距离 ChatGLM2 系列模型发布已有月余。日前,GLM 技术团队公布了 ChatGLM2-12B 在部分中英文典型数据集上的评测效果,数据集包括 MMLU(英文)、C-Eval(中文)、GSM8K(数学) 和 BBH(英文) 等。
“ChatGLM2-12B 模型在这些数据集上取得了不错的成绩。我们将继续不断改进和优化模型,以提供更优质的模型效果。”

MMLU
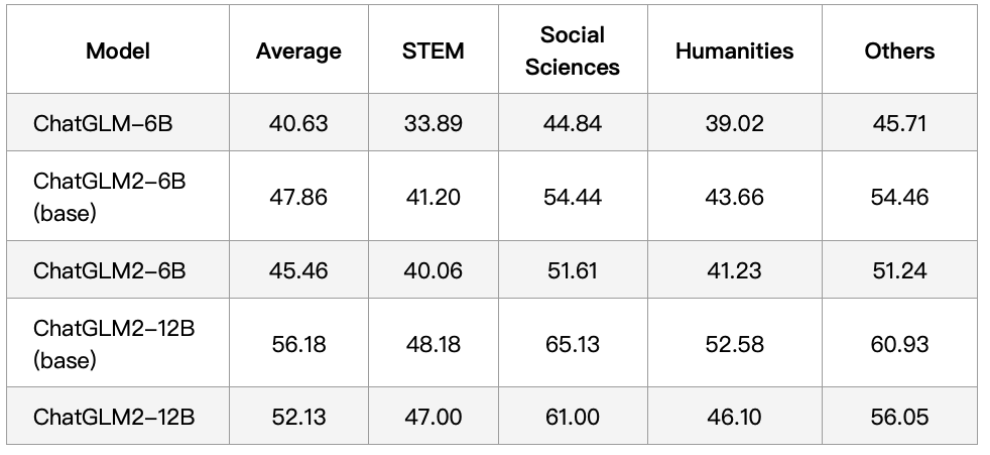
Chat 模型使用 zero-shot CoT (Chain-of-Thought) 的方法测试,Base 模型使用 few-shot answer-only 的方法测试。
C-Eval
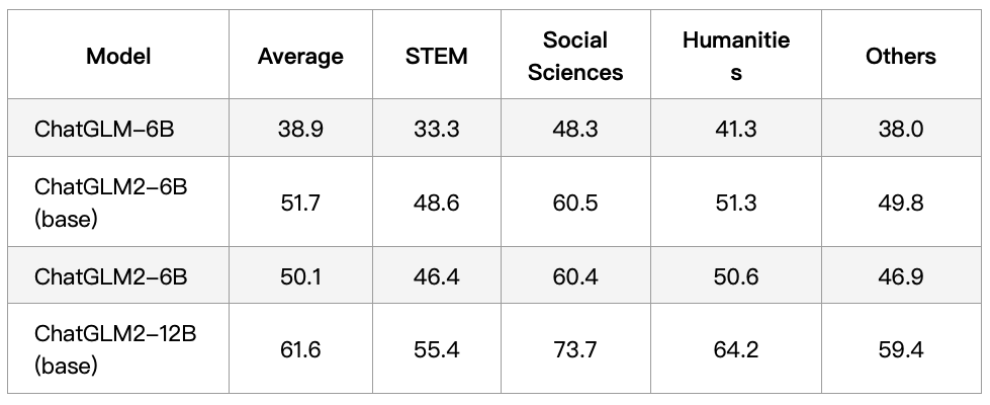
Chat 模型使用 zero-shot CoT 的方法测试,Base 模型使用 few-shot answer only 的方法测试。
GSM8K

所有模型均使用 few-shot CoT 的方法测试,CoT prompt 来自 http://arxiv.org/abs/2201.11903
* 使用翻译 API 翻译了 GSM8K 中的 500 道题目和 CoT prompt 并进行了人工校对。
BBH
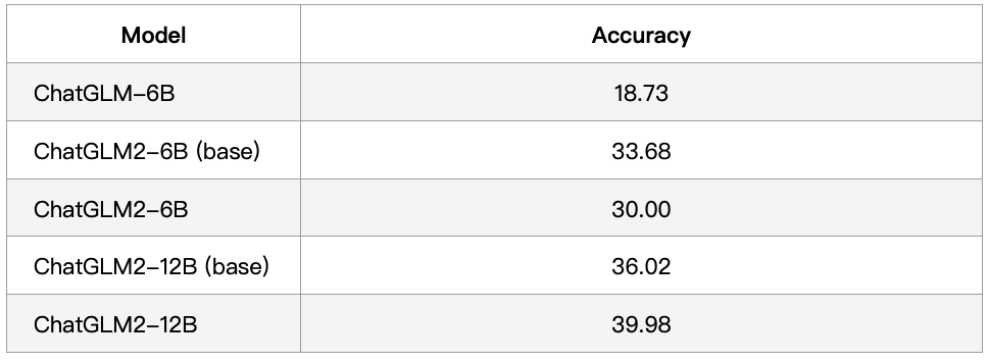
所有模型均使用 few-shot CoT 的方法测试,CoT prompt 来自此处。