estimate the model built above, the idea is to choose parameters
,
so that
is close to y for our training examples(x,y). In practice, we minimize the cost function:
是残差, 是残差平方和(SSR)。常数项 不影响参数估计结果,但习惯上我们在残差平方和的基础上除以样本量m,以计算平均值,再除以2,方便之后的求导计算(对参数求导后1/2会被消去)。完整的目标函数 即为代价函数(cost function),也称损失函数(loss function)。代价函数有多种类型,以上这种在回归问题里最常用。
1.4 Goal
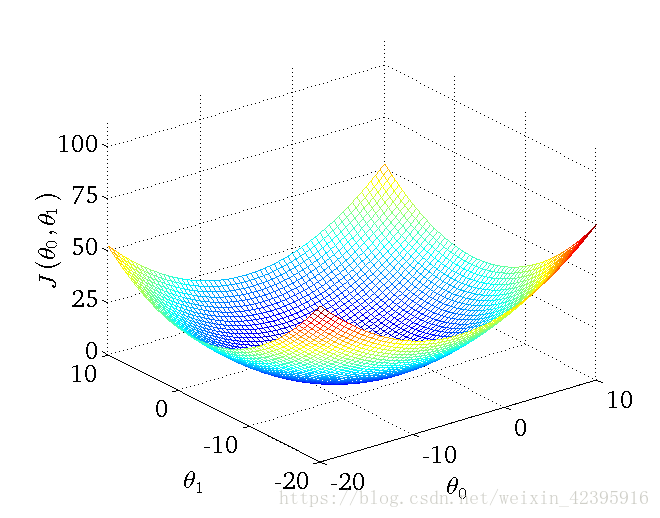
线性回归的代价函数为严格凸函数(convex function),上图最底端为唯一的最优点,此时 .
Contour Plot: A graph that contains many contour lines
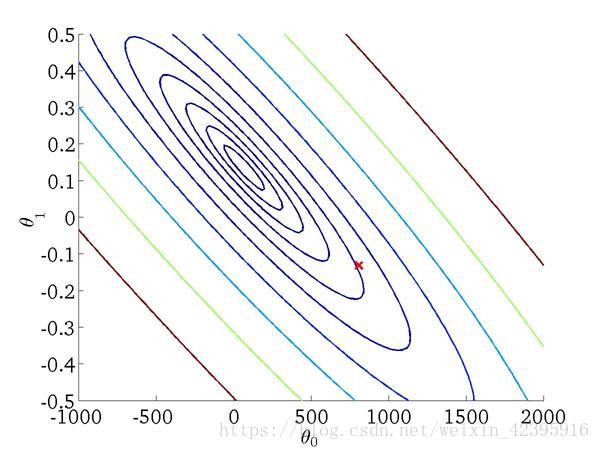
2. Parameter Learning
2.1 Gradient Descent 梯度下降
Have some function
Want
梯度下降是机器学习中常用的参数优化算法,它的用途非常广泛,不仅可用于单变量线性回归的参数优化,还可用于多变量回归、逻辑回归、神经网络等多种场合。以单变量线性回归为例,梯度下降的主要思想是:
- Start with some
- Keep changing
to reduce
until we hopefully end up
at a minimum
下面我们通过一张图直观地理解梯度下降到底是在做什么:
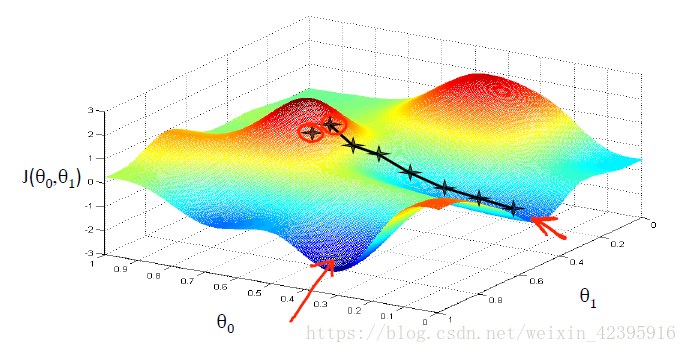
黑色线条展示了一种可能的下降路径,它以左上角记号点为起始点,右下角记号点为终点,下降步骤包括:
Step1:随机初始化参数
Step2:找到下降最快的方向迈出一小步
Step3:不断重复步骤2
Step4:到达局部最优点
注意:梯度下降法不一定会找到全局最优解。起始点不同,可能会得到不同的局部最优解。
2.2 Gradient Descent Algorithm
repeat until convergence {
(for j=0 and j=1)
}
where := denotes assignment operator, α denotes learning rate, which is a positive number and controls how big a step we take when updating parameters.
为了正确实现梯度下降,我们需要对参数进行同步更新(simultaneous update):
| Correct: Simultaneous update | Incorrect: |
|---|---|
2.3 Gradient Descent for Linear Regression
简单起见,我们只考虑单变量线性回归的情况,且假设
固定,仅对
进行优化。代价函数简化为
的函数
,其大致图像为
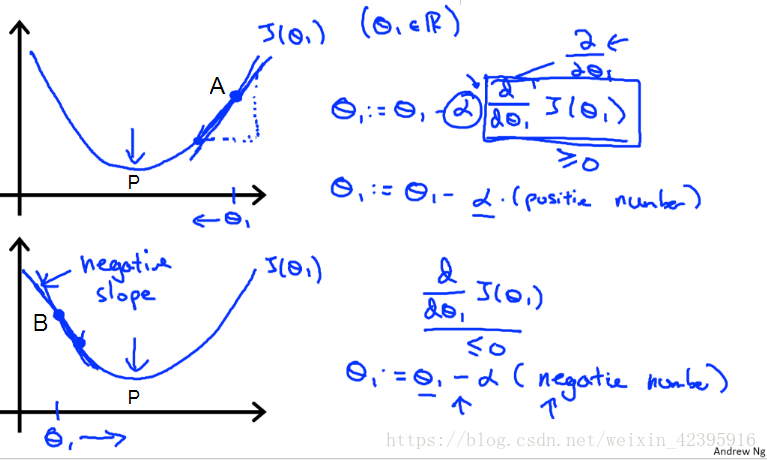
假设A为初始点,此时斜率
,因此
会逐渐收敛至最优点P。当初始点为B点时,斜率为负,
依然逐渐向P点移动。
关于学习率的注意事项:
1. 如果α太小,梯度下降的速度会非常慢;
2. 如果α太大,梯度下降可能会跳过最优解(如从A点直接到B点),可能会导致算法无法收敛,甚至发散;
3. 即使不改变α的值,梯度下降仍可收敛到局部最优解,因为当接近局部最优时,梯度下降的步长会自动变小
在实践中,为了选择合适的α,Ng给出的建议是尝试以下值,并依次扩大三倍:
0.001,…0.003…,0.01,…0.03…,0.1,…0.3…,1……
这种梯度下降的方法又称批量梯度下降算法(Batch gradient descent),因为下降的每一步都用到了所有训练样本。