文章目录
- 前言
- 欢迎来到我们的圈子
- 初见爬虫
- 为什么是爬虫
- 通用爬虫架构
- 爬虫的工作步骤
- 优秀爬虫的特性
- 1.高性能
- 2.可扩展性
- 3.健壮性
- 4.友好性
- 爬虫初体验
- requests.get()
- Response对象常用的四个属性
前言
前期回顾:你要偷偷的学Python,然后惊呆所有人(第六天)
前一天说了,我们今天要进入到爬虫的学习,对,今天我们开始爬

本系列文默认各位有一定的C或C++基础,因为我是学了点C++的皮毛之后入手的Python。
本系列文默认各位会百度,学习‘模块’这个模块的话,还是建议大家有自己的编辑器和编译器的,上一篇已经给大家做了推荐啦?
本系列也会着重培养各位的自主动手能力,毕竟我不可能把所有知识点都给你讲到,所以自己解决需求的能力就尤为重要,所以我在文中埋得坑请不要把它们看成坑,那是我留给你们的锻炼机会,请各显神通,自行解决。
1234567
如果是小白的话,可以看一下下面这一段:
欢迎来到我们的圈子

如果大家在学习中遇到困难,想找一个python学习交流环境,可以微信扫描下方CSDN官方认证二维码加入我们的==


初见爬虫
我也不是啥大佬,所以也不会一上来就一大堆特别高大上的爬虫技巧呈现出来,我们一步一步来吧。
网络爬虫,也叫网络蜘蛛(Web Spider)。它根据网页地址(URL)爬取网页内容,而网页地址(URL)就是我们在浏览器中输入的网站链接。比如:https://www.baidu.com/,它就是一个URL。
为什么是爬虫
通用搜索引擎的处理对象是互联网网页,目前互联网网页的数量已达百亿,所以搜索引擎首先面临的问题是:如何能够设计出高效的下载系统,以将如此海量的网页数据传送到本地,在本地形成互联网网页的镜像备份。
网络爬虫能够起到这样的作用,完成此项艰巨的任务,它是搜索引擎系统中很关键也很基础的构件。
举个很常见的栗子吧:百度。 百度这家公司会源源不断地把千千万万个网站爬取下来,存储在自己的服务器上。你在百度搜索的本质就是在它的服务器上搜索信息,你搜索到的结果是一些超链接,在超链接跳转之后你就可以访问其它网站了。
通用爬虫架构

好,上面这张图能看明白吗?如果不能的话,我们来再看些用户访问网站的流程图:
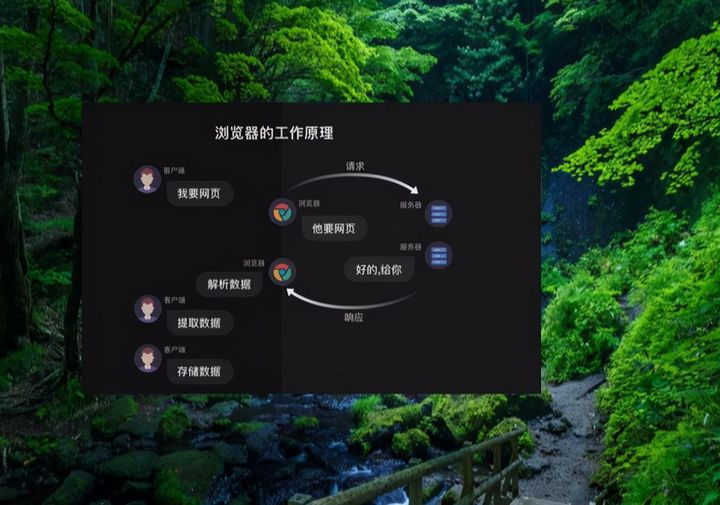
这是一个人机交互的流程,那么我们再来看看爬虫在这个闭环里面能够取代掉哪些工作:

是吧,非常符合我们的“人工智能”的特性,解放我们的双手。
爬虫的工作步骤
第1步:获取数据。爬虫程序会根据我们提供的网址,向服务器发起请求,然后返回数据。
第2步:解析数据。爬虫程序会把服务器返回的数据解析成我们能读懂的格式。
第3步:提取数据。爬虫程序再从中提取出我们需要的数据。
第4步:储存数据。爬虫程序把这些有用的数据保存起来,便于你日后的使用和分析。
1234567
这就是爬虫的工作原理啦,无论之后的学习内容怎样变化,其核心都是爬虫原理。
本章旨在直截了当的认识爬虫,所以过多的不必要的概念就不引伸了。
优秀爬虫的特性
话说优秀的代码好像都是这些特性。 不过有人能说出优秀架构的特性吗?让我眼前一亮,惊呼一声:“大佬,带我”
1.高性能
这里的性能主要是指爬虫下载网页的抓取速度,常见的评价方式是以爬虫每秒能够下载的网页数量作为性能指标,单位时间能够下载的网页数量越多,爬虫的性能越高。
要提高爬虫的性能,在设计时程序访问磁盘的操作方法(磁盘IO)及具体实现时数据结构的选择很关键,比如对于待抓取URL队列和已抓取URL队列,因为URL数量非常大,不同实现方式性能表现迥异,所以高效的数据结构对于爬虫性能影响很大。
2.可扩展性
即使单个爬虫的性能很高,要将所有网页都下载到本地,仍然需要相当长的时间周期,为了能够尽可能缩短抓取周期,爬虫系统应该有很好地可扩展性,即很容易通过增加抓取服务器和爬虫数量来达到此目的。
目前实用的大型网络爬虫一定是分布式运行的,即多台服务器专做抓取。每台服务器部署多个爬虫,每个爬虫多线程运行,通过多种方式增加并发性。
对于巨型的搜索引擎服务商来说,可能还要在全球范围、不同地域分别部署数据中心,爬虫也被分配到不同的数据中心,这样对于提高爬虫系统的整体性能是很有帮助的。
3.健壮性
爬虫要访问各种类型的网站服务器,可能会遇到很多种非正常情况:比如网页HTML编码不规范、 被抓取服务器突然死机,甚至爬到陷阱里边去了等。爬虫对各种异常情况能否正确处理非常重要,否则可能会不定期停止工作,这是无法忍受的。
从另外一个角度来讲,假设爬虫程序在抓取过程中死掉,或者爬虫所在的服务器宕机,健壮的爬虫应能做到:再次启动爬虫时,能够恢复之前抓取的内容和数据结构,而不是每次都需要把所有工作完全从头做起,这也是爬虫健壮性的一种体现。
4.友好性
爬虫的友好性包含两方面的含义:一是保护网站的部分私密性;另一是减少被抓取网站的网络负载。爬虫抓取的对象是各类型的网站,对于网站所有者来说,有些内容并不希望被所有人搜到,所以需要设定协议,来告知爬虫哪些内容是不允许抓取的。目前有两种主流的方法可达到此目的:爬虫禁抓协议和网页禁抓标记。
这一点后面会再详细说明。
爬虫初体验
网络爬虫的第一步就是根据URL,获取网页的HTML信息。在Python3中,可以使用urllib.request和requests进行网页爬取。
urllib库是python内置的,无需我们额外安装,只要安装了Python就可以使用这个库。
requests库是第三方库,需要我们自己安装。
12
requests库的基础方法如下:
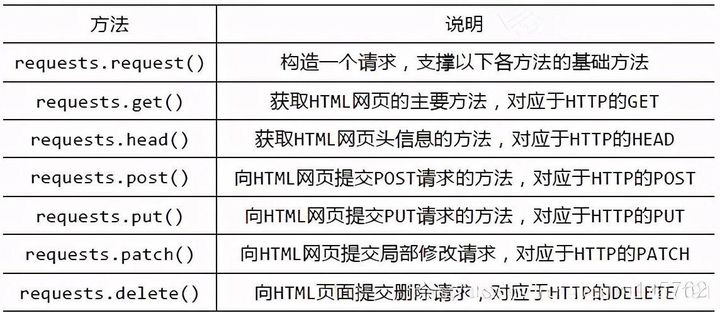
requests.get()
看一段伪代码:
import requests
#引入requests库
res = requests.get('URL')
#requests.get是在调用requests库中的get()方法,
#它向服务器发送了一个请求,括号里的参数是你需要的数据所在的网址,然后服务器对请求作出了响应。
#我们把这个响应返回的结果赋值在变量res上。
123456
刚刚我还在群里跟他们说,学习Python最重要的是打基础,从数据类型,数据结构开始。 那我们就来看看这爬虫获取数据的返回值是个什么数据类型。
先随便找个网址吧,要不就开头那个小乌龟的网址吧: https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1604032500192&di=67b6cdd3eb1722f845fd0cc39625b386&imgtype=0&src=http%3A%2F%2Fwx1.sinaimg.cn%2Flarge%2F006m97Kgly1g5voen881dj30ag0aawfo.jpg
网址是长了点哈,不过可以实验的。
import requests
res = requests.get('URL')
print(type(res))
#打印变量res的数据类型
1234
结果:<class ‘requests.models.Response’>
Response对象常用的四个属性
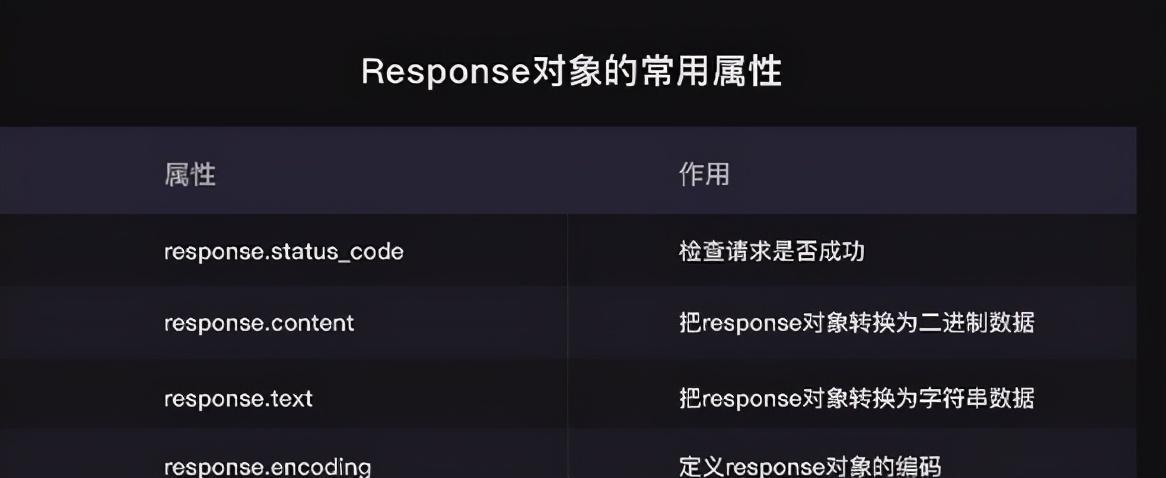
首先是我们的status_code,它是一个很常用的属性,用于检查请求出否成功,可以把它的返回值打印出来看。

接着的属性是response.content,它能把Response对象的内容以二进制数据的形式返回,适用于图片、音频、视频的下载,看个例子你就懂了。 来我们把那个小乌龟爬下来:
import requests
res = requests.get('https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1604032500192&di=67b6cdd3eb1722f845fd0cc39625b386&imgtype=0&src=http%3A%2F%2Fwx1.sinaimg.cn%2Flarge%2F006m97Kgly1g5voen881dj30ag0aawfo.jpg')
#发出请求,并把返回的结果放在变量res中
pic=res.content
#把Reponse对象的内容以二进制数据的形式返回
photo = open('乌龟.jpg','wb')
#新建了一个文件ppt.jpg,这里的文件没加路径,它会被保存在程序运行的当前目录下。
#图片内容需要以二进制wb读写。你在学习open()函数时接触过它。
photo.write(pic)
#获取pic的二进制内容
photo.close()
#关闭文件
123456789101112
大家也可以自己去爬一爬网站里面的小照片。 有的朋友会问:那我要怎么知道我的小照片网址呢? 其实也好办:右击小照片,新建标签页打开,网址不就有了吗。
再不行,你直接把这篇文章上的小照片拖一下嘛,拖到新窗口去,网址就有了。
好,今天的实操大概就在这里了。
讲完了response.content,继续看response.text,这个属性可以把Response对象的内容以字符串的形式返回,适用于文字、网页源代码的下载。
看清楚啊,是源代码。
来,随便找个网址,比方说我这篇文章的网址,咱来体验一下:
import requests
#引用requests库
res = requests.get('https://mp.toutiao.com/profile_v4/graphic/publish?pgc_id=6889211245900071428')
novel=res.text
#把Response对象的内容以字符串的形式返回
k = open('《第七天》.txt','a+')
#创建一个名为《第七天》的txt文档,指针放在文件末尾,追加内容
k.write(novel)
#写进文件中
k.close()
#关闭文档
1234567891011
接下来,我们看最后一个属性:response.encoding,它能帮我们定义Response对象的编码。
首先,目标数据本身是什么编码是未知的。用requests.get()发送请求后,我们会取得一个Response对象,其中,requests库会对数据的编码类型做出自己的判断。但是!这个判断有可能准确,也可能不准确。
如果它判断准确的话,我们打印出来的response.text的内容就是正常的、没有乱码的,那就用不到res.encoding;如果判断不准确,就会出现一堆乱码,那我们就可以去查看目标数据的编码,然后再用res.encoding把编码定义成和目标数据一致的类型即可。