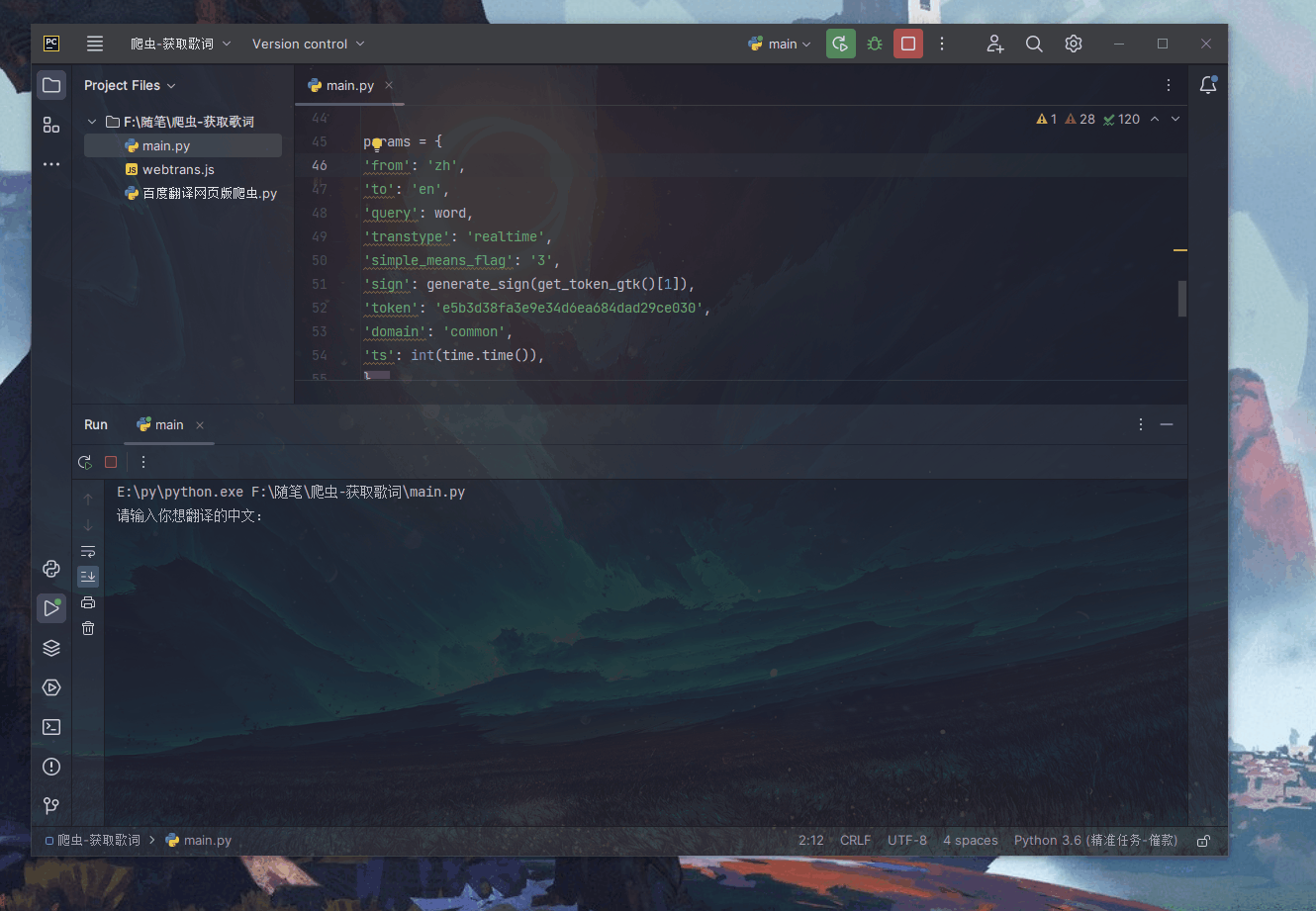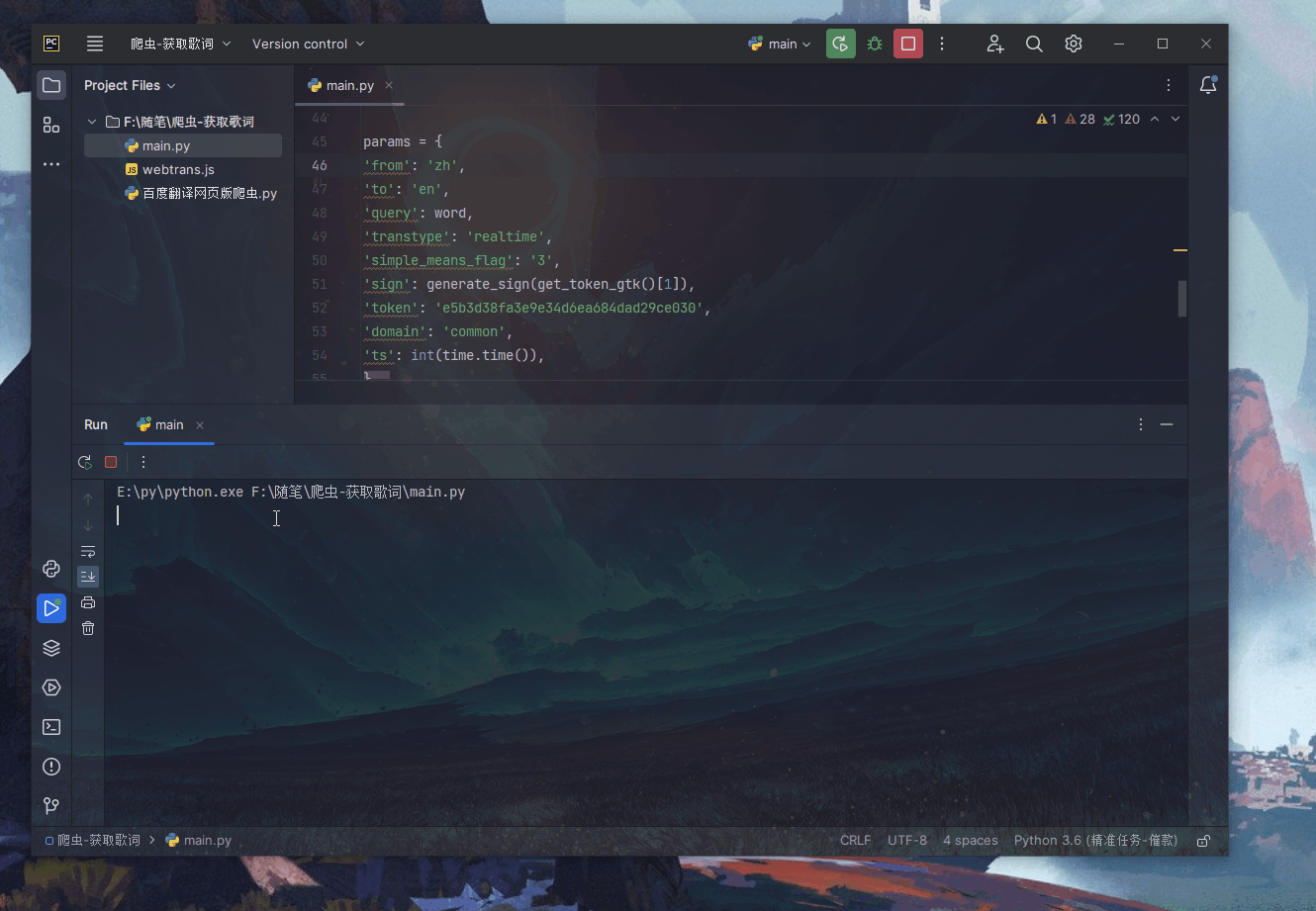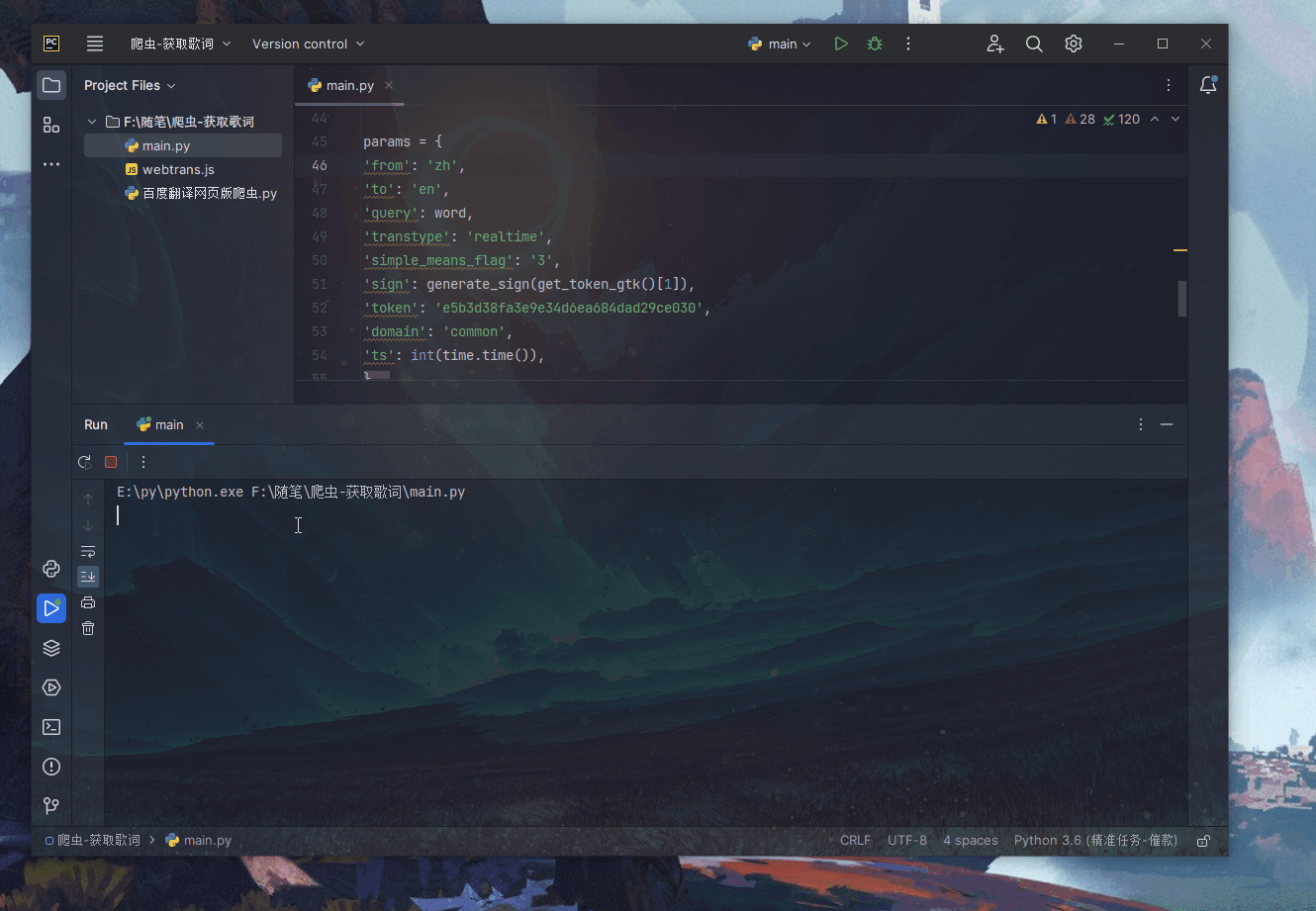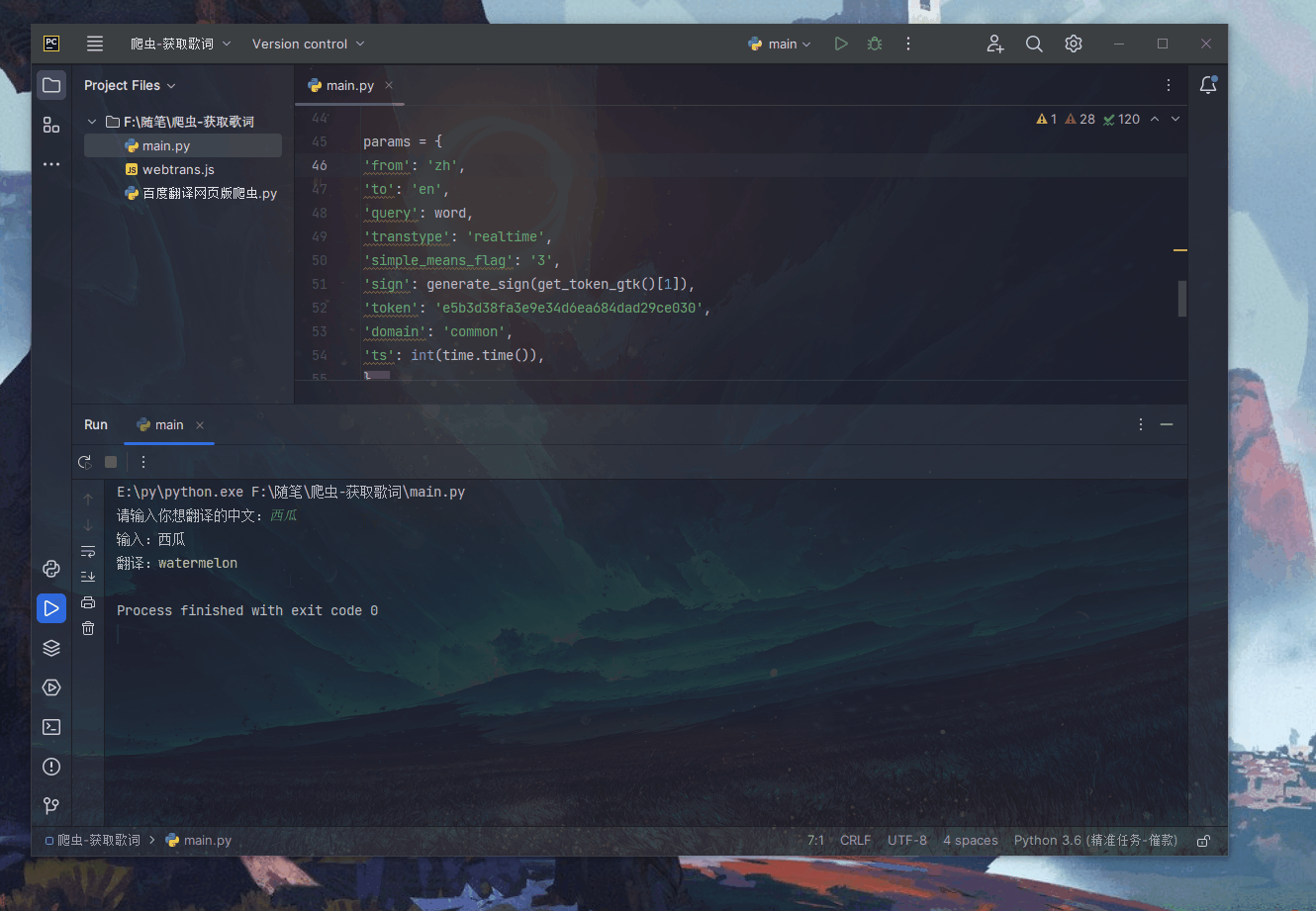
// webtrans.jsfunctionn(r, o){
for(var t =0; t < o.length -2; t +=3){
var a = o.charAt(t +2);
a = a >="a"? a.charCodeAt(0)-87:Number(a),
a ="+"=== o.charAt(t +1)? r >>> a : r << a,
r ="+"=== o.charAt(t)? r + a &4294967295: r ^ a
}return r
}functione(r){
var o = r.match(/[\uD800-\uDBFF][\uDC00-\uDFFF]/g);if(null=== o){
var t = r.length;
t >30&&(r =""+ r.substr(0,10)+ r.substr(Math.floor(t /2)-5,10)+ r.substr(-10,10))}else{
for(var e = r.split(/[\uD800-\uDBFF][\uDC00-\uDFFF]/),C=0, h = e.length, f =[]; h >C;C++)""!== e[C]&& f.push.apply(f,a(e[C].split(""))),C!== h -1&& f.push(o[C]);var g = f.length;
g >30&&(r = f.slice(0,10).join("")+ f.