大家好,我是微学AI,今天给大家介绍一下机器学习实战9-基于多模型的自闭症的筛查与预测分析,自闭症是一种神经发育障碍,主要表现为人际交往和社交互动的困难、沟通障碍以及重复刻板行为。早期的筛查和分析对于儿童自闭症的诊断和干预至关重要。
目录
1.项目背景
2.研究意义
3.代码实战与数据分析
3.1数据预处理
3.2数据图形分析
4.机器学习模型分析
4.1数据独热编码
4.2数据整理
4.3逻辑回归模型
4.4随机森林模型
4.5 K近邻模型
4.6 运行结果
5.总结
1.项目背景
自闭症在过去几十年里得到了广泛关注,目前认识到它的高发生率和对患者及其家庭的长期影响。然而,由于自闭症的症状多样化,并且缺乏特异性生物标志物,导致其诊断和治疗面临巨大挑战。因此,开展自闭症的筛查与分析项目可以帮助提高早期诊断的准确性和干预的效果。
2.研究意义
早期干预:自闭症的早期干预对儿童的发展至关重要。通过筛查与分析项目,可以在儿童出现明显症状之前尽早发现患者,并及时进行干预。这有助于改善患者的社交交往、语言能力和行为发展。
提高诊断准确性:自闭症的诊断依赖于专业医生的临床评估,然而这种方式存在主观性和误诊的风险。通过筛查与分析项目,可以利用先进的科学技术和数据分析方法,提高自闭症的诊断准确性,减少漏诊和误诊的情况。
优化资源分配:自闭症的诊断和治疗需要大量的时间、经济和人力资源。通过筛查与分析项目,可以更好地了解自闭症的流行病学特征和社会影响,从而优化资源的分配,提供更有效的支持和服务。
促进研究与知识积累:筛查与分析项目可以收集大量的数据,为自闭症的研究提供宝贵的资源和信息。这有助于深入了解自闭症的发病机制、遗传因素以及潜在的治疗方法,推动自闭症领域的科学进展。
3.代码实战与数据分析
3.1数据预处理
首先要加载数据集,数据集下载地址:
链接:https://pan.baidu.com/s/1sfb3_w2o5X7ya7Z0R51Npw?pwd=94we
提取码:94we
# 第三方库导入
import numpy as np # 导入numpy库用于进行线性代数计算
import pandas as pd # 导入pandas库用于数据处理
import matplotlib.pyplot as plt # 导入matplotlib库用于数据可视化
import seaborn as sns # 导入seaborn库用于数据可视化
# 读取数据集1和数据集2
df1 = pd.read_csv('Autism_Data.arff', na_values='?')
df2 = pd.read_csv('Toddler Autism dataset July 2018.csv', na_values='?')
sns.set_style('whitegrid') # 设置seaborn风格为白色网格
# 提取ASD类别为YES的数据(成年人)
data1 = df1[df1['Class/ASD'] == 'YES']
# 提取ASD Traits为Yes的数据(幼儿)
data2 = df2[df2['Class/ASD Traits '] == 'Yes']
# 计算ASD阳性成年人的比例
print("成年人: ", len(data1) / len(df1) * 100)
# 计算ASD阳性幼儿的比例
print("幼儿:", len(data2) / len(df2) * 100)
# 创建一个包含2个子图的画布,设置大小为20x6
fig, ax = plt.subplots(1, 2, figsize=(20, 6))
3.2数据图形分析
绘制成年人数据集的缺失值热力图
sns.heatmap(data1.isnull(), yticklabels=False, cbar=False, cmap='viridis', ax=ax[0])
ax[0].set_title('成年人数据集')
ax[0].set_ylabel('样本索引')
绘制幼儿数据集的缺失值热力图
sns.heatmap(data2.isnull(), yticklabels=False, cbar=False, cmap='viridis', ax=ax[1])
ax[1].set_title('幼儿数据集')
ax[1].set_ylabel('样本索引')
plt.show() # 显示图形
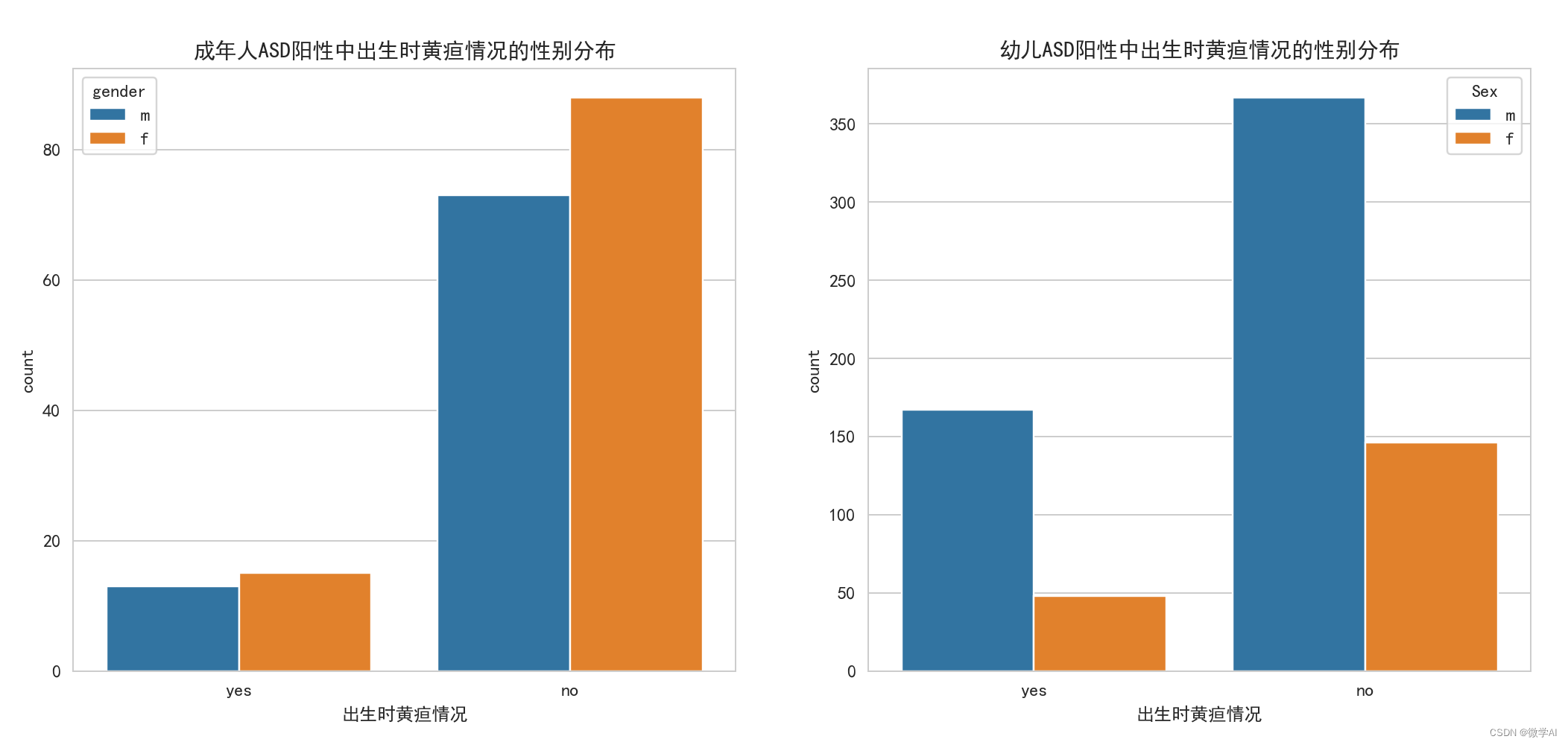
绘制成年、幼儿ASD阳性中出生时黄疸情况的计数柱状图
# 创建一个包含2个子图的画布,设置大小为20x6
fig, ax = plt.subplots(1, 2, figsize=(20, 6))
# 绘制成年人ASD阳性中出生时黄疸情况的计数柱状图
sns.countplot(x='jundice', data=data1, hue='gender', ax=ax[0])
ax[0].set_title('成年人ASD阳性中出生时黄疸情况的性别分布')
ax[0].set_xlabel('出生时黄疸情况')
# 绘制幼儿ASD阳性中出生时黄疸情况的计数柱状图
sns.countplot(x='Jaundice', data=data2, hue='Sex', ax=ax[1])
ax[1].set_title('幼儿ASD阳性中出生时黄疸情况的性别分布')
ax[1].set_xlabel('出生时黄疸情况')
plt.show() # 显示图形
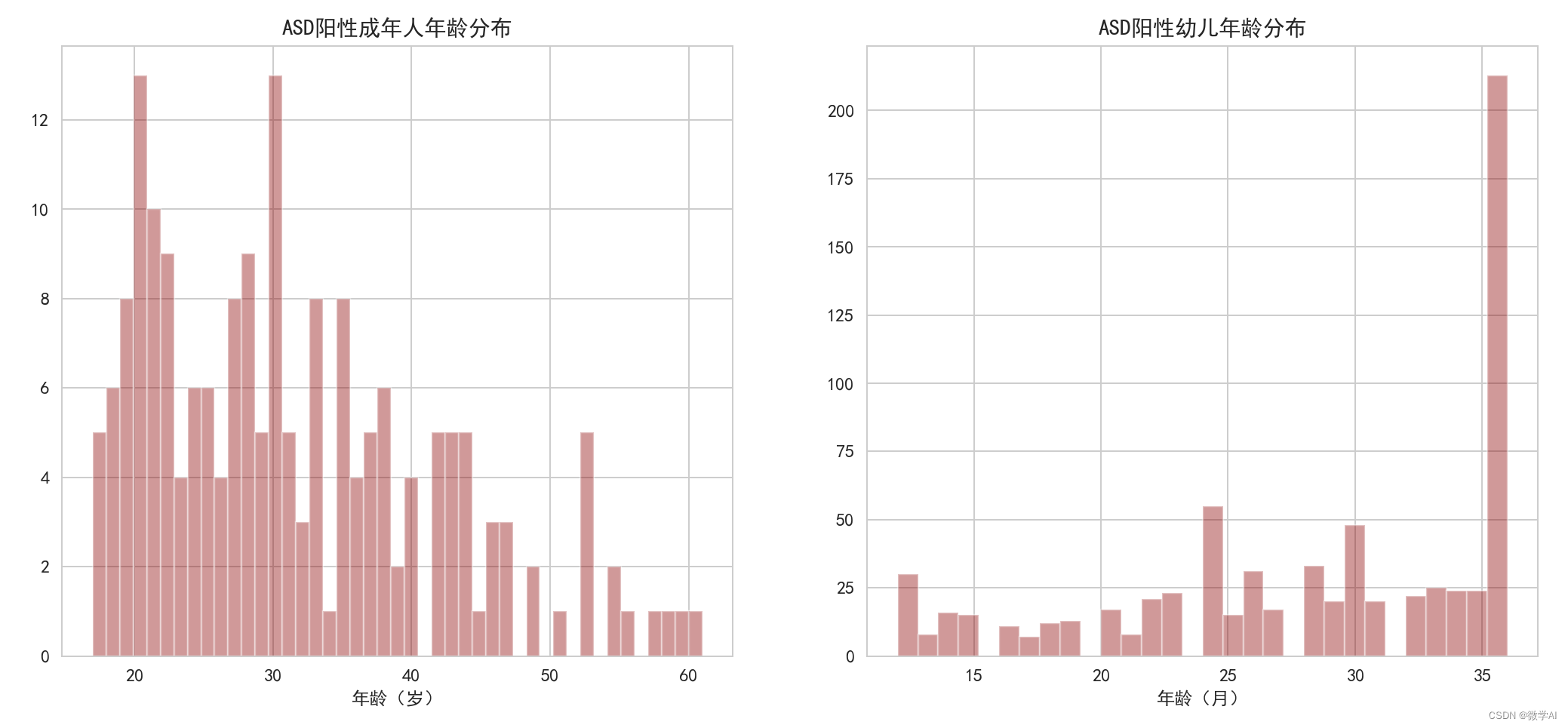
绘制成年人、幼儿ASD阳性年龄分布的直方图
# 创建一个包含2个子图的画布,设置大小为20x6
fig, ax = plt.subplots(1, 2, figsize=(20, 6))
# 绘制成年人ASD阳性年龄分布的直方图
sns.distplot(data1['age'], kde=False, bins=45, color='darkred', ax=ax[0])
ax[0].set_xlabel('年龄(岁)')
ax[0].set_title('ASD阳性成年人年龄分布')
# 绘制幼儿ASD阳性年龄分布的直方图
sns.distplot(data2['Age_Mons'], kde=False, bins=30, color='darkred', ax=ax[1])
ax[1].set_xlabel('年龄(月)')
ax[1].set_title('ASD阳性幼儿年龄分布')
plt.show() # 显示图形
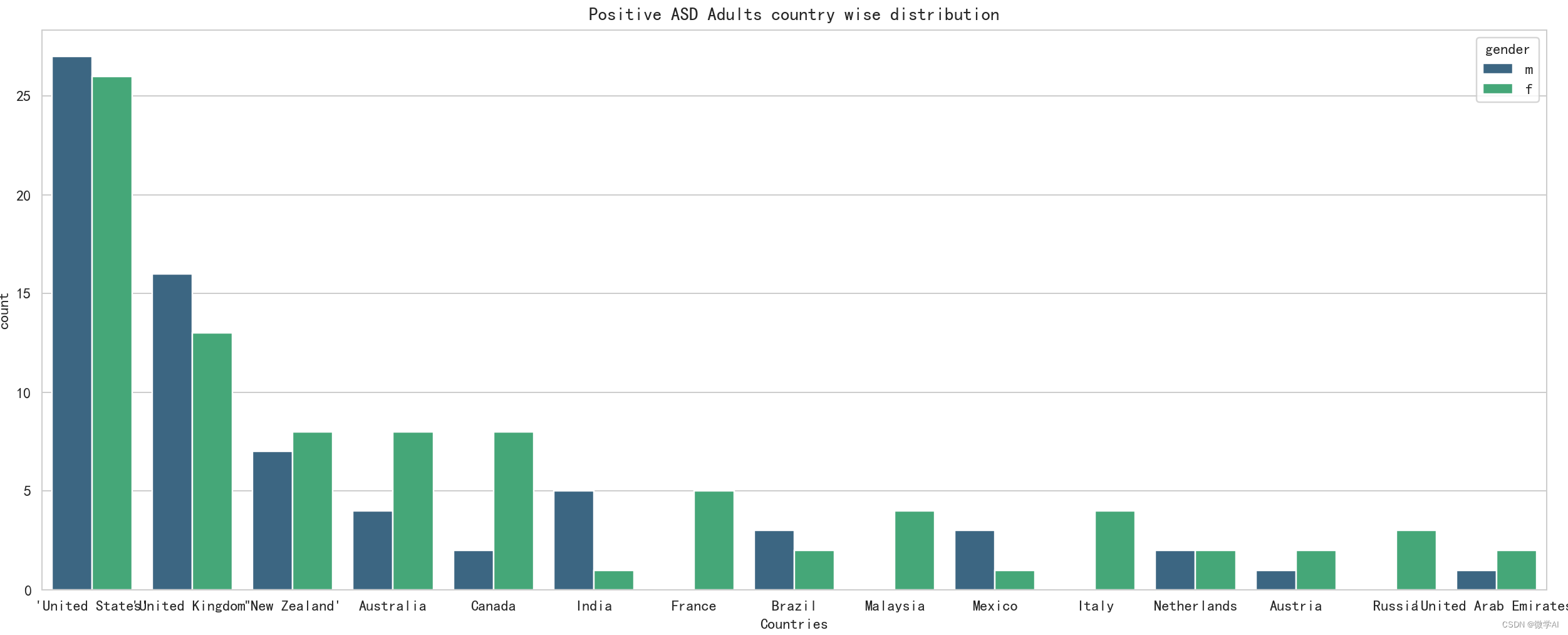
绘制正向 ASD 成人的国家分布图分析
plt.figure(figsize=(20,6))
sns.countplot(x='contry_of_res',data=data1,order= data1['contry_of_res'].value_counts().index[:15],hue='gender',palette='viridis')
plt.title('Positive ASD Adults country wise distribution')
plt.xlabel('Countries')
plt.tight_layout()
plt.show() # 显示图形
# 输出种族的计数值
print(data1['ethnicity'].value_counts())
data2['Ethnicity'].value_counts()
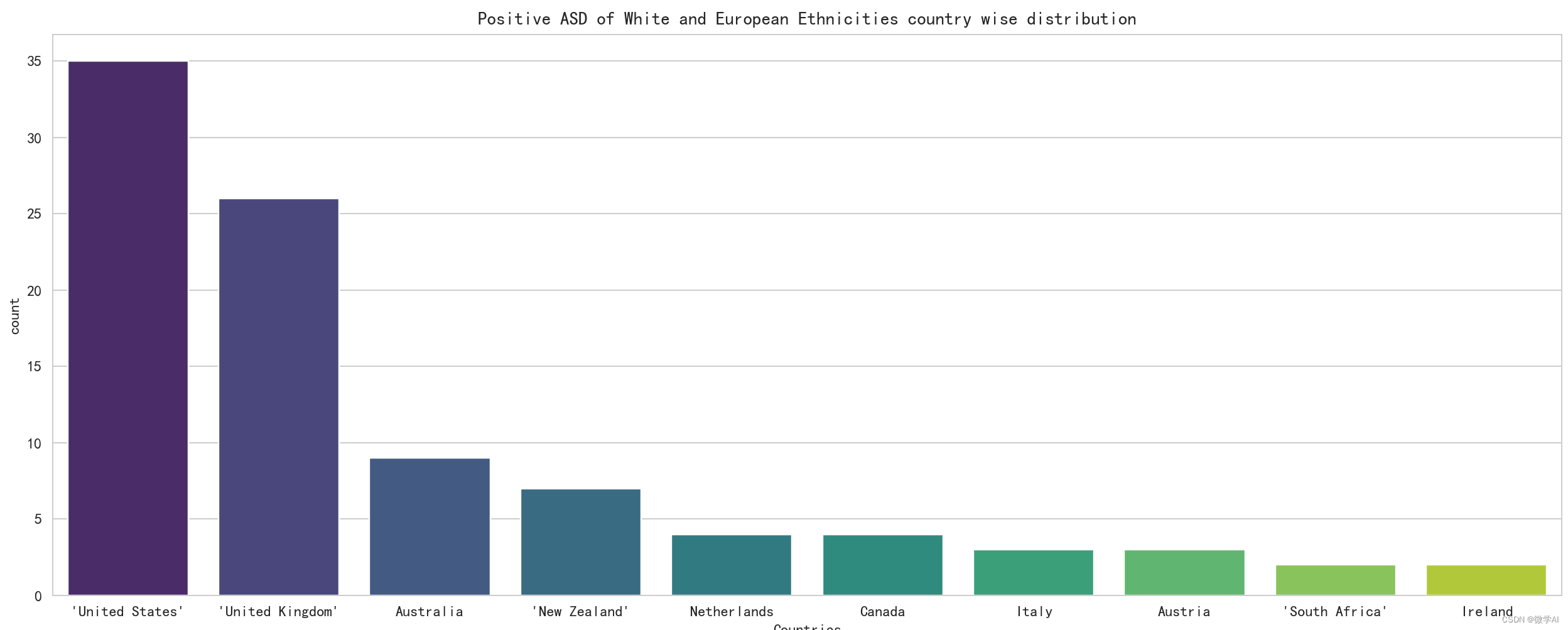
# 绘制白人和欧洲人种族在各个国家的分布图
plt.figure(figsize=(15,6))
sns.countplot(x='contry_of_res',data=data1[data1['ethnicity']=='White-European'],order=data1[data1['ethnicity']=='White-European']['contry_of_res'].value_counts().index[:10],palette='viridis')
plt.title('Positive ASD of White and European Ethnicities country wise distribution')
plt.xlabel('Countries')
plt.tight_layout()
plt.show() # 显示图形
# 绘制不同种族的 ASD 成人亲属中有无自闭症分布和不同种族的 ASD 儿童亲属中有无自闭症分布
fig, ax = plt.subplots(1,2,figsize=(20,6))
sns.countplot(x='austim',data=data1,hue='ethnicity',palette='rainbow',ax=ax[0])
ax[0].set_title('Positive ASD Adult relatives with Autism distribution for different ethnicities')
ax[0].set_xlabel('Adult Relatives with ASD')
sns.countplot(x='Family_mem_with_ASD',data=data2,hue='Ethnicity',palette='rainbow',ax=ax[1])
ax[1].set_title('Positive ASD Toddler relatives with Autism distribution for different ethnicities')
ax[1].set_xlabel('Toddler Relatives with ASD')
plt.tight_layout()
4.机器学习模型分析
4.1数据独热编码
within24_36= pd.get_dummies(df2['Age_Mons']>24,drop_first=True) # 大于24个月的为1,否则为0
within0_12 = pd.get_dummies(df2['Age_Mons']<13,drop_first=True) # 小于13个月的为1,否则为0
male=pd.get_dummies(df2['Sex'],drop_first=True) # 性别为男性的为1,否则为0
ethnics=pd.get_dummies(df2['Ethnicity'],drop_first=True) # 使用独热编码表示种族
jaundice=pd.get_dummies(df2['Jaundice'],drop_first=True) # 是否有黄疸,有黄疸为1,否则为0
ASD_genes=pd.get_dummies(df2['Family_mem_with_ASD'],drop_first=True) # 亲属中是否有自闭症,有自闭症为1,否则为0
ASD_traits=pd.get_dummies(df2['Class/ASD Traits '],drop_first=True) # ASD 特征,有特征为1,否则为0
4.2数据整理
import pandas as pd
# 将多个数据集按列合并
final_data = pd.concat([within0_12, within24_36, male, ethnics, jaundice, ASD_genes, ASD_traits], axis=1)
# 设置列名
final_data.columns = ['within0_12', 'within24_36', 'male', 'Latino', 'Native Indian', 'Others', 'Pacifica', 'White European', 'asian', 'black', 'middle eastern', 'mixed', 'south asian', 'jaundice', 'ASD_genes', 'ASD_traits']
# 显示合并后的数据的前几行
final_data.head()
from sklearn.model_selection import train_test_split
# 划分特征和标签
X = final_data.iloc[:, :-1]
y = final_data.iloc[:, -1]
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=101)
4.3逻辑回归模型
from sklearn.linear_model import LogisticRegression
# 创建逻辑回归模型
logmodel = LogisticRegression()
# 在训练集上训练逻辑回归模型
logmodel.fit(X_train, y_train)
from sklearn.model_selection import GridSearchCV
# 设置网格搜索的参数
param_grid = {
'C': [0.01, 0.1, 1, 10, 100, 1000]}
# 创建逻辑回归模型的网格搜索对象
grid_log = GridSearchCV(LogisticRegression(), param_grid, refit=True)
# 在训练集上进行网格搜索
grid_log.fit(X_train, y_train)
print('GridSearchCV')
# 输出网格搜索得到的最佳模型参数
print(grid_log.best_estimator_)
# 使用网格搜索得到的最佳模型在测试集上进行预测
pred_log = grid_log.predict(X_test)
from sklearn.metrics import classification_report, confusion_matrix
# 输出逻辑回归模型在测试集上的混淆矩阵和分类报告
print(confusion_matrix(y_test, pred_log))
print(classification_report(y_test, pred_log))
4.4 随机森林模型
from sklearn.ensemble import RandomForestClassifier
# 创建随机森林分类器
rfc = RandomForestClassifier(n_estimators=100)
# 在训练集上训练随机森林分类器
rfc.fit(X_train, y_train)
# 使用随机森林分类器在测试集上进行预测
pred_rfc = rfc.predict(X_test)
print('RandomForestClassifier')
# 输出随机森林分类器在测试集上的混淆矩阵和分类报告
print(confusion_matrix(y_test, pred_rfc))
print(classification_report(y_test, pred_rfc))
4.5 K近邻模型
from sklearn.preprocessing import StandardScaler
# 对特征进行标准化处理
scaler = StandardScaler()
scaler.fit(X)
scaled_features = scaler.transform(X)
X_scaled = pd.DataFrame(scaled_features, columns=X.columns)
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=101)
from sklearn.neighbors import KNeighborsClassifier
# 计算不同的K值下的分类错误率
error_rate = []
for i in range(1, 50):
knn = KNeighborsClassifier(n_neighbors=i)
knn.fit(X_train, y_train)
pred_i = knn.predict(X_test)
error_rate.append(np.mean(pred_i != y_test))
# 绘制K值和错误率的关系图
plt.figure(figsize=(10, 6))
plt.plot(range(1, 50), error_rate, color='blue', linestyle='dashed', marker='o', markerfacecolor='red', markersize=10)
plt.title('Error rate vs K-value')
plt.xlabel('K')
plt.ylabel('Error Rate')
# 根据错误率最低的K值创建K近邻分类器
knn = KNeighborsClassifier(n_neighbors=13)
knn.fit(X_train, y_train)
# 使用K近邻分类器在测试集上进行预测
pred_knn = knn.predict(X_test)
print(confusion_matrix(y_test, pred_knn))
print(classification_report(y_test, pred_knn))
4.6 运行结果
逻辑回归模型:
precision recall f1-score support
0 0.00 0.00 0.00 78
1 0.63 1.00 0.77 133
accuracy 0.63 211
macro avg 0.32 0.50 0.39 211
weighted avg 0.40 0.63 0.49 211
随机森林模型:
precision recall f1-score support
0 0.71 0.37 0.49 78
1 0.71 0.91 0.80 133
accuracy 0.71 211
macro avg 0.71 0.64 0.64 211
weighted avg 0.71 0.71 0.68 211
K近邻分类模型:
precision recall f1-score support
0 0.68 0.32 0.43 78
1 0.70 0.91 0.79 133
accuracy 0.69 211
macro avg 0.69 0.62 0.61 211
weighted avg 0.69 0.69 0.66 211
5.总结
本文通过Toddler Autism dataset July 2018.csv数据集对自闭症的情况进行了分析,并通过代码和图表进行可视化分析,其中使用pd.concat()函数将多个数据集按列合并为一个final_data数据集。然后将特征和标签分开,并使用train_test_split()函数将数据划分为训练集和测试集。
本文分别使用网格搜索的逻辑回归模型、随机森林模型和K近邻分类器对训练集进行训练,并在测试集上进行预测。最后,输出模型的混淆矩阵和分类报告,评估模型性能。
其中,特征经过标准化处理后,使用K值从1到49的范围内进行搜索,找到错误率最低的K值,创建最终的K近邻分类器,并进行预测和评估。