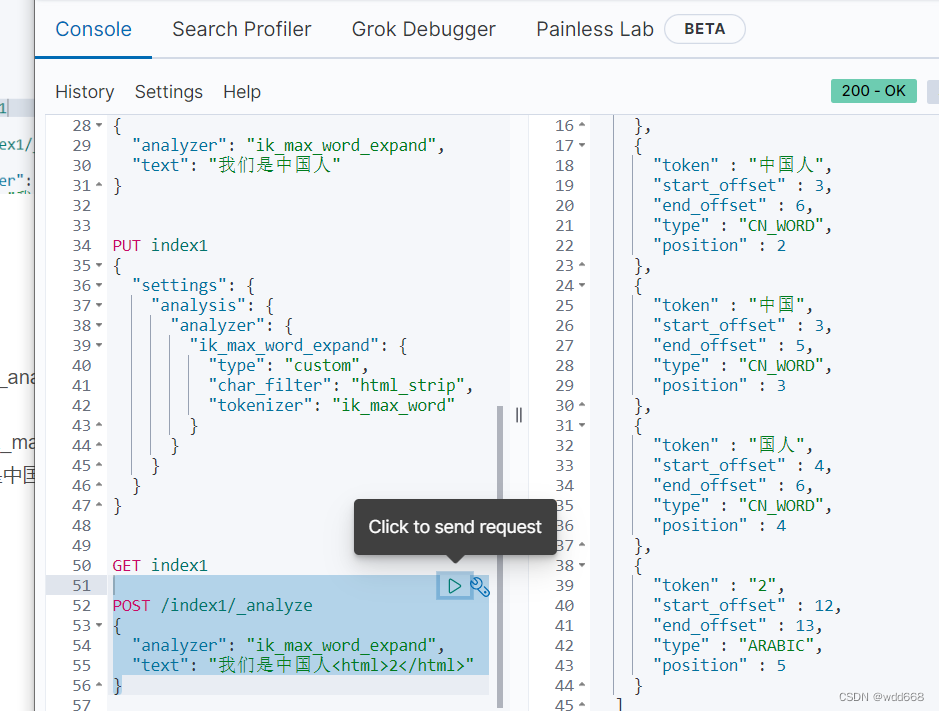
es在索引中自定义简单的分词器 Analyzer 扩展
PUT index1
{
"settings": {
"analysis": {
"analyzer": {
"ik_max_word_expand": {
"type": "custom",
"char_filter": "html_strip",
"tokenizer": "ik_max_word"
}
}
}
}
}

在索引中自定义简单的分词器 Analyzer
上面各个步骤介绍了Analyzer的构成,以及ElasticSearch为每一部分所提供的默认实现,通过组合这些默认实现,我们可以构建属于自己的 Analyzer。
自定义的 Analyzer 必须关联到一个索引上,其语法格式如下:
PUT 索引名称
{
"settings": {
"analysis": {
"analyzer": {
"自定义分词器名称":{
自定义分词器具体内部实现
}
}
}
}
}
通过组合 html strip (character filter), ik_max_word(tokernizer)来实现自己的分词器
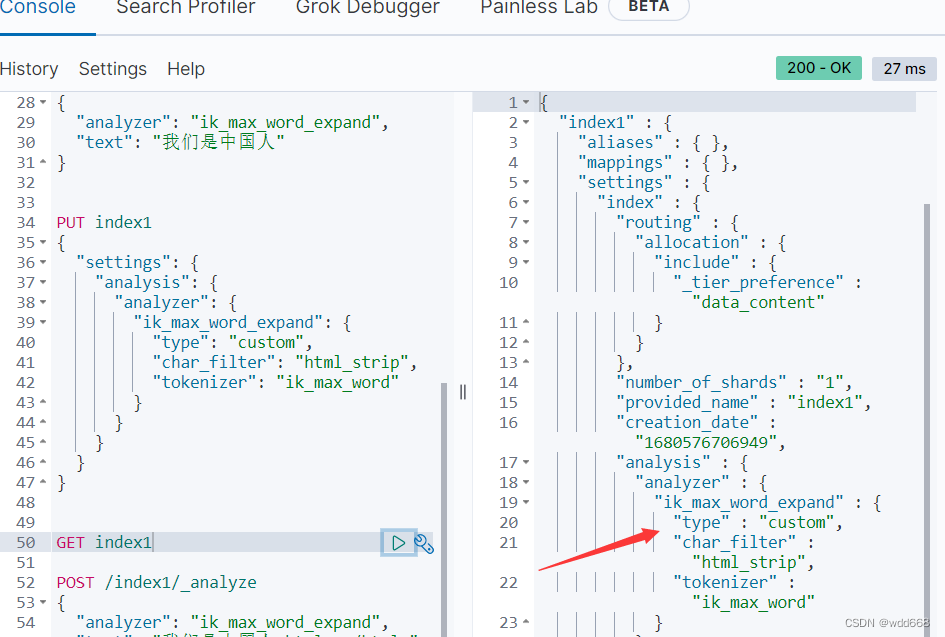
GET index1
POST /index1/_analyze
{
"analyzer": "ik_max_word_expand",
"text": "我们是中国人<html>2</html>
}